悄悄学python【更新至包。。。】
文章目录
-
- 一、引入
-
- 1、猜测随机数字
- 2、for循环和if-else嵌套
- 3、数据类型转换
- 4、标识符
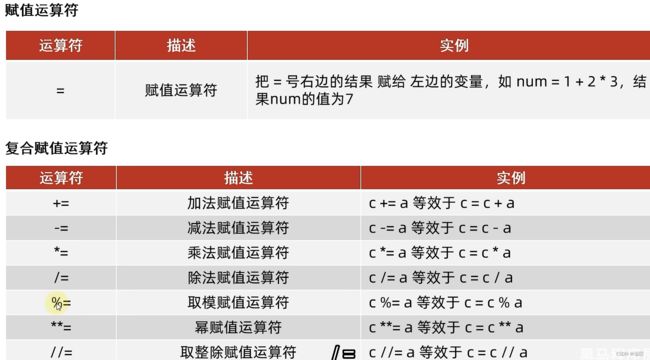
- 5、运算符
- 6、注释
- 7、字符串的定义
- 8、变量的拼接
- 9、字符串格式化
- 10、字符串的快速格式化(f字符串)
- 11、对表达式格式化
- 12、input语句
- 二、判断
-
- 1、布尔类型
- 2、if判断
- 3、 if-else语句
- 4、if-elif-else
- 5、嵌套判断
- 6、综合案例
- 三、循环
-
- 1、while循环
- 2、使用while循环打印九九乘法表:
- 3、for循环
- 4、range语句
- 5、for循环的嵌套
- 6、break和continue
- 四、函数
-
- 1、函数的参数
- 2、函数的返回值
- 3、函数的说明文档
- 4、函数的嵌套调用
- 5、变量的作用域
- 6、综合案例
- 五、数据容器
-
- 1、list列表
- 2、列表的索引
- 3、列表的方法
- 4、列表的遍历(迭代)
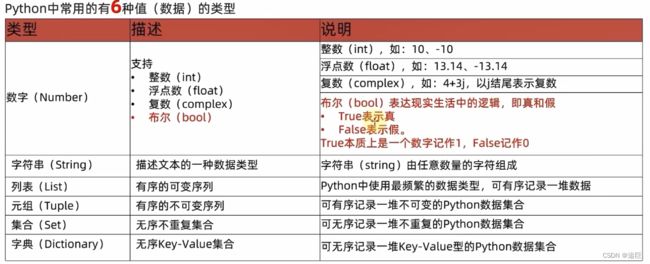
- 5、元组
- 6、字符串
- 7、序列的切片
- 8、集合
- 9、字典
- 10、字典的常用操作
- 11、字典的案例
- 12、几种数据容器的对比
- 13、数据容器的通用操作
- 六、函数进阶
-
- 1、多返回值
- 2、函数参数形式
- 3、匿名函数
- 七、文件操作
-
- 1、文件读取
- 2、文件的写入
- 3、文件的追加
- 4、综合案例
- 八、异常、模块和包
-
- 1、捕获异常
- 2、异常的传递
- 3、Python的模块
- 4、python包
- 5、综合案例
- 九、数据可视化
-
- 1、json的数据格式
一、引入
1、猜测随机数字
import random
num = random.randint(1,100)
count = 0
#print(num)
flag = True
while flag:
guss_num = int(input("输入数字:"))
count += 1
if guss_num == num:
print("right!")
flag = False
else:
if guss_num > num:
print("too big")
else:
print("to small")
#print("count=", count)
print(f"count= {count}")
2、for循环和if-else嵌套
import random
total = 10000
salary = 1000
for id_num in range(1, 21):
score = random.randint(1,10)
if total > 0:
if score < 5:
print("no salary!")
else:
total -= 1000
print(f"{id_num}:Your salsry is {salary}")
else:
print(f"total is {total}")
break
3、数据类型转换
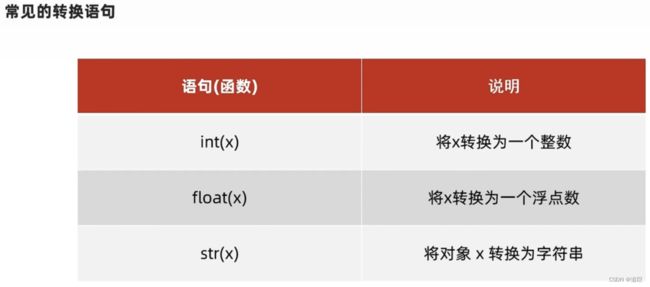
num_str = str(11)
print(type(num_str), 'num_str', '=', num_str)
num2 = float('11.322') #字符串内必须是数字
print(type(num2), num2)
# 浮点数和整数可以相互转换,浮点数装转换成整数,会丢失精度。
4、标识符

变量命名规范:

5、运算符
算数运算符
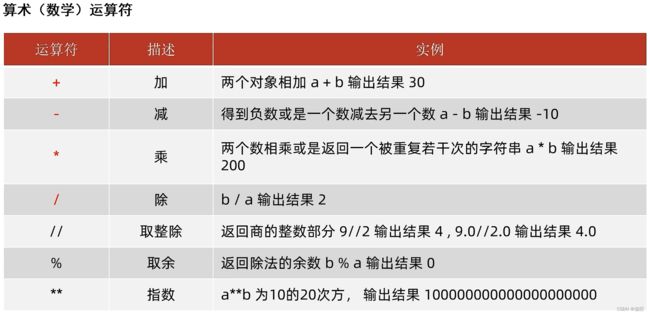
print('1 + 2 =', 1 + 2)
print('11//2 = ', 11 // 2)
6、注释
多行注释
"""
这里是注释
"""
单行注释
# 单行注释
7、字符串的定义
字符串定义时可以用单引号,双引号,三引号。
但字符串中包含引号时,有三种解决办法:
# 单引号内套双引号
str_name = '人生苦短,我选"python"'
# 双引号内套单引号
str_name2 = "人生苦短,我选'python'"
# 使用转义字符
str_name3 = "人生苦短,我选\"python\""
print(str_name, str_name2, str_name3)
#输出结果:
人生苦短,我选"python" 人生苦短,我选'python' 人生苦短,我选"python"
8、变量的拼接
字符串不能用“+”号和整形、浮点型变量拼接
# 字面量的拼接
print("人生苦短" + "我选python")
# 字符串字面量的拼接
province = "山东"
city = "菏泽"
print("我在" + province + city)
9、字符串格式化

id_card = 45
avg_salary = 15000
message = "工号:%s" % id_card
print(message)
message = "工号:%s, 工资:%s" % (id_card, avg_salary)
print(message)
name = "小明"
math = 98
chinese = 89
message = "%s的数学成绩是%d,语文成绩是%d" % (name, math, chinese)
print(message)
结果:
小明的数学成绩是98,语文成绩是89

num1 = 11
num2 = 11.234
print("数字11宽度限制5,结果是:%5d" % num1)
print("数字11.234 宽度限制7,小数精度为2,结果为:%7.2f" % num2)
print("数字11.234 宽度不限制,小数精度为2,结果为:%.2f" % num2)
结果:
数字11宽度限制5,结果是: 11
数字11.234 宽度限制7,小数精度为2,结果为: 11.23
数字11.234 宽度不限制,小数精度为2,结果为:11.23
10、字符串的快速格式化(f字符串)
f字符串不做精度控制,原样输出,且不考虑数据类型。
num1 = 11
num2 = 11.234
print(f"num1={num1},num2={num2}")
结果:
num1=11,num2=11.234
11、对表达式格式化

print("1*1 的结果是:%d" % (1*1))
print(f"1*2 的结果是: {1*2}")
print("字符串在python中的类型名是:%s" % type("字符串"))
结果:
1*1 的结果是:1
1*2 的结果是: 2
字符串在python中的类型名是:<class 'str'>
字符串练习
name = "CSDN"
stock_price = 19.99
stock_code = "000000"
stock_price_daily_growth_factor = 1.2
growth_days = 7
print(f"公司:{name},股票代码:{stock_code},当前股价:{stock_price}")
print("每日增长系数是:%.1f,经过%d天的增长后,股票达到了:%.2f" % (stock_price_daily_growth_factor, growth_days, stock_price * stock_price_daily_growth_factor ** growth_days))
结果:
公司:CSDN,股票代码:000000,当前股价:19.99
每日增长系数是:1.2,经过7天的增长后,股票达到了:71.63
12、input语句
input功能是获取键盘输入
name = input("输入你的名字:")
print(f"你的名字是{name}")
name = input("输入你的名字:")
print(f"你的名字是{name}")
# 数字类型
num = input("输入银行卡密码:") # 默认字符串类型
num = int(num) # 类型转换
print("你的银行卡密码类型是:", type(num))
结果:
输入你的名字:tom
你的名字是tom
输入银行卡密码:12345
你的银行卡密码类型是: <class 'int'>
user_name = input("请输入用户名:")
user_type = input("输入用户类型:")
print(f"您好,{user_name},您是尊贵的{user_type}用户,欢迎您的光临")
二、判断
1、布尔类型
布尔类型与比较运算符结合
result = 10 > 5
print(f"10 > 5 是{result},result的类型是{type(result)}")
结果:
10 > 5 是True,result的类型是<class 'bool'>
2、if判断

age = input("请输入你的年龄:")
age = int(age) # 输入的内容默认是字符串类型,转换成整型
if age >= 18:
print("你已成年,需全价购买门票。")
if age < 18:
print("你是未成年人,可以购买半价票。")
print("祝您游玩愉快!")
3、 if-else语句
"""
游乐园购票系统
"""
age = input("请输入你的年龄:")
age = int(age)
if age >= 18:
print("你已成年,需全价购买门票。")
else:
print("你是未成年人,可以购买半价票。")
print("祝您游玩愉快!")
4、if-elif-else
print("欢迎来到动物园")
height = int(input("请输入你的身高(cm):"))
vip_level = int(input("输入你的vip等级:"))
data = int(input("今天是这个月的第几号:"))
if height <= 120:
print("您的身高未超过120cm,可以免费游玩。")
elif vip_level > 3:
print("vip等级大于3,可以免费游玩。")
elif data == 1:
print("今天是1号,可以免费游玩。")
else:
print("所有条件都不满足,你需要买票。")
print("祝您玩得愉快。")
以上代码优化后:
print("欢迎来到动物园")
if int(input("请输入你的身高(cm):")) <= 120:
print("您的身高未超过120cm,可以免费游玩。")
elif int(input("输入你的vip等级:")) > 3:
print("vip等级大于3,可以免费游玩。")
elif int(input("今天是这个月的第几号:")) == 1:
print("今天是1号,可以免费游玩。")
else:
print("所有条件都不满足,你需要买票。")
5、嵌套判断
print("欢迎来到动物园。")
if int(input("输入身高(cm):")) > 120:
print("身高超出限制,不可以免费。")
print("但是vip级别大于3,可以免费")
if int(input("输入vip级别:")) > 3:
print("vip级别大于3,可以免费。")
else:
print("需要买票。")
else:
print("身高符合要求,可以免费游玩。")
6、综合案例
随机生成一个1-10之内的数字,猜数字,有三次机会
import random
num = random.randint(1, 10)
# print(num)
guess_num = int(input("输入你猜的数字:"))
if guess_num == num:
print("恭喜你猜对了")
else:
if guess_num > num:
print("猜大了")
else:
print("猜小了")
guess_num = int(input("再输入你猜的数字:"))
if guess_num == num:
print("恭喜你猜对了")
else:
if guess_num > num:
print("猜大了")
else:
print("猜小了")
guess_num = int(input("再输入你猜的数字:"))
if guess_num == num:
print("恭喜你猜对了")
else:
print("三次机会已经用完。没有猜中")
三、循环
1、while循环

使用循环打印数字0-9
i = 0
while i < 10:
print(i)
i += 1
1到100累加
i = 1
sum = 0
while i <= 100:
sum += i
i += 1
print("1-100累加的和为:%d" % sum)
随机生成一个100以内的数字,猜数字,直至猜对。
import random
num = random.randint(1, 100)
count = 0
flag = True
while flag:
guess = int(input("请输入你猜的数字:"))
count += 1
if guess == num:
print("猜对了")
flag = 0
else:
if guess > num:
print("猜大了")
else:
print("猜小了")
print("再猜一次")
2、使用while循环打印九九乘法表:
多个print不换行:
print("hello,", end='')
print("world", end='')
结果:
hello,world
i = 1
while i <= 9:
j = 1
while j <= i:
print(f"{j}*{i}={i*j}\t", end='') # \t 的作用是使算式对齐
j += 1
print() # 空输出会打印一个换行
i += 1
3、for循环

string = "hello"
for i in string:
print(i) # 会依次打印字符串中的字符
# 临时变量i,从规范上是限制在for循环之内的。
"""
统计字符串中字符l的个数
"""
string = "hello,world"
count = 0
for i in string:
if i == 'l':
count += 1
print(f"字符l的个数为:{count}")
4、range语句



"""
range 的使用
"""
# range 语法1 range(num)
for x in range(10):
print(x, end='')
print()
# range 语法2,range(num1, num2)
for x in range(5, 10):
# 从5开始到10结束,不包含10,
print(x,end='')
print()
# range 语法3,range(num1, num2, step)
for x in range(5, 10, 2):
# 从5开始,到10结束,不包含10,步长为2
print(x,end='')
print()
5、for循环的嵌套
"""
使用for循环打印九九乘法表
"""
for i in range(1, 10):
for j in range(1, i+1):
print(f"{j} * {i} = {i*j}\t", end='')
print()
6、break和continue
continue的作用是中断所在循环的本次循环,跳过continue下面的语句,开始下一次循环;break的作用是结束所在循环。
四、函数
函数是组织好的,可实现特定功能的,可重用的代码段,函数要先定义后使用。
"""
函数的定义
"""
def 函数名(传入参数):
函数体
return 返回值
def hello():
print("hello,world!")
# 调用函数
hello()
1、函数的参数
"""
计算两数和的函数
"""
def add(num1, num2): #num1和num2是形式参数
result = num1 + num2
print(f"{num1} + {num2} = {result}")
# 调用函数
add(1, 2) #1和2是实际参数,分别替换num1和num2
2、函数的返回值
返回值是函数返回的结果,在函数内,return之后的代码不执行。所以return要在函数体最后。
"""
计算两数和的函数
"""
def add(num1, num2):
result = num1 + num2
return result
# 调用函数
r = add(1, 2)
print(r)

函数返回值
def hello():
print("hello!")
result = hello()
print(result, type(result))
结果:
hello!
None <class 'NoneType'>
if 判断
def check_age(age):
if age >= 18:
return "SUCCESS"
else:
return None
result = check_age(18)
if not result: #None 等价与False
print("未成年,不可以进入")
else:
print("欢迎!")
为变量赋值
name = None #None 可以给变量赋予空类型的值,暂时不提供值,后续再处理。
3、函数的说明文档
def add(x, y):
"""
add 函数可以接受两个参数,进行两数相加,
:param x: 形参x表示两数里的其中一个数
:param y: 形参y表示两数相加中的另一个数
:return: 返回两数相加的结果
"""
result = x + y
return result
r = add(3, 4)
4、函数的嵌套调用
在一个函数了调用另一个函数
def func_b():
print("---2---")
def func_a():
print("---1---")
func_b()
print("---3---")
# 调用func_a
func_a()
结果:
---1---
---2---
---3---
5、变量的作用域
# 局部变量
def test():
num = 100
print(num) # num的作用域是test函数内,函数外部无法使用
test() 函数调用结束,变量num销毁
print(num) 不在num的作用域内,报错
# num是全局变量
num =200
def test():
num = 100
print(num)
test()
print(num)
在函数内修改全局变量的值,使用global关键字
num =200
def test():
global num
num = 500
print(num)
test()
print(num)
6、综合案例
要求:
"""
银行存取款
"""
money = 5000000 # 全局变量money存放账户余额
name = input("请输入你的姓名:")
print(f"{name},您好!")
def free(show_header):
if show_header: #防止重复打印标头
print("--------查询余额--------")
print(f"{name},您好,您的余额为:{money}")
def money_in(change_money):
print("--------存款--------")
print(f"您存款的数额为{change_money}")
global money # 定义全局变量,用来更改账户余额
money += change_money
free(False)
def money_out(change_money):
print("--------取款--------")
print(f"您取款的数额为{change_money}")
global money
money -= change_money
free(False)
def mem():
print("---业务目录---")
print("查询余额\t输入[1]")
print("存款\t\t输入[2]")
print("取款\t\t输入[3]")
print("退出系统\t输入[4]")
while True:
mem()
choice = int(input("请输入您要办理的业务代码:"))
if choice == 1:
free(1)
elif choice == 2:
change_money = int(input("请输入您的存款数额:"))
money_in(change_money)
elif choice == 3:
change_money = int(input("请输入您的取款数额:"))
money_out(change_money)
elif choice == 4:
print("欢迎下次光临!")
exit()
else:
print("无效代码!")
exit()
五、数据容器
可以容纳多份数据的数据类型是数据容器
1、list列表
语法: [元素1, 元素2…]
列表的元素类型没有限制,甚至可以是列表。

language = ['c', 'c++', 'python']
print(language, type(language))
结果:
['c', 'c++', 'python'] <class 'list'>
列表中可以同时存放不同的元素类型
mylist = ['python', 123, True]
print(mylist, type(mylist))
结果:
['python', 123, True] <class 'list'>
嵌套列表
mylist = ['python', 123, True, ['hello', 123]]
print(mylist, type(mylist))
结果:
['python', 123, True, ['hello', 123]] <class 'list'>
2、列表的索引
使用列表的下表索引,来取出数据,索引从0开始,每次加1。可以使用索引来取出对应位置的元素。

name = ['tom', 'jerry', 'tim']
print(name[0])
# 使用负数反向取元素,最后一个元素索引是-1,然后从右向左依次减1
print(name[-1])
print(name[-2])
结果:
tom
tim
jerry
name = ['tom', 'jerry', 'tim', ['hello', 'world']]
print(name[3][0])
print(name[-1])
print(name[-1][1])
结果:
hello
['hello', 'world']
world
3、列表的方法
在python中,如果将函数定义为class(类)的成员,那么函数会称之为方法。
name = ['tom', 'jerry', 'tim', ['hello', 'world']]
# 查询某元素在列表中的下标索引
index = name.index('jerry')
print(f"tom的索引是{index}")
结果:
tom的索引是1
# 插入元素,修改特定下标索引的值
# 语法:insert.(下表,元素)
name = ['tom', 'jerry', 'tim', ['hello', 'world']]
name.insert(0, 'herry')
print(name)
结果:
['herry', 'tom', 'jerry', 'tim', ['hello', 'world']]
# 追加元素
# 语法:列表.append(元素),将指定元素追加到列表的尾部
name = ['tom', 'jerry', 'tim', ['hello', 'world']]
name.append('alan')
print(name)
结果:
['tom', 'jerry', 'tim', ['hello', 'world'], 'alan']
# 在列表末尾追加一批新元素
# 语法:列表.extend(其他数据容器),将其他数据容器的内容取出,依次追加到列表尾部。
name = ['tom', 'jerry', 'tim']
testlist = ['123', '456']
name.extend(testlist)
print(name)
结果:
['tom', 'jerry', 'tim', '123', '456']
# 删除列表元素
# 语法1:del 列表[下标]
name = ['tom', 'jerry', 'tim']
del name[0]
print(name)
# 语法2:列表.pop(下标),可以作为一个返回值存到变量里
name = ['tom', 'jerry', 'tim']
result = name.pop(0)
print(name,result)
结果:
['jerry', 'tim']
['jerry', 'tim'] tom
# 删除某元素在列表中的第一匹配项
name = ['tom', 'jerry', 'tim', 'tom']
name.remove('tom')
print(name)
结果:
['jerry', 'tim', 'tom']
# 清空列表
# 语法:列表.clear()
name = ['tom', 'jerry', 'tim', 'tom']
name.clear()
print(name)
结果:
[]
# 统计某个元素在列表中出现的次数
# 语法:列表.count(元素)
name = ['tom', 'jerry', 'tim', 'tom']
count = name.count('tom')
print(count)
结果:
2
# 统计列表的元素数量
# 语法:len(列表)
name = ['tom', 'jerry', 'tim', 'tom']
count = len(name)
print(count)
结果:
4
4、列表的遍历(迭代)
使用while遍历
mylist = ['hello', 'world', 'Python']
index = 0
while index < len(mylist):
print(f"列表的第{index + 1}个元素是:{mylist[index]}")
index += 1
结果:
列表的第1个元素是:hello
列表的第2个元素是:world
列表的第3个元素是:Python
使用for遍历
mylist = ['hello', 'world', 'Python']
for element in mylist:
print(element)

5、元组
元组是只读的列表,内容不可修改
# 定义元组
t1 = (1, "hello", True)
t2 = () # 空元组
t3 = tuple() # 空元组
t4 = ("hello",) # 定义只有一个元素的元组,里面的逗号不可省略
# 元组的嵌套
t5 = ((1, 2, 3), (4, 5, 6))
print(t5)
元组的常用方法:
1、index方法:统计某个元素的索引,用法同列表
2、count方法:统计某个元素出现的次数,同列表
3、len函数:统计元组中的元素个数,用法同列表。
元组的遍历同列表
如果元组内嵌套了一个列表,那么这个列表内的内容可以修改
t6 = (1, 2, ["hello", "world"])
print(f"t6的内容是:{t6}")
t6[2][1] = "python"
print(f"修改元组的列表:{t6}")
my_tuple = ("菜徐坤", 18, ["sing", "jump", "rap", "basketball"])
print(my_tuple[0]) # 输出姓名
print(my_tuple.index(18)) # 输出年龄所在的索引
del my_tuple[2][-1] # 删除爱好中的篮球
print(my_tuple)
my_tuple[2].append("coding") # 爱好中加入coding
print(my_tuple)
结果:
菜徐坤
1
('菜徐坤', 18, ['sing', 'jump', 'rap'])
('菜徐坤', 18, ['sing', 'jump', 'rap', 'coding'])
6、字符串
字符串是字符的容器,字符串和元组类似,是个只读的数据容器
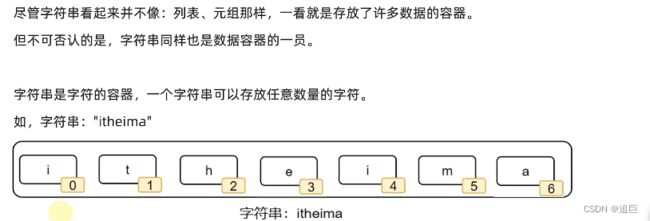
mystr = "hello"
print(mystr[0])
h
字符串常用方法:
1、index方法:用法同列表
2、replace方法:替换字符串中的内容,不改变原字符串的内容,生成一个新的字符串。
my_str = "hello,python"
new_str = my_str.replace("hello", "你好")
print(new_str)
结果:
你好,python
3、split方法:将字符串按照特定字符分隔,分割的结果会称为一个列表,不修改原字符串的内容
my_str = "hello, world"
new_str = my_str.split(",") # 以逗号为分隔,分隔字符串,结果是一个列表
print(new_str)
结果:
['hello', ' world']
4、strip方法:不加参数时,默认去除字符串首尾的空格,带参数时,就去除去除字符串首尾的参数部分。不改变原字符串的内容。
my_str = " hello "
new_str = my_str.strip()
print(f"去除空格前:{my_str},去除空格后:{new_str}。")
结果:
去除空格前: hello ,去除空格后:hello。
my_str = "12hello21,world2112"
new_str = my_str.strip("12")
# 此处的12,会被视为两个字符串1和2,所以原字符串中的12和21都会被去除
# 只会去除首尾的12和21
print(f"去除12前:{my_str},去除12后:{new_str}。")
结果:
去除12前:12hello21,world2112,去除12后:hello21,world。
5、count方法:统计字符串中某小字符串出现的次数
6、len函数:统计字符串的长度
7、字符串也可以遍历
8、字符串的比较是从头到尾按位比较的,比较的是ASCII码值,只要一位大,那么字符串整体就大。
7、序列的切片
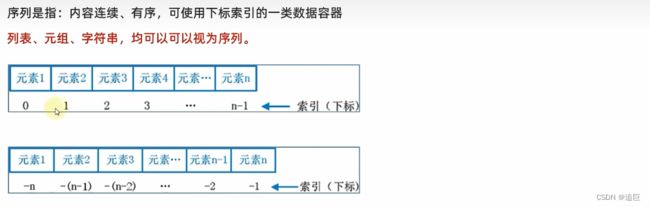
切片是从序列中取出一个子序列。切片不改变原序列

# 对list进行切片,从1开始,4结束,步长为1
my_list = [0, 1, 2, 3, 4, 5, 6]
result1 = my_list[1:4] # 默认步长为1
print(f"result1: {result1}")
# 对tuple进行切片,从头开始,到最后结束,步长为1
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result2 = my_tuple[:]
print(f"result2: {result2}")
# 对str进行切片,从头开始,到最后结束,步长为2
my_str = "0123456"
result3 = my_str[::2]
print(f"result3: {result3}")
# 对str进行切片,从头开始,到最后结束,步长为-1
my_str = "0123456"
result4 = my_str[::-1]
print(f"result4: {result4}")
# 对列表进行切片,从3开始,到1结束,步长为-1
my_list = [0, 1, 2, 3, 4, 5, 6]
result5 = my_list[3:1:-1]
print(f"result5: {result5}")
# 对元组进行切片,从头开始,到尾结束,步长为-2
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result6 = my_tuple[::-2]
print(f"result6: {result6}")
结果:
result1: [1, 2, 3]
result2: (0, 1, 2, 3, 4, 5, 6)
result3: 0246
result4: 6543210
result5: [3, 2]
result6: (6, 4, 2, 0)
8、集合
集合不支持元素重复,所以自带去重功能。
集合是无序的,所以不支持下标索引
集合允许修改
"""基本语法"""
# 定义集合字面量
{元素, 元素, 元素...,元素}
# 定义集合变量
变量名称 = {元素, 元素, 元素...,元素}
# 定义空集合
变量名称 = set()
my_set = {"c", "c++", "Python", "java", "c"} # 定义时有两个c,打印时只打印一个,去重
my_set_empty = set() # 定义空集合
print(f"my_set的内容为:{my_set},类型为:{type(my_set)}")
结果:
my_set的内容为:{'java', 'Python', 'c', 'c++'},类型为:<class 'set'>
my_set = {"c", "c++", "Python", "java", "c"}
my_set.add("c#") # 添加新元素
print(my_set)
结果:
{'c#', 'java', 'Python', 'c', 'c++'}
# 移除元素
my_set = {"c", "c++", "Python", "java", "c"}
my_set.remove("c")
print(my_set)
结果:
{'java', 'c++', 'Python'}
# 随机取出元素
my_set = {"c", "c++", "Python", "java", "c"}
element = my_set.pop()
print(element)
# 清空集合
my_set = {"c", "c++", "Python", "java", "c"}
my_set.clear()
print(my_set)
结果:
set()
# 取两个集合的差集
my_set = {"c", "c++", "Python", "java", "c"}
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.difference(set2) # set1里有的,而set2里没有的元素会被存在set3中
# 不会改变原集合的内容
print(f"取出差集后的结果:{set3}")
print(f"取出差集后原有set1的内容:{set1}")
print(f"取出差集后原有set2的内容:{set2}")
结果:
取出差集后的结果:{2, 3}
取出差集后原有set1的内容:{1, 2, 3}
取出差集后原有set2的内容:{1, 5, 6}
# 消除两个集合的差集
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set1.difference_update(set2) # 在set1里删除和set2相同的元素。
# 结果是,set1被修改,set2不变
print(set1)
print(set2)
结果:
{2, 3}
{1, 5, 6}
# 两个集合合并
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.union(set2)
# 不修改原有集合
print(f"集合合并的结果:{set3}")
print(f"合并后的集合1:{set1}")
print(f"合并后的集合2:{set2}")
结果:
集合合并的结果:{1, 2, 3, 5, 6}
合并后的集合1:{1, 2, 3}
合并后的集合2:{1, 5, 6}
# 统计集合的个数
set1 = {1, 2, 3}
num = len(set1)
print(num)
结果:
3
# 集合的遍历
# 集合不支持下标索引,不能用whlie来遍历
set1 = {1, 2, 3}
for element in set1:
print(f"集合的元素有:{element}")
结果:
集合的元素有:1
集合的元素有:2
集合的元素有:3
"""
定义一个列表,再定义一个空集合,使用for循环将列表元素添加到集合内
"""
my_list = ["hello", "world", "Python", "world"]
new_set = set()
for element in my_list:
new_set.add(element)
print(new_set)
9、字典
字典是key:value形式的键值对,通过key可以取出value。字典的key不能重复(重复会覆盖)。
字典不支持下标索引
字典中的key和value可以为任意类型的数据(key)不可以为字典。字典可以嵌套。
# 字典的定义
{key:value, key:value,...}
# 字典的定义
# {key:value, key:value,...}
my_dict = {"张三": 99, "李四": 98, "王五": 80}
# 定义空字典
my_dict2 = {}
my_dict3 = my_dict2
print(my_dict)
print(my_dict2)
print(my_dict3)
结果:
{'张三': 99, '李四': 98, '王五': 80}
{}
{}
# 在字典中使用key获取valu
my_dict = {"张三": 99, "李四": 98, "王五": 80}
score = my_dict["张三"]
print(f"张三的分数是:{score}")
结果;
张三的分数是:99
# 字典的嵌套
stu_score_dict = {
"王丽红": {
"语文": 99,
"数学": 80,
"英语": 85
}, "林俊节": {
"语文": 59,
"数学": 83,
"英语": 75
}, "周杰轮": {
"语文": 100,
"数学": 70,
"英语": 65
}
}
print(f"学生的成绩单:{stu_score_dict}")
# 从嵌套字典中获取周杰轮的语文成绩
score = stu_score_dict["周杰轮"]["语文"]
print(f"周杰轮的语文成绩是:{score}")
10、字典的常用操作
# 新增元素
my_dict = {"王丽红": 99, "林俊节": 59, "周杰轮": 100}
my_dict["张学有"] = 76
print(f"新增元素后:{my_dict}")
结果:
新增元素后:{'王丽红': 99, '林俊节': 59, '周杰轮': 100, '张学有': 76}
# 更新元素
my_dict = {"王丽红": 99, "林俊节": 59, "周杰轮": 100}
my_dict["王丽红"] = 19
print(f"更新元素后:{my_dict}")
结果:
更新元素后:{'王丽红': 19, '林俊节': 59, '周杰轮': 100}
# 删除元素
my_dict = {"王丽红": 99, "林俊节": 59, "周杰轮": 100}
score = my_dict.pop("王丽红")
print(f"移除王丽红后:{my_dict},王丽红的分数:{score}")
结果:
移除王丽红后:{'林俊节': 59, '周杰轮': 100},王丽红的分数:99
# 清空元素
my_dict = {"王丽红": 99, "林俊节": 59, "周杰轮": 100}
my_dict.clear()
print(my_dict)
结果:
{}
# 获取全部key
my_dict = {"王丽红": 99, "林俊节": 59, "周杰轮": 100}
keys = my_dict.keys()
print(f"字典的全部key:{keys}")
结果:
字典的全部key:dict_keys(['王丽红', '林俊节', '周杰轮'])
# 遍历字典
# 方法1:
my_dict = {"王丽红": 99, "林俊节": 59, "周杰轮": 100}
keys = my_dict.keys()
for key in keys:
print(f"字典的key是:{key}")
print(f"字典的value是:{my_dict[key]}")
# 方法2:
for key in my_dict:
print(f"2字典的key是:{key}")
print(f"2字典的value是:{my_dict[key]}")
结果:
字典的key是:王丽红
字典的value是:99
字典的key是:林俊节
字典的value是:59
字典的key是:周杰轮
字典的value是:100
2字典的key是:王丽红
2字典的value是:99
2字典的key是:林俊节
2字典的value是:59
2字典的key是:周杰轮
2字典的value是:100
# 统计字典的元素数量
my_dict = {"王丽红": 99, "林俊节": 59, "周杰轮": 100}
num = len(my_dict)
print(f"字典中的元素数量:{num}")
结果:
字典中的元素数量:3
11、字典的案例

em = {
"wanglihong": {
"department": "technology",
"salary": 3000,
"level": 3
},
"zhoujay": {
"department": "market",
"salary": 5000,
"level": 2
},
"linjunjie": {
"department": "market",
"salary": 7000,
"level": 3
},
"zhangxueyou": {
"department": "technology",
"salary": 4000,
"level": 1
}
}
print(f"all employees is : {em}")
"""
for people in em:
if em[people]["level"] == 1:
em[people]["level"] = 2
em[people]["salary"] += 1000
"""
# 上面的for循环还可以这样写:
for employee in em:
if em[employee]["level"] == 1:
# 俩个的区别就在这里,把每个嵌套在em里的字典单独拿出来,更加清晰。
employee_info_dict = em[employee]
employee_info_dict["level"] = 2
employee_info_dict["salary"] += 1000
print(f"升职加薪后的结果:{em}")
12、几种数据容器的对比

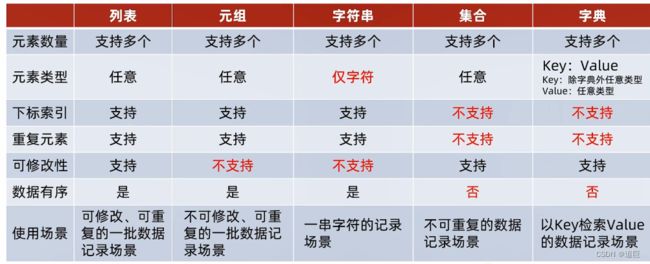
这几种数据容器的使用场景对比

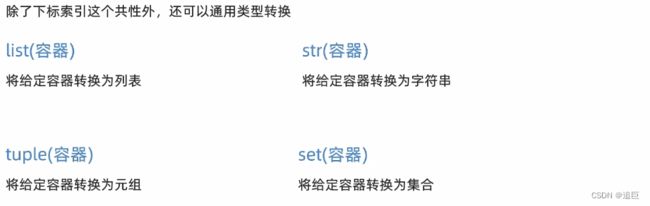
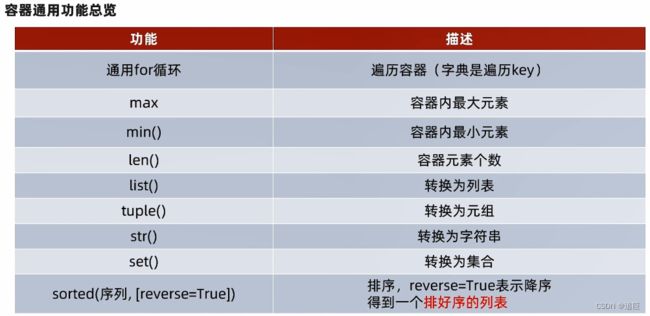
13、数据容器的通用操作
1、支持遍历操作
2、通用的函数
len函数:返回元素个数
max函数:返回最大的元素
min函数:返回最小的元素
3、支持数据类型转换
4、支持sorted函数排序


六、函数进阶
1、多返回值
通过return语句返回多个值,值用逗号分隔,用多个变量来接收返回值。
def test_return():
return 1, "hello", True
x, y, z =test_return()
print(x, y, z)
结果:
1 hello True
2、函数参数形式
1、位置参数
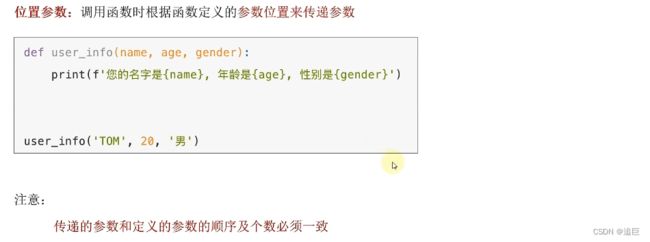
# 位置参数,形参和实参位置一一对应
def user_info(name, age, gender):
print(f"name is {name},age is {age},gender is {gender}")
user_info('Tom', 10, 'man')
2、关键字参数

# 关键字参数,参数位置可以任意
def user_info(name, age, gender):
print(f"name is {name},age is {age},gender is {gender}")
user_info(name='jerry', age=10,gender='man')
user_info(age=9, name='Herry', gender='woman')
3、缺省参数
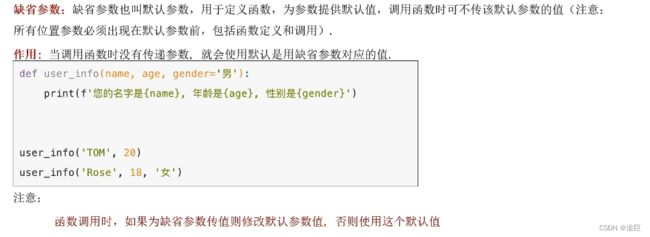
# 缺省参数, 函数内的参数有默认值,当缺省时,使用默认值
# 有默认值的参数在最后
def user_info(name, age, gender='man'):
print(f"name is {name},age is {age},gender is {gender}")
user_info("小李", 15) # 不指定gender,则用默认值
user_info("小李", 15, 'woman')
结果:
name is 小李,age is 15,gender is man
name is 小李,age is 15,gender is woman
4、不定长参数

位置传递的不定长

# 位置不定长
# 不定长定义的形式参数会作为元组存在,接受不定长数量的参数传入。
def user_info(*args):
print(f"args参数的类型是:{type(args)},内容是{args}")
user_info(1, 2,'hello', True)
结果:
args参数的类型是:<class 'tuple'>,内容是(1, 2, 'hello', True)
关键字不定长

# 关键字不定长
# 传递的参数数量不限,但参数形式必须是 key = value。参数生成一个字典
def user_info(**kargs):
print(f"args参数的类型是:{type(kargs)},内容是{kargs}")
user_info(name = 'xioawang', age =18, gender = "man")
结果:
args参数的类型是:<class 'dict'>,内容是{'name': 'xioawang', 'age': 18, 'gender': 'man'}
3、匿名函数
1、函数作为参数传递

def test_func(computer):
result = computer(1,2)
print(type(computer))
print(result)
def computer(x, y):
return x + y
test_func(computer)
结果:
<class 'function'>
3
2、lambda匿名函数


# 演示匿名函数
# 定义一个函数,接受其他函数的输入
def test_func(computer):
result = computer(1, 2)
print(f"结果是:{result}")
# 通过lambda匿名函数的形式,将匿名函数作为参数传入
test_func(lambda x, y: x + y)
结果:
结果是:3
七、文件操作
1、文件读取
在E盘新建一个名为ceshi.txt的文档,内容如下




# 打开文件
f = open("E:/ceshi.txt", "r", encoding="UTF-8")
print(type(f))
结果:
<class '_io.TextIOWrapper'>
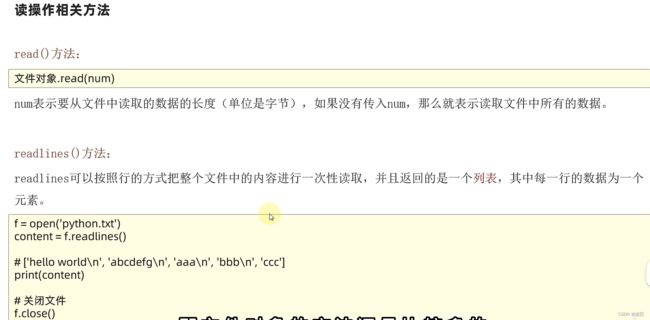
# 打开文件
f = open("E:/ceshi.txt", "r", encoding="UTF-8")
print(type(f))
# 读取文件
print(f"读取2个字节的结果:{f.read(2)}")
# 上一条语句已经读取了两个字节,因为文件指针,这里会接着读取
print(f"读取全部内容的结果:{f.read()}")
结果:
读取2个字节的结果:Py
读取全部内容的结果:thon由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫作ABC语言的替代品。
Python提供了高效的高级数据结构,还能简单有效地面向对象编程。
Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
# 读取文件的全部行,封装到列表中
f = open("E:/ceshi.txt", "r", encoding="UTF-8")
lines = f.readlines()
print(f"lines对象的内容是{lines}")
结果:
lines对象的内容是['Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫作ABC语言的替代品。\n', ' Python提供了高效的高级数据结构,还能简单有效地面向对象编程。\n', 'Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。']
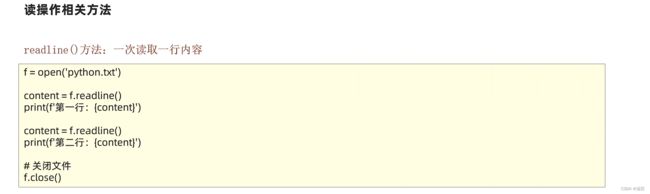
# 读取文件readline
f = open("E:/ceshi.txt", "r", encoding="UTF-8")
line1 = f.readline()
line2 = f.readline()
print(f"第一行内容:{line1}")
print(f"第二行内容:{line2}")
结果:
第一行内容:Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫作ABC语言的替代品。
第二行内容: Python提供了高效的高级数据结构,还能简单有效地面向对象编程
# 使用for循环读取每行文件
f = open("E:/ceshi.txt", "r", encoding="UTF-8")
for line in f:
print(f"每一行内容:{line}")
结果:
每一行内容:Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫作ABC语言的替代品。
每一行内容: Python提供了高效的高级数据结构,还能简单有效地面向对象编程。
每一行内容:Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
文件操作完毕之后要关闭文件,来结束对该文件的占用。
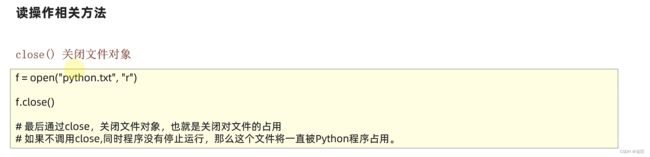
# 使用for循环读取每行文件
f = open("E:/ceshi.txt", "r", encoding="UTF-8")
f.close()

# 使用for循环读取每行文件
with open("E:/ceshi.txt", "r", encoding="UTF-8") as f:
for line in f:
print(f"每一行的内容为:{line}")
结果:
每一行的内容为:Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫作ABC语言的替代品。
每一行的内容为: Python提供了高效的高级数据结构,还能简单有效地面向对象编程。
每一行的内容为:Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
练习题,新建一个内容如下的txt文档,统计里面的hello出现的次数

# 方法一
# 使用for循环读取每行文件
count = 0
with open("E:/hello.txt", "r", encoding="UTF-8") as f:
for line in f: # 遍历行
line = line.strip() # 去除每行的换行符
newline = line.split(" ") # 把行的内容用空格分割成列表
for word in newline: # 遍历上一步生成的列表
if word == "hello": # 判断里面是否存在hello
count += 1 # 若存在hello,count加1
print(f"hello出现的次数为:{count}")
结果:
hello出现的次数为:4
# 方式二
f = open("E:/hello.txt", "r", encoding="UTF-8")
content = f.read()
num = content.count("hello")
print(f"hello出现的次数为:{num}")
2、文件的写入

# 打开一个不存在的文件,w模式会新建该文件
f = open("E:/test/test.txt", "w", encoding="UTF-8")
# write 写入内容
f.write("Hello,world!") # 数据在内存中
f.flush() # 刷新,将内存中的数据写入硬盘
f.close() # close里内置了flush功能,若中间没写flush,关闭文件后,也会将内容写入硬盘
然后,额e盘下的test文件下会新建一个名为test.txt的文件,内容为 Hello,world!

# 经过上一步 test.txt中已经有了内容,此时再对这个文件进行写入,会覆盖掉原有的内容
f = open("E:/test/test.txt", "w", encoding="UTF-8")
f.write("Python!!!")
f.close()
此时的test.txt的内容是

3、文件的追加

f = open("E:/test/test.txt", "a", encoding="UTF-8")
f.write("人生苦短,我选Python。")
# 换行写入,加 \n
f.write("\n人生苦短,我选Python。")
f.close()
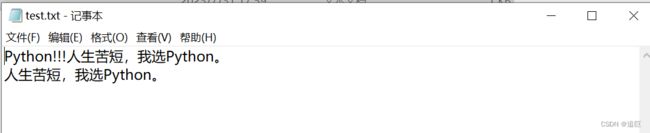
4、综合案例
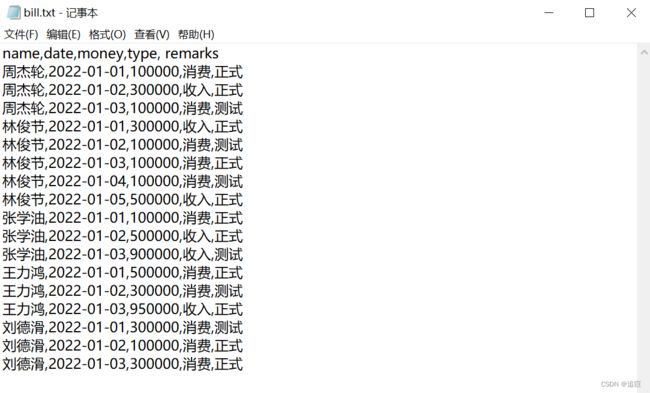
有一份账单文件,内容如下
name,date,money,type, remarks
周杰轮,2022-01-01,100000,消费,正式
周杰轮,2022-01-02,300000,收入,正式
周杰轮,2022-01-03,100000,消费,测试
林俊节,2022-01-01,300000,收入,正式
林俊节,2022-01-02,100000,消费,测试
林俊节,2022-01-03,100000,消费,正式
林俊节,2022-01-04,100000,消费,测试
林俊节,2022-01-05,500000,收入,正式
张学油,2022-01-01,100000,消费,正式
张学油,2022-01-02,500000,收入,正式
张学油,2022-01-03,900000,收入,测试
王力鸿,2022-01-01,500000,消费,正式
王力鸿,2022-01-02,300000,消费,测试
王力鸿,2022-01-03,950000,收入,正式
刘德滑,2022-01-01,300000,消费,测试
刘德滑,2022-01-02,100000,消费,正式
刘德滑,2022-01-03,300000,消费,正式

# 打开文件准备读取
fr = open("E:/test/bill.txt", "r", encoding="UTF-8")
# 打开得到的文件对象,准备写入
fw = open("E:/test/bill.txt.bak", "w", encoding="UTF-8")
# 使用for循环读取文件
for line in fr:
line = line.strip() # 去除换行符
if line.split(",")[4] == "测试":
continue # 是测试就跳过
# 不是测试就写入备份
fw.write(line)
# 前面去除了换行符,这里再加上
fw.write("\n")
# 关闭两个文件对象
fr.close()
fw.close()
运行上面的代码后会自动创建一个bill.txt.bak备份文件,“正式”数据条目将放入bill.txt.bak中,结果如下

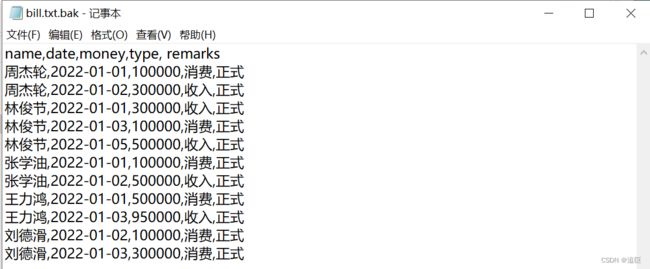
八、异常、模块和包
1、捕获异常
异常是程序运行过程中出现的错误
捕获异常是为了解决异常,当程序出现异常时,提供相应的解决方案,异常有很多种,

# 捕获常规异常
基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码
try:
f = open("E:/test/abc.txt", "r", encoding="UTF-8")
except:
print("出现异常了,因为文件不存在,将open的模式改为w")
f = open("E:/test/abc.txt", "w", encoding="UTF-8")
结果:
出现异常了,因为文件不存在,将open的模式改为w
# 捕获指定的异常
try:
print(name) # 这里的name未定义
# 只会捕获NameError的异常,其他类型的异常将正常报错
except NameError as e: # 这里的e是异常的对象
print("出现了变量未定义的异常")
# 打印e
print(e)
结果:
出现了变量未定义的异常
name 'name' is not defined
# 捕获多个异常
try:
11/0
print(name)
# 将异常要捕获的异常类型放入元组中
except (NameError, ZeroDivisionError) as e:
print("出现了变量未定义 或者 除以0的异常")
# 捕获全部异常
try:
1/0
# Exception是顶级的异常
except Exception as e: # 等价于except:
print("出现异常了")
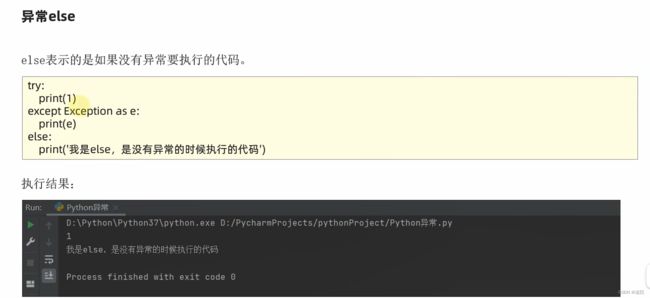
# 异常的else语法
try:
print("Hello")
except Exception as e:
print("出现异常了")
# 没有except里的异常时会执行else
else:
print("没有异常!")
结果:
Hello
没有异常!

# 带finally的异常语法
try:
# 123.txt这个文件不存在
f = open("E:/test/123.txt", "r", encoding="UTF-8")
except Exception as e:
print("出现异常了")
f = open("E:/test/123.txt", "w", encoding="UTF-8")
else:
print("没有异常!")
finally:
print("这里是finally,有没有异常最后都要执行finally")
f.close()
结果:
出现异常了
这里是finally,有没有异常最后都要执行finally
注意:在异常中,else和finally是可选的,try和except是必选的关键字。
2、异常的传递
异常会一层层传递,当最高的层级没有异常的处理时,就会报错了。

# 定义一个出现异常的函数
def func1():
print("func1 开始执行")
num = 1/0 # 此处有异常
print("func1 结束执行")
# 定义一个无异常的函数,调用上面的函数func1
def func2():
print("func2 开始执行")
func1() # 调用func1
print("func2 结束执行")
# 定义main函数调用func2
def main():
func2()
main()
结果:
D:\pythonProject\venv\Scripts\python.exe D:\pythonProject\面向对象t\test.py
Traceback (most recent call last):
File "D:\pythonProject\面向对象t\test.py", line 113, in <module>
main()
File "D:\pythonProject\面向对象t\test.py", line 111, in main
func2()
File "D:\pythonProject\面向对象t\test.py", line 106, in func2
func1() # 调用func1
^^^^^^^
File "D:\pythonProject\面向对象t\test.py", line 100, in func1
num = 1/0 # 此处有异常
~^~
ZeroDivisionError: division by zero
func2 开始执行
func1 开始执行
Process finished with exit code 1
加入异常捕获语句后:
# 定义一个出现异常的函数
def func1():
print("func1 开始执行")
num = 1/0 # 此处有异常
print("func1 结束执行")
# 定义一个无异常的函数,调用上面的函数func1
def func2():
print("func2 开始执行")
func1() # 调用func1
print("func2 结束执行")
# 定义main函数调用func2
def main():
try:
func2()
except Exception as e:
print(f"出现异常了!异常信息是:{e}")
main()
结果:
func2 开始执行
func1 开始执行
出现异常了!异常信息是:division by zero
因为异常具有传递性,所以我们不用深入到真正出现异常的那一层去处理异常。可以在高层级来处理异常。
3、Python的模块
3.1 模块的导入
模块的导入一般写在python文件的开头




# 模块本质是一个.py结尾的python文件,按Ctrl键点击可查看模块内容
import time
print("hello")
# 导入模块后使用“模块.函数”的形式来调用模块内定义的函数
time.sleep(5)
print("world")
from time import sleep
print("hello")
# 只导入某个模块的功能,可以直接使用这个功能,而不必写模块名
sleep(5)
print("world")
# 使用*来导入模块的全部功能,
from time import *
print("hello")
# 也可以直接使用这个功能,而不必写模块名
sleep(5)
print("world")

当模块或者功能的名字很长时,使用as来为模块或功能起别名
# 为模块起别名
import time as t
print("start")
t.sleep(5)
print("end")
# 为功能起别名
from time import sleep as sl
print("start")
sl(5)
print("end")
3.2 自定义模块
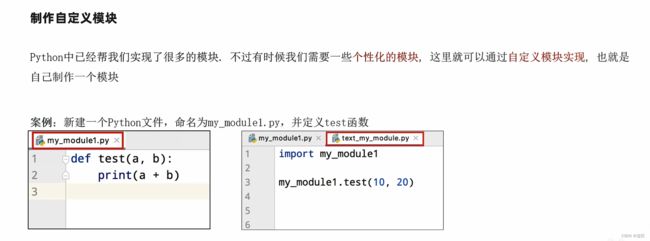
自定义模块。只需要正常的写python文件,用的时候使用import导入即可。
def test(a, b):
print(a + b)
# import my_module1
from my_module1 import test
test(1 , 2)
结果:
3
当导入多个模块时,模块内有相同名字的功能,后导入的会将先导入的覆盖。

模块在被导入的时候里面的代码会执行一次,如果想测试模块功能,而在外部导入时不执行测试代码,可以将测试内容写入如下的if判断
def test(a, b):
print(a + b)
# 下面是模块的测试内容
# 加入if判断后,在外部导入时,不会执行if判断里的语句。
# 只有程序是直接执行时才会进入
if __name__ == '__main__':
test(1, 2)
*和__all__ 是等价的。此时使用from module1 import test_b之后就可以使用test_b了

4、python包
4.1 自定义python包
当模块文件越来越多时,包可以帮助我们管理这些模块,包的作用就是包含多个模块,其本质仍然是模块。
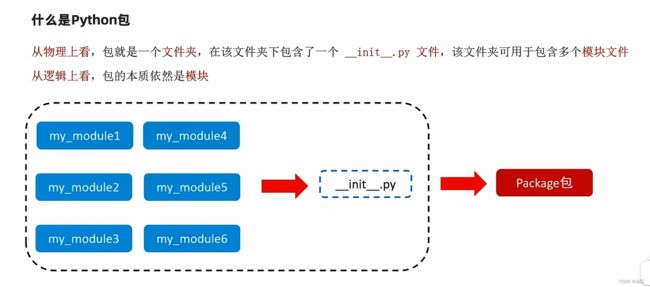
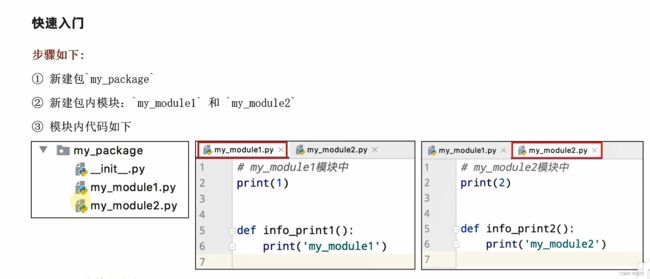
创建一个包,写两个模块
模块内容
module1:
"""
自定义模块1
"""
def info1():
print("模块1!")
module2:
"""
自定义模块2
"""
def info2():
print("模块2!!!")
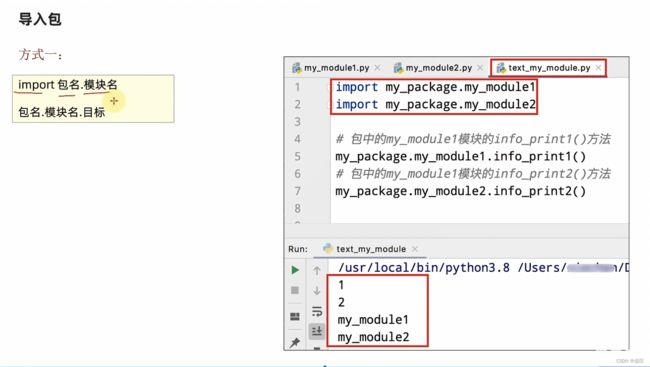
使用import的方式导入
# 导入包中的模块并使用
import my_pkg.module1
import my_pkg.module2
# 使用 . 来表示层级关系
my_pkg.module1.info1()
my_pkg.module2.info2()
结果:
模块1!
模块2!!!
from my_pkg import module1
from my_pkg import module2
# 使用from .. import..的形式来导入包调用时就不用写包名了
module1.info1()
module2.info2()
结果:
模块1!
模块2!!!
# 也可以直接导入到功能层级,这样就可以直接使用功能,
#不用写包名和模块名
from my_pkg.module1 import info1
from my_pkg.module2 import info2
info1()
info2()
结果:
模块1!
模块2!!!
和模块一样,包也可以使用__all__变量,这个变量要定义在__init__.py文件中。用法和模块一致
4.2 安装python第三方包



5、综合案例

str_utils.py
"""字符串相关"""
def str_reverse(s):
"""
将字符串反转
:param s: 需要被反转的字符串
:return: 反转后的字符串
"""
return s[::-1]
def substr(s, x, y):
"""
按照给定下标,完成给定字符串的切片
:param s: 即将被切片的字符串
:param x: 切片的开始下标
:param y: 切片结束的下标
:return: 切片完成后的字符串
"""
return s[x:y]
if __name__ == '__main__':
print(str_reverse("hello, world"))
print(substr("hello,world",1,2))
结果:
dlrow ,olleh
e
file_util.py
"""
文件操作的工作模块
"""
def print_file_info(file_name):
"""
将指定路径的文件内容输出到控制台
:param file_name: 即将读取的文件路径
:return: None
"""
f = None
try:
f = open(file_name, "r", encoding="utf-8")
content = f.read()
print("文件的全部内容如下:")
print(content)
except Exception as e:
print(f"程序出现异常了,异常是:{e}")
finally:
if f: # 如果变量是None,表示False,如果有内容,表示True
f.close()
def append_to_file(file_name, data):
"""
将指定的数据追加到指定的文件中
:param file_name: 指定的数据路径
:param data: 指定的数据
:return: None
"""
f = open(file_name, "a", encoding="utf-8")
f.write(data)
f.write("\n")
f.close()
if __name__ == '__main__':
print(print_file_info("E:\\test\\bill.txt"))
append_to_file("E:\\test\\test.txt", "helloword")

新建一个文件里调用刚才的包
from my_utils import file_util
from my_utils import str_util
print(str_util.str_reverse("hello"))
file_util.append_to_file("E:\\test\\test.txt", "Python!!!")
file_util.print_file_info("E:\\test\\test.txt")
结果:
olleh
文件的全部内容如下:
Python!!!人生苦短,我选Python。
人生苦短,我选Python。helloword
helloword
Python!!!
Process finished with exit code 0
九、数据可视化
1、json的数据格式


json格式像是python中的字典,或列表内嵌字典

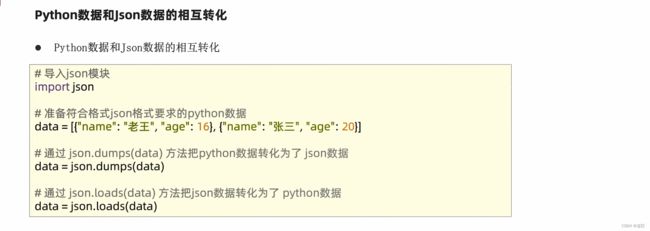
import json
data = [{"name": "jerry", "age":10}, {"name":"tom", "age":11}, {"name":"tim", "age":15}]
# 将字典转为json格式字符串
json_str = json.dumps(data) # 当要转换的数据中有中文时,加入参数 ensure_ascii=False
print(type(json_str))
print(json_str)
# 将列表转为json格式字符串
d = {"name": "周杰伦", "addr": "台湾"}
json_str = json.dumps(d, ensure_ascii=False)
print(type(json_str))
print(json_str)
print("json转为python中的类型:")
# 将json字符串转为python类型
s = '[{"name": "jerry", "age":10}, {"name":"tom", "age":11}, {"name":"tim", "age":15}]'
l = json.loads(s)
print(type(l))
print(l)
# 将json字符串转为python类型
s = '{"name": "周杰伦", "addr": "台湾"}'
d = json.loads(s)
print(type(d))
print(d)
结果:
<class 'str'>
[{"name": "jerry", "age": 10}, {"name": "tom", "age": 11}, {"name": "tim", "age": 15}]
<class 'str'>
{"name": "周杰伦", "addr": "台湾"}
json转为python中的类型:
<class 'list'>
[{'name': 'jerry', 'age': 10}, {'name': 'tom', 'age': 11}, {'name': 'tim', 'age': 15}]
<class 'dict'>
{'name': '周杰伦', 'addr': '台湾'}
Process finished with exit code 0