卷(四)C++___二刷
Templates and Classes
19.1 — Template classes
Creating template classes works pretty much identically to creating template functions, so we’ll proceed by example. Here’s our array class, templated version:
Array.h:
#ifndef ARRAY_H
#define ARRAY_H
#include , not Array
{
return m_length;
}
#endif
As you can see, this version is almost identical to the IntArray version, except we’ve added the template declaration, and changed the contained data type from int to T.
Note that we’ve also defined the getLength() function outside of the class declaration. This isn’t necessary, but new programmers typically stumble when trying to do this for the first time due to the syntax, so an example is instructive. Each templated member function defined outside the class declaration needs its own template declaration. Also, note that the name of the templated array class is Array, not Array – Array would refer to a non-templated version of a class named Array, unless Array is used inside of the class. For example, the copy constructor and copy-assignment operator used Array rather than Array. When the class name is used without template arguments inside of the class, the arguments are the same as the ones of the current instantiation.
Template classes are instanced in the same way template functions are – the compiler stencils out a copy upon demand, with the template parameter replaced by the actual data type the user needs, and then compiles the copy. If you don’t ever use a template class, the compiler won’t even compile it.
Template classes in the standard library
Now that we’ve covered template classes, you should understand what std::vector means now – std::vector is actually a template class, and int is the type parameter to the template! The standard library is full of predefined template classes available for your use. We’ll cover these in later chapters.
Splitting up template classes
A template is not a class or a function – it is a stencil used to create classes or functions. As such, it does not work in quite the same way as normal functions or classes. In most cases, this isn’t much of a issue. However, there is one area that commonly causes problems for developers.
With non-template classes, the common procedure is to put the class definition in a header file, and the member function definitions in a similarly named code file. In this way, the member function definitions are compiled as a separate project file. However, with templates, this does not work. Consider the following:
If you feel that putting the Array.cpp code into the Array.h header makes the header too long/messy, an alternative is to move the contents of Array.cpp to a new file named Array.inl (.inl stands for inline), and then include Array.inl at the bottom of the Array.h header (inside the header guard). That yields the same result as putting all the code in the header, but helps keep things a little more organized.
Tip
If you use the .inl method and then get a compiler error about duplicate definitions, your compiler is most likely compiling the .inl file as part of the project as if it were a code file. This results in the contents of the .inl getting compiled twice: once when your compiler compiles the .inl, and once when the .cpp file that includes the .inl gets compiled. If the .inl file contains any non-inline functions (or variables), then we will run afoul of the one definition rule. If this happens, you’ll need to exclude the .inl file from being compiled as part of the build.
Excluding the .inl from the build can usually be done by right clicking on the .inl file in the project view, and then choosing properties. The setting will be somewhere in there. In Visual Studio, set “Exclude From Build” to “Yes”. In Code::Blocks, uncheck “Compile file” and “Link file”.
Other solutions involve #including .cpp files, but we don’t recommend these because of the non-standard usage of #include.
Another alternative is to use a three-file approach. The template class definition goes in the header. The template class member functions goes in the code file. Then you add a third file, which contains all of the instantiated classes you need:
templates.cpp:
// Ensure the full Array template definition can be seen
#include "Array.h"
#include "Array.cpp" // we're breaking best practices here, but only in this one place
// #include other .h and .cpp template definitions you need here
template class Array<int>; // Explicitly instantiate template ArrayThe “template class” command causes the compiler to explicitly instantiate the template class. In the above case, the compiler will stencil out definitions for Array and Array inside of templates.cpp. Other code files that want to use these types can include Array.h (to satisfy the compiler), and the linker will link in these explicit type definitions from template.cpp.
This method may be more efficient (depending on how your compiler and linker handle templates and duplicate definitions), but requires maintaining the templates.cpp file for each program.
19.2 — Template non-type parameters
Non-type parameters
A template non-type parameter is a template parameter where the type of the parameter is predefined and is substituted for a constexpr value passed in as an argument.
One noteworthy thing about the above example is that we do not have to dynamically allocate the m_array member variable! This is because for any given instance of the StaticArray class, size must be constexpr. For example, if you instantiate a StaticArray
This functionality is used by the standard library class std::array. When you allocate a std::array
Note that if you try to instantiate a template non-type parameter with a non-constexpr value, it will not work:
template <int size>
class Foo
{
};
int main()
{
int x{ 4 }; // x is non-constexpr
Foo<x> f; // error: the template non-type argument must be constexpr
return 0;
}
In such a case, your compiler will issue an error.
19.3 — Function template specialization
Now, let’s say we want double values (and only double values) to output in scientific notation. To do so, we can use a function template specialization (sometimes called a full or explicit function template specialization) to create a specialized version of the print() function for type double. This is extremely simple: simply define the specialized function (if the function is a member function, do so outside of the class definition), replacing the template type with the specific type you wish to redefine the function for. Here is our specialized print() function for doubles:
template <>
void Storage<double>::print()
{
std::cout << std::scientific << m_value << '\n';
}
When the compiler goes to instantiate Storage::print(), it will see we’ve already explicitly defined that function, and it will use the one we’ve defined instead of stenciling out a version from the generic templated class.
The template <> tells the compiler that this is a template function, but that there are no template parameters (since in this case, we’re explicitly specifying all of the types). Some compilers may allow you to omit this, but it’s correct to include it.
As a result, when we rerun the above program, it will print:
5
6.700000e+000
Another example
Fortunately, we can fix this problem using template specialization. Instead of doing a pointer copy, we’d really like our constructor to make a copy of the input string. So let’s write a specialized constructor for datatype char* that does exactly that:
template <>
Storage<char*>::Storage(char* const value)
{
if (!value)
return;
// Figure out how long the string in value is
int length { 0 };
while (value[length] != '\0')
++length;
++length; // +1 to account for null terminator
// Allocate memory to hold the value string
m_value = new char[length];
// Copy the actual value string into the m_value memory we just allocated
for (int count=0; count < length; ++count)
m_value[count] = value[count];
}
However, this class now has a memory leak for type char*, because m_value will not be deleted when a Storage
template <>
Storage<char*>::~Storage()
{
delete[] m_value;
}
That way, when variables of type Storage
However, perhaps surprisingly, the above specialized destructor won’t compile. This is because a specialized function must specialize an explicit function (not one that the compiler is providing a default for). Since we didn’t define a destructor in Storage, the compiler is providing a default destructor for us, and thus we can’t provide a specialization. To solve this issue, we must explicitly define a destructor in Storage. Here’s the full code:
template <typename T>
class Storage
{
private:
T m_value{};
public:
Storage(T value)
: m_value{ value }
{
}
~Storage() {}; // need an explicitly defined destructor to specialize
void print()
{
std::cout << m_value << '\n';
}
};
19.4 — Class template specialization
As it turns out, using some basic bit logic, it’s possible to compress all 8 bools into a single byte, eliminating the wasted space altogether.
Fortunately, C++ provides us a better method: class template specialization.
Class template specialization
// Requires the Storage8 type definition from above
#include First, note that we start off with template<>. The template keyword tells the compiler that what follows is templated, and the empty angle braces means that there aren’t any template parameters. In this case, there aren’t any template parameters because we’re replacing the only template parameter (T) with a specific type (bool).
Next, we add to the class name to denote that we’re specializing a bool version of class Storage8.
Note that this specialization class utilizes a std::uint8_t (1 byte) instead of an array of 8 bools (8 bytes).
19.5 — Partial template specialization
This lesson and the next are optional reading for those desiring a deeper knowledge of C++ templates. Partial template specialization is not used all that often (but can be useful in specific cases).
This program will compile, execute, and produce the following value (or one similar):
H e l l o , w o r l d !
For non-char types, it makes sense to put a space between each array element, so they don’t run together. However, with a char type, it makes more sense to print everything run together as a C-style string, which our print() function doesn’t do.
So how can we fix this?
Template specialization to the rescue?
Although we could make a copy of print() that handles StaticArray
Obviously full template specialization is too restrictive a solution here. The solution we are looking for is partial template specialization.
Partial template specialization
Here’s our example with an overloaded print function that takes a partially specialized StaticArray:
// overload of print() function for partially specialized StaticArrayAs you can see here, we’ve explicitly declared that this function will only work for StaticArray of type char, but size is still a templated expression parameter, so it will work for char arrays of any size. That’s all there is to it!
Partial template specialization can only be used with classes, not template functions (functions must be fully specialized). Our void print(StaticArray
Partial template specialization for member functions
You might start off trying to write that code like this:
print() is now a member function of class StaticArray
// Doesn't work
template <int size>
void StaticArray<double, size>::print()
{
for (int i{ 0 }; i < size; ++i)
std::cout << std::scientific << m_array[i] << ' ';
std::cout << '\n';
}
Unfortunately, this doesn’t work, because we’re trying to partially specialize a function, which is disallowed.
So how do we get around this? One obvious way is to partially specialize the entire class:
This prints:
0 1 2 3 4 5
4.000000e+00 4.100000e+00 4.200000e+00 4.300000e+00
While it works, this isn’t a great solution, because we had to duplicate a lot of code from StaticArray
If only there were some way to reuse the code in StaticArray
You might start off trying to write that code like this:
template <int size> // size is the expression parameter
class StaticArray<double, size>: public StaticArray<T, size>
But this doesn’t work, because we’ve used T without defining it. There is no syntax that allows us to inherit in such a manner.
As an aside…
Even if we were able to define T as a type template parameter, when StaticArray
Fortunately, there’s a workaround, by using a common base class:
#include This prints the same as above, but has significantly less duplicated code.
19.6 — Partial template specialization for pointers
Fortunately, partial template specialization offers us a convenient solution. In this case, we’ll use class partial template specialization to define a special version of the Storage class that works for pointer values. This class is considered partially specialized because we’re telling the compiler that it’s only for use with pointer types, even though we haven’t specified the underlying type exactly.
#include class from the example above here
template <typename T>
class Storage<T*> // this is a partial-specialization of Storage that works with pointer types
{
private:
T* m_value;
public:
Storage(T* value) // for pointer type T
: m_value { new T { *value } } // this copies a single value, not an array
{
}
~Storage()
{
delete m_value; // so we use scalar delete here, not array delete
}
void print() const
{
std::cout << *m_value << '\n';
}
};
And an example of this working:
int main()
{
// Declare a non-pointer Storage to show it works
Storage<int> myint { 5 };
myint.print();
// Declare a pointer Storage to show it works
int x { 7 };
Storage<int*> myintptr { &x };
// Let's show that myintptr is separate from x.
// If we change x, myintptr should not change
x = 9;
myintptr.print();
return 0;
}
This prints the value:
5
7
It’s worth noting that because this partially specialized Storage class only allocates a single value, for C-style strings, only the first character will be copied. If we want to store entire C-style strings, we can do a full specialization for type char*. A fully specialized class or function will take precedence over a partially specialized version.
To fully specialize Storage for type char*, we have two options. We can either fully specialize the Storage class for char*, or we can fully specialize each of the individual functions we’ll need (the constructor, destructor, and print function) for type char*. In this case, the Storage class has 3 member functions, and we’ll need to specialize them all – so we might as well just specialize the whole class.
Using partial template class specialization to create separate pointer and non-pointer implementations of a class is extremely useful when you want a class to handle both differently, but in a way that’s completely transparent to the end-user.
19.x — Chapter 19 comprehensive quiz
Templates allow us to write functions or classes using placeholder types, so that we can stencil out identical versions of the function or class using different types. A function or class that has been instantiated is called a function or class instance.
Splitting up template class definition and member function definitions doesn’t work like normal classes – you can’t put your class definition in a header and member function definitions in a .cpp file. It’s usually best to keep all of them in a header file, with the member function definitions underneath the class.
Template specialization can be used when we want to override the default behavior from the templated function or class for a specific type. If all types are overridden, this is called full specialization. Classes also support partial specialization, where only some of the templated parameters are specialized. Functions can not be partially specialized.
Chapter 20_Exceptions
20.1 — The need for exceptions
When return codes fail
Exceptions
Exception handling provides a mechanism to decouple handling of errors or other exceptional circumstances from the typical control flow of your code. This allows more freedom to handle errors when and how ever is most useful for a given situation, alleviating most (if not all) of the messiness that return codes cause.
In the next lesson, we’ll take a look at how exceptions work in C++.
20.2 — Basic exception handling
Exceptions in C++ are implemented using three keywords that work in conjunction with each other: throw, try, and catch.
Throwing exceptions
In C++, a throw statement is used to signal that an exception or error case has occurred (think of throwing a penalty flag). Signaling that an exception has occurred is also commonly called raising an exception.
To use a throw statement, simply use the throw keyword, followed by a value of any data type you wish to use to signal that an error has occurred. Typically, this value will be an error code, a description of the problem, or a custom exception class.
Here are some examples:
throw -1; // throw a literal integer value
throw ENUM_INVALID_INDEX; // throw an enum value
throw "Can not take square root of negative number"; // throw a literal C-style (const char*) string
throw dX; // throw a double variable that was previously defined
throw MyException("Fatal Error"); // Throw an object of class MyException
Each of these statements acts as a signal that some kind of problem that needs to be handled has occurred.
Looking for exceptions
In C++, we use the try keyword to define a block of statements (called a try block). The try block acts as an observer, looking for any exceptions that are thrown by any of the statements within the try block.
Here’s an example of a try block:
try
{
// Statements that may throw exceptions you want to handle go here
throw -1; // here's a trivial throw statement
}
Note that the try block doesn’t define HOW we’re going to handle the exception. It merely tells the program, “Hey, if any of the statements inside this try block throws an exception, grab it!”.
Handling exceptions
Actually handling exceptions is the job of the catch block(s). The catch keyword is used to define a block of code (called a catch block) that handles exceptions for a single data type.
Here’s an example of a catch block that will catch integer exceptions:
catch (int x)
{
// Handle an exception of type int here
std::cerr << "We caught an int exception with value" << x << '\n';
}
Once an exception has been caught by the try block and routed to a catch block for handling, the exception is considered handled, and execution will resume as normal after the catch block.
Catch parameters work just like function parameters, with the parameter being available within the subsequent catch block. Exceptions of fundamental types can be caught by value, but exceptions of non-fundamental types should be caught by const reference to avoid making an unnecessary copy (and, in some cases, to prevent slicing).
Just like with functions, if the parameter is not going to be used in the catch block, the variable name can be omitted:
catch (double) // note: no variable name since we don't use it in the catch block below
{
// Handle exception of type double here
std::cerr << "We caught an exception of type double" << '\n';
}
This can help prevent compiler warnings about unused variables.
No type conversion is done for exceptions (so an int exception will not be converted to match a catch block with a double parameter).
Putting throw, try, and catch together
#include Running the above try/catch block would produce the following result:
We caught an int exception with value -1
Continuing on our merry way
Recapping exception handling
Exception handling is actually quite simple, and the following two paragraphs cover most of what you need to remember about it:
When an exception is raised (using throw), execution of the program immediately jumps to the nearest enclosing try block (propagating up the stack if necessary to find an enclosing try block – we’ll discuss this in more detail next lesson). If any of the catch handlers attached to the try block handle that type of exception, that handler is executed and the exception is considered handled.
If no appropriate catch handlers exist, execution of the program propagates to the next enclosing try block. If no appropriate catch handlers can be found before the end of the program, the program will fail with an exception error.
Note that the compiler will not perform implicit conversions or promotions when matching exceptions with catch blocks! For example, a char exception will not match with an int catch block. An int exception will not match a float catch block. However, casts from a derived class to one of its parent classes will be performed.
That’s really all there is to it. The rest of this chapter will be dedicated to showing examples of these principles at work.
Exceptions are handled immediately
A more realistic example
Let’s take a look at an example that’s not quite so academic:
#include If the user enters a negative number, we throw an exception of type const char. Because we’re within a try block and a matching exception handler is found, control immediately transfers to the const char exception handler. The result is:
Enter a number: -4
Error: Can not take sqrt of negative number
By now, you should be getting the basic idea behind exceptions. In the next lesson, we’ll do quite a few more examples to show how flexible exceptions are.
What catch blocks typically do
If an exception is routed to a catch block, it is considered “handled” even if the catch block is empty. However, typically you’ll want your catch blocks to do something useful. There are four common things that catch blocks do when they catch an exception:
First, catch blocks may print an error (either to the console, or a log file) and then allow the function to proceed.
Second, catch blocks may return a value or error code back to the caller.
Third, a catch block may throw another exception. Because the catch block is outside of the try block, the newly thrown exception in this case is not handled by the preceding try block – it’s handled by the next enclosing try block.
Fourth, a catch block in main() may be used to catch fatal errors and terminate the program in a clean way.
20.3 — Exceptions, functions, and stack unwinding
Throwing exceptions from a called function
One of the most useful properties of exception handling is that the throw statements do NOT have to be placed directly inside a try block. Instead, exceptions can be thrown from anywhere in a function, and those exceptions can be caught by the try block of the caller (or the caller’s caller, etc…). When an exception is caught in this manner, execution jumps from the point where the exception is thrown to the catch block handling the exception.
Key insight
Try blocks catch exceptions not only from statements within the try block, but also from functions that are called within the try block.
#include The most interesting part of the above program is that the mySqrt() function can throw an exception, but does not handle this exception itself! This essentially means mySqrt() is willing to say, “Hey, there’s a problem!”, but is unwilling to handle the problem itself. It is, in essence, delegating the responsibility for handling the exception to its caller (the equivalent of how using a return code passes the responsibility of handling an error back to a function’s caller).
At this point, some of you are probably wondering why it’s a good idea to pass errors back to the caller. Why not just make MySqrt() handle its own error? The problem is that different applications may want to handle errors in different ways. A console application may want to print a text message. A windows application may want to pop up an error dialog. In one application, this may be a fatal error, and in another application it may not be. By passing the error out of the function, each application can handle an error from mySqrt() in a way that is the most context appropriate for it! Ultimately, this keeps mySqrt() as modular as possible, and the error handling can be placed in the less-modular parts of the code.
Exception handling and stack unwinding
The process of checking each function up the call stack continues until either a handler is found, or all of the functions on the call stack have been checked and no handler can be found.
If a matching exception handler is found, then execution jumps from the point where the exception is thrown to the top of the matching catch block. This requires unwinding the stack (removing the current function from the call stack) as many times as necessary to make the function handling the exception the top function on the call stack.
If no matching exception handler is found, the stack may or may not be unwound. We will talk more about this case in the next lesson (20.4 – Uncaught exceptions and catch-all handlers).
Key insight
Unwinding the stack destroys local variables in the functions that are unwound (which is good, because it ensures their destructors execute).
Another stack unwinding example
As you can see, stack unwinding provides us with some very useful behavior – if a function does not want to handle an exception, it doesn’t have to. The exception will propagate up the stack until it finds someone who will! This allows us to decide where in the call stack is the most appropriate place to handle any errors that may occur.
In the next lesson, we’ll take a look at what happens when you don’t capture an exception, and a method to prevent that from happening.
20.4 — Uncaught exceptions and catch-all handlers
Uncaught exceptions
Warning
The call stack may or may not be unwound if an exception is unhandled.
If the stack is not unwound, local variables will not be destroyed, which may cause problems if those variables have non-trivial destructors.
As an aside…
Although it might seem strange to not unwind the stack in such a case, there is a good reason for not doing so. An unhandled exception is generally something you want to avoid at all costs. If the stack were unwound, then all of the debug information about the state of the stack that led up to the throwing of the unhandled exception would be lost! By not unwinding, we preserve that information, making it easier to determine how an unhandled exception was thrown, and fix it.
Catch-all handlers
Fortunately, C++ also provides us with a mechanism to catch all types of exceptions. This is known as a catch-all handler. A catch-all handler works just like a normal catch block, except that instead of using a specific type to catch, it uses the ellipses operator (…) as the type to catch. For this reason, the catch-all handler is also sometimes called an “ellipsis catch handler”
If you recall from lesson 12.6 – Ellipsis (and why to avoid them), ellipses were previously used to pass arguments of any type to a function. In this context, they represent exceptions of any data type. Here’s an simple example:
#include Because there is no specific exception handler for type int, the catch-all handler catches this exception. This example produces the following result:
We caught an exception of an undetermined type
The catch-all handler must be placed last in the catch block chain. This is to ensure that exceptions can be caught by exception handlers tailored to specific data types if those handlers exist.
Often, the catch-all handler block is left empty:
catch(...) {} // ignore any unanticipated exceptions
This will catch any unanticipated exceptions, ensuring that stack unwinding occurs up to this point and preventing the program from terminating, but does no specific error handling.
Using the catch-all handler to wrap main()
The downside of this approach is that if an unhandled exception does occur, stack unwinding will occur, making it harder to determine why the unhandled exception was thrown in the first place. For this reason, using a catch-all handler in main is often a good idea for production applications, but disabled (using conditional compilation directives) in debug builds.
Best practice
If your program uses exceptions, consider using a catch-all handler in main, to help ensure orderly behavior when an unhandled exception occurs. Also consider disabling the catch-all handler for debug builds, to make it easier to identify how unhandled exceptions are occurring.
20.5 — Exceptions, classes, and inheritance
Exceptions and member functions
Now if the user passes in an invalid index, the program will cause an assertion error. Unfortunately, because overloaded operators have specific requirements as to the number and type of parameter(s) they can take and return, there is no flexibility for passing back error codes or Boolean values to the caller to handle. However, since exceptions do not change the signature of a function, they can be put to great use here. Here’s an example:
int& IntArray::operator[](const int index)
{
if (index < 0 || index >= getLength())
throw index;
return m_data[index];
}
Now, if the user passes in an invalid index, operator[] will throw an int exception.
When constructors fail
However, the class’s destructor is never called (because the object never finished construction). Because the destructor never executes, you can’t rely on said destructor to clean up any resources that have already been allocated.
Fortunately, there is a better way. Taking advantage of the fact that class members are destructed even if the constructor fails, if you do the resource allocations inside the members of the class (rather than in the constructor itself), then those members can clean up after themselves when they are destructed.
Here’s an example:
#include This prints:
Member allocated some resources
Member cleaned up
Oops
In the above program, when class A throws an exception, all of the members of A are destructed. m_member’s destructor is called, providing an opportunity to clean up any resources that it allocated.
This is part of the reason that RAII (covered in lesson 13.9 – Destructors) is advocated so highly – even in exceptional circumstances, classes that implement RAII are able to clean up after themselves.
However, creating a custom class like Member to manage a resource allocation isn’t efficient. Fortunately, the C++ standard library comes with RAII-compliant classes to manage common resource types, such as files (std::fstream, covered in lesson 23.6 – Basic file I/O) and dynamic memory (std::unique_ptr and the other smart pointers, covered in M.1 – Introduction to smart pointers and move semantics).
For example, instead of this:
class Foo
private:
int* ptr; // Foo will handle allocation/deallocation
Do this:
class Foo
private:
std::unique_ptr<int> ptr; // std::unique_ptr will handle allocation/deallocation
In the former case, if Foo’s constructor were to fail after ptr had allocated its dynamic memory, Foo would be responsible for cleanup, which can be challenging. In the latter case, if Foo’s constructor were to fail after ptr has allocated its dynamic memory, ptr’s destructor would execute and return that memory to the system. Foo doesn’t have to do any explicit cleanup when resource handling is delegated to RAII-compliant members!
Exception classes
One way to solve this problem is to use exception classes. An exception class is just a normal class that is designed specifically to be thrown as an exception. Let’s design a simple exception class to be used with our IntArray class:
#include Note that exception handlers should catch class exception objects by reference instead of by value. This prevents the compiler from making a copy of the exception, which can be expensive when the exception is a class object, and prevents object slicing when dealing with derived exception classes (which we’ll talk about in a moment). Catching exceptions by pointer should generally be avoided unless you have a specific reason to do so.
Exceptions and inheritance
Since it’s possible to throw classes as exceptions, and classes can be derived from other classes, we need to consider what happens when we use inherited classes as exceptions. As it turns out, exception handlers will not only match classes of a specific type, they’ll also match classes derived from that specific type as well! Consider the following example:
In order to make this example work as expected, we need to flip the order of the catch blocks:
#include This way, the Derived handler will get first shot at catching objects of type Derived (before the handler for Base can). Objects of type Base will not match the Derived handler (Derived is-a Base, but Base is not a Derived), and thus will “fall through” to the Base handler.
Rule
Handlers for derived exception classes should be listed before those for base classes.
std::exception
The good news is that all of these exception classes are derived from a single class called std::exception (defined in the header). std::exception is a small interface class designed to serve as a base class to any exception thrown by the C++ standard library.
Thanks to std::exception, we can set up an exception handler to catch exceptions of type std::exception, and we’ll end up catching std::exception and all of the derived exceptions together in one place. Easy!
#include On the author’s machine, the above program prints:
Standard exception: string too long
The above example should be pretty straightforward. The one thing worth noting is that std::exception has a virtual member function named what() that returns a C-style string description of the exception. Most derived classes override the what() function to change the message. Note that this string is meant to be used for descriptive text only – do not use it for comparisons, as it is not guaranteed to be the same across compilers.
Sometimes we’ll want to handle a specific type of exception differently. In this case, we can add a handler for that specific type, and let all the others “fall through” to the base handler. Consider:
try
{
// code using standard library goes here
}
// This handler will catch std::length_error (and any exceptions derived from it) here
catch (const std::length_error& exception)
{
std::cerr << "You ran out of memory!" << '\n';
}
// This handler will catch std::exception (and any exception derived from it) that fall
// through here
catch (const std::exception& exception)
{
std::cerr << "Standard exception: " << exception.what() << '\n';
}
Using the standard exceptions directly
Nothing throws a std::exception directly, and neither should you. However, you should feel free to throw the other standard exception classes in the standard library if they adequately represent your needs. You can find a list of all the standard exceptions on cppreference.
std::runtime_error (included as part of the stdexcept header) is a popular choice, because it has a generic name, and its constructor takes a customizable message:
#include This prints:
Standard exception: Bad things happened
Deriving your own classes from std::exception or std::runtime_error
You can, of course, derive your own classes from std::exception, and override the virtual what() const member function. Here’s the same program as above, with ArrayException derived from std::exception:
Note that virtual function what() has specifier noexcept (which means the function promises not to throw exceptions itself). Therefore, our override should also have specifier noexcept.
Because std::runtime_error already has string handling capabilities, it’s also a popular base class for derived exception classes. Here’s the same example derived from std::runtime_error instead:
20.6 — Rethrowing exceptions
Throwing a new exception
One obvious solution is to throw a new exception.
int getIntValueFromDatabase(Database* d, std::string table, std::string key)
{
assert(d);
try
{
return d->getIntValue(table, key); // throws int exception on failure
}
catch (int exception)
{
// Write an error to some global logfile
g_log.logError("getIntValueFromDatabase failed");
throw 'q'; // throw char exception 'q' up the stack to be handled by caller of getIntValueFromDatabase()
}
}
In the example above, the program catches the int exception from getIntValue(), logs the error, and then throws a new exception with char value ‘q’. Although it may seem weird to throw an exception from a catch block, this is allowed. Remember, only exceptions thrown within a try block are eligible to be caught. This means that an exception thrown within a catch block will not be caught by the catch block it’s in. Instead, it will be propagated up the stack to the caller.
The exception thrown from the catch block can be an exception of any type – it doesn’t need to be the same type as the exception that was just caught.
Rethrowing an exception (the wrong way)
But significantly, consider what happens in the following case:
int getIntValueFromDatabase(Database* d, std::string table, std::string key)
{
assert(d);
try
{
return d->getIntValue(table, key); // throws Derived exception on failure
}
catch (Base& exception)
{
// Write an error to some global logfile
g_log.logError("getIntValueFromDatabase failed");
throw exception; // Danger: this throws a Base object, not a Derived object
}
}
In this case, getIntValue() throws a Derived object, but the catch block is catching a Base reference. This is fine, as we know we can have a Base reference to a Derived object. However, when we throw an exception, the thrown exception is copy-initialized from variable exception. Variable exception has type Base, so the copy-initialized exception also has type Base (not Derived!). In other words, our Derived object has been sliced!
You can see this in the following program:
#include This prints:
Caught Base b, which is actually a Derived
Caught Base b, which is actually a Base
The fact that the second line indicates that Base is actually a Base rather than a Derived proves that the Derived object was sliced.
Rethrowing an exception (the right way)
Fortunately, C++ provides a way to rethrow the exact same exception as the one that was just caught. To do so, simply use the throw keyword from within the catch block (with no associated variable), like so:
#include This prints:
Caught Base b, which is actually a Derived
Caught Base b, which is actually a Derived
This throw keyword that doesn’t appear to throw anything in particular actually re-throws the exact same exception that was just caught. No copies are made, meaning we don’t have to worry about performance killing copies or slicing.
If rethrowing an exception is required, this method should be preferred over the alternatives.
Rule
When rethrowing the same exception, use the throw keyword by itself
20.7 — Function try blocks
Function try blocks are designed to allow you to establish an exception handler around the body of an entire function, rather than around a block of code.
The syntax for function try blocks is a little hard to describe, so we’ll show by example:
#include When this program is run, it produces the output:
Exception caught
Oops
Let’s examine this program in more detail.
First, note the addition of the “try” keyword before the member initializer list. This indicates that everything after that point (until the end of the function) should be considered inside of the try block.
Second, note that the associated catch block is at the same level of indentation as the entire function. Any exception thrown between the try keyword and the end of the function body will be eligible to be caught here.
Limitations on function catch blocks
The following table summarizes the limitations and behavior of function-level catch blocks:
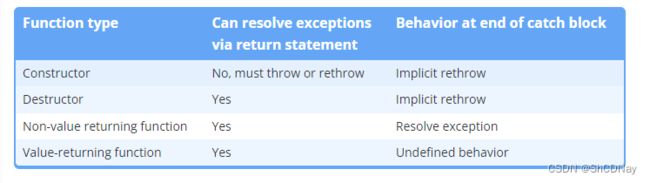
Because such behavior at the end of the catch block varies dramatically depending on the type of function (and includes undefined behavior in the case of value-returning functions), we recommend never letting control reach the end of the catch block, and always explicitly throwing, rethrowing, or returning.
Best practice
Avoid letting control reach the end of a function-level catch block. Instead, explicitly throw, rethrow, or return.
Although function level try blocks can be used with non-member functions as well, they typically aren’t because there’s rarely a case where this would be needed. They are almost exclusively used with constructors!
Function try blocks can catch both base and the current class exceptions
In the above example, if either A or B’s constructor throws an exception, it will be caught by the try block around B’s constructor.
We can see that in the following example, where we’re throwing an exception from class B instead of class A:
We get the same output:
Exception caught
Oops
Don’t use function try to clean up resources
When construction of an object fails, the destructor of the class is not called. Consequently, you may be tempted to use a function try block as a way to clean up a class that had partially allocated resources before failing. However, referring to members of the failed object is considered undefined behavior since the object is “dead” before the catch block executes. This means that you can’t use function try to clean up after a class. If you want to clean up after a class, follow the standard rules for cleaning up classes that throw exceptions (see the “When constructors fail” subsection of lesson 20.5 – Exceptions, classes, and inheritance).
Function try is useful primarily for either logging failures before passing the exception up the stack, or for changing the type of exception thrown.
20.8 — Exception dangers and downsides
As with almost everything that has benefits, there are some potential downsides to exceptions as well. This article is not meant to be comprehensive, but just to point out some of the major issues that should be considered when using exceptions (or deciding whether to use them).
Cleaning up resources
The second way is to use a local variable of a class that knows how to cleanup itself when it goes out of scope (often called a “smart pointer”). The standard library provides a class called std::unique_ptr that can be used for this purpose. std::unique_ptr is a template class that holds a pointer, and deallocates it when it goes out of scope.
#include We’ll talk more about smart pointers in the next chapter.
Exceptions and destructors
Unlike constructors, where throwing exceptions can be a useful way to indicate that object creation did not succeed, exceptions should never be thrown in destructors.
The problem occurs when an exception is thrown from a destructor during the stack unwinding process. If that happens, the compiler is put in a situation where it doesn’t know whether to continue the stack unwinding process or handle the new exception. The end result is that your program will be terminated immediately.
Consequently, the best course of action is just to abstain from using exceptions in destructors altogether. Write a message to a log file instead.
Rule
Destructors should not throw exceptions.
Performance concerns
As a note, some modern computer architectures support an exception model called zero-cost exceptions. Zero-cost exceptions, if supported, have no additional runtime cost in the non-error case (which is the case we most care about performance). However, they incur an even larger penalty in the case where an exception is found.
So when should I use exceptions?
Exception handling is best used when all of the following are true:
- The error being handled is likely to occur only infrequently.
- The error is serious and execution could not continue otherwise.
- The error cannot be handled at the place where it occurs.
- There isn’t a good alternative way to return an error code back to the caller.
As an example, let’s consider the case where you’ve written a function that expects the user to pass in the name of a file on disk. Your function will open this file, read some data, close the file, and pass back some result to the caller. Now, let’s say the user passes in the name of a file that doesn’t exist, or a null string. Is this a good candidate for an exception?
In this case, the first two bullets above are trivially met – this isn’t something that’s going to happen often, and your function can’t calculate a result when it doesn’t have any data to work with. The function can’t handle the error either – it’s not the job of the function to re-prompt the user for a new filename, and that might not even be appropriate, depending on how your program is designed. The fourth bullet is the key – is there a good alternative way to return an error code back to the caller? It depends on the details of your program. If so (e.g. you can return a null pointer, or a status code to indicate failure), that’s probably the better choice. If not, then an exception would be reasonable.
20.9 — Exception specifications and noexcept
Looking at a typical function declaration, it is not possible to determine whether a function might throw an exception or not:
int doSomething(); // can this function throw an exception or not?
In the above example, can the doSomething function throw an exception? It’s not clear. But the answer is important in some contexts. If doSomething could throw an exception, then it’s not safe to call this function from a destructor, or any other place where a thrown exception is undesirable.
While comments may help enumerate whether a function throws exceptions or not (and if so, what kind of exceptions), documentation can grow stale and there is no compiler enforcement for comments.
Exception specifications are a language mechanism that was originally designed to document what kind of exceptions a function might throw as part of a function specification. While most of the exception specifications have now been deprecated or removed, one useful exception specification was added as a replacement, which we’ll cover in this lesson.
The noexcept specifier
In C++, all functions are classified as either non-throwing or potentially throwing. A non-throwing function is one that promises not to throw exceptions that are visible to the caller. A potentially throwing function may throw exceptions that are visible to the caller.
To define a function as non-throwing, we can use the noexcept specifier. To do so, we use the noexcept keyword in the function declaration, placed to the right of the function parameter list:
void doSomething() noexcept; // this function is specified as non-throwing
Note that noexcept doesn’t actually prevent the function from throwing exceptions or calling other functions that are potentially throwing. This is allowed so long as the noexcept function catches and handles those exceptions internally, and those exceptions do not exit the noexcept function.
If an unhandled exception would exit a noexcept function, std::terminate will be called (even if there is an exception handler that would otherwise handle such an exception somewhere up the stack). And if std::terminate is called from inside a noexcept function, stack unwinding may or may not occur (depending on implementation and optimizations), which means your objects may or may not be destructed properly prior to termination.
Key insight
The promise that a noexcept function makes to not throw exceptions that are visible to the caller is a contractual promise, not a promise enforced by the compiler. So while calling a noexcept function should be safe, any exception handling bugs in the noexcept function that cause the contract to be broken will result in termination of the program! This shouldn’t happen, but neither should bugs.
For this reason, it’s best that noexcept functions don’t mess with exceptions at all, or call potentially throwing functions that could raise an exception. A noexcept function can’t have an exception handling bug if no exceptions can possibly be raised in the first place!
Much like functions that differ only in their return values can not be overloaded, functions differing only in their exception specification can not be overloaded.
Illustrating the behavior of noexcept functions and exceptions
The noexcept specifier with a Boolean parameter
The noexcept specifier has an optional Boolean parameter. noexcept(true) is equivalent to noexcept, meaning the function is non-throwing. noexcept(false) means the function is potentially throwing. These parameters are typically only used in template functions, so that a template function can be dynamically created as non-throwing or potentially throwing based on some parameterized value.
Which functions are non-throwing and potentially-throwing
Functions that are implicitly non-throwing:
-
Destructors
Functions that are non-throwing by default for implicitly-declared or defaulted functions: -
Constructors: default, copy, move
-
Assignments: copy, move
-
Comparison operators (as of C++20)
However, if any of these functions call (explicitly or implicitly) another function which is potentially throwing, then the listed function will be treated as potentially throwing as well. For example, if a class has a data member with a potentially throwing constructor, then the class’s constructors will be treated as potentially throwing as well. As another example, if a copy assignment operator calls a potentially throwing assignment operator, then the copy assignment will be potentially throwing as well.
Functions that are potentially throwing (if not implicitly-declared or defaulted):
- Normal functions
- User-defined constructors
- User-defined operators
The noexcept operator
The noexcept operator can also be used inside functions. It takes an expression as an argument, and returns true or false if the compiler thinks it will throw an exception or not. The noexcept operator is checked statically at compile-time, and doesn’t actually evaluate the input expression.
void foo() {throw -1;}
void boo() {};
void goo() noexcept {};
struct S{};
constexpr bool b1{ noexcept(5 + 3) }; // true; ints are non-throwing
constexpr bool b2{ noexcept(foo()) }; // false; foo() throws an exception
constexpr bool b3{ noexcept(boo()) }; // false; boo() is implicitly noexcept(false)
constexpr bool b4{ noexcept(goo()) }; // true; goo() is explicitly noexcept(true)
constexpr bool b5{ noexcept(S{}) }; // true; a struct's default constructor is noexcept by default
The noexcept operator can be used to conditionally execute code depending on whether it is potentially throwing or not. This is required to fulfill certain exception safety guarantees, which we’ll talk about in the next section.
Exception safety guarantees
An exception safety guarantee is a contractual guideline about how functions or classes will behave in the event an exception occurs. There are four levels of exception safety:
- No guarantee – There are no guarantees about what will happen if an exception is thrown (e.g. a class may be left in an unusable state)
- Basic guarantee – If an exception is thrown, no memory will be leaked and the object is still usable, but the program may be left in a modified state.
- Strong guarantee – If an exception is thrown, no memory will be leaked and the program state will not be changed. This means the function must either completely succeed or have no side effects if it fails. This is easy if the failure happens before anything is modified in the first place, but can also be achieved by rolling back any changes so the program is returned to the pre-failure state.
- No throw / No fail – The function will always succeed (no-fail) or fail without throwing an exception (no-throw).
The no-throw guarantee: if a function fails, then it won’t throw an exception. Examples of code that should be no-throw:
- destructors and memory deallocation/cleanup functions
- functions that higher-level no-throw functions need to call
The no-fail guarantee: a function will always succeed in what it tries to do (and thus never has a need to throw an exception, thus, no-fail is a slightly stronger form of no-throw). Examples of code that should be no-fail:
- move constructors and move assignment (move semantics, covered in chapter M)
- swap functions
- clear/erase/reset functions on containers
- operations on std::unique_ptr (also covered in chapter M)
- functions that higher-level no-fail functions need to call
When to use noexcept
There are a few good reasons to mark functions a non-throwing:
- Non-throwing functions can be safely called from functions that are not exception-safe, such as destructors
- Functions that are noexcept can enable the compiler to perform some optimizations that would not otherwise be available. Because a noexcept function cannot throw an exception outside the function, the compiler doesn’t have to worry about keeping the runtime stack in an unwindable state, which can allow it to produce faster code.
- There are significant cases where knowing a function is noexcept allows us to produce more efficient implementations in our own code: the standard library containers (such as std::vector) are noexcept aware and will use the noexcept operator to determine whether to use move semantics (faster) or copy semantics (slower) in some places. We cover move semantics in chapter M, and this optimization in lesson M.5 – std::move_if_noexcept.
The standard library’s policy is to use noexcept only on functions that must not throw or fail.Functions that are potentially throwing but do not actually throw exceptions (due to implementation) typically are not marked as noexcept.
For your code, there are two places that make sense to use noexcept:
- On constructors and overloaded assignment operators that are no-throw (to take advantage of optimizations).
- On functions for which you want to express a no-throw or no-fail guarantee (e.g. to document that they can be safely called from destructors or other noexcept functions)
Best practice
Make constructors and overloaded assignment operators noexcept when you can. Use noexcept on other functions to express a no-fail or no-throw guarantee.
Best practice
If you are uncertain whether a function should have a no-fail/no-throw guarantee, error on the side of caution and do not mark it with noexcept. Reversing a decision to use noexcept violates an interface commitment to the user about the behavior of the function, and may break existing code. Making guarantees stronger by later adding noexcept to a function that was not originally noexcept is considered safe.
Dynamic exception specifications
Optional reading
Before C++11, and until C++17, dynamic exception specifications were used in place of noexcept. The dynamic exception specifications syntax uses the throw keyword to list which exception types a function might directly or indirectly throw:
int doSomething() throw(); // does not throw exceptions
int doSomething() throw(std::out_of_range, int*); // may throw either std::out_of_range or a pointer to an integer
int doSomething() throw(...); // may throw anything
Due to factors such as incomplete compiler implementations, some incompatibility with template functions, common misunderstandings about how they worked, and the fact that the standard library mostly didn’t use them, the dynamic exception specifications were deprecated in C++11 and removed from the language in C++17 and C++20. See this paper for more context.
20.x — Chapter 20 comprehensive quiz
Chapter review
Exception handling provides a mechanism to decouple handling of errors or other exceptional circumstances from the typical control flow of your code. This allows more freedom to handle errors when and how ever is most useful for a given situation, alleviating many (if not all) of the messiness that return codes cause.
Catch blocks can be configured to catch exceptions of a particular data type, or a catch-all handler can be set up by using the ellipses (…). A catch block catching a base class reference will also catch exceptions of a derived class. All of the exceptions thrown by the standard library are derived from the std::exception class (which lives in the exception header), so catching a std::exception by reference will catch all standard library exceptions. The what() member function can be used to determine what kind of std::exception was thrown.
You should never throw an exception from a destructor.
The noexcept exception specifier can be used to denote that a function is no-throw/no-fail.
Finally, exception handling does have a cost. In most cases, code using exceptions will run slightly slower, and the cost of handling an exception is very high. You should only use exceptions to handle exceptional circumstances, not for normal error handling cases (e.g. invalid input).
Chapter M_Move Semantics and Smart Pointers
M.1 — Introduction to smart pointers and move semantics
At heart, these kinds of issues occur because pointer variables have no inherent mechanism to clean up after themselves.
Smart pointer classes to the rescue?
One of the best things about classes is that they contain destructors that automatically get executed when an object of the class goes out of scope. So if you allocate (or acquire) memory in your constructor, you can deallocate it in your destructor, and be guaranteed that the memory will be deallocated when the class object is destroyed (regardless of whether it goes out of scope, gets explicitly deleted, etc…). This is at the heart of the RAII programming paradigm that we talked about in lesson 13.9 – Destructors.
So can we use a class to help us manage and clean up our pointers? We can!
A Smart pointer is a composition class that is designed to manage dynamically allocated memory and ensure that memory gets deleted when the smart pointer object goes out of scope. (Relatedly, built-in pointers are sometimes called “dumb pointers” because they can’t clean up after themselves).
Note that even in the case where the user enters zero and the function terminates early, the Resource is still properly deallocated.
Because the ptr variable is a local variable, ptr will be destroyed when the function terminates (regardless of how it terminates). And because the Auto_ptr1 destructor will clean up the Resource, we are assured that the Resource will be properly cleaned up.
A critical flaw
int main()
{
Auto_ptr1<Resource> res1(new Resource());
Auto_ptr1<Resource> res2(res1); // Alternatively, don't initialize res2 and then assign res2 = res1;
return 0;
}
This program prints:
Resource acquired
Resource destroyed
Resource destroyed
Very likely (but not necessarily) your program will crash at this point. See the problem now? Because we haven’t supplied a copy constructor or an assignment operator, C++ provides one for us. And the functions it provides do shallow copies. So when we initialize res2 with res1, both Auto_ptr1 variables are pointed at the same Resource. When res2 goes out of the scope, it deletes the resource, leaving res1 with a dangling pointer. When res1 goes to delete its (already deleted) Resource, crash!
You’d run into a similar problem with a function like this:
void passByValue(Auto_ptr1<Resource> res)
{
}
int main()
{
Auto_ptr1<Resource> res1(new Resource());
passByValue(res1);
return 0;
}
In this program, res1 will be copied by value into passByValue’s parameter res, leading to duplication of the Resource pointer. Crash!
So clearly this isn’t good. How can we address this?
Well, one thing we could do would be to explicitly define and delete the copy constructor and assignment operator, thereby preventing any copies from being made in the first place. That would prevent the pass by value case (which is good, we probably shouldn’t be passing these by value anyway).
But then how would we return an Auto_ptr1 from a function back to the caller?
??? generateResource()
{
Resource* r{ new Resource() };
return Auto_ptr1(r);
}
Plus assigning or initializing a dumb pointer doesn’t copy the object being pointed to, so why would we expect smart pointers to behave differently?
What do we do?
Move semantics
What if, instead of having our copy constructor and assignment operator copy the pointer (“copy semantics”), we instead transfer/move ownership of the pointer from the source to the destination object? This is the core idea behind move semantics. Move semantics means the class will transfer ownership of the object rather than making a copy.
A reminder
Deleting a nullptr is okay, as it does nothing.
std::auto_ptr, and why it was a bad idea
Now would be an appropriate time to talk about std::auto_ptr. std::auto_ptr, introduced in C++98 and removed in C++17, was C++’s first attempt at a standardized smart pointer. std::auto_ptr opted to implement move semantics just like the Auto_ptr2 class does.
However, std::auto_ptr (and our Auto_ptr2 class) has a number of problems that makes using it dangerous.
First, because std::auto_ptr implements move semantics through the copy constructor and assignment operator, passing a std::auto_ptr by value to a function will cause your resource to get moved to the function parameter (and be destroyed at the end of the function when the function parameters go out of scope). Then when you go to access your auto_ptr argument from the caller (not realizing it was transferred and deleted), you’re suddenly dereferencing a null pointer. Crash!
Second, std::auto_ptr always deletes its contents using non-array delete. This means auto_ptr won’t work correctly with dynamically allocated arrays, because it uses the wrong kind of deallocation. Worse, it won’t prevent you from passing it a dynamic array, which it will then mismanage, leading to memory leaks.
Finally, auto_ptr doesn’t play nice with a lot of the other classes in the standard library, including most of the containers and algorithms. This occurs because those standard library classes assume that when they copy an item, it actually makes a copy, not a move.
Because of the above mentioned shortcomings, std::auto_ptr has been deprecated in C++11 and removed in C++17.
Moving forward
The core problem with the design of std::auto_ptr is that prior to C++11, the C++ language simply had no mechanism to differentiate “copy semantics” from “move semantics”. Overriding the copy semantics to implement move semantics leads to weird edge cases and inadvertent bugs. For example, you can write res1 = res2 and have no idea whether res2 will be changed or not!
Because of this, in C++11, the concept of “move” was formally defined, and “move semantics” were added to the language to properly differentiate copying from moving. Now that we’ve set the stage for why move semantics can be useful, we’ll explore the topic of move semantics throughout the rest of this chapter. We’ll also fix our Auto_ptr2 class using move semantics.
In C++11, std::auto_ptr has been replaced by a bunch of other types of “move-aware” smart pointers: std::unique_ptr, std::weak_ptr, and std::shared_ptr. We’ll also explore the two most popular of these: unique_ptr (which is a direct replacement for auto_ptr) and shared_ptr.
M.2 — R-value references
L-value references recap
Prior to C++11, only one type of reference existed in C++, and so it was just called a “reference”. However, in C++11, it’s called an l-value reference. L-value references can only be initialized with modifiable l-values.
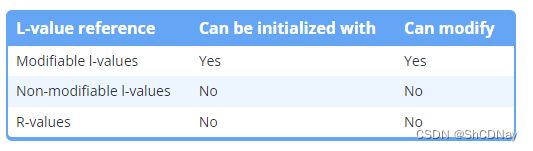
L-value references to const objects can be initialized with modifiable and non-modifiable l-values and r-values alike. However, those values can’t be modified.
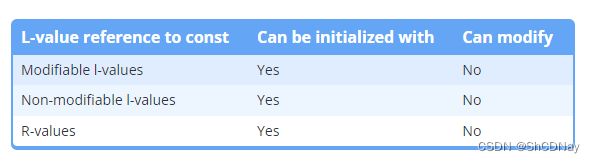
L-value references to const objects are particularly useful because they allow us to pass any type of argument (l-value or r-value) into a function without making a copy of the argument.
R-value references
C++11 adds a new type of reference called an r-value reference. An r-value reference is a reference that is designed to be initialized with an r-value (only). While an l-value reference is created using a single ampersand, an r-value reference is created using a double ampersand:
int x{ 5 };
int& lref{ x }; // l-value reference initialized with l-value x
int& &rref{ 5 }; // r-value reference initialized with r-value 5
R-values references cannot be initialized with l-values.
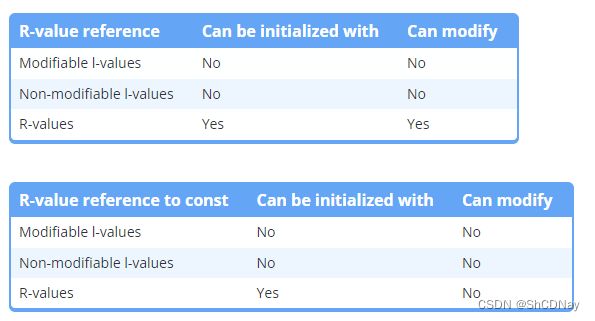
R-value references have two properties that are useful. First, r-value references extend the lifespan of the object they are initialized with to the lifespan of the r-value reference (l-value references to const objects can do this too). Second, non-const r-value references allow you to modify the r-value!
Now let’s take a look at a less intuitive example:
#include This program prints:
10
While it may seem weird to initialize an r-value reference with a literal value and then be able to change that value, when initializing an r-value reference with a literal, a temporary object is constructed from the literal so that the reference is referencing a temporary object, not a literal value.
R-value references are not very often used in either of the manners illustrated above.
R-value references as function parameters
R-value references are more often used as function parameters. This is most useful for function overloads when you want to have different behavior for l-value and r-value arguments.
#include This prints:
l-value reference to const
r-value reference
As you can see, when passed an l-value, the overloaded function resolved to the version with the l-value reference. When passed an r-value, the overloaded function resolved to the version with the r-value reference (this is considered a better match than a l-value reference to const).
Why would you ever want to do this? We’ll discuss this in more detail in the next lesson. Needless to say, it’s an important part of move semantics.
Rvalue reference variables are lvalues
Consider the following snippet:
int&& ref{ 5 };
fun(ref);
Which version of fun would you expect the above to call: fun(const int&) or fun(int&&)?
The answer might surprise you. This calls fun(const int&).
Although variable ref has type int&&, when used in an expression it is an lvalue (as are all named variables). The type of an object and its value category are independent.
You already know that literal 6 is an rvalue of type int, and int x is an lvalue of type int. Similarly, int&& ref is an lvalue of type int&&.
So not only does fun(ref) call fun(const int&), it does not even match fun(int&&), as rvalue references can’t bind to lvalues.
Returning an r-value reference
You should almost never return an r-value reference, for the same reason you should almost never return an l-value reference. In most cases, you’ll end up returning a hanging reference when the referenced object goes out of scope at the end of the function.
M.3 — Move constructors and move assignment
Recapping copy constructors and copy assignment
So, in short, because we call the copy constructor once to copy construct res to a temporary, and copy assignment once to copy the temporary into mainres, we end up allocating and destroying 3 separate objects in total.
Inefficient, but at least it doesn’t crash!
However, with move semantics, we can do better.
Move constructors and move assignment
Defining a move constructor and move assignment work analogously to their copy counterparts. However, whereas the copy flavors of these functions take a const l-value reference parameter, the move flavors of these functions use non-const r-value reference parameters.
Here’s the same Auto_ptr3 class as above, with a move constructor and move assignment operator added. We’ve left in the deep-copying copy constructor and copy assignment operator for comparison purposes.
When run, this program prints:
Resource acquired
Resource destroyed
That’s much better!
So instead of copying our Resource twice (once for the copy constructor and once for the copy assignment), we transfer it twice. This is more efficient, as Resource is only constructed and destroyed once instead of three times.
When are the move constructor and move assignment called?
The move constructor and move assignment are called when those functions have been defined, and the argument for construction or assignment is an r-value. Most typically, this r-value will be a literal or temporary value.
Implicit move constructor and move assignment
The compiler will create an implicit move constructor and move assignment operator if all of the following are true:
- There are no user-declared copy constructors or copy assignment operators.
- There are no user-declared move constructors or move assignment operators.
- There is no user-declared destructor.
The key insight behind move semantics
You now have enough context to understand the key insight behind move semantics.
If we construct an object or do an assignment where the argument is an l-value, the only thing we can reasonably do is copy the l-value. We can’t assume it’s safe to alter the l-value, because it may be used again later in the program. If we have an expression “a = b” (where b is an lvalue), we wouldn’t reasonably expect b to be changed in any way.
However, if we construct an object or do an assignment where the argument is an r-value, then we know that r-value is just a temporary object of some kind. Instead of copying it (which can be expensive), we can simply transfer its resources (which is cheap) to the object we’re constructing or assigning. This is safe to do because the temporary will be destroyed at the end of the expression anyway, so we know it will never be used again!
C++11, through r-value references, gives us the ability to provide different behaviors when the argument is an r-value vs an l-value, enabling us to make smarter and more efficient decisions about how our objects should behave.
Move functions should always leave both objects in a valid state
In the above examples, both the move constructor and move assignment functions set a.m_ptr to nullptr. This may seem extraneous – after all, if a is a temporary r-value, why bother doing “cleanup” if parameter a is going to be destroyed anyway?
The answer is simple: When a goes out of scope, the destructor for a will be called, and a.m_ptr will be deleted. If at that point, a.m_ptr is still pointing to the same object as m_ptr, then m_ptr will be left as a dangling pointer. When the object containing m_ptr eventually gets used (or destroyed), we’ll get undefined behavior.
When implementing move semantics, it is important to ensure the moved-from object is left in a valid state, so that it will destruct properly (without creating undefined behavior).
Automatic l-values returned by value may be moved instead of copied
In the generateResource() function of the Auto_ptr4 example above, when variable res is returned by value, it is moved instead of copied, even though res is an l-value. The C++ specification has a special rule that says automatic objects returned from a function by value can be moved even if they are l-values. This makes sense, since res was going to be destroyed at the end of the function anyway! We might as well steal its resources instead of making an expensive and unnecessary copy.
Although the compiler can move l-value return values, in some cases it may be able to do even better by simply eliding the copy altogether (which avoids the need to make a copy or do a move at all). In such a case, neither the copy constructor nor move constructor would be called.
Disabling copying
In the Auto_ptr4 class above, we left in the copy constructor and assignment operator for comparison purposes. But in move-enabled classes, it is sometimes desirable to delete the copy constructor and copy assignment functions to ensure copies aren’t made. In the case of our Auto_ptr class, we don’t want to copy our templated object T – both because it’s expensive, and whatever class T is may not even support copying!
Here’s a version of Auto_ptr that supports move semantics but not copy semantics:
// Copy constructor -- no copying allowed!
Auto_ptr5(const Auto_ptr5& a) = delete;
// Move constructor
// Transfer ownership of a.m_ptr to m_ptr
Auto_ptr5(Auto_ptr5&& a) noexcept
: m_ptr(a.m_ptr)
{
a.m_ptr = nullptr;
}
// Copy assignment -- no copying allowed!
Auto_ptr5& operator=(const Auto_ptr5& a) = delete;
// Move assignment
// Transfer ownership of a.m_ptr to m_ptr
Auto_ptr5& operator=(Auto_ptr5&& a) noexcept
{
// Self-assignment detection
if (&a == this)
return *this;
// Release any resource we're holding
delete m_ptr;
// Transfer ownership of a.m_ptr to m_ptr
m_ptr = a.m_ptr;
a.m_ptr = nullptr;
return *this;
}
If you were to try to pass an Auto_ptr5 l-value to a function by value, the compiler would complain that the copy constructor required to initialize the function argument has been deleted. This is good, because we should probably be passing Auto_ptr5 by const l-value reference anyway!
Auto_ptr5 is (finally) a good smart pointer class. And, in fact the standard library contains a class very much like this one (that you should use instead), named std::unique_ptr. We’ll talk more about std::unique_ptr later in this chapter.
Another example
Comparing the runtime of the two programs, 0.0056 / 0.00825559 = 67.8%. The move version was 47.4% faster!
Do not implement move semantics using std::swap
Since the goal of move semantics is to move a resource from a source object to a destination object, you might think about implementing the move constructor and move assignment operator using std::swap(). However, this is a bad idea, as std::swap() calls both the move constructor and move assignment on move-capable objects, which would result in an infinite recursion. You can see this happen in the following example:
This prints:
Move assign
Move ctor
Move ctor
Move ctor
Move ctor
And so on… until the stack overflows.
You can implement the move constructor and move assignment using your own swap function, as long as your swap member function does not call the move constructor or move assignment. Here’s an example of how that can be done:
#include This works as expected, and prints:
Move assign
Joe
Deleting the move constructor and move assignment
Key insight
The rule of five says that if the copy constructor, copy assignment, move constructor, move assignment, or destructor are defined or deleted, then each of those functions should be defined or deleted.
While deleting only the move constructor and move assignment may seem like a good idea if you want a copyable but not movable object, this has the unfortunate consequence of making the class not returnable by value in cases where mandatory copy elision does not apply. This happens because a deleted move constructor is still declared, and thus is eligible for overload resolution. And return by value will favor a deleted move constructor over a non-deleted copy constructor. This is illustrated by the following program:
#include M.4 — std::move
However, doing copies isn’t necessary here. All we’re really trying to do is swap the values of a and b, which can be accomplished just as well using 3 moves instead! So if we switch from copy semantics to move semantics, we can make our code more performant.
But how? The problem here is that parameters a and b are l-value references, not r-value references, so we don’t have a way to invoke the move constructor and move assignment operator instead of copy constructor and copy assignment. By default, we get the copy constructor and copy assignment behaviors. What are we to do?
std::move
In C++11, std::move is a standard library function that casts (using static_cast) its argument into an r-value reference, so that move semantics can be invoked. Thus, we can use std::move to cast an l-value into a type that will prefer being moved over being copied. std::move is defined in the utility header.
Here’s the same program as above, but with a myswapMove() function that uses std::move to convert our l-values into r-values so we can invoke move semantics:
#include This prints the same result as above:
x: abc
y: de
x: de
y: abc
But it’s much more efficient about it. When tmp is initialized, instead of making a copy of x, we use std::move to convert l-value variable x into an r-value. Since the parameter is an r-value, move semantics are invoked, and x is moved into tmp.
With a couple of more swaps, the value of variable x has been moved to y, and the value of y has been moved to x.
Another example
We can also use std::move when filling elements of a container, such as std::vector, with l-values.
In the following program, we first add an element to a vector using copy semantics. Then we add an element to the vector using move semantics.
#include On the author’s machine, this program prints:
Copying str
str: Knock
vector: Knock
Moving str
str:
vector: Knock Knock
In the first case, we passed push_back() an l-value, so it used copy semantics to add an element to the vector. For this reason, the value in str is left alone.
In the second case, we passed push_back() an r-value (actually an l-value converted via std::move), so it used move semantics to add an element to the vector. This is more efficient, as the vector element can steal the string’s value rather than having to copy it.
Moved from objects will be in a valid, but possibly indeterminate state
Key insight
std::move() gives a hint to the compiler that the programmer doesn’t need the value of an object any more. Only use std::move() on persistent objects whose value you want to move, and do not make any assumptions about the value of the object beyond that point. It is okay to give a moved-from object a new value (e.g. using operator=) after the current value has been moved.
Where else is std::move useful?
std::move can also be useful when sorting an array of elements. Many sorting algorithms (such as selection sort and bubble sort) work by swapping pairs of elements. In previous lessons, we’ve had to resort to copy-semantics to do the swapping. Now we can use move semantics, which is more efficient.
It can also be useful if we want to move the contents managed by one smart pointer to another.
Conclusion
std::move can be used whenever we want to treat an l-value like an r-value for the purpose of invoking move semantics instead of copy semantics.
M.5 — std::move_if_noexcept
In lesson 20.9 – Exception specifications and noexcept, we covered the noexcept exception specifier and operator, which this lesson builds on.
We also covered the strong exception guarantee, which guarantees that if a function is interrupted by an exception, no memory will be leaked and the program state will not be changed. In particular, all constructors should uphold the strong exception guarantee, so that the rest of the program won’t be left in an altered state if construction of an object fails.
The move constructors exception problem
To summarize the above results: the move constructor of std::pair used the throwing copy constructor of CopyClass. This copy constructor threw an exception, causing the creation of moved_pair to abort, and my_pair.first to be permanently damaged. The strong exception guarantee was not preserved.
std::move_if_noexcept to the rescue
Key insight
std::move_if_noexcept will return a movable r-value if the object has a noexcept move constructor, otherwise it will return a copyable l-value. We can use the noexcept specifier in conjunction with std::move_if_noexcept to use move semantics only when a strong exception guarantee exists (and use copy semantics otherwise).
The move constructor of std::pair isn’t noexcept (as of C++20), so std::move_if_noexcept returns my_pair as an l-value reference. This causes moved_pair to be created via the copy constructor (rather than the move constructor). The copy constructor can throw safely, because it doesn’t modify the source object.
The standard library uses std::move_if_noexcept often to optimize for functions that are noexcept. For example, std::vector::resize will use move semantics if the element type has a noexcept move constructor, and copy semantics otherwise. This means std::vector will generally operate faster with objects that have a noexcept move constructor.
Warning
If a type has both potentially throwing move semantics and deleted copy semantics (the copy constructor and copy assignment operator are unavailable), then std::move_if_noexcept will waive the strong guarantee and invoke move semantics. This conditional waiving of the strong guarantee is ubiquitous in the standard library container classes, since they use std::move_if_noexcept often.
M.6 — std::unique_ptr
As a reminder, a smart pointer is a class that manages a dynamically allocated object.
By always allocating smart pointers on the stack (as local variables or composition members of a class), we’re guaranteed that the smart pointer will properly go out of scope when the function or object it is contained within ends, ensuring the object the smart pointer owns is properly deallocated.
C++11 standard library ships with 4 smart pointer classes: std::auto_ptr (removed in C++17), std::unique_ptr, std::shared_ptr, and std::weak_ptr. std::unique_ptr is by far the most used smart pointer class, so we’ll cover that one first. In the following lessons, we’ll cover std::shared_ptr and std::weak_ptr.
std::unique_ptr
std::unique_ptr is the C++11 replacement for std::auto_ptr. It should be used to manage any dynamically allocated object that is not shared by multiple objects. That is, std::unique_ptr should completely own the object it manages, not share that ownership with other classes. std::unique_ptr lives in the header.
Let’s take a look at a simple smart pointer example:
#include Because the std::unique_ptr is allocated on the stack here, it’s guaranteed to eventually go out of scope, and when it does, it will delete the Resource it is managing.
Unlike std::auto_ptr, std::unique_ptr properly implements move semantics.
#include This prints:
Resource acquired
res1 is not null
res2 is null
Ownership transferred
res1 is null
res2 is not null
Resource destroyed
Because std::unique_ptr is designed with move semantics in mind, copy initialization and copy assignment are disabled. If you want to transfer the contents managed by std::unique_ptr, you must use move semantics. In the program above, we accomplish this via std::move (which converts res1 into an r-value, which triggers a move assignment instead of a copy assignment).
Accessing the managed object
std::unique_ptr has an overloaded operator* and operator-> that can be used to return the resource being managed. Operator* returns a reference to the managed resource, and operator-> returns a pointer.
std::unique_ptr and arrays
Unlike std::auto_ptr, std::unique_ptr is smart enough to know whether to use scalar delete or array delete, so std::unique_ptr is okay to use with both scalar objects and arrays.
However, std::array or std::vector (or std::string) are almost always better choices than using std::unique_ptr with a fixed array, dynamic array, or C-style string.
Best practice
Favor std::array, std::vector, or std::string over a smart pointer managing a fixed array, dynamic array, or C-style string.
std::make_unique
C++14 comes with an additional function named std::make_unique(). This templated function constructs an object of the template type and initializes it with the arguments passed into the function.
Use of std::make_unique() is optional, but is recommended over creating std::unique_ptr yourself. This is because code using std::make_unique is simpler, and it also requires less typing (when used with automatic type deduction). Furthermore it resolves an exception safety issue that can result from C++ leaving the order of evaluation for function arguments unspecified.
Best practice
Use std::make_unique() instead of creating std::unique_ptr and using new yourself.
The exception safety issue in more detail
For those wondering what the “exception safety issue” mentioned above is, here’s a description of the issue.
Consider an expression like this one:
some_function(std::unique_ptr<T>(new T), function_that_can_throw_exception());
The compiler is given a lot of flexibility in terms of how it handles this call. It could create a new T, then call function_that_can_throw_exception(), then create the std::unique_ptr that manages the dynamically allocated T. If function_that_can_throw_exception() throws an exception, then the T that was allocated will not be deallocated, because the smart pointer to do the deallocation hasn’t been created yet. This leads to T being leaked.
std::make_unique() doesn’t suffer from this problem because the creation of the object T and the creation of the std::unique_ptr happen inside the std::make_unique() function, where there’s no ambiguity about order of execution.
Returning std::unique_ptr from a function
std::unique_ptr can be safely returned from a function by value:
#include In general, you should not return std::unique_ptr by pointer (ever) or reference (unless you have a specific compelling reason to).
Passing std::unique_ptr to a function
If you want the function to take ownership of the contents of the pointer, pass the std::unique_ptr by value. Note that because copy semantics have been disabled, you’ll need to use std::move to actually pass the variable in.
Instead, it’s better to just pass the resource itself (by pointer or reference, depending on whether null is a valid argument). This allows the function to remain agnostic of how the caller is managing its resources. To get a raw resource pointer from a std::unique_ptr, you can use the get() member function:
#include The above program prints:
Resource acquired
I am a resource
Ending program
Resource destroyed
std::unique_ptr and classes
You can, of course, use std::unique_ptr as a composition member of your class. This way, you don’t have to worry about ensuring your class destructor deletes the dynamic memory, as the std::unique_ptr will be automatically destroyed when the class object is destroyed.
However, if the class object is not destroyed properly (e.g. it is dynamically allocated and not deallocated properly), then the std::unique_ptr member will not be destroyed either, and the object being managed by the std::unique_ptr will not be deallocated.
Misusing std::unique_ptr
There are two easy ways to misuse std::unique_ptrs, both of which are easily avoided. First, don’t let multiple classes manage the same resource. For example:
Resource* res{ new Resource() };
std::unique_ptr<Resource> res1{ res };
std::unique_ptr<Resource> res2{ res };
While this is legal syntactically, the end result will be that both res1 and res2 will try to delete the Resource, which will lead to undefined behavior.
Second, don’t manually delete the resource out from underneath the std::unique_ptr.
Resource* res{ new Resource() };
std::unique_ptr<Resource> res1{ res };
delete res;
If you do, the std::unique_ptr will try to delete an already deleted resource, again leading to undefined behavior.
Note that std::make_unique() prevents both of the above cases from happening inadvertently.
M.7 — std::shared_ptr
Note that we created a second shared pointer from the first shared pointer. This is important. Consider the following similar program:
and then crashes (at least on the author’s machine).
The difference here is that we created two std::shared_ptr independently from each other. As a consequence, even though they’re both pointing to the same Resource, they aren’t aware of each other.
Fortunately, this is easily avoided: if you need more than one std::shared_ptr to a given resource, copy an existing std::shared_ptr.
Best practice
Always make a copy of an existing std::shared_ptr if you need more than one std::shared_ptr pointing to the same resource.
std::make_shared
#include The reasons for using std::make_shared() are the same as std::make_unique() – std::make_shared() is simpler and safer (there’s no way to directly create two std::shared_ptr pointing to the same resource using this method). However, std::make_shared() is also more performant than not using it. The reasons for this lie in the way that std::shared_ptr keeps track of how many pointers are pointing at a given resource.
Digging into std::shared_ptr
However, when a std::shared_ptr is cloned using copy assignment, the data in the control block can be appropriately updated to indicate that there are now additional std::shared_ptr co-managing the resource.
Shared pointers can be created from unique pointers
A std::unique_ptr can be converted into a std::shared_ptr via a special std::shared_ptr constructor that accepts a std::unique_ptr r-value. The contents of the std::unique_ptr will be moved to the std::shared_ptr.
However, std::shared_ptr can not be safely converted to a std::unique_ptr. This means that if you’re creating a function that is going to return a smart pointer, you’re better off returning a std::unique_ptr and assigning it to a std::shared_ptr if and when that’s appropriate.
The perils of std::shared_ptr
std::shared_ptr has some of the same challenges as std::unique_ptr – if the std::shared_ptr is not properly disposed of (either because it was dynamically allocated and never deleted, or it was part of an object that was dynamically allocated and never deleted) then the resource it is managing won’t be deallocated either. With std::unique_ptr, you only have to worry about one smart pointer being properly disposed of. With std::shared_ptr, you have to worry about them all. If any of the std::shared_ptr managing a resource are not properly destroyed, the resource will not be deallocated properly.
std::shared_ptr and arrays
In C++17 and earlier, std::shared_ptr does not have proper support for managing arrays, and should not be used to manage a C-style array. As of C++20, std::shared_ptr does have support for arrays.
Conclusion
std::shared_ptr is designed for the case where you need multiple smart pointers co-managing the same resource. The resource will be deallocated when the last std::shared_ptr managing the resource is destroyed.
M.8 — Circular dependency issues with std::shared_ptr, and std::weak_ptr
However, this program doesn’t execute as expected:
Lucy created
Ricky created
Lucy is now partnered with Ricky
And that’s it. No deallocations took place. Uh oh. What happened?
After partnerUp() is called, there are two shared pointers pointing to “Ricky” (ricky, and Lucy’s m_partner) and two shared pointers pointing to “Lucy” (lucy, and Ricky’s m_partner).
Circular references
A Circular reference (also called a cyclical reference or a cycle) is a series of references where each object references the next, and the last object references back to the first, causing a referential loop. The references do not need to be actual C++ references – they can be pointers, unique IDs, or any other means of identifying specific objects.
In the context of shared pointers, the references will be pointers.
This is exactly what we see in the case above: “Lucy” points at “Ricky”, and “Ricky” points at “Lucy”. With three pointers, you’d get the same thing when A points at B, B points at C, and C points at A. The practical effect of having shared pointers form a cycle is that each object ends up keeping the next object alive – with the last object keeping the first object alive. Thus, no objects in the series can be deallocated because they all think some other object still needs it!
A reductive case
So what is std::weak_ptr for anyway?
std::weak_ptr was designed to solve the “cyclical ownership” problem described above. A std::weak_ptr is an observer – it can observe and access the same object as a std::shared_ptr (or other std::weak_ptrs) but it is not considered an owner. Remember, when a std::shared pointer goes out of scope, it only considers whether other std::shared_ptr are co-owning the object. std::weak_ptr does not count!
Using std::weak_ptr
One downside of std::weak_ptr is that std::weak_ptr are not directly usable (they have no operator->). To use a std::weak_ptr, you must first convert it into a std::shared_ptr. Then you can use the std::shared_ptr. To convert a std::weak_ptr into a std::shared_ptr, you can use the lock() member function. Here’s the above example, updated to show this off:
#include This prints:
Lucy created
Ricky created
Lucy is now partnered with Ricky
Ricky's partner is: Lucy
Ricky destroyed
Lucy destroyed
We don’t have to worry about circular dependencies with std::shared_ptr variable “partner” since it’s just a local variable inside the function. It will eventually go out of scope at the end of the function and the reference count will be decremented by 1.
Avoiding dangling pointers with std::weak_ptr
Because std::weak_ptr won’t keep an owned resource alive, it’s similarly possible for a std::weak_ptr to be left pointing to a resource that has been deallocated by a std::shared_ptr. However, std::weak_ptr has a neat trick up its sleeve – because it has access to the reference count for an object, it can determine if it is pointing to a valid object or not! If the reference count is non-zero, the resource is still valid. If the reference count is zero, then the resource has been destroyed.
The easiest way to test whether a std::weak_ptr is valid is to use the expired() member function, which returns true if the std::weak_ptr is pointing to an invalid object, and false otherwise.
Here’s a simple example showing this difference in behavior:
// h/t to reader Waldo for an early version of this example
#include This prints:
Resource acquired
Resource destroyed
Our dumb ptr is: non-null
Resource acquired
Resource destroyed
Our weak ptr is: expired
Both getDumbPtr() and getWeakPtr() use a smart pointer to allocate a Resource – this smart pointer ensures that the allocated Resource will be destroyed at the end of the function. When getDumbPtr() returns a Resource*, it returns a dangling pointer (because std::unique_ptr destroyed the Resource at the end of the function). When getWeakPtr() returns a std::weak_ptr, that std::weak_ptr is similarly pointing to an invalid object (because std::shared_ptr destroyed the Resource at the end of the function).
Inside main(), we first test whether the returned dumb pointer is nullptr. Because the dumb pointer is still holding the address of the deallocated resource, this test fails. There is no way for main() to tell whether this pointer is dangling or not. In this case, because it is a dangling pointer, if we were to dereference this pointer, undefined behavior would result.
Next, we test whether weak.expired() is true. Because the reference count for the object being pointed to by weak is 0 (because the object being pointed to was already destroyed), this resolves to true. The code in main() can thus tell that weak is pointing to an invalid object, and we can conditionalize our code as appropriate!
Note that if a std::weak_ptr is expired, then we shouldn’t call lock() on it, because the object being pointed to has already been destroyed, so there is no object to share. If you do call lock() on an expired std::weak_ptr, it will return a std::shared_ptr to nullptr.
Conclusion
std::shared_ptr can be used when you need multiple smart pointers that can co-own a resource. The resource will be deallocated when the last std::shared_ptr goes out of scope. std::weak_ptr can be used when you want a smart pointer that can see and use a shared resource, but does not participate in the ownership of that resource.
M.x — Chapter M comprehensive review
A smart pointer class is a composition class that is designed to manage dynamically allocated memory, and ensure that memory gets deleted when the smart pointer object goes out of scope.
std::auto_ptr is deprecated and should be avoided.
std::move_if_noexcept will return a movable r-value if the object has a noexcept move constructor, otherwise it will return a copyable l-value. We can use the noexcept specifier in conjunction with std::move_if_noexcept to use move semantics only when a strong exception guarantee exists (and use copy semantics otherwise).
Quiz time
- Explain why move semantics is focused around r-values.
Because r-values are temporary, we know they are going to get destroyed after they are used. When passing or returning an r-value by value, it’s wasteful to make a copy and then destroy the original. Instead, we can simply move (steal) the r-value’s resources, which is generally more efficient.
Chapter 21_The Standard Template Library
21.1 — The Standard Library
You’ve probably also noticed that programs written using non-class versions of containers and common algorithms are error-prone. The good news is that C++ comes with a library that is chock full of reusable classes for you to build programs out of. This library is called The C++ Standard Library.
The Standard Library
The Standard library contains a collection of classes that provide templated containers, algorithms, and iterators.
Fortunately, you can bite off the standard library in tiny pieces, using only what you need from it, and ignore the rest until you’re ready to tackle it.
21.2 — STL containers overview
Generally speaking, the container classes fall into three basic categories: Sequence containers, Associative containers, and Container adapters.
Sequence Containers
As of C++11, the STL contains 6 sequence containers: std::vector, std::deque, std::array, std::list, std::forward_list, and std::basic_string.
-
A list is a special type of sequence container called a doubly linked list where each element in the container contains pointers that point at the next and previous elements in the list. Lists only provide access to the start and end of the list – there is no random access provided. If you want to find a value in the middle, you have to start at one end and “walk the list” until you reach the element you want to find. The advantage of lists is that inserting elements into a list is very fast if you already know where you want to insert them. Generally iterators are used to walk through the list.
-
Although the STL string (and wstring) class aren’t generally included as a type of sequence container, they essentially are, as they can be thought of as a vector with data elements of type char (or wchar).
Associative Containers
Associative containers are containers that automatically sort their inputs when those inputs are inserted into the container. By default, associative containers compare elements using operator<.
Container Adapters
Container adapters are special predefined containers that are adapted to specific uses. The interesting part about container adapters is that you can choose which sequence container you want them to use.
21.3 — STL iterators overview
An Iterator is an object that can traverse (iterate over) a container class without the user having to know how the container is implemented. With many classes (particularly lists and the associative classes), iterators are the primary way elements of these classes are accessed.
- Operator= – Assign the iterator to a new position (typically the start or end of the container’s elements). To assign the value of the element the iterator is pointing at, dereference the iterator first, then use the assign operator.
Each container includes four basic member functions for use with Operator=:
- begin() returns an iterator representing the beginning of the elements in the container.
- end() returns an iterator representing the element just past the end of the elements.
- cbegin() returns a const (read-only) iterator representing the beginning of the elements in the container.
- cend() returns a const (read-only) iterator representing the element just past the end of the elements.
Finally, all containers provide (at least) two types of iterators:
- container::iterator provides a read/write iterator
- container::const_iterator provides a read-only iterator
Conclusion
Iterators provide an easy way to step through the elements of a container class without having to understand how the container class is implemented. When combined with STL’s algorithms and the member functions of the container classes, iterators become even more powerful. In the next lesson, you’ll see an example of using an iterator to insert elements into a list (which doesn’t provide an overloaded operator[] to access its elements directly).
One point worth noting: Iterators must be implemented on a per-class basis, because the iterator does need to know how a class is implemented. Thus iterators are always tied to specific container classes.
21.4 — STL algorithms overview
In addition to container classes and iterators, STL also provides a number of generic algorithms for working with the elements of the container classes. These allow you to do things like search, sort, insert, reorder, remove, and copy elements of the container class.
Note that algorithms are implemented as functions that operate using iterators. This means that each algorithm only needs to be implemented once, and it will generally automatically work for all containers that provides a set of iterators (including your custom container classes). While this is very powerful and can lead to the ability to write complex code very quickly, it’s also got a dark side: some combination of algorithms and container types may not work, may cause infinite loops, or may work but be extremely poor performing. So use these at your risk.
STL provides quite a few algorithms – we will only touch on some of the more common and easy to use ones here. The rest (and the full details) will be saved for a chapter on STL algorithms.
To use any of the STL algorithms, simply include the algorithm header file.
sort and reverse
In this example, we’ll sort a vector and then reverse it.
#include This produces the result:
-5 -3 0 2 4 6 7
7 6 4 2 0 -3 -5
Alternatively, we could pass a custom comparison function as the third argument to std::sort. There are several comparison functions in the header which we can use so we don’t have to write our own. We can pass std::greater to std::sort and remove the call to std::reverse. The vector will be sorted from high to low right away.
Note that std::sort() doesn’t work on list container classes – the list class provides its own sort() member function, which is much more efficient than the generic version would be.
Conclusion
Although this is just a taste of the algorithms that STL provides, it should suffice to show how easy these are to use in conjunction with iterators and the basic container classes. There are enough other algorithms to fill up a whole chapter!
Chapter 22_std::string
22.1 — std::string and std::wstring
Motivation for a string class
Fortunately, C++ and the standard library provide a much better way to deal with strings: the std::string and std::wstring classes. By making use of C++ concepts such as constructors, destructors, and operator overloading, std::string allows you to create and manipulate strings in an intuitive and safe manner! No more memory management, no more weird function names, and a much reduced potential for disaster.
Sign me up!
String overview
While the standard library string classes provide a lot of functionality, there are a few notable omissions:
- Regular expression support
- Constructors for creating strings from numbers
- Capitalization / upper case / lower case functions
- Case-insensitive comparisons
- Tokenization / splitting string into array
- Easy functions for getting the left or right hand portion of string
- Whitespace trimming
- Formatting a string sprintf style
- Conversion from utf-8 to utf-16 or vice-versa
For most of these, you will have to either write your own functions, or convert your string to a C-style string (using c_str()) and use the C functions that offer this functionality.
In the next lessons, we will look at the various functions of the string class in more depth. Although we will use string for our examples, everything is equally applicable to wstring.
22.2 — std::string construction and destruction
In this lesson, we’ll take a look at how to construct objects of std::string, as well as how to create strings from numbers and vice-versa.
Constructing strings from numbers
One notable omission in the std::string class is the lack of ability to create strings from numbers. For example:
std::string sFour{ 4 };
Produces the following error:
c:vcprojectstest2test2test.cpp(10) : error C2664: 'std::basic_string<_Elem,_Traits,_Ax>::basic_string(std::basic_string<_Elem,_Traits,_Ax>::_Has_debug_it)' : cannot convert parameter 1 from 'int' to 'std::basic_string<_Elem,_Traits,_Ax>::_Has_debug_it'
Remember what I said about the string classes producing horrible looking errors? The relevant bit of information here is:
cannot convert parameter 1 from 'int' to 'std::basic_string
In other words, it tried to convert your int into a string but failed.
The easiest way to convert numbers into strings is to involve the std::ostringstream class. std::ostringstream is already set up to accept input from a variety of sources, including characters, numbers, strings, etc… It is also capable of outputting strings (either via the extraction operator>>, or via the str() function). For more information on std::ostringstream, see 23.4 – Stream classes for strings.
Here’s a simple solution for creating std::string from various types of inputs:
#include Here’s some sample code to test it:
int main()
{
std::string sFour{ ToString(4) };
std::string sSixPointSeven{ ToString(6.7) };
std::string sA{ ToString('A') };
std::cout << sFour << '\n';
std::cout << sSixPointSeven << '\n';
std::cout << sA << '\n';
}
And the output:
4
6.7
A
Note that this solution omits any error checking. It is possible that inserting tX into oStream could fail. An appropriate response would be to throw an exception if the conversion fails.
Related content
The standard library also contains a function named std::to_string() that can be used to convert numbers into a std::string. While this is a simpler solution for basic cases, the output of std::to_string may differ from the output of std::cout or out ToString() function above. Some of these differences are currently documented here.
Converting strings to numbers
Similar to the solution above:
#include Here’s some sample code to test it:
int main()
{
double dX;
if (FromString("3.4", dX))
std::cout << dX << '\n';
if (FromString("ABC", dX))
std::cout << dX << '\n';
}
And the output:
3.4
Note that the second conversion failed and returned false.
22.3 — std::string length and capacity
Once you’ve created strings, it’s often useful to know how long they are. This is where length and capacity operations come into play. We’ll also discuss various ways to convert std::string back into C-style strings, so you can use them with functions that expect strings of type char*.
Length of a string
Capacity of a string
void string::reserve()
void string::reserve(size_type unSize)
- The second flavor of this function sets the capacity of the string to at least unSize (it can be greater). Note that this may require a reallocation to occur.
- If the first flavor of the function is called, or the second flavor is called with unSize less than the current capacity, the function will try to shrink the capacity to match the length. This request to shrink the capacity may be ignored, depending on implementation.
Sample code:
std::string s { "01234567" };
std::cout << "Length: " << s.length() << '\n';
std::cout << "Capacity: " << s.capacity() << '\n';
s.reserve(200);
std::cout << "Length: " << s.length() << '\n';
std::cout << "Capacity: " << s.capacity() << '\n';
s.reserve();
std::cout << "Length: " << s.length() << '\n';
std::cout << "Capacity: " << s.capacity() << '\n';
Output:
Length: 8
Capacity: 15
Length: 8
Capacity: 207
Length: 8
Capacity: 207
This example shows two interesting things. First, although we requested a capacity of 200, we actually got a capacity of 207. The capacity is always guaranteed to be at least as large as your request, but may be larger. We then requested the capacity change to fit the string. This request was ignored, as the capacity did not change.
Rather than having to reallocate s multiple times, we set the capacity once and then fill the string up. This can make a huge difference in performance when constructing large strings via concatenation.
22.4 — std::string character access and conversion to C-style arrays
Character access
Conversion to C-style arrays
Many functions (including all C functions) expect strings to be formatted as C-style strings rather than std::string. For this reason, std::string provides 3 different ways to convert std::string to C-style strings.
1.
const char* string::c_str () const
const char* string::data () const
size_type string::copy(char* szBuf, size_type nLength, size_type nIndex = 0) const
This function should be avoided where possible as it is relatively dangerous (as it is up to the caller to provide null-termination and avoid buffer overflows).
22.5 — std::string assignment and swapping
String assignment
The easiest way to assign a value to a string is to use the overloaded operator= function. There is also an assign() member function that duplicates some of this functionality.
Swapping
If you have two strings and want to swap their values, there are two functions both named swap() that you can use.
void string::swap (string& str)
void swap (string& str1, string& str2)
Sample code:
std::string sStr1("red");
std::string sStr2("blue");
std::cout << sStr1 << ' ' << sStr2 << '\n';
swap(sStr1, sStr2);
std::cout << sStr1 << ' ' << sStr2 << '\n';
sStr1.swap(sStr2);
std::cout << sStr1 << ' ' << sStr2 << '\n';
22.6 — std::string appending
Appending
Operator+= and append() also have versions that work on C-style strings:
22.7 — std::string inserting
Chapter 23_Input and Output (I/O)
23.1 — Input and output (I/O) streams
The iostream library
When you include the iostream header, you gain access to a whole hierarchy of classes responsible for providing I/O functionality (including one class that is actually named iostream). You can find a class hierarchy diagram for the non-file-I/O classes here.
The first thing you may notice about this hierarchy is that it uses multiple inheritance (that thing we told you to avoid if at all possible). However, the iostream library has been designed and extensively tested in order to avoid any of the typical multiple inheritance problems, so you can use it freely without worrying.
Streams
The nice thing about streams is the programmer only has to learn how to interact with the streams in order to read and write data to many different kinds of devices. The details about how the stream interfaces with the actual devices they are hooked up to is left up to the environment or operating system.
Input/output in C++
Standard streams in C++
A standard stream is a pre-connected stream provided to a computer program by its environment. C++ comes with four predefined standard stream objects that have already been set up for your use. The first three, you have seen before:
- cin – an istream object tied to the standard input (typically the keyboard)
- cout – an ostream object tied to the standard output (typically the monitor)
- cerr – an ostream object tied to the standard error (typically the monitor), providing unbuffered output
- clog – an ostream object tied to the standard error (typically the monitor), providing buffered output
Unbuffered output is typically handled immediately, whereas buffered output is typically stored and written out as a block. Because clog isn’t used very often, it is often omitted from the list of standard streams.
In the next lesson, we’ll take a look at some more I/O related functionality in more detail.
23.2 — Input with istream
The iostream library is fairly complex – so we will not be able to cover it in its entirety in these tutorials. However, we will show you the most commonly used functionality. In this section, we will look at various aspects of the input class (istream).
The extraction operator
A manipulator is an object that is used to modify a stream when applied with the extraction (>>) or insertion (<<) operators. One manipulator you have already worked with is “std::endl”, which both prints a newline character and flushes any buffered output.
#include This program will now only read the first 9 characters out of the stream (leaving room for a terminator). Any remaining characters will be left in the stream until the next extraction.
Extraction and whitespace
As a reminder, the extraction operator skips whitespace (blanks, tabs, and newlines).
Take a look at the following program:
int main()
{
char ch;
while (std::cin >> ch)
std::cout << ch;
return 0;
}
When the user inputs the following:
Hello my name is Alex
The extraction operator skips the spaces and the newline. Consequently, the output is:
HellomynameisAlex
Oftentimes, you’ll want to get user input but not discard whitespace. To do this, the istream class provides many functions that can be used for this purpose.
One of the most useful is the get() function, which simply gets a character from the input stream. Here’s the same program as above using get():
int main()
{
char ch;
while (std::cin.get(ch))
std::cout << ch;
return 0;
}
Now when we use the input:
Hello my name is Alex
The output is:
Hello my name is Alex
std::get() also has a string version that takes a maximum number of characters to read:
Note that we only read the first 10 characters (we had to leave one character for a terminator). The remaining characters were left in the input stream.
One important thing to note about get() is that it does not read in a newline character! This can cause some unexpected results:
Consequently, there is another function called getline() that works exactly like get() but reads the newline as well.
If you need to know how many character were extracted by the last call of getline(), use gcount():
int main()
{
char strBuf[100];
std::cin.getline(strBuf, 100);
std::cout << strBuf << '\n';
std::cout << std::cin.gcount() << " characters were read" << '\n';
return 0;
}
A special version of getline() for std::string
There is a special version of getline() that lives outside the istream class that is used for reading in variables of type std::string. This special version is not a member of either ostream or istream, and is included in the string header. Here is an example of its use:
#include A few more useful istream functions
23.3 — Output with ostream and ios
In this section, we will look at various aspects of the iostream output class (ostream).
The insertion operator
The insertion operator (<<) is used to put information into an output stream. C++ has predefined insertion operations for all of the built-in data types, and you’ve already seen how you can overload the insertion operator for your own classes.
In the lesson on streams, you saw that both istream and ostream were derived from a class called ios. One of the jobs of ios (and ios_base) is to control the formatting options for output.
Formatting
There are two ways to change the formatting options: flags, and manipulators. You can think of flags as boolean variables that can be turned on and off. Manipulators are objects placed in a stream that affect the way things are input and output.
To switch a flag on, use the setf() function, with the appropriate flag as a parameter. For example, by default, C++ does not print a + sign in front of positive numbers. However, by using the std::ios::showpos flag, we can change this behavior:
std::cout.setf(std::ios::showpos); // turn on the std::ios::showpos flag
std::cout << 27 << '\n';
This results in the following output:
+27
It is possible to turn on multiple ios flags at once using the Bitwise OR (|) operator:
std::cout.setf(std::ios::showpos | std::ios::uppercase); // turn on the std::ios::showpos and std::ios::uppercase flag
std::cout << 1234567.89f << '\n';
This outputs:
+1.23457E+06
To turn a flag off, use the unsetf() function:
std::cout.setf(std::ios::showpos); // turn on the std::ios::showpos flag
std::cout << 27 << '\n';
std::cout.unsetf(std::ios::showpos); // turn off the std::ios::showpos flag
std::cout << 28 << '\n';
There’s one other bit of trickiness when using setf() that needs to be mentioned.
The second way is to use a different form of setf() that takes two parameters: the first parameter is the flag to set, and the second is the formatting group it belongs to. When using this form of setf(), all of the flags belonging to the group are turned off, and only the flag passed in is turned on. For example:
// Turn on std::ios::hex as the only std::ios::basefield flag
std::cout.setf(std::ios::hex, std::ios::basefield);
std::cout << 27 << '\n';
This also produces the expected output:
1b
Using setf() and unsetf() tends to be awkward, so C++ provides a second way to change the formatting options: manipulators. The nice thing about manipulators is that they are smart enough to turn on and off the appropriate flags. Here is an example of using some manipulators to change the base:
std::cout << std::hex << 27 << '\n'; // print 27 in hex
std::cout << 28 << '\n'; // we're still in hex
std::cout << std::dec << 29 << '\n'; // back to decimal
This program produces the output:
1b
1c
29
In general, using manipulators is much easier than setting and unsetting flags. Many options are available via both flags and manipulators (such as changing the base), however, other options are only available via flags or via manipulators, so it’s important to know how to use both.
Useful formatters
Here is a list of some of the more useful flags, manipulators, and member functions. Flags live in the std::ios class, manipulators live in the std namespace, and the member functions live in the std::ostream class.
By now, you should be able to see the relationship between setting formatting via flag and via manipulators. In future examples, we will use manipulators unless they are not available.
Precision, notation, and decimal points
If fixed or scientific notation is used, precision determines how many decimal places in the fraction is displayed. Note that if the precision is less than the number of significant digits, the number will be rounded.
If neither fixed nor scientific are being used, precision determines how many significant digits should be displayed. Again, if the precision is less than the number of significant digits, the number will be rounded.
Width, fill characters, and justification
One thing to note is that setw() and width() only affect the next output statement. They are not persistent like some other flags/manipulators.
23.4 — Stream classes for strings
To use the stringstreams, you need to #include the sstream header.
Conversion between strings and numbers
Because the insertion and extraction operators know how to work with all of the basic data types, we can use them in order to convert strings to numbers or vice versa.
First, let’s take a look at converting numbers into a string:
std::stringstream os;
int nValue{ 12345 };
double dValue{ 67.89 };
os << nValue << ' ' << dValue;
std::string strValue1, strValue2;
os >> strValue1 >> strValue2;
std::cout << strValue1 << ' ' << strValue2 << '\n';
This snippet prints:
12345 67.89
Now let’s convert a numerical string to a number:
std::stringstream os;
os << "12345 67.89"; // insert a string of numbers into the stream
int nValue;
double dValue;
os >> nValue >> dValue;
std::cout << nValue << ' ' << dValue << '\n';
This program prints:
12345 67.89
Clearing a stringstream for reuse
There are several ways to empty a stringstream’s buffer.
When clearing out a stringstream, it is also generally a good idea to call the clear() function:
std::stringstream os;
os << "Hello ";
os.str(""); // erase the buffer
os.clear(); // reset error flags
os << "World!";
std::cout << os.str();
clear() resets any error flags that may have been set and returns the stream back to the ok state. We will talk more about the stream state and error flags in the next lesson.
23.5 — Stream states and input validation
Stream states
If an error occurs and a stream is set to anything other than goodbit, further stream operations on that stream will be ignored. This condition can be cleared by calling the clear() function.
Input validation
Input validation is the process of checking whether the user input meets some set of criteria. Input validation can generally be broken down into two types: string and numeric.
String validation
Numeric validation
If you don’t want such input to be valid, we’ll have to do a little extra work. Fortunately, the previous solution gets us half way there. We can use the gcount() function to determine how many characters were ignored. If our input was valid, gcount() should return 1 (the newline character that was discarded). If it returns more than 1, the user entered something that wasn’t extracted properly, and we should ask them for new input. Here’s an example of this:
#include Numeric validation as a string
As you can see, doing input validation in C++ is a lot of work. Fortunately, many such tasks (e.g. doing numeric validation as a string) can be easily turned into functions that can be reused in a wide variety of situations.
23.6 — Basic file I/O
Author’s note
This lesson and the next were written pre-C++17. In C++17, file I/O is better done using std::filesystem.
File output
File input
Buffered output
Output in C++ may be buffered. This means that anything that is output to a file stream may not be written to disk immediately. Instead, several output operations may be batched and handled together. This is done primarily for performance reasons. When a buffer is written to disk, this is called flushing the buffer. One way to cause the buffer to be flushed is to close the file – the contents of the buffer will be flushed to disk, and then the file will be closed.
Buffering is usually not a problem, but in certain circumstance it can cause complications for the unwary. The main culprit in this case is when there is data in the buffer, and then program terminates immediately (either by crashing, or by calling exit()). In these cases, the destructors for the file stream classes are not executed, which means the files are never closed, which means the buffers are never flushed. In this case, the data in the buffer is not written to disk, and is lost forever. This is why it is always a good idea to explicitly close any open files before calling exit().
It is possible to flush the buffer manually using the ostream::flush() function or sending std::flush to the output stream. Either of these methods can be useful to ensure the contents of the buffer are written to disk immediately, just in case the program crashes.
One interesting note is that std::endl; also flushes the output stream. Consequently, overuse of std::endl (causing unnecessary buffer flushes) can have performance impacts when doing buffered I/O where flushes are expensive (such as writing to a file). For this reason, performance conscious programmers will often use ‘\n’ instead of std::endl to insert a newline into the output stream, to avoid unnecessary flushing of the buffer.
File modes
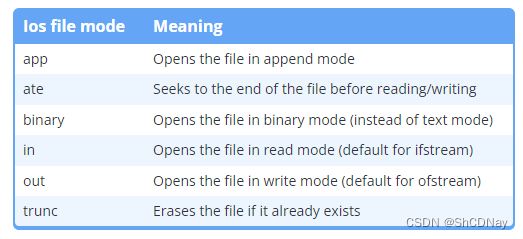
Tip
Due to the way fstream was designed, it may fail if std::ios::in is used and the file being opened does not exist. If you need to create a new file using fstream, use std::ios::out mode only.
Let’s write a program that appends two more lines to the Sample.txt file we previously created:
#include Now if we take a look at Sample.txt (using one of the above sample programs that prints its contents, or loading it in a text editor), we will see the following:
This is line 1
This is line 2
This is line 3
This is line 4
Explicitly opening files using open()
Just like it is possible to explicitly close a file stream using close(), it’s also possible to explicitly open a file stream using open(). open() works just like the file stream constructors – it takes a file name and an optional file mode.
For example:
std::ofstream outf{ "Sample.txt" };
outf << "This is line 1\n";
outf << "This is line 2\n";
outf.close(); // explicitly close the file
// Oops, we forgot something
outf.open("Sample.txt", std::ios::app);
outf << "This is line 3\n";
outf.close();
You can find more information about the open() function here.
23.7 — Random file I/O
The file pointer
Each file stream class contains a file pointer that is used to keep track of the current read/write position within the file. When something is read from or written to a file, the reading/writing happens at the file pointer’s current location. By default, when opening a file for reading or writing, the file pointer is set to the beginning of the file. However, if a file is opened in append mode, the file pointer is moved to the end of the file, so that writing does not overwrite any of the current contents of the file.
Random file access with seekg() and seekp()
Random file access is done by manipulating the file pointer using either seekg() function (for input) and seekp() function (for output).In case you are wondering, the g stands for “get” and the p for “put”. For some types of streams, seekg() (changing the read position) and seekp() (changing the write position) operate independently – however, with file streams, the read and write position are always identical, so seekg and seekp can be used interchangeably.
Reading and writing a file at the same time using fstream
Other useful file functions
To delete a file, simply use the remove() function.
Also, the is_open() function will return true if the stream is currently open, and false otherwise.
A warning about writing pointers to disk
Warning
Do not write memory addresses to files. The variables that were originally at those addresses may be at different addresses when you read their values back in from disk, and the addresses will be invalid.
Appendix A_Miscellaneous Subjects
A.1 — Static and dynamic libraries
There are two types of libraries: static libraries and dynamic libraries.
A static library (also known as an archive) consists of routines that are compiled and linked directly into your program. When you compile a program that uses a static library, all the functionality of the static library that your program uses becomes part of your executable. On Windows, static libraries typically have a .lib extension, whereas on Linux, static libraries typically have an .a (archive) extension.
A dynamic library (also called a shared library) consists of routines that are loaded into your application at run time. When you compile a program that uses a dynamic library, the library does not become part of your executable – it remains as a separate unit. On Windows, dynamic libraries typically have a .dll (dynamic link library) extension, whereas on Linux, dynamic libraries typically have a .so (shared object) extension.
An import library is a library that automates the process of loading and using a dynamic library.
Installing and using libraries
A.2 — Using libraries with Visual Studio
To recap the process needed to use a library:
Once per library:
-
Acquire the library. Download it from the website or via a package manager.
-
Install the library. Unzip it to a directory or install it via a package manager.
Once per project: -
Tell the compiler where to look for the header file(s) for the library.
-
Tell the linker where to look for the library file(s) for the library.
-
Tell the linker which static or import library files to link.
-
#include the library’s header file(s) in your program.
-
Make sure the program know where to find any dynamic libraries being used.
A.3 — Using libraries with Code::Blocks
A.4 — C++ FAQ
There are certain questions that tend to get asked over and over. This FAQ will attempt to answer the most common ones.
Q: Why shouldn’t we use “using namespace std”?
The statement using namespace std; is a using directive. Using directives import all of the identifiers from a namespace into the scope of the using directive.
For this reason, we recommend avoiding using namespace std (or any other using directive) entirely. The small savings in typing isn’t worth the additional headaches and future risks.
Q: Why can I use (some feature) without including header ?
Q: Why does (some code that produces undefined behavior) generate a certain result?
Undefined behavior occurs when you perform an operation whose behavior is not defined by the C++ language. Code implementing undefined behavior may exhibit any of the following symptoms:
Q: I tried to compile an example that should work, but get a compile error. Why?
The most common reason for this is that your project is being compiled using the wrong language standard.
Appendix B_C++ Updates
B.1 — Introduction to C++11
B.2 — Introduction to C++14
B.3 — Introduction to C++17
B.4 — Introduction to C++20
Appendix C_The End
C.1 — The end?
What next?
However, for most users, I think there are a few natural next steps.
Data structures, algorithms, and design patterns
If you haven’t already learned about these, this is my strongest recommendation.
Data structures and algorithms serve the same purpose in programming: they are tools that, if you know how to use them, can vastly accelerate how quickly you can get things done at quality.
Data structures and algorithms give us good tools for storing and manipulating data. However, there is one more tool that we can add to our toolkit that can help us write better programs. A design pattern is a reusable solution to a commonly occurring software design problem.
The C++ standard library
The bulk of the C++ standard library is data structures and algorithms.
Graphical applications
TCP/IP / Network programming (aka. the internets)
Multithreading
Threading is powerful, but it introduces additional complexity, and a lot of room for additional errors. Therefore, I wouldn’t recommend starting here – but it is a good area to learn about eventually, especially if you want to do complex graphical applications or network programming.
Improve your fundamentals
Another option is to spend time improving your understanding of best practices. For this, I highly recommend having a read-through of the CPP Core Guidelines, with an optional delving into the GSL library.
A good bye!
Old programmers never die – they just go out of scope.