数据分享|SAS数据挖掘EM贷款违约预测分析:逐步Logistic逻辑回归、决策树、随机森林...
全文链接:http://tecdat.cn/?p=31745
近几年来,各家商业银行陆续推出多种贷款业务,如何识别贷款违约因素已经成为各家商业银行健康有序发展贷款业务的关键(点击文末“阅读原文”获取完整数据)。
相关视频
在贷款违约预测的数据(查看文末了解数据免费获取方式)的基础上,探索是否能通过借贷者的数据判断其违约风险,从而帮助商业银行提前做好应对。
解决方案
任务/目标
根据借款者的个人信息和贷款的属性,运用SAS EM软件,使用多种模型进行分析。
数据源准备
因获取数据的能力有限,并为了保证数据量足够巨大且数据质量较高,我们选择了贷款违约预测的数据。整个数据集为有800,000条数据,每条数据除了ID、是否违约isDefault该目标值,还包括loanAmnt、term等 29个变量,变量的具体情况在数据探索中进行描述。
特征转换
为了进一步探究issueDate和earliesCreditLine这两个时间ID的时间久远性是否会对我们的预测产生影响,另外增加了两个变量,分别是interval_issueDate和Interval_earliesCreditLine,都是用2020减去issueDate和earliesCreditLine的年份得到的。对缺失数据进行补缺,修改年份变量为区间型变量并对其进行分箱处理,对偏正态分布的变量进行对数处理,拒绝单值型变量。
划分训练集和测试集
划分数据集的50%为训练集,50%为验证集。
建模
使用逐步Logistic回归
回归结果显示,贷款违约风险与年收入负相关,与债务收入比正相关,与利率正相关,与贷款金额正相关;对于分类变量,贷款年限3年的贷款违约风险显著小于贷款5年,2013-2015年的贷款违约风险显著大于2015-2017年等等。
决策树
使用二分支和三分支决策树进行分析,结果显示影响贷款违约的重要因素有homeOwnership、ficoRangeHigh、dti、grade、term、issueDate等。
随机森林
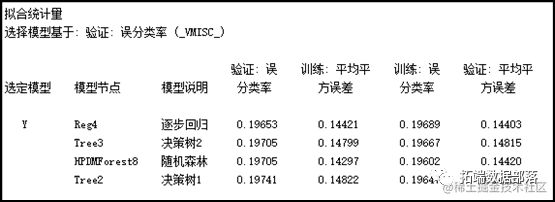
调参后设置最大树个数为100,最大深度为50,显著性水平为0.05,结果显示训练误分类率为0.1964,验证误分类率为0.1974,根据Gini缩减,对分类准确度影响较大的变量为grade、interestRate、term、dti、ficoRangeHigh等。
模型比较
通过比较发现,Logistic回归具有最小的验证误分类率,为0.1965,其次是三分支决策树和随机森林,最差的为二分支决策树。
点击标题查阅往期内容

R语言逻辑回归(Logistic Regression)、回归决策树、随机森林信用卡违约分析信贷数据集

左右滑动查看更多
01
02

03
04
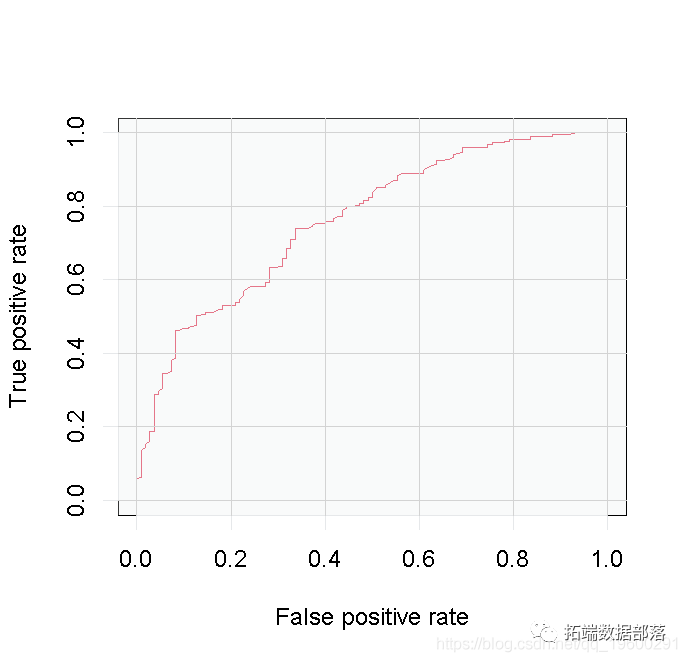
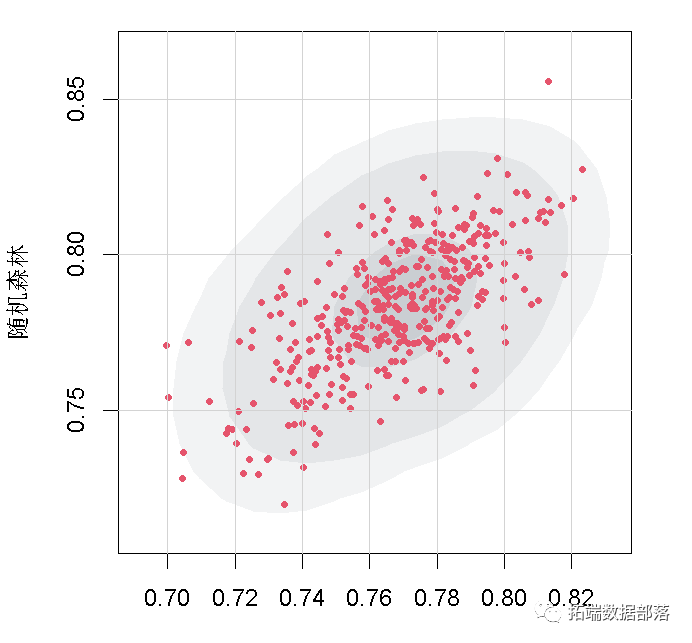
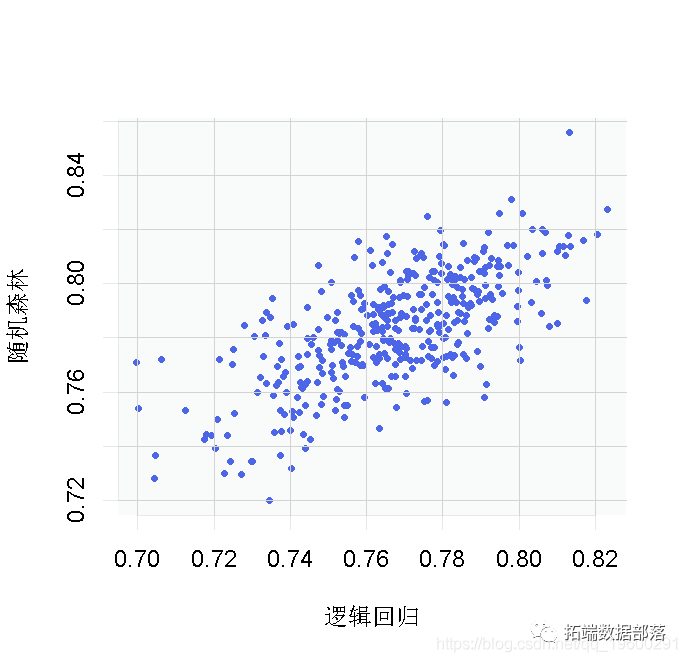
在累积提升度和ROC曲线上,Logistic回归和随机森林表现相近,二分支决策树和三分支决策树表现相近,但是Logistic回归和随机森林模型表现明显优于两个决策树模型。
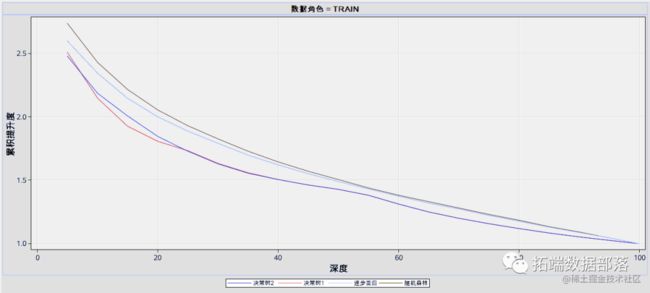

逐步回归模型的验证误分类率低于决策树1、决策树2和随机森林模型,这表明在这四个模型中,逐步回归模型相比其他模型对于新样本具有更强的泛化能力,在对新样本违约概率的预测上更加准确。
根据结果,就数值型变量而言,违约风险与借款人的债务收入比dti、循环额度利用率revolUtil、贷款利率interestRate、贷款金额loanAmnt、借款人信用档案中未结信用额度的数量openAcc显著正相关;与就业职称employmentTitle、年收入annualIncome、借款人在贷款发放时的FICO所属的下限范围ficoRangeLow、分期付款金额installment、信贷周转余额合计revolBal、借款人信用档案中当前的信用额度总数totalAcc显著负相关。
对于贷款发放年份issueDate,相较于2017年6月之后发放的贷款,2013年6月之前发放的贷款违约风险显著更大,贷款发放年份在2013.6-2015.6年的违约风险稍低,在2015.6-2017.6年的贷款则显著更小。
申请类型applicationType为0时,其违约风险显著小于其值为1时。
相对于贷款等级G,贷款等级为A、B、C时,其违约风险显著更大,贷款等级为D、E、F时,违约风险则显著更小。
相对于房屋所有权状况homeOwnership为5时,homeOwnership为1时,违约风险显著更小,homeOwnership为0,2,3时,违约风险减小,但其结果在统计学上不显著;homeOwnership为4时,违约风险升高,但在统计学上仍然不显著。
贷款用途purpose为0,4,5,8,12时,违约风险显著大于用途为13,用途为1,7,9时,违约风险显著更小,用途为2,3,6,10,11时,其违约风险相对于13没有统计学意义。
贷款期限term为3年时,其违约风险显著小于贷款期限为5年。
验证状态verificationStatus为0时,相对于其值为2时违约风险显著更大。其值为1时则相对于2违约风险显著更小。
因此,建议贷款发放机构在评估借款人的违约风险时,重点关注借款人的负债收入比、就业职称、年收入、房屋所有权状况等个人信息,并分析借款人的借款行为,包括其申请贷款的金额、利率、分期付款金额、用途、申请类型、贷款等级、贷款期限、验证状态,调查借款人的历史借款记录,包括循环额度利用率、借款人信用档案中未结信用额度的数量、贷款发放时的FICO所属的下限范围、信贷周转余额合计、信用档案中当前的信用额度总数。
对于已经发放的贷款,如果贷款行为发生于2013年6月之前,贷款发放机构应该尽快追回并做好坏账准备。
关于分析师
在此对Jiasong Xue对本文所作的贡献表示诚挚感谢,他在中山大学完成了管理科学专业的学位,专注商业数据分析领域。擅长SPSS、R语言、Python。
数据获取
在公众号后台回复“贷款违约数据”,可免费获取完整数据。
![]()
本文中分析的数据分享到会员群,扫描下面二维码即可加群!

点击文末“阅读原文”
获取全文完整数据资料。
本文选自《SAS数据挖掘EM贷款违约预测分析:逐步Logistic逻辑回归、决策树、随机森林》。
![]()

点击标题查阅往期内容
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
spss modeler用决策树神经网络预测ST的股票
R语言中使用线性模型、回归决策树自动组合特征因子水平
R语言中自编基尼系数的CART回归决策树的实现
R语言用rle,svm和rpart决策树进行时间序列预测
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言ISLR工资数据进行多项式回归和样条回归分析
R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
如何用R语言在机器学习中建立集成模型?
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
在python 深度学习Keras中计算神经网络集成模型
R语言ARIMA集成模型预测时间序列分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言基于Bootstrap的线性回归预测置信区间估计方法
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线
matlab使用分位数随机森林(QRF)回归树检测异常值
![]()
![]()
