【100天精通Python】Day60:Python 数据分析_Pandas高级功能-数据透视表pivot_table()和数据交叉表crosstab()常用功能和操作
目录
1 数据透视表和交叉表pivot_table(),crosstab()
2 Pandas数据透视表常用操作
2.1 自定义聚合函数
2.2 指定多个聚合函数
2.3 处理缺失值
2.4 更改行和列的顺序
2.5 重新排列多层索引
3 数据交叉表常用功能
3.1 计算频率表
3.2 计算百分比表
3.3 使用 margins 参数计算边际频率
3.4 使用 values 参数进行加权计算
3.5 自定义聚合函数
1 数据透视表和交叉表pivot_table(),crosstab()
数据透视表:使用
pivot_table()方法,你可以根据一个或多个列的值对数据进行汇总和分析。你可以指定哪些列作为索引,哪些列作为值,以及如何进行聚合计算。交叉表:使用
pd.crosstab()函数,你可以计算两个或多个因素之间的交叉频率,特别适用于分类数据的汇总分析。
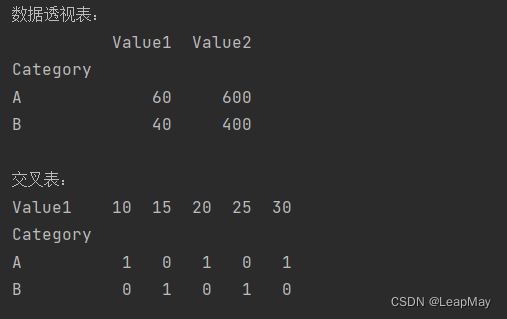
数据透视表和交叉表示例:
import pandas as pd
# 创建一个示例DataFrame
data = {'Category': ['A', 'B', 'A', 'B', 'A'],
'Value1': [10, 15, 20, 25, 30],
'Value2': [100, 150, 200, 250, 300]}
df = pd.DataFrame(data)
# 创建数据透视表
pivot_table = pd.pivot_table(df, values=['Value1', 'Value2'], index='Category', aggfunc='sum')
# 创建交叉表
cross_table = pd.crosstab(df['Category'], df['Value1'])
print("数据透视表:")
print(pivot_table)
print("\n交叉表:")
print(cross_table)
2 Pandas数据透视表常用操作
Pandas 的数据透视表(Pivot Table)提供了丰富的高级选项,允许你自定义数据的汇总方式、聚合函数、行和列的顺序等。以下是一些常见的高级选项示例:
2.1 自定义聚合函数
默认情况下,pivot_table() 使用平均值作为聚合函数。但你可以使用 aggfunc 参数来指定自定义的聚合函数,例如 sum、count、max、min 等,甚至可以传递自己编写的函数。
import pandas as pd
# 创建一个示例DataFrame
data = {'Category': ['A', 'A', 'B', 'B', 'A', 'A'],
'Value': [10, 20, 15, 25, 5, 10]}
df = pd.DataFrame(data)
# 创建数据透视表,使用自定义聚合函数计算总和
pivot_table = pd.pivot_table(df, values='Value', index='Category', aggfunc='sum')
print(pivot_table)
输出:

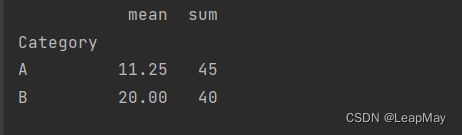
2.2 指定多个聚合函数
你可以同时指定多个聚合函数,以便在数据透视表中显示多个统计结果。
import pandas as pd
# 创建一个示例DataFrame
data = {'Category': ['A', 'A', 'B', 'B', 'A', 'A'],
'Value': [10, 20, 15, 25, 5, 10]}
df = pd.DataFrame(data)
# 创建数据透视表,同时计算总和和平均值
pivot_table = pd.pivot_table(df, values='Value', index='Category', aggfunc={'Value': ['sum', 'mean']})
print(pivot_table)
输出:
2.3 处理缺失值
你可以使用 fill_value 参数来指定如何处理数据透视表中的缺失值(NaN)。
import pandas as pd
import numpy as np
# 创建一个示例DataFrame,包含缺失值
data = {'Category': ['A', 'A', 'B', 'B', 'A', 'A'],
'Value': [10, np.nan, 15, 25, np.nan, 10]}
df = pd.DataFrame(data)
# 创建数据透视表,指定如何处理缺失值
pivot_table = pd.pivot_table(df, values='Value', index='Category', aggfunc=np.mean, fill_value=0)
print(pivot_table)
在这个示例中,我们使用
np.NaN表示缺失值,然后通过fill_value=0参数告诉pivot_table在计算平均值时将缺失值替换为0。这将产生一个数据透视表,其中缺失值已被替换为0,并计算了平均值。
2.4 更改行和列的顺序
在 Pandas 中,你可以使用不同的方法来更改行和列的顺序,具体取决于你的需求。以下是一些示例:
更改行的顺序:
(a)使用 reindex() 方法:reindex() 方法允许你按照特定的顺序重新排列DataFrame的行。
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df0 = pd.DataFrame(data)
# 指定新的行顺序
new_order = [2, 0, 1]
# 使用reindex()重新排列行
df1 = df0.reindex(new_order)
print("df0 \n", df0)
print( "df1\n", df1)
输出:

(b)使用 iloc 属性:iloc 属性允许你按照整数位置选择行,并以指定的顺序重新排列它们。
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
# 指定新的行顺序
new_order = [2, 0, 1]
# 使用iloc重新排列行
df = df.iloc[new_order]
print(df)
输出:

更改列的顺序:
(a)使用列名列表:你可以使用列名列表以所需的顺序重新排列DataFrame的列。
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
# 指定新的列顺序
new_order = ['B', 'A']
# 重新排列列
df = df[new_order]
print(df)
输出:

(b)使用 reindex() 方法:你也可以使用 reindex() 方法来重新排列列,但要指定axis=1。
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
# 指定新的列顺序
new_order = ['B', 'A']
# 使用reindex()重新排列列
df = df.reindex(columns=new_order)
print(df)
输出:

2.5 重新排列多层索引
reorder_levels() 是 Pandas 中用于重新排列多层索引(MultiIndex)级别的方法。它允许你更改多层索引的层次顺序,以适应不同的需求。以下是关于 reorder_levels() 的详细解释和示例:
reorder_levels() 方法的语法:
DataFrame.reorder_levels(order, axis=0)
参数说明:
order:一个整数列表或元组,表示你希望将多层索引的哪些级别移动到前面。这里的整数是级别的位置,从0开始。例如,如果你的多层索引有两个级别(0和1),你可以使用[1, 0]来交换这两个级别的顺序。axis:指定要重新排序级别的轴,0 表示行索引,1 表示列索引。
示例:
让我们通过一个示例来了解如何使用 reorder_levels() 方法:
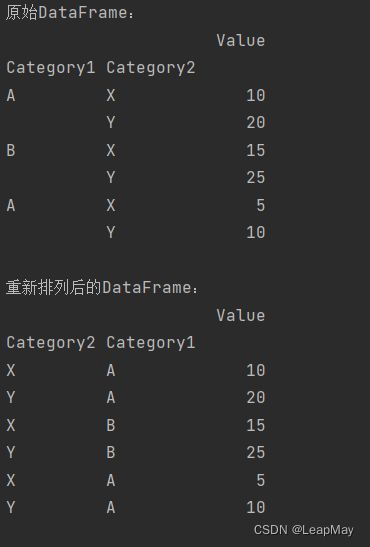
import pandas as pd
# 创建一个示例DataFrame
data = {'Category1': ['A', 'A', 'B', 'B', 'A', 'A'],
'Category2': ['X', 'Y', 'X', 'Y', 'X', 'Y'],
'Value': [10, 20, 15, 25, 5, 10]}
df = pd.DataFrame(data)
# 将多层索引设置为行索引
df.set_index(['Category1', 'Category2'], inplace=True)
# 输出原始DataFrame
print("原始DataFrame:")
print(df)
# 使用reorder_levels()重新排列多层索引
df_reordered = df.reorder_levels([1, 0], axis=0)
# 输出重新排列后的DataFrame
print("\n重新排列后的DataFrame:")
print(df_reordered)
在这个示例中,我们首先将多层索引设置为行索引。然后,我们使用
reorder_levels([1, 0], axis=0)将索引级别重新排列,将 "Category2" 放在前面,然后 "Category1"。
输出:
3 数据交叉表常用功能
3.1 计算频率表
最基本的用法是计算两个或多个因素的交叉频率。例如,你可以使用交叉表来计算性别与职业的分布情况。
import pandas as pd
# 创建一个示例DataFrame
data = {'Gender': ['Male', 'Female', 'Male', 'Female', 'Male'],
'Occupation': ['Engineer', 'Doctor', 'Doctor', 'Engineer', 'Doctor']}
df = pd.DataFrame(data)
# 创建交叉表
cross_table = pd.crosstab(df['Gender'], df['Occupation'])
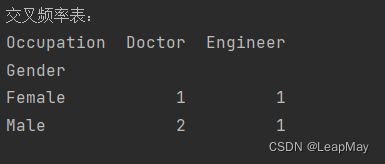
print("交叉频率表:")
print(cross_table)
使用
pd.crosstab()函数来创建交叉频率表。在这个函数中,你传递了两个参数:
df['Gender']:这是要分析的第一个分类变量,表示性别。df['Occupation']:这是要分析的第二个分类变量,表示职业。- 结果表格的行表示性别(Male 和 Female),列表示职业(Engineer 和 Doctor),每个单元格中的值表示相应性别和职业组合的数量。显示了示例数据中性别和职业的分布情况。
3.2 计算百分比表
你可以将 normalize 参数设置为 True,以计算百分比表,显示每个单元格的相对频率而不是绝对频率。
cross_table = pd.crosstab(df['Gender'], df['Occupation'], normalize=True)
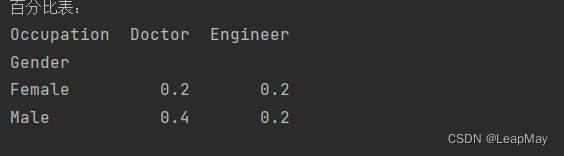
print("百分比表:")
print(cross_table)
创建交叉表并计算百分比表:使用
pd.crosstab()函数创建交叉频率表,但在此次使用了normalize=True参数。这个参数的作用是将表格中的值转换为相对频率(百分比)。这意味着每个单元格中的值表示相应性别和职业组合的相对频率,而不是绝对数量。 每个单元格中的值表示相应性别和职业组合的百分比。
输出结果:
3.3 使用 margins 参数计算边际频率
你可以通过将 margins 参数设置为 True 来计算边际频率,这将在表中添加行和列的边际总计。
cross_table = pd.crosstab(df['Gender'], df['Occupation'], margins=True)
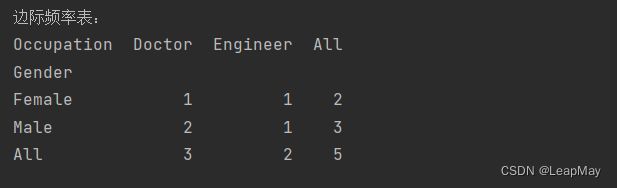
print("边际频率表:")
print(cross_table)
创建交叉表并计算边际频率表:使用
pd.crosstab()函数创建交叉频率表,但在此次使用了margins=True参数。这个参数的作用是在表格中添加行和列的边际总计。这将在结果表格的右侧和底部分别添加边际总计行和列。 边际总计行显示了每个性别的总数量,边际总计列显示了每个职业的总数量
3.4 使用 values 参数进行加权计算
如果你有一个权重列,可以使用 values 参数来执行加权计算。
data = {'Gender': ['Male', 'Female', 'Male', 'Female', 'Male'],
'Occupation': ['Engineer', 'Doctor', 'Doctor', 'Engineer', 'Doctor'],
'Weight': [150, 160, 140, 170, 155]}
df = pd.DataFrame(data)
# 创建交叉表,使用Weight列进行加权计算
cross_table = pd.crosstab(df['Gender'], df['Occupation'], values=df['Weight'], aggfunc='sum')
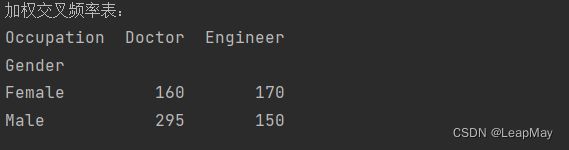
print("加权交叉频率表:")
print(cross_table)
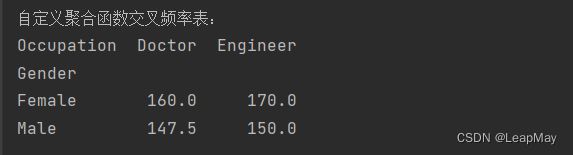
3.5 自定义聚合函数
你可以使用
aggfunc参数指定自定义聚合函数,例如np.mean、np.sum、lambda x: x.max() - x.min()等。
import numpy as np
# 创建交叉表,使用自定义聚合函数
cross_table = pd.crosstab(df['Gender'], df['Occupation'], values=df['Weight'], aggfunc=np.mean)
print("自定义聚合函数交叉频率表:")
print(cross_table)
创建交叉表并使用自定义聚合函数:使用
pd.crosstab()函数创建交叉频率表,但在此次的参数中使用了values和aggfunc。具体如下:
df['Gender']:指定要分析的第一个分类变量,表示性别。df['Occupation']:指定要分析的第二个分类变量,表示职业。values=df['Weight']:将Weight列作为值变量,这意味着我们将在交叉表中应用自定义聚合函数到Weight列上。aggfunc=np.mean:指定自定义聚合函数为 NumPy 中的均值函数np.mean,这将计算每个性别和职业组合的体重均值。交叉频率表中每个单元格中的值表示相应性别和职业组合的体重均值。
输出: