postgresql-DML
DML 语句
- 创建示例表
- 插入数据
-
- 插入单行数据
- 插入多行数据
- 复制数据
- 返回插入的数据
- 更新数据
-
- 单表更新
- 跨表更新
- 返回更新后的数据
- 删除数据
-
- 单表删除
- 跨表删除
- 返回被删除的数据
- 合并数据
-
- MERGE 语句
- INSERT ON CONFLICT
- DML 语句与 CTE
创建示例表
CREATE TABLE dept (
department_id int NOT NULL,
department_name varchar(30) NOT NULL,
CONSTRAINT dept_pkey PRIMARY KEY (department_id)
);
CREATE TABLE emp (
employee_id int NOT NULL,
first_name varchar(20) NULL,
last_name varchar(25) NOT NULL,
hire_date date not null default current_date,
salary numeric(8,2) NULL,
manager_id int NULL,
department_id int NULL,
CONSTRAINT emp_pkey PRIMARY KEY (employee_id),
CONSTRAINT fk_emp_dept FOREIGN KEY (department_id) REFERENCES
dept(department_id) ON DELETE CASCADE,
CONSTRAINT fk_emp_manager FOREIGN KEY (manager_id) REFERENCES
emp(employee_id)
);
插入数据
插入单行数据
语法
INSERT INTO table_name(column1, column2, ...)
VALUES (value1, value2, ...);
value1 是 column1 的值,value2 是 column2 的值
insert into public.dept(department_id,department_name)
values(10,'Administration');
插入多行数据
postgresql中的insert语句支持一次插入多行数据,在values之后使用逗号进行分隔
INSERT INTO emp
VALUES (200, 'Jennifer', 'Whalen', '2020-01-01', 4400.00, NULL, 10),
(201, 'Michael', 'Hartstein', '2020-02-02', 13000.00, NULL, 20),
(202, 'Pat', 'Fay', default, 6000.00, 201, 20);
select * from emp;

复制数据
-- 创建表emp1表结构和emp一样
create table emp1 (like emp);
insert into select 语句可以将一个查询语句的结果插入表中
-- 将查询到的emp数据插入到emp1中
insert into emp1 select * from emp;
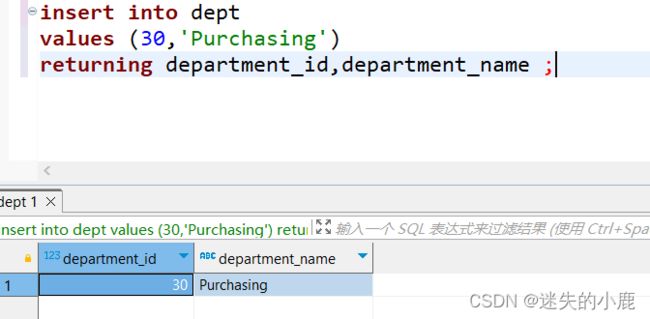
返回插入的数据
insert into dept
values (30,'Purchasing')
returning department_id,department_name ;
更新数据
单表更新
postgresql 使用 update 语句更新表中已有的数据,基本的语法如下:
UPDATE table_name
SET column1 = value1,
column2 = value2,
...
WHERE conditions;
其中,WHERE 决定了需要更新的数据行,只有满足条件的数据才会更新;如果省略 WHERE
条件,将会更新表中的所有数据,需要谨慎使用
-- 将编号为 200 的员工从原部门调动到 Marketing,并且涨薪 1000
UPDATE emp1
SET salary = salary + 1000,
department_id = 20
WHERE employee_id = 200;
跨表更新
-- 跨表更新
-- postgresql 还支持通过关联其他表中的数据进行更新。以下语句利用 emp 中的数据更新 emp1 表
update emp1 e
set salary = t.salary
from emp t
where t.employee_id = e.employee_id;

返回更新后的数据
postgresql 同样对 update 语句进行了扩展,支持使用 returning 返回更新后的数据值
-- 跨表更新
-- postgresql 还支持通过关联其他表中的数据进行更新。以下语句利用 emp 中的数据更新 emp1 表
update emp1 e
set salary = t.salary
from emp t
where t.employee_id = e.employee_id
-- * 返回更新后表中的所有列
returning *;

删除数据
单表删除
-- table 表名 相当于select * from 表名
table emp1;
-- 只有满足 WHERE 条件的数据才会被删除;如果省略,将会删除表中所有的数据
-- 删除 emp1 中员工编号为 201 的数据
-- 如果没有编号为 201 的记录,不会删除任何数据
delete from cps.public.emp1 e where e.employee_id = 202;
跨表删除
-- postgresql 同样支持通过关联其他表进行数据删除
-- 利用 emp 表删除 emp1 表中全部的数据
delete
from emp1
using emp
where emp1.employee_id = emp.employee_id;
跨表删除使用 using 关键字引用其他的表,而不是 join。以上语句了 emp1 中员工
编号存在于 emp 表中的数据,等价于以下子查询实现:
delete
from emp1
where emp1.employee_id in (select employee_id from emp);
返回被删除的数据
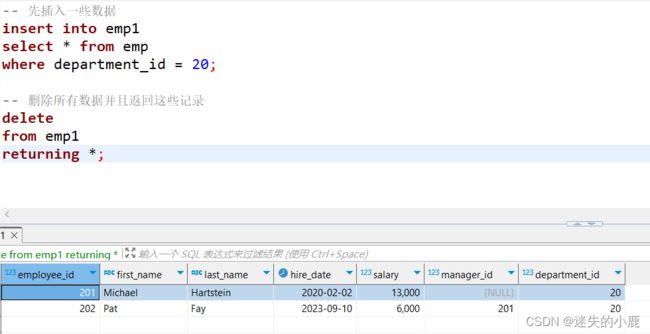
postgresql 中的 delete 语句也可以使用 returning 返回被删除的数据。例如:
-- 删除所有数据并且返回这些记录
delete
from emp1
returning *;
合并数据
MERGE 语句

创建示例表
CREATE TABLE account (
id INTEGER PRIMARY KEY,
balance NUMERIC NOT NULL,
status VARCHAR(1) NOT NULL CHECK (status IN ('Y', 'N'))
);
-- 使用以下语句为 account 表新增一条记录:
/*
* WHEN MATCHED THEN:数据匹配上时候的操作
* WHEN NOT MATCHED THEN:数据没有匹配上时候的操作
*/
MERGE INTO account a
USING (VALUES(1, 0, 'Y')) s(id, balance, status)
ON a.id = s.id
WHEN MATCHED THEN
UPDATE SET balance = s.balance, status = s.status
WHEN NOT MATCHED THEN
INSERT (id, balance, status)
VALUES (s.id, s.balance, s.status);
由于 id 等于 1 的记录不存在,以上语句将会执行 WHEN NOT MATCHED THEN 分支,插
入一条新的记录。
接下来我们将插入源数据中的 balance 修改为 100,再次执行 MERGE 语句:
-- 以下语句将会执行 WHEN MATCHED THEN 分支,更新 account 表中 id 等于 1 的记录。
MERGE INTO account a
USING (VALUES(1, 100, 'Y')) s(id, balance, status)
ON a.id = s.id
WHEN MATCHED THEN
UPDATE SET balance = s.balance, status = s.status
WHEN NOT MATCHED THEN
INSERT (id, balance, status)
VALUES (s.id, s.balance, s.status);
--最后,我们在 MERGE 语句中增加一个分支,用于删除数据:
/*
* 语句中的 WHEN MATCHED AND s.status = ‘N’ THEN 表示如果源数据存在,
* 并且源数据中的状态为 N,则删除目标表中的对应记录
* */
MERGE INTO account a
USING (VALUES(1, 100, 'N')) s(id, balance, status)
ON a.id = s.id
WHEN MATCHED AND s.status = 'N' THEN
DELETE
WHEN MATCHED THEN
UPDATE SET balance = s.balance, status = s.status
WHEN NOT MATCHED THEN
INSERT (id, balance, status)
VALUES (s.id, s.balance, s.status);
INSERT ON CONFLICT
对于 PostgreSQL 14 以及更早版本,可以通过 INSERT INTO … ON CONFLICT… 实现数据
合并的功能

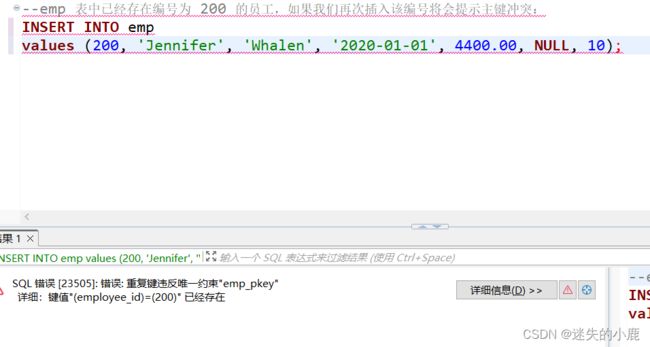
--emp 表中已经存在编号为 200 的员工,如果我们再次插入该编号将会提示主键冲突:
--增加冲突处理,从而避免语句出错
INSERT INTO emp
values (200, 'Jennifer', 'Whalen', '2020-01-01', 4400.00, NULL, 10)
--基于 employee_id 字段是否重复进行判断,冲突时不做任何处理
on conflict (employee_id)
do nothing
;
--emp 表中已经存在编号为 200 的员工,如果我们再次插入该编号将会提示主键冲突:
--增加冲突处理,从而避免语句出错
INSERT INTO emp
values (200, 'Jennifer', 'Whalen', '2020-01-01', 4400.00, NULL, 10)
--基于 employee_id 字段是否重复进行判断,冲突时进行数据更新
on conflict on constraint emp_pkey
do update
set first_name = EXCLUDED.first_name,
last_name = EXCLUDED.last_name,
hire_date = EXCLUDED.hire_date,
salary = EXCLUDED.salary,
manager_id =EXCLUDED.manager_id,
department_id = EXCLUDED.department_id;
/*该员工的部门编号在前面被修改为 20;我们通过主键约束 emp_pkey 进行重复数据的判断,
*然后更新该员工的数据;
*EXCLUDED 是一个特殊的表,代表了原本应该插入的数据行;最终该
*员工的部门编号被更新为 10。
*/
select * from emp e where e.employee_id =200;

DML 语句与 CTE
除了 SELECT 语句之外,INSERT、UPDATE 或者 DELETE 语句也可以与 CTE 一起使用。
我们可以在 CTE 中使用 DML 语句,也可以将 CTE 用于 DML 语句
如果在 CTE 中使用 DML 语句,我们可以将数据修改操作影响的结果作为一个临时表,然
后在其他语句中使用
-- 创建一个员工历史表
CREATE TABLE employees_history
AS SELECT * FROM employees WHERE 1 = 0;
WITH deletes AS (
-- 返回删除的数据
DELETE FROM employees
WHERE employee_id = 206
RETURNING *
)
-- 将删除的数据插入到employees_history表中
INSERT INTO employees_history
SELECT * FROM DELETEs;
-- 查询数据
SELECT employee_id, first_name, last_name
FROM employees_history;
我们首先创建了一个记录员工历史信息的 employees_history 表;然后使用 DELETE 语句定
义了一个 CTE,RETURNING *返回了被删除的数据,构成了结果集 deletes;然后使用 INSERT
语句记录被删除的员工信息
WITH inserts AS (
INSERT INTO employees
VALUES
(207,'William','Gietz','11','515.123.8181','2002-06-07','AC_ACCOUNT',8800.00,NULL,205,110)
RETURNING *
)
-- inserts插入的结果集插入到employees_history表中
INSERT INTO employees_history
SELECT * FROM inserts;
/*
* returning 在 CTE 中,UPDATE 语句修改了一个员工的月薪;但是为了记录修改之前的数据,
* 我们插入 employees_history 的数据仍然来自 employees 表。
* 因为在一个语句中,所有的操作都在一个事务中,所以主查询中的 employees 是修改之前的状态
*/
WITH updates AS (
UPDATE employees
SET salary = salary + 500
WHERE employee_id = 206
RETURNING *
)
INSERT INTO employees_history
SELECT * FROM employees WHERE employee_id = 206;
--获取更新之后的数据,直接使用 updates
WITH updates AS (
UPDATE employees
set salary = salary - 500
WHERE employee_id = 206
RETURNING *
)
SELECT employee_id,first_name, last_name, salary
FROM updates;