嗖一下【基于命令行交互的文件搜索工具】实现思路
目录
一、背景
二、实现功能(todo)
三、效果展示
四、分析
存储文件位置分析
存储文件内容分析
打印文件信息分析
五、实现
六、使用
七、代码实现
八、总结
九、项目测试
一、背景
有时候需要在Windows命令行下搜索文件,而搜索文件所用的命令:
for /r 目录名 %i in (匹配模式1,匹配模式2) do @echo %i
并不那么好用(个人觉得命令输入不便,且不方便记忆)。
以在D盘Program Files (x86)下查找目录MathType下的所有子目录及文件为例,需在命令行窗口下输入for /r MathType %i in (*) do @echo %i命令:
D:\Program Files (x86)>for /r MathType %i in (*) do @echo %i
部分查询结果如下:
D:\Program Files (x86)\MathType\MathType.exe
D:\Program Files (x86)\MathType\MPlugin.dll
D:\Program Files (x86)\MathType\MT6enu.chm
D:\Program Files (x86)\MathType\Setup.exe
D:\Program Files (x86)\MathType\Fonts\FontInfo.ini
D:\Program Files (x86)\MathType\Fonts\PostScript\euclid.afm
D:\Program Files (x86)\MathType\Fonts\PostScript\euclid.pfb
D:\Program Files (x86)\MathType\Fonts\PostScript\euclid.pfm
D:\Program Files (x86)\MathType\Fonts\PostScript\euclidb.afm
D:\Program Files (x86)\MathType\Fonts\PostScript\euclidb.pfb
正是由于Windows自带的搜索功能不那么好用,且不能跨盘符搜索,所以Everything文件搜索软件就诞生了。
使用过Everything文件搜索软件的都知道,随机输入一个字或词就会出现相应的文件信息【包括文件名称,文件路径,文件大小和文件最近修改时间】。以搜索WPS为例,搜索结果如下:
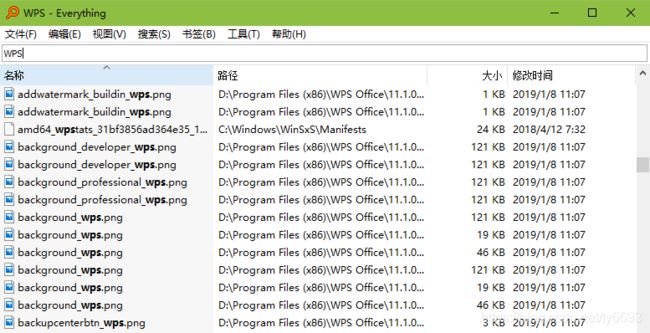
那么这么好用的一款文件搜索软件,我们是不是也可以仿照它DIY一个Java语言开发的命令行文件搜索工具呢
二、实现功能(todo)
帮助:help
索引:index
检索:search
1)支持输入文件名进行检索
2)支持输入文件名 + 文件类型进行检索
退出:quit
三、效果展示
使用效果展示:


四、分析
存储文件位置分析:
我们知道通过遍历磁盘来查询文件速度会很低,那么为了让查询速度变快,我们是不是可以在第一次遍历磁盘的时候就将遍历所得的文件信息存储到“某个地方”,以后查询的时候只需从前面所述的“某个地方”查询,而不用一次次遍历磁盘呢?答案是可以的。
那么此时我们应该思考的就是将遍历磁盘所得的大量文件信息存放到哪儿查询起来才会更快呢?
相信我们都会不自觉地想到数据库,因为数据库不仅可以存放海量数据,对数据的查询和管理也特别方便。--> 存入MySQL数据库中。由于访问数据库的各种操作(增删改查)都需要进行数据库连接和释放连接动作,会耗费很多时间,所以为了提高数据库访问效率,我们采用数据库连接池的方式,通过数据源DataSource对象获取连接【通过数据源从数据库连接池中获取连接】。
存储文件内容分析:
我们知道不论是文件还是文件夹,都有文件名,文件大小,文件路径和文件最近修改时间。所以为了跟Everything文件搜索软件搜索所得的文件信息一致,我们也可以将上述4个信息存入到数据库中。
其次,为了查询方便,我们可以在查询时选择性地输入文件类型,这样可以快速排除不符合类型的文件。那么就需要我们将文件类型也存到数据库中。但是由于文件类型众多,全部存到数据库中不利于管理,我们可以将文件类型抽象成一个类,并将类的属性设置为常见的几大类文件类型,比如文本类型、图片类型等。
另外,由于检索后的文件可能有很多,我们可以按文件路径深度升序或者降序排列,所以自然而然就应该把文件路径的深度也存到数据库中。
打印文件信息分析:
打印信息跟Everything搜索软件的显示结果一样,包含文件名,文件大小,文件路径和文件最近修改时间。
五、实现
实现之前先来看一下大致实现框架:

接下来进行具体实现:
首先我们创建一个Maven项目,并配置pom文件。其中配置pom文件的时候应该包括打包格式、属性信息【编码格式;版本;Maven编译目标和Maven源码】、项目依赖【为了减少代码量,可引入Lombok插件;MySQL数据库以及驱动;数据库连接池】等。
jar
UTF-8
1.8
${java.version}
${java.version}
org.projectlombok
lombok
1.18.6
mysql
mysql-connector-java
5.1.47
com.alibaba
druid
1.1.2
接着,
由于该项目是基于命令行的文件搜索工具,那么我们必不可少地要有命令行交互相关的代码;
其次,既然要实现搜索查询等功能,那肯定不能忘了核心业务相关的代码;
最后,为了提高检索速度,我们还可以加一些项目配置相关的代码,具体要配置些啥后面会介绍到。
综上,为了方便编写代码和检查代码,我们可以创建三个包将上述三大类分开:cmd、config和core包。
cmd包中主要存放命令行的交互主程序
config包主要存放配置相关的类
core包主要存放核心功能代码

现在,我们先对core包底下存放的内容进行分析:
由于core包中主要存放的是核心业务相关代码,所以关于文件存储位置、文件存储内容等信息我们都应该放在core包下。
从前边对文件存储内容分析中我们可以知道,我们要对文件的名称、路径、路径深度、大小、类型和最近修改时间这些信息进行存储,所以我们可以将其抽象成一个类【Thing类】。接着,前边也提到过,为了提高检索速度,我们可以增加文件类型属性,在检索时只需要输入文件名和文件类型就可以排除好多不符合的文件。而由于文件类型众多,为了方便管理,我们将文件类型抽象成使用enum定义的枚举类,里边主要存放大类的文件类型【FileType类】。而对于检索时输入的条件,比如文件名、文件类型等我们也可以抽象成一个类【Condition类】。最后将这三个类统一放到core包下的一个包中【model包】。

此时Thing类、FileType类和Condition类三个类各自独立,而我们的目的是希望将Thing类中的属性值存到数据库中,然后设计一个数据库表,最终通过查询数据库表获取文件信息,那么必不可少,我们要跟数据库打交道:
1. 创建数据库脚本【右击resources,新建一个文件(以.sql为扩展名)】

2. 进入到脚本中,创建数据库表,将Thing类中的属性存入表中
3. 进行数据库编程(DAO:Data Access Object)【在core包下新建一个dao包,专门存放数据库相关代码】

3.1 创建数据源DataSource【依赖druid数据库连接池】
我们可以用一个类DataSourceFactory专门来创建数据源,而由于连的是一个数据库,因此不需要反复实例化数据源对象,自然我们就可以让其成为一个单例对象。
3.2 执行数据库脚本
由于SQL语句在resources目录下,而resources目录下的文件在classPath路径下(编译后的sql文件在target目录的classes目录下),所以我们可以通过classLoader来加载(获得当前类加载器)->DataSourceFactory.class.getClassLoader().getResourceAsStream(“文件资源名称”)方法 (作用:读取文件资源并转化成流)的方式获取SQL语句

3.3 对数据库中的表进行增删查操作
我们可以在dao下下定义一个接口FileIndexDao,里边存放增删查的抽象方法,让子类FileIndexDaoImpl去实现接口中的抽象方法【面向接口编程思想】。
那么此时我们要是想从数据库中查询文件信息的话,只需要通过FileIndexDao的对象,调用对应查询方法就可以啦。而为了让检索业务跟数据库相关业务没有直接关联关系,我们新建一个search包,在该包下定义一个FileSearch接口,里边定义一个检索数据库的抽象方法,然后定义一个实现类FileSearchImpl来实现该接口。
对应的,要插入文件信息到数据库,我们也是通过FileIndexDao的实例化对象,调用对应插入方法就可以啦。但是这里有一点需要注意的是,由于我们在扫描遍历各盘符的时候,得到的只是文件的路径信息,所以在往数据库中插入文件信息之前,我们需要做一个转换工作,根据文件的路径信息获取File对象,并将其转换成Thing对象。所以我们可以在core包下新建一个interceptor包,在该包下定义一个文件处理器类FileInterceptor来专门做转换和插入工作,而又在core包下新建一个index包,在该包下新建一个FileScan类专门做扫描遍历的工作。当然,在做遍历工作的同时,我们可以调用处理器进行文件的转换和插入工作。对于文件的转换工作,我们在core包下的common包下新建一个FileConvertThing类来专门实现。


![]()
而实际上,不论是windows下还是linux下,对于有些系统文件我们并不关心其中包含哪些文件,所以在进行盘符遍历时我们可以适当的排除某些文件,比如C 盘下的Windows目录,Program Files,Program Files (x86),ProgramData等,Linux下的etc,root目录等。所以在进行盘符遍历的时候,如果遇到此类目录,我们便可跳过。当然,我们也实现了让用户可以自定义排除目录的功能。而这就是所谓的配置信息【在config包下新建一个EverythingPConfig类实现配置功能】。
![]()
到这儿我们的功能貌似都实现完了,但是,回想一下,我们的检索和扫描插入文件信息好像都是各自分离的,而为了让客户能更好地使用这些功能,我们需要一个调度器来调度这些业务。所以我们在core包下新建一个EverythingPManager类来实现调度功能。
但是回顾一下我们会发现,如果文件已经被我们删除,而检索时却能显示出该文件对应的信息,这会是很不妥的一件事情,所以,为了避免此类事件的发生,我们可以在检索后返回的List集合中利用过滤器filter将满足条件的筛选出来,将不满足条件【检测时如果发现Thing对应的文件已不存在】的交给清理线程处理。

但是如果又新增了文件怎么办呢?别急,这里有两种解决办法:
第一种:重新索引一次【重新扫描遍历盘符并插入一次】
第二种:采用文件系统监控,每隔一段时间监控一下文件的变化【包括文件的新增、删除等】,并作出对应处理
对应第一种方法,我们只要调用一下对应重建索引的函数就可以了。
所以现在我们主要来说一下第二种方法的实现:
这里有两种方案实现文件系统的监控:
第一种方案:JDK提供的文件系统监控【深度受限,不采用】

但是由于其中的WatchService方法监听时深度受限:只能监听一级目录,无法监听更深层次目录。所以我们并不采取这种方案
第二种方案:Apache Commons IO 开源库

File Monitor:用于监视文件系统事件的组件
org.apache.commons.io.monitor包提供了监控文件系统事件的组件,包括文件和目录的创建,更新和删除事件:

对应的Maven依赖:
commons-io
commons-io
2.6
其中,
FileAlterationMonitor:每间隔一段时间调用一次已注册的观察者observer检查文件,相当于指挥官、调度器一样。
FileAlterationObserver:检查文件系统的变化并通知侦听器创建、更改或删除事件。
FileAlterationListener:接收文件系统修改事件的侦听器。专门用来接收文件系统(发生变化)的通知,如果发生变化,则通过实现Listener接口处理业务。


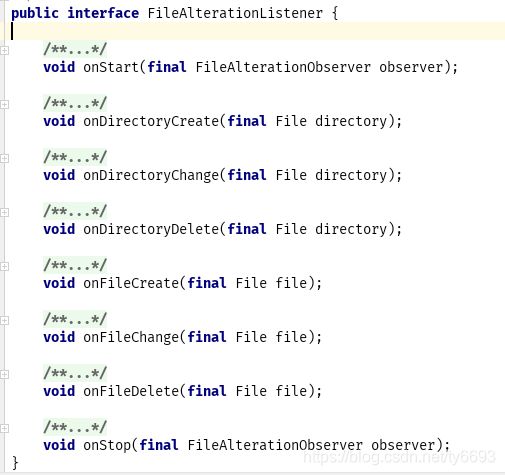
接着我们就可以通过对上述三个类或接口编程以达到对文件系统的监控了。
六、使用
由于是命令行文件搜索工具,当然少不了命令啦。那么接下来我们来看一下都有哪些命令供我们使用呢:
帮助:help
退出:quit
索引:index
检索:search[ img | doc | bin | archive | other]
由于我们配置了默认的排除目录和包含目录,如果用户想自定义的话也是可以的,只需要输入对应参数即可:
--maxReturnThingRecode=数值 //文件信息的显示数目,默认30
--orderByAsc=true/false //以文件路径深度升序或降序显示,默认为true【表示升序显示】
--includePath=文件路径 //表示要遍历的文件路径,多路径以分号隔开
--excludePath=文件路径 //表示要排除的文件路径,多路径以分号隔开
--interval=数值 //文件系统监控的时间间隔,默认为10
用户自定义参数输入格式可参考下面的图片:
![]()
七、代码实现
github地址:https://github.com/huiforeverlin/everythingP
八、项目测试
测试环境:Windows10 ;处理器:AMD A8-8600P Radeon R6, 10 Compute Cores 4C+6G 1.60GHz;内存:4.00GB
文件总数:601277个

利用正交排列法对参数填写部分进行测试:
约定:1-填写 2-不填写
| 序号 |
1 |
2 |
3 |
4 |
5 |
| 因素名称 |
最多显示个数 |
升/降序显示 |
监控间隔时间 |
遍历路径 |
排除路径 |
| 水平1 |
1 |
1 |
1 |
1 |
1 |
| 水平2 |
2 |
2 |
2 |
2 |
2 |
因素数C=5;水平数T=2;行数N=因素数*(水平数-1)+1=5*(2-1)+1=6
L=N(TC)=6(24)
选择正交表L6_2_4
| 所在列 |
1 |
2 |
3 |
4 |
5 |
| 因素 |
最多显示个数 |
升/降序显示 |
监控间隔时间 |
遍历路径 |
排除路径 |
| 试验1 |
1 |
1 |
1 |
1 |
1 |
| 试验2 |
1 |
1 |
2 |
1 |
2 |
| 试验3 |
1 |
2 |
1 |
2 |
2 |
| 试验4 |
2 |
1 |
2 |
1 |
2 |
| 试验5 |
2 |
2 |
1 |
2 |
1 |
| 试验6 |
2 |
2 |
2 |
2 |
1 |
增补测试用例:
最多显示记录数、升/降序显示、监控间隔时间、遍历路径、排除路径都不填写