python爬取百度图片并对图片做一系列处理
1、首先python爬取百度图片
代码如下:
import csv
import os
import re
import parsel
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0)like Gecko)'}
def baidu_img(keword, num):
base_url = 'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word={}'.format(keword)
path1 = r"E:\图片\\" + keword
y = os.path.exists(path1)
if y == 0:
os.mkdir(path1)
else:
pass
response = requests.get(base_url, headers=headers)
html_str = response.text
# html = parsel.Selector(html_str)
# img_href = html.xpath('//li/div/a/img/@src').extract() #利用xpath提取图片路径
pic_url = re.findall('"objURL":"(.*?)",', html_str, re.S) #利用正则表达式找到图片url
# print(pic_url)
n = 0
for i in pic_url:
try:
img = requests.get(i, headers=headers).content
img_name = i.split('=')[-1]
with open(path1 + '\\' + img_name + '.jpg', 'wb')as f:
f.write(img)
n = n + 1
with open(path1 + '.csv', 'a', newline='')as ff:
csvwriter = csv.writer(ff, dialect='excel')
csvwriter.writerow([img_name, i])
if n >= num:
break
except Exception as e:
print(e)
if __name__ == '__main__':
baidu_img('狗', 20)
2、验证图片是否已经正常爬取
如下图所示,20张狗狗图片已经爬取到我们的磁盘中来了

3、对图片进行去重操作,一般图片去重可以通过MD5去重,也可以通过感知哈希,计算图片的汉明距离进行去重,这里我们介绍第一种
代码如下:
import hashlib
import numpy as np
import requests
from PIL import Image
def md5(dirName):
files = os.listdir(dirName) # 遍历文件夹下的所有文件
temp = set() # 创建一个set()
count = 0 # 删除的文件计数
for file in files:
if file.lower().endswith(('jpg', 'jpeg', 'png')):
file_path = os.path.join(dirName, file) # 获得完整的路径
try:
img = Image.open(file_path) # 打开图片
img_array = np.array(img) # 转为数组
md5 = hashlib.md5() # 创建一个hash对象
md5.update(img_array) # 获得当前文件的md5码
if md5.hexdigest() not in temp: # 如果当前的md5码不在集合中
temp.add(md5.hexdigest()) # 则添加当前md5码到集合中
else:
os.remove(file_path)
count += 1 # 否则删除图片数加一
except Exception as e:
os.remove(file_path)
print("duplicate removal:", count) # 最后输出删除图片的总数
验证结果:

以上是有重复图片的样本
执行代码后:

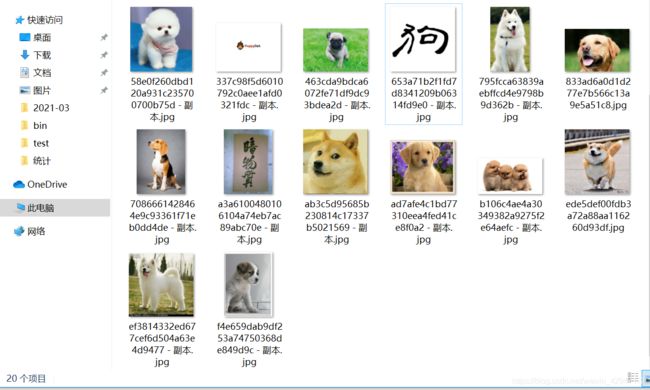
那些相同的图片已经被删掉了,图片数量又恢复到了20张,图片去重验证成功。
4、对图片进行重命名和统计操作
不多说,代码如下:
def rename(dirName):
for root, files in os.walk(dirName):
print(root,files)
i = 0
for file_name in files:
if file_name.lower().endswith(('jpg', 'jpeg', 'png')):
oldname = os.path.join(root, file_name)
pic_format = os.path.splitext(oldname)[-1]
name = 'hivision_buiing_' + root.split('\\')[-1]
print(name)
newname = root + '/' + name + '_' + str(i + 1).zfill(4) + pic_format
i = i + 1
print(newname)
try:
os.rename(oldname, newname)
except Exception as f:
print(f)
重命名验证截图:

可以看出小狗狗的名字就整齐归一了
5、对图片的文件夹进行统计
代码如下:
def get_dirs_num(self):
dict = {}
f = xlwt.Workbook()
sheet1 = f.add_sheet(u'统计文件数量', cell_overwrite_ok=True)
row = 0
row0 = ['文件夹路径', '文件夹名称', '文件数量']
for n in range(len(row0)):
sheet1.write(0, n, row0[n])
path = r'E:\图片'
for root, dirs, files in os.walk(path):
num = 0
for dir_files in os.listdir(root):
if os.path.isfile(os.path.join(root, dir_files)):
if dir_files.lower().endswith(('.jpg', 'jpeg', 'png')):
num = num + 1
name = root.replace(path + '\\', '')
dict[name] = num
for key, values in dict.items():
col = 0
if values > 0:
sheet1.write(row + 1, col, os.path.join(path, key))
col = col + 1
name_list = key.split('\\')
row = row + 1
sheet1.write(row, col, name_list)
col = col + 1
sheet1.write(row, col, values)
f.save(r'E:\图片\\count.xls')
完成统计,结果如下:
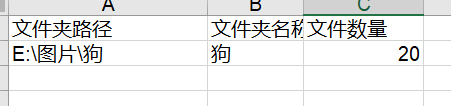
完整代码统一整理如下:
import csv
import hashlib
import os
from tkinter import *
import numpy as np
import requests
from PIL import Image
import xlwt
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0)like Gecko)'}
class image():
def baidu_img(self, keword, num):
base_url = 'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word={}'.format(keword)
path1 = r"E:\图片\\" + keword
y = os.path.exists(path1)
if y == 0:
os.mkdir(path1)
else:
pass
response = requests.get(base_url, headers=headers)
html_str = response.text
# html = parsel.Selector(html_str)
# img_href = html.xpath('//li/div/a/img/@src').extract() #利用xpath提取图片路径
pic_url = re.findall('"objURL":"(.*?)",', html_str, re.S) # 利用正则表达式找到图片url
# print(pic_url)
n = 0
for i in pic_url:
try:
img = requests.get(i, headers=headers).content
img_name = i.split('=')[-1]
with open(path1 + '\\' + img_name + '.jpg', 'wb')as f:
f.write(img)
n = n + 1
with open(path1 + '.csv', 'a', newline='')as ff:
csvwriter = csv.writer(ff, dialect='excel')
csvwriter.writerow([img_name, i])
if n >= num:
break
except Exception as e:
print(e)
def md5(self, dirName):
files = os.listdir(dirName) # 遍历文件夹下的所有文件
temp = set() # 创建一个set()
count = 0 # 删除的文件计数
for file in files:
if file.lower().endswith(('jpg', 'jpeg', 'png')):
file_path = os.path.join(dirName, file) # 获得完整的路径
try:
img = Image.open(file_path) # 打开图片
img_array = np.array(img) # 转为数组
md5 = hashlib.md5() # 创建一个hash对象
md5.update(img_array) # 获得当前文件的md5码
if md5.hexdigest() not in temp: # 如果当前的md5码不在集合中
temp.add(md5.hexdigest()) # 则添加当前md5码到集合中
else:
os.remove(file_path)
count += 1 # 否则删除图片数加一
except Exception as e:
os.remove(file_path)
print("duplicate removal:", count) # 最后输出删除图片的总数
def rename(self, dirName):
for root, dirs, files in os.walk(dirName):
i = 0
for file_name in files:
if file_name.lower().endswith(('jpg', 'jpeg', 'png')):
oldname = os.path.join(root, file_name)
pic_format = os.path.splitext(oldname)[-1]
name = 'hivision_buiing_' + root.split('\\')[-1]
print(name)
newname = root + '/' + name + '_' + str(i + 1).zfill(4) + pic_format
i = i + 1
print(newname)
try:
os.rename(oldname, newname)
except Exception as f:
print(f)
def get_dirs_num(self):
dict = {}
f = xlwt.Workbook()
sheet1 = f.add_sheet(u'统计文件数量', cell_overwrite_ok=True)
row = 0
row0 = ['文件夹路径', '文件夹名称', '文件数量']
for n in range(len(row0)):
sheet1.write(0, n, row0[n])
path = r'E:\图片'
for root, dirs, files in os.walk(path):
num = 0
for dir_files in os.listdir(root):
if os.path.isfile(os.path.join(root, dir_files)):
if dir_files.lower().endswith(('.jpg', 'jpeg', 'png')):
num = num + 1
name = root.replace(path + '\\', '')
dict[name] = num
for key, values in dict.items():
col = 0
if values > 0:
sheet1.write(row + 1, col, os.path.join(path, key))
col = col + 1
name_list = key.split('\\')
row = row + 1
sheet1.write(row, col, name_list)
col = col + 1
sheet1.write(row, col, values)
f.save(r'E:\图片\\count.xls')
if __name__ == '__main__':
keyword = '狗'
dirName = r"E:\图片\\{}".format(keyword)
num =20
test = image()
test.baidu_img(keyword, num)
test.md5(dirName)
test.rename(dirName)
test.get_dirs_num()