Hive——数据库、表的增删改查 (每一步详细代码加截图,傻瓜式教程)
我们安装完Hive,配置好hive-site.xml文件,其中我把hive在hdfs路径设置为hive110/warehouse
启动hadoop
hdfs dfs -chmod -R 777 /hive110给所有组加最高权限,方便以后操作

登录hive,这里我直接使用本地登录,也就不适用hiveserver2了
数据库
一、创建数据库
- 创建数据库,数据库在 HDFS 上的默认存储路径是/hive110/warehouse/*.db。(也就是自己在hive-site.xml里的设置)
create database stu

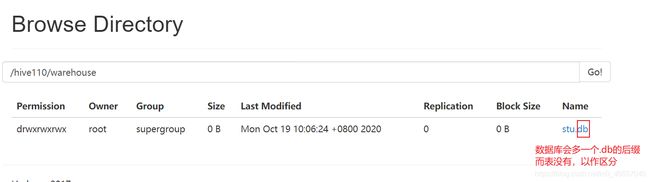
- 避免要创建的数据库已经存在错误,增加 if not exists 判断。(标准写法)

- 创建一个数据库,指定数据库在 HDFS 上存放的位置,这样就不会在默认的路径创建数据库了
create database stu2 location ‘/stu2’;
二、查看数据库
- 显示数据库
hive> show databases; - 过滤显示查询的数据库
hive> show databases like ‘stu*’;

- 显示数据库信息
hive> desc database stu;

这样看感觉比较乱,所以我想为结果加一个列名,并指定当前所在的数据库,在hive-site.xml文件插入如下信息

重启一下hive

三、修改数据库
数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
比如修改数据库的创建时间
hive (default)> alter database stu set dbproperties(‘createtime’=‘20170830’);
四、 删除数据库
(危险操作,尽量少用)
- 删除空数据库
hive>drop database stu; - 如果删除的数据库不存在,最好采用 if exists 判断数据库是否存在
hive> drop database stu3;
FAILED: SemanticException [Error 10072]: Database does not exist:stu3
hive> drop database if exists stu3; - 如果数据库不为空,可以采用 cascade 命令,强制删除
hive> drop database stu cascade
表
一、增加表
(标红是常用语句)
create[external] table[if not exists] table_name
[(col_name data_type, …)]
[partition by (col_name data_type, …)]
[clustered by (col_name, col_name, …)
[sorted by (col_name [asc|desc], …)] into num_buckets buckets]
[row format row_format]
[stored as file_format]
[location hdfs_path]
字段解释说明
(1)create table table_name 创建一个指定名字的表。如果相同名字的表已经存在,则抛出
异常;用户可以用 if not exists 选项来忽略这个异常。
(2)external关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(location),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。因为表是外部表,所以 Hive 并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。在删除表的
时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)comment:为表和列添加注释。
(4)partition by创建分区表
(5)clustered by创建分桶表
(6)stored by不常用
(7)row format delimited
后面跟
fields terminated by ‘,’ --列分隔符
collection items terminated by ‘_’ --map struct和 array的分隔符(数据分割符号)
map keys terminated by ‘:’ – map中的 key 与 value 的分隔符
lines terminated by ‘\n’; – 行分隔符
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW
FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户
还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe
确定表的具体的列的数据。
SerDe 是 Serialize/Deserilize 的简称,目的是用于序列化和反序列化。
(8)stored as 指定存储文件类型
常用的存储文件类型:sequencefile(二进制序列文件)、textfile(文本)、
rcfile(列式存储格式文件)
如果文件数据是纯文本,可以使用 stored as textfile。如果数据需要压缩,
使用 stored as sequencefile。
(9)location:指定表在 HDFS 上的存储位置。
(10)like:允许用户复制现有的表结构,但是不复制数据。
增加数据
dept.txt文件内容,把它放到/root目录下
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
在stu数据库创建dept表
create external table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by ‘\t’;
一般我们都是直接用lode命令导入数据,不用insert into table values… 因为不可能一条条的插入,效率极低
第一种方法: 这是把本地文件导入表:hive (default)> load data local inpath ‘/root/dept.txt’ into table stu.dept;
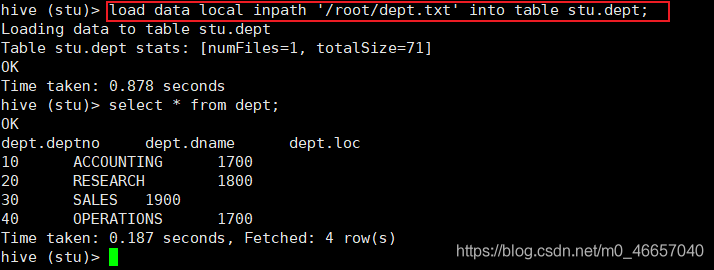
第二种方法:在把文件传到hdfs目录:/hive110/warehouse/stu.db下也可以成功查询
dept1的内容和dept内容一样
hadoop dfs -put /root/dept1.txt /hive110/warehouse/stu.db/dept

二、修改表
内外部表的相互转换
查询表的类型
hive (default)> desc formatted stu;
Table Type: MANAGED_TABLE
(2)修改内部表 stu为外部表
alter table stu set tblproperties(‘EXTERNAL’=‘TRUE’);
(3)查询表的类型
hive (default)> desc formatted stu;
Table Type: EXTERNAL_TABLE
(4)把刚才修改好的外部表 stu变为内部表
alter table stu set tblproperties(‘EXTERNAL’=‘FALSE’);
(5)查询表的类型
hive (default)> desc formatted student2;
Table Type: MANAGED_TABLE
注意:(‘EXTERNAL’=‘TRUE’)和(‘EXTERNAL’=‘FALSE’)为固定写法,区分大小写!
重命名表
(1)语法
alter table table_name rename to new_table_name
(2)实操案例
hive (default)> alter table stu1 rename to stu2;
分区的修改
分区是Hive里非常重要的一节,详情见 博客 Hive——分区的详细图文介绍,绝对看懂!
增加/修改/替换列信息
更新列
alter table table_name change [column] col_old_name col_new_name
column_type [first|after column_name]
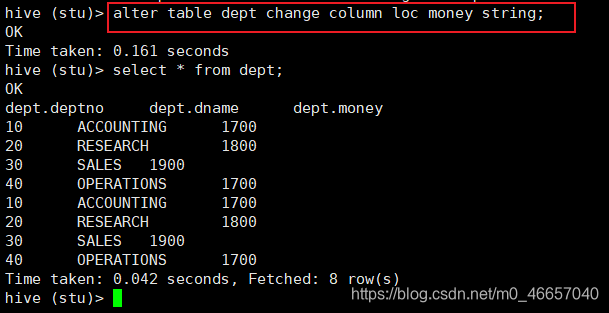
比如我把dept表的loc列名改为money 并指明是String类型
hive (stu)> alter table dept change column loc money string;
增加和替换列
alter table table_name add|replace columns (col_name data_type, …)
注:add 是代表新增一字段,字段位置在所有列后面(partition 列前),replace 则是
表示替换表中所有字段。
比如我添加add和phone列
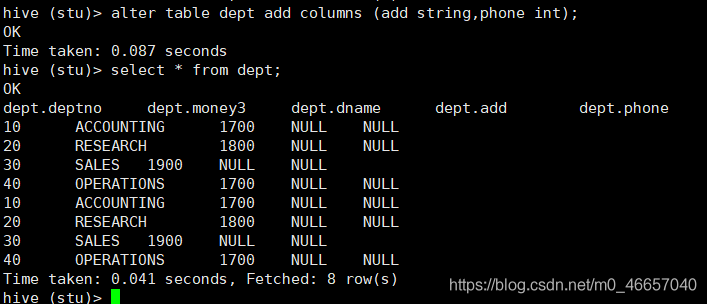
replace 表示替换表中所有字段。这里把所有列都换成最后add和phone这两个列

三、删除表
hive (default)> drop table dept;
虽然删除了表,但是hdfs的数据还在

如果我这时再创一张相同的表,我们不用导入数据就可以查到内容
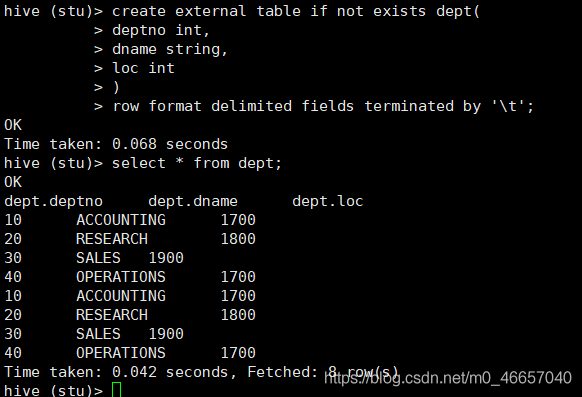
四、查表
查看stu库下有几个表
use stu;
show tables;
