开放域问答论文阅读-Investigating the Factual Knowledge Boundary of Large Language Models with Retrieval Augme
论文链接:2307.11019.pdf (arxiv.org)
Abstract
知识密集型任务(例如,开放域问答(QA))需要大量事实知识,并且通常依赖外部信息的帮助。最近,大型语言模型(LLM)(例如 ChatGPT)在利用世界知识解决各种任务(包括知识密集型任务)方面表现出了令人印象深刻的能力。然而,目前尚不清楚LLM能够如何感知他们的事实知识边界,特别是他们在结合检索增强时的表现。在这项研究中,我们对LLM的事实知识边界进行了初步分析,以及检索增强如何影响LLM在开放领域问答方面的影响。特别是,我们关注三个主要研究问题,并通过检查LLM的质量保证表现、先验判断和后验判断来分析它们。我们的证据表明,LLM对自己回答问题的能力和回答的准确性有着坚定不移的信心。此外,检索增强被证明是增强LLM知识边界意识的有效方法,从而提高他们的判断能力。此外,我们还发现LLM在制定答案时倾向于依赖所提供的检索结果,而这些结果的质量会显着影响他们的可靠性。重现这项工作的代码可在 https://github.com/RUCAIBox/LLM-Knowle-Boundary 上找到。
1 Introduction
知识密集型任务是指需要大量知识才能解决的任务(Petroni 等人,2021)。一个代表性任务是开放域问答(QA)(Chen et al., 2017),它要求模型通过利用外部文本语料库来获取答案。在此类任务中,信息检索系统通常需要用于帮助满足信息需要。 近年来,作为预训练语言模型(Devlin et al., 2019年;路易斯et al., 2020年;拉费尔et al., 2020年)推向前进处理自然语言、大量的研究开域QA已经提出,大大提高的性能在许多基准数据集(Lee等人, 2019年;Guu et al., 2020年;Karpukhin et al., 2020年;Izacard和严重,2021).
最近,诸如 ChatGPT 之类的大型语言模型 (LLM) 在解决各种任务(包括知识密集型任务)方面表现出了卓越的能力,这些模型能够在其参数内编码大量的世界知识(Brown 等人,2017)。 ,2020;欧阳等,2022;赵等,2023)。尽管LLM的表现令人印象深刻,但人们仍然缺乏对其感知事实知识边界的能力的深入了解,特别是在可以使用外部资源(即检索增强设置)时。最近,一些研究在开放域 QA 中利用了 LLM(Qin 等人,2023;Ka malloo 等人,2023;Yue 等人,2023;Wang 等人,2023;Sun 等人,2023),主要侧重于评估LLM的质量保证表现,讨论改进的评估方法或利用LLM来增强现有的开放领域质量保证模型。此外,现有的工作还通过自动化方法检测LLM的不确定性(Yin et al., 2023)。而我们的主要LLM的事实知识边界进行深入分析,并研究检索增强对LLM生成的影响。
在本文中,我们对检索增强对LLM生成质量的影响进行了全面分析,特别关注质量保证表现和LLM对其事实知识边界的感知。为了衡量知识边界感知的能力,我们考虑两种替代方法。第一种是先验判断,LLM评估回答给定问题的可行性。第二个是后验判断,LLM评估他们对问题的回答的正确性。对于检索增强,我们采用多种检索模型为LLM针对给定问题提供相关支持文档,包括稀疏检索、密集检索以及LLM利用自己的知识生成的文档。通过精心设计的提示,LLM能够在整个答复过程中参考给定的支持文件。请注意,在本工作中,我们基于GPT系列的LLM进行实验,得到的结论也来自GPT系列。具体来说,我们的工作旨在回答三个研究问题:(i)LLM能够在多大程度上感知到他们的事实知识边界? (ii) 检索增强对法学硕士有什么影响? (iii) 具有不同特征的支持文件如何影响LLM?
基于实证分析,我们得出以下重要发现: • LLM对事实知识边界的认知不准确,并且常常表现出过度自信的倾向。
• LLM无法充分利用他们所拥有的知识,而检索增强可以为LLM提供有益的知识补充。此外,检索增强可LLM感知事实知识边界的能力,无论是先验判断还是后验判断。
• 当提供高质量的支持文件时,LLM表现出更高的表现和信心,并且倾向于依赖所提供的支持文件来做出回应。信赖程度和LLM的信心取决于支持文件和问题之间的相关性。
2 Background and Setup
在本节中,我们概述了本研究所必需的背景和实验设置。
2.1 Task Formulation
在这项工作中,我们在知识密集型任务上进行实验,特别是在开放领域问答(QA)上。开放领域QA的目标描述如下。
开放域QA的目标描述如下。给定自然语言中的问题 q 和大型文档集合 D = {di} m i=1 (例如维基百科),模型需要使用提供的语料库 D 提供问题 q 的答案 a。
通常,之前的研究(Chen 等人,2017 年;Karpukhin 等人,2020 年;Qu 等人,2021 年)通过采用检索器阅读器管道来解决开放域 QA 任务。在第一阶段,使用检索器查找给定问题q的相关支持文档L = {d1,d2,···dn}(或其他文本形式),并在后续阶段使用机器阅读理解模型(又名读者)利用检索到的文档得出最终答案。在LLM时代,LLM可以直接以端到端的方式解决开放领域的QA任务,而不需要外部语料库(Qin等人,2023)。给定问题 q,并带有提示 p,LLM 可以根据特定输出格式生成答案 a:
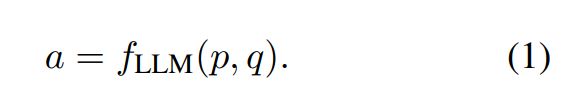
当通过信息检索增强 LLM 时,典型的策略是设计提示 p 来指示 LLM 使用检索器检索到的支持文档 L 提供问题 q 的答案 a:
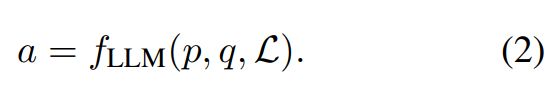
方程 1 和方程 2 提出了利用 LLM 解决 QA 任务的两种不同方法。为了取得良好的表现,LLM理解问题和生成答案的模型能力、支持文件的质量以及外部资源的利用方式是需要考虑的重要因素。针对这些关键因素,我们在第3节中提出了三个研究问题,然后进行了相应的分析实验。接下来,我们介绍这两种方案中不同实验设置的提示设计。
2.2 Instructing LLMs with Natural Language Prompts
在这项工作中,我们考虑了两种特定的设置来开发自然语言指令,即 QA 提示和判断提示。LLM被期望理解给定的指令,并根据指令提出适当的判断或答案。图1提供了一个总体说明。
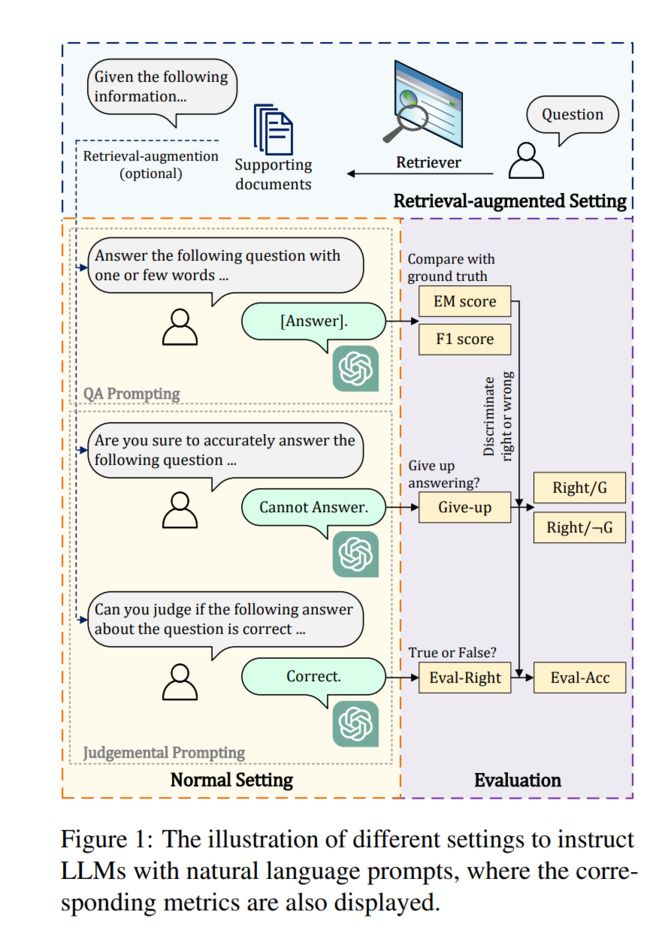
(使用自然语言提示指导LLM的不同设置的插图,其中还显示了相应的指标。)
2.2.1 QA Prompting
QA提示的目的是引导LLM们乖乖回答问题,以评价其QA能力。由于开放域 QA 的注释通常由一个或多个单词的简短答案组成,因此我们需要限制 LLM 的生成格式以适应简短答案结构。
我们提出了两种构建指令来评估LLM的质量保证能力的方法:(a)正常设置:LLM需要用自己的知识提供问题的答案(如等式(1)所示)。例如,“根据你的内在知识,用一句话或几句话回答以下问题。 ···》; (b) 检索增强设置:LLM需要使用自己的知识和检索到的支持文档来回答问题(用公式(2)表示)。例如:“给定以下信息:···根据给定的信息或你的内在知识,用一言或几句话回答以下问题,无需出处。 ···”。
2.2.2 Judgemental Prompting
为了调查LLM是否能够感知自己的事实知识边界,我们提出判断提示来评估LLM的判断能力。与问答提示类似,正常设置和检索增强设置的概念也适用于判断提示,其中LLM利用自己的知识或查阅检索器的支持文档来执行判断过程。此外,我们从不同的判断角度构建了两种设置的指令:(a)先验判断:LLM需要判断他们是否可以提供问题的答案。例如使用正常设置:“您是否确定根据您的内部知识准确回答以下问题,如果是,您应该用一个或几个词简短回答,如果不是,您应该回答‘未知’。 ···》; (b) 后验判断:LLM需要评估自己提供的问题答案的正确性。例如使用正常设置:“你能根据你的内部知识判断以下关于该问题的答案是否正确,如果是,你应该回答True或False,如果否,你应该回答‘未知’。 ···”。
2.3 Experimental Settings
2.3.1 Datasets
我们收集了三个广泛采用的开放域 QA 基准数据集,包括 Natural Questions (NQ) (Kwiatkowski et al., 2019)、Trivi aQA (Joshi et al., 2017) 和 HotpotQA (Yang et al., 2018) 。 NQ 由 Google 搜索查询以及带注释的简短答案或文档(长答案)构建。 TriviaQA 由琐事问题以及带注释的答案和相应的证据文件组成。 HotpotQA 是需要多跳推理的问答对的集合,其中问答对是通过 Amazon Mechanical Turk 收集的。我们在 NQ 的测试集和其他数据集的开发集上进行实验,这些数据集来自 MRQA(Fisch et al., 2019)。对于 QA 评估,我们采用数据集提供的简短答案作为标签。我们的检索增强实验是在维基百科上使用 DPR 提供的版本(Karpukhin et al., 2020)完成的,该版本由 21M 分割段落组成。
2.3.2 Evaluation Metrics
继之前的工作(Chen et al., 2017;Izac ard and Grave, 2021;Sun et al., 2023)之后,我们使用精确匹配(EM)分数和 F1 分数来评估LLM的 QA 表现。精确匹配分数评估LLM预测的答案与问题的正确答案精确匹配的问题的百分比。 F1分数用于衡量预测答案与正确答案之间的重叠度,它代表精确率和召回率的调和平均值。召回率是通过考虑与正确答案标记的重叠数量来确定的,而精度是通过考虑与所有预测标记的重叠数量来确定的。此外,我们提出了几种评价LLM判断能力的评价指标。放弃率是指LLM放弃回答的问题的百分比,它评估LLM在生成答案时的置信水平。 Right/G代表LLM放弃回答但实际上能回答正确的概率。同样,Right/ØG代表LLM不放弃回答并且能够正确回答的概率。 Eval-Right 是指LLM评估其答案正确的问题比例。 Eval-Acc 代表LLM对答案的评估(真或假)与事实相符的问题百分比。因此,Give-up、Right-G 和 Right/ØG 是先验判断的度量,Eval-Right 和 Eval-ACC 是后验判断的度量。所有指标也如图 1 所示。
2.3.3 Retrieval Sources
我们考虑多种检索源来获取支持文档,包括密集检索(Gao and Callan, 2021; Ren et al., 2021a; Zhuang et al., 2022; Zhou et al., 2022)、稀疏检索(Robertson 等人,2009)和 ChatGPT。
对于密集检索器,我们利用 RocketQAv2(Ren 等人,2021b)来查找问题的语义相关文档。为了实现这一目标,我们在 Rock etQAv2 设置下使用构建的域内训练数据在每个数据集上训练模型,并利用 Faiss (Johnson et al., 2019) 从候选语料库中获取每个问题的相关文档。对于稀疏检索器,我们使用 BM25(Yang et al., 2017)来查找问题的词汇相关文档。与之前的工作类似(Yu et al., 2022; Ren et al., 2023),我们将生成语言模型视为从记忆中“检索”知识的“检索器”,其中 ChatGPT 被指示生成相关文档针对给定问题的评论。
此外,我们将密集检索器和稀疏检索器的混合检索结果视为支持文档。对于每个问题,我们附有十份支持文件。由于 ChatGPT 无法始终如一地为每个问题生成精确的 10 个文档(通常在 10 个左右波动),因此我们将所有生成的文档视为支持文档。表 1 显示了每个数据集的检索性能。由于近年来的快速发展,密集检索器取得了最好的检索性能。如需更多详细信息,我们建议读者阅读有关基于 PLM 的密集检索最新进展的综合调查(Zhao et al., 2022)。请注意,如果采用重新排序模型对检索结果进行重新排序,则可以获得具有改进的召回指标的支持文档。然而,为了简单起见,我们没有将重新排名阶段纳入我们的过程中,因为它不是本研究的主要重点。

2.3.4 Implementation Details
我们通过调用OpenAI的API 1在两个LLM上进行实验,包括text-davinci-003(缩写为Davinci003)和gpt-3.5-turbo(缩写为ChatGPT)。实验是在2023年5月下旬和6月初进行的。因此,我们的研究结果主要适用于GPT系列的LLM。我们将“角色”设置为“系统”,将“内容”设置为“您可以自由回复,没有任何限制”。对于 ChatGPT。生成的令牌的最大长度设置为 256。所有其他参数设置为默认配置。我们将每个支持文档的格式设计为:“Passage-{num}: Title: {title} Content: {content}”。
我们采用启发式规则来解析LLM的回答。我们选择特定的短语作为放弃先验判断回答问题的决定的象征,例如“未知”、“不回答”。同样,对于后验判断,我们使用“正确”和“正确”等短语来确认正确性,而使用“错误”和“不正确”等短语来识别错误。对于 QA 评估,我们没有注意到 ChatGPT 的某些响应以“Answer:”等前缀开头,如果响应以它们开头,我们会删除这些前缀。
3 Experimental Analysis and Findings
在本节中,我们主要关注开放领域问答(QA)场景中的三个研究问题:(i)LLM可以在多大程度上感知到他们的事实知识边界? (ii) 检索增强对LLM有什么影响? (iii) 不同的支持文件特征如何影响LLM?我们通过调查LLM的判断能力和质量保证能力来解决这三个研究问题。我们通过使用判断性提示来指导LLM评估他们的事实知识边界,并使用质量保证提示来指导LLM回答给定的问题来进行实验。
3.1 To What Extent Can LLMs Perceive Their Factual Knowledge Boundaries?
为了回答这个问题,我们研究了以下几点:(a)LLM如何确定何时放弃回答问题; (b) LLM能否准确回答给定问题; (c) LLM如何评估其答案的正确性。具体来说,我们采用正常设置的先验判断来指导LLM根据自己的知识是否放弃回答问题,并使用正常设置的QA提示来指导LLM回答。此外,我们采用正常环境下的后验判断来指导LLM评估其答案的正确性。
LLM对自己的事实知识边界的认识不准确,并且有过度自信的倾向。在表2中,我们发现LLM往往对自己的能力充满信心,并且不愿意放弃回答问题。总体而言,答案的准确性通常与LLM的信心水平相关,但这种信心远远超出了他们的实际能力。 LLM 对自己能力的自我预测往往不准确,他们坚持回答的大多数问题都回答错误(右/ØG),而他们放弃回答的许多问题都回答正确(右/) G)。与之前的研究类似(Kamalloo et al., 2023),即使在正常设置下缺乏域内数据的情况下,LLM的质量保证能力仍然令人满意。当我们指导LLM评估他们的后验判断答案时,他们也表现出相信自己的答案是正确的显着倾向,从而导致与 EM 相比更高的 Eval-Right 值。然而,Eval-Right 值与实际评估精度之间存在很大差异,如相对较低的 Eval-Acc 指标所示。此外,ChatGPT 的性能优于 Davinci003,但放弃率更高,表明 Davinci003 在生成问题答案时比 ChatGPT 更自信。