看完这个还不会 Canvas,请你吃瓜~
文章目录
-
- 什么是Canvas
- Canvas 解决了什么问题
- SVG 和 Canvas 的区别
-
- 怎么在网页上画一个圆?
- 什么是 SVG
- Canvas 和 SVG的区别
- Canvas基本使用
-
- 获取 Canvas 对象
- 绘制线条
- 绘制矩形
- 绘制圆弧/曲线
- 设置样式
- 渐变
- 绘制文本
- 图像绘制
- 移动、旋转和缩放
- 合成与裁剪
- 保存和恢复
- 动画
- 事件
- Canvas拖拽相册
- Canvas截图保存
- Canvas主题滤镜
- Canvas拾色器
- Canvas马赛克
- Canvas简易画板
-
- 制作画笔
- 手动涂擦
- 实现撤销
- 撤销改进
- 刮刮乐
- Canvas水印图片
- Canvas性能优化
-
- 尽量避免浮点运算
- 使用多层画布绘制复杂场景
- 动画请使用requestAnimationFrame
- 尽量少改变Canvas状态机
- 离屏Canvas
- 关闭透明度
- 尽量利用 CSS
- 利用裁剪进行局部重绘
- 尽量少用性能开销高的api
- 清除画布尽量使用clearRect
- Canvas注意事项
-
- Canvas宽高与CSS宽高
- Canvas图片跨域
- 思考题:100*100的 canvas 占多少内存?
- 写在最后
什么是Canvas
在 MDN 中是这样定义 的:
是 HTML5 新增的元素,可用于通过使用 JavaScript 中的脚本来绘制图形。例如,它可以用于绘制图形、制作照片、创建动画,甚至可以进行实时视频处理或渲染。
只是一个画布,本身并不具有绘图的能力,绘图必须使用 JavaScript 等脚本语言。
标签允许JavaScript 脚本语言动态渲染位图像。它创建出了一个可绘制区域,JavaScript 代码可以通过一套绘图功能的 API 访问该区域,从而生成动态的图形。
简单来说,我们可以认为 标签只是一个矩形的画布。JavaScript 就是画笔,负责在画布上画画。
Canvas 解决了什么问题
我在 MSDN(《Microsoft Developer Network》是微软一个期刊产品,专门介绍各种编程技巧)上找到了 Canvas 出现的背景,来给大家简单介绍一下。
在互联网出现的早期,Web 只不过是静态文本和链接的集合。1993 年,有人提出了 img 标签,它可以用来嵌入图像。由于互联网的发展越来越迅猛,Web 应用已经从 Web 文档发展到 Web 应用程序。但是图像一直是静态的,人们越来越希望在其网站和应用程序中使用动态媒体(如音频、视频和交互式动画等),于是 Flash 就出现了。
但是随着 Web 应用的发展,出现了 HTML5,在 HTML5 中,浏览器中的媒体元素大受青睐。包括出现新的 Audio 和 Video 标签,可以直接将音频和视频资源放在 Web 上,而不需要其他第三方。其次就是为了解决只能在 Web 页面中显示静态图片的问题,出现了 Canvas 标签。它是一个绘图表面,包含一组丰富的 JavaScript API,这些 API 使你能够动态创建和操作图像及动画。img 对静态图形内容起到了哪些作用,Canvas 就可能对可编写脚本的动态内容起到哪些作用。
一句话总结 Canvas 是什么:
Canvas 是为了解决 Web 页面中只能显示静态图片这个问题而提出的,是一个可以使用 JavaScript 等脚本语言向其中绘制图像的 HTML 标签。
SVG 和 Canvas 的区别
怎么在网页上画一个圆?
- 直接使用图片,如果需求只是显示一个圆形,那么可以直接使用图片。
- 使用 div + CSS3 的
border+border-radius模拟一个圆。 - 使用 SVG或者 Canvas + JavaScript 动态画一个圆。
什么是 SVG
SVG(Scalable Vector Graphics,可缩放矢量图形)是基于 XML(可扩展标记语言,标准通用标记语言的子集),用于描述二维矢量图形的一种图形格式。它由 W3C(万维网联盟)制定,是一个开放标准。
简单的说就是,SVG可以用来定义 XML 格式的矢量图形。
因为其本质是 XML 文件,所以 SVG是使用 XML 文档描述来绘图的。和 HTML 一样,如果我们需要修改 SVG文件,可以直接使用记事本打开修改。
Canvas 和 SVG的区别
svg 本质上是一种使用 XML 描述 2D 图形的语言。svg 创建的每一个元素都是一个独立的 DOM 元素,既然是独立的 DOM 元素,那么我们就可以通过 css 和 JavaScript 来操控 dom。可以对每一个 DOM 元素进行监听。并且因为每一个元素都是一个 DOM 元素,所以修改 svg 中的 DOM 元素,系统会自动进行 DOM 重绘。
Canvas 通过 JavaScript 来绘制 2D 图形,Canvas 只是一个 HTML 元素,其中的图形不会单独创建 DOM 元素。因此我们不能通过 JavaScript 操控 Canvas 内单独的图形,不能对其中的具体图形进行监控。在 Canvas 中,一旦图形被绘制完成,它就不会继续得到浏览器的关注。如果其位置发生变化,那么整个场景也需要重新绘制,包括任何或许已被图形覆盖的对象。
Canvas 是基于像素的即时模式图形系统,绘制完对象后不保存对象到内存中,当再次需要这个对象时,需要重新绘制;
svg 是基于形状的保留模式图形系统,绘制完对象后会将其保存在内存中,当需要修改这个对象信息时,直接修改就可以了。这种根本的区别导致了很多应用场景的不同。
Canvas和SVG是当前HTML5中主要使用的图形绘制技术,前者提供画布标签和绘制API,后者是一整套独立的矢量图形语言,使用 XML 格式定义图像。
- Canvas通过JS绘制图形,只有当个HTML元素;而SVG使用 XML 格式定义图形,生成的图形包含多种图形元素(Path、Line、Rect)。
- Canvas绘制基于像素级控制;SVG则基于内部图形元素操作控制;
- Canvas是像素级渲染,依赖分辨率;SVG则是矢量图形,缩放时图形质量不会失真;
- 事件交互:Canvas中,事件只能注册到
标签上,但通过事件委托,可以细化到像素点(x,y)的交互;SVG则可以为某个元素附加 单独的JavaScript 事件处理器,但也只能控制细化在图形元素上。 - Canvas适合小面积、大数据应用场景;SVG适合大面积、小数量应用场景(图像元素少)。
Canvas适用场景:适合像素处理,动态渲染和大数据量绘制; 适合图像密集型的游戏;
SVG适用场景:适合静态图片展示,高保真文档查看和打印的应用场景。
Canvas基本使用
Canvas标签的默认大小为:300 x 150 (像素),而这里咱们设置为了:200 x 200(像素)
Canvas标签中的文字是在不支持Canvas标签的浏览器中使用的,因为支持Canvas标签的浏览器会忽略容器中包含的内容正常渲染Canvas标签,而不支持Canvas标签的浏览器则相反,浏览器会忽略容器而显示其中的内容。
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>canvas 基本使用title>
head>
<body>
<canvas width="200" height="200">
当前浏览器不支持canvas元素,请升级或更换浏览器!
canvas>
body>
html>
获取 Canvas 对象
创建了一个 Canvas 画布后,第二步要做的就是获取到 Canvas 的上下文环境,对应的语法为:
canvas.getContext(contextType, contextAttributes);
2d:建立二维渲染上下文。这种情况可以用CanvasRenderingContext2D()来替换getContext('2d')。webgl(或experimental-webgl): 创建一个WebGLRenderingContext三维渲染上下文对象。只在实现WebGL 版本1(OpenGL ES 2.0)的浏览器上可用。webgl2(或experimental-webgl2):创建一个WebGL2RenderingContext三维渲染上下文对象。只在实现 WebGL 版本2 (OpenGL ES 3.0)的浏览器上可用。bitmaprenderer:创建一个只提供将canvas内容替换为指定ImageBitmap功能的ImageBitmapRenderingContext。
第二个参数并不是经常用到,所以这里就不给大家介绍了,有兴趣的可以查阅 MDN 文档
var canvas = document.getElementById("canvas");
var context = canvas.getContext("2d");
context 是一个状态机,可以改变 context 的若干状态,而几乎所有的渲染操作,最终的效果与 context 本身的状态有关系
绘制线条
设置开始位置: context.moveTo( x, y )设置初始位置,参数为初始位置x和y的坐标点
设置终点位置: context.lineTo( x, y )绘制一条从初始位置到指定位置的直线,参数为指定位置x和y的坐标
这里需要注意:
- 如果没有
moveTo,那么第一次lineTo的就视为moveTo- 每次
lineTo后如果没有moveTo,那么下次lineTo的开始点为前一次lineTo的结束点。
描边绘制: context.stroke()通过线条来绘制图形轮廓
填充绘制: context.fill()通过填充路径的内容区域生成实心的图形
新建路径: context.beginPath()新建一条路径,生成之后,图形绘制命令被指向到路径上
闭合路径: context.closePath()闭合路径之后图形绘制命令又重新指向到上下文中
需要说明一下:
- 关闭路径其实并不是必须的,对于新路径其实每次都开启新路径就ok
绘制矩形
fillRect( x , y , width , height)填充一个以 (x , y) 为起点宽高分别为 width、height 的矩形stokeRect( x , y , width , height)绘制一个空心以 (x , y) 为起点宽高分别为 width、height 的矩形clearRect( x, y , width , height )清除以 (x , y) 为起点宽高分别为 width、height 的矩形
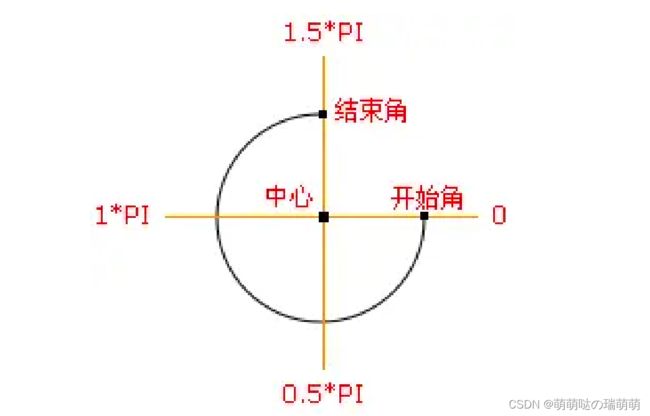
绘制圆弧/曲线
arc(x, y, radius, startAngle, endAngle, anticlockwise)
- x和Y为圆心的坐标
- radius为半径
- startAngle为圆弧或圆的开始位置
- endAngle为圆弧或圆的结束位置
- anticlockwise是绘制的方向(不写默认为false,从顺时针方向)
需要注意的是:在画弧的时候,arc()函数中角的单位是弧度而不是角度
角度换算为弧度的表达式为:
弧度=(Math.PI/180)*角度
ellipse(x, y, radiusX, radiusY, rotation, startAngle, endAngle, anticlockwise)
- x、y:椭圆的圆心位置
- radiusX、radiusY:x轴和y轴的半径
- rotation:椭圆的旋转角度,以弧度表示
- startAngle:开始绘制点
- endAngle:结束绘制点
- anticlockwise:绘制的方向(默认顺时针),可选参数。
设置样式
在上面的图形绘制中都只是默认的样式,接下来说一下具体有哪些绘制样式
CanvasRenderingContext2D.lineWidth设置当前绘线的粗细,属性值必须为正数,默认值是 1.0CanvasRenderingContext2D.strokeStyle设置或返回线条的颜色、渐变或模式CanvasRenderingContext2D.fillStyle设置或返回用于填充绘画的颜色、渐变或模式CanvasRenderingContext2D.shadowColor设置或返回用于阴影的颜色CanvasRenderingContext2D.shadowBlur设置或返回用于阴影的模糊级别CanvasRenderingContext2D.lineCap设置线末端类型,‘butt’( 默认 ), ‘round’, ‘square’CanvasRenderingContext2D.lineJoin设置相交线的拐点, ‘miter’(默认),‘round’, ‘bevel’CanvasRenderingContext2D.getLineDash()返回当前虚线设置的样式,长度为非负偶数的数组CanvasRenderingContext2D.setLineDash()设置线段样式CanvasRenderingContext2D.lineDashOffset设置虚线样式的起始偏移量
渐变
渐变分为两种,分别是线性渐变和径向渐变,在绘图中我们可以用线性或者径向的渐变来填充或描边
| 方法 | 描述 |
|---|---|
createLinearGradient() |
创建线性渐变 |
createRadialGradient() |
创建放射状/环形的渐变 |
addColorStop() |
规定渐变对象中的颜色和停止位置 |
createLinearGradient(x1, y1, x2, y2),参数分别为起点的坐标和终点的坐标
这是粉色到白色的由上向下的渐变:
var canvas = document.getElementById("canvas");
var context = canvas.getContext("2d");
var cx = canvas.width = 400;
var cy = canvas.height = 400;
var grd = context.createLinearGradient(100,100,100,200);
grd.addColorStop(0,'pink');
grd.addColorStop(1,'white');
context.fillStyle = grd;
context.fillRect(100,100,200,200);
可以看出,createLinearGradient() 的参数是两个点的坐标,这两个点的连线实际上就是渐变的方向。
我们可以使用 addColorStop() 方法来设置渐变的颜色。
gradient.addColorStop(stop,color);:
stop:介于 0.0 与 1.0 之间的值,表示渐变中开始与结束之间的位置color:在结束位置显示的 CSS 颜色值
我们可以设置多个颜色断点,比如,要实现一个彩虹的效果,只需要多增加几个颜色断点就可以了
var canvas = document.getElementById("canvas");
var context = canvas.getContext("2d");
var cx = canvas.width = 400;
var cy = canvas.height = 400;
var grd = context.createLinearGradient(0,0,0,400);
grd.addColorStop(0,'rgb(255, 0, 0)');
grd.addColorStop(0.2,'rgb(255, 165, 0)');
grd.addColorStop(0.3,'rgb(255, 255, 0)');
grd.addColorStop(0.5,'rgb(0, 255, 0)');
grd.addColorStop(0.7,'rgb(0, 127, 255)');
grd.addColorStop(0.9,'rgb(0, 0, 255)');
grd.addColorStop(1,'rgb(139, 0, 255)');
context.fillStyle = grd;
context.fillRect(0,0,400,400);

绘制文本
canvas 中依旧提供了两种方法来渲染文本,一种是描边一种是填充
ctx.strokeText(text, x, y, maxWidth)
- text:绘制的文案
- x、y:文本的起始位置
- maxWidth:可选参数,最大宽度。需要注意的是当文案大于最大宽度时不是裁剪或者换行,而是缩小字体。
ctx.fillText(text, x, y, maxWidth)
- text:绘制的文案
- x、y:文本的起始位置
- maxWidth:可选参数,最大宽度。需要注意的是当文案大于最大宽度时不是裁剪或者换行,而是缩小字体。
图像绘制
绘制图片和上面的绘制基本大同小异,绘制图片是使用 drawImage 方法将它渲染到 canvas 里
context.drawImage(img,sx,sy,swidth,sheight,x,y,width,height);
img:规定要使用的图像、画布或视频sx:可选,开始剪切的 x 坐标位置sy:可选,开始剪切的 y 坐标位置swidth:可选,被剪切图像的宽度sheight:可选,被剪切图像的高度x:在画布上放置图像的 x 坐标位置y:在画布上放置图像的 y 坐标位置width:可选,要使用的图像的宽度(伸展或缩小图像)height:可选,要使用的图像的高度(伸展或缩小图像)
移动、旋转和缩放
| 方法 | 描述 |
|---|---|
scale(x, y) |
缩放当前绘图至更大或更小,x 为水平缩放的值,y 为垂直缩放得值。x和y的值小于1则为缩小,大于1则为放大。默认值为 1 |
rotate(angle) |
旋转当前绘图,angle 是旋转的角度,它是顺时针旋转,以弧度为单位 |
translate(x, y) |
重新映射画布上的 (0,0) 位置,x 是左右偏移量,y 是上下偏移量 |
transform() |
替换绘图的当前转换矩阵,将当前的变形矩阵乘上一个基于自身参数的矩阵 |
setTransform() |
将当前转换重置为单位矩阵,然后运行 transform() |
在进行图形变换的时候,我们需要画布旋转,然后再绘制图形,旋转的中心点始终是 canvas 的原点;
需要注意的是,我们使用的图形变换的方法都是作用在画布上的,既然对画布进行了变换,那么在接下来绘制的图形都会变换。比如对画布使用了
rotate(20*Math.PI/180)方法,就是将画布旋转了 20°,那么之后绘制的图形都会旋转 20°
合成与裁剪
合成的图形受限于绘制的顺序
如果我们不想受限于绘制的顺序,那么我们可以利用 globalCompositeOperation 属性来改变这种情况
语法:globalCompositeOperation = type,type为合成的类型
source-over,默认值,在现有画布上下文之上绘制新图形source-in,新图形只在新图形和目标画布重叠的地方绘制,其他的都是透明的source-out,在不与现有画布内容重叠的地方绘制新图形source-atop,新图形只在与现有画布内容重叠的地方绘制destination-over,在现有的画布内容后面绘制新的图形destination-in,现有的画布内容保持在新图形和现有画布内容重叠的位置destination-out,现有内容保持在新图形不重叠的地方destination-atop,现有的画布只保留与新图形重叠的部分,新的图形是在画布内容后面绘制的
裁剪的作用是遮罩,用来隐藏不需要的部分,所有在路径以外的部分都不会在 canvas 上绘制出来
裁剪的效果和 globalCompositeOperation 属性的 source-in 和 source-atop差不多,但也有区别
最重要的区别是裁剪路径不会在 canvas 上绘制东西,而且它永远不受新图形的影响
语法:clip() 将当前正在构建的路径转换为当前的裁剪路径
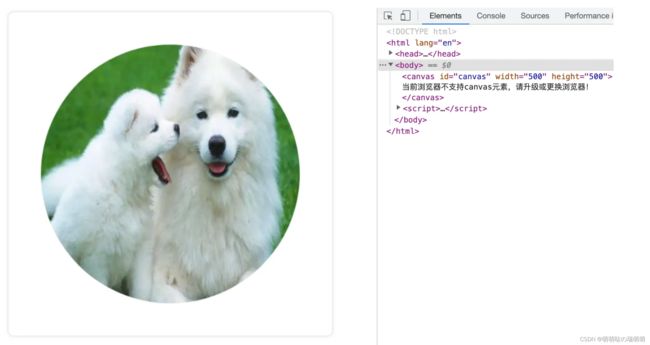
// 获取 canvas 元素
var canvas = document.getElementById('canvas');
// 通过判断getContext方法是否存在来判断浏览器的支持性
if(canvas.getContext) {
// 获取绘图上下文
var ctx = canvas.getContext('2d');
var img = new Image();
img.src = 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2F5b0988e595225.cdn.sohucs.com%2Fimages%2F20191212%2F556cc408058d4c64a46468761406afe6.png&refer=http%3A%2F%2F5b0988e595225.cdn.sohucs.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1660103116&t=8dd0c641e1e1890fa65ee80dfa428d34';
img.onload = function(){
// 创建圆形裁剪路径
ctx.arc(250, 250, 200, 0, Math.PI*2, false);
ctx.clip();
// 创建完后绘制
ctx.drawImage(img, 0, 0, 500, 500);
}
}
保存和恢复
save() 和 restore() 方法是用来保存和恢复 canvas 状态的,方法不需要参数,基于状态记录
save()和restore()方法只会在有效范围内生效,它是绘制状态的存储器,并不是画布内容的存储器
当我们保存一个状态以后,在我们恢复以后可以继续使用这个状态
Canvas的状态是存储在栈中的,每次调用save()方法后,当前的状态都会被推送到栈中保存起来
save()保存的状态是可以多次保存的,同时保存在栈中的元素遵循的是后进先出的顺序
每一次调用 restore() 方法,上一个保存的状态就从栈中弹出,所有设定都恢复
save()和restore()的使用场景也很广泛,例如 "变换"状态的用途
当执行“变换”操作时,整个上下文的坐标系都将会改变
“变换”之后,我们需要将坐标系恢复到原有正常的状态,这时候就需要使用save()和restore():
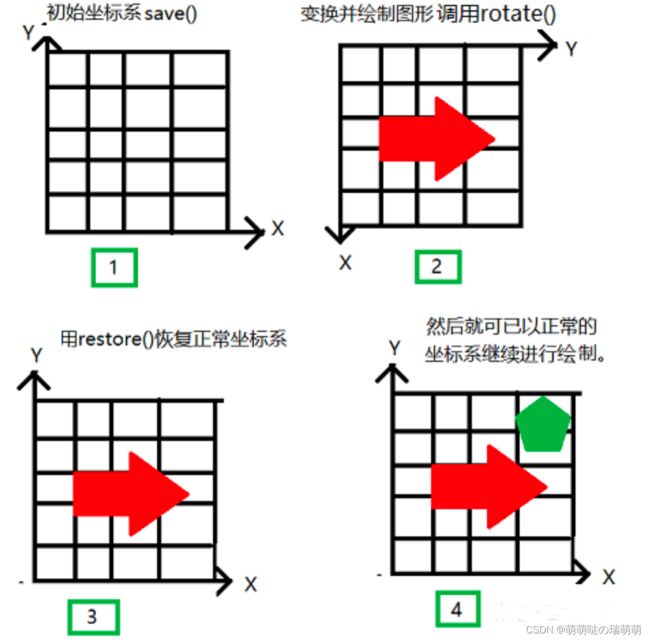
我们看到在调用了restore()绘制的图形并没有发生变化,只是绘制状态发生了变化
因为绘制好的图形并不属于绘制状态,而restore()和save()只作用于绘制状态
Canvas Context维持着绘制状态的堆栈,绘画的状态有哪些呢(就是我们可以保存和恢复的状态有哪些)?
- 应用的变形:移动、旋转、缩放、
strokeStyle、fillStyle、globalAlpha、lineWidth、lineCap、lineJoin、miterLimit、lineDashOffset、shadowOffsetX、shadowOffsetY、shadowBlur、shadowColor、globalCompositeOperation、font、textAlign、textBaseline、direction、imageSmoothingEnabled等。 - 应用的裁切路径(
clipping path)
动画
Canvas呈现的东西都是绘制完了以后才能看到,因此想通过Canvas自己提供的 Api 来实现动画是做不到的
那么为了实现动画,我们需要一些可以定时执行重绘的方法
-
setInterval(function, delay):定时器,当设定好间隔时间后,function 会定期执行 -
setTimeout(function, delay):延时器,在设定好的时间之后执行函数 -
requestAnimationFrame(callback):告诉浏览器希望执行一个动画,并在重绘之前,请求浏览器执行一个特定的函数来更新动画
正常情况下,当我们需要自动去展示动画而不需要和用户交互的情况下,我们会选择 setInterval()方法,因为我们只需要把执行动画的代码丢在 setInterval()方法中,他就会自动执行绘制我们想要的动画。
如果我们做一些交互性的动画,那么使用 setTimeout() 方法和键盘或者鼠标事件配合会更简单一些,通过设置事件监听,可以捕捉用户的交互,并执行相应的动作。
相对于前两个方法,requestAnimationFrame()方法可能会显得陌生一些,requestAnimationFrame()方法提供了更加平缓且有效率的方式来执行动画,当我们准备好动画以后,把动画交给requestAnimationFrame()方法就能绘制动画帧。
requestAnimationFrame相对于setinterval处理动画有以下几个优势:
- 经过浏览器优化,动画更流畅
- 窗口没激活时,动画将停止,节省计算资源
- 更省电,尤其是对移动终端
这个 API 不需要传入动画间隔时间,这个方法会告诉浏览器以最佳的方式进行动画重绘
requestAnimationFrame()一般每秒钟回调函数执行 60 次,也有可能会被降低它遵循 W3C 的建议 ,浏览器中的回调函数执行次数通常与浏览器屏幕刷新次数相匹配
如果用
setInterval()方法来做动画,我们需要设置一下多长时间执行一次setInterval()方法里面的代码块。而这个时间我们只要设定了,那么就会强行这个时间执行。而如果我们的浏览器显示频率和
setInterval()方法执行的绘制请求不一致,就会造成卡顿的效果。同时,定时器的实现其实是在当前任务队列完成后再执行定时器的回调,也就是如果当前队列的执行时间大于定时器设置的时间,那么这个定时器的时间就不是那么靠谱了。
由于定时器的时间只是我们自己设置的一个期望渲染时间,但这个时间点其实并非浏览器一个重绘的时间点,当这两个时间点出现偏差时,可能就会发生丢帧之类的现象。
因此使用
requestAnimationFrame()方法做动画会更加平缓且有效率。
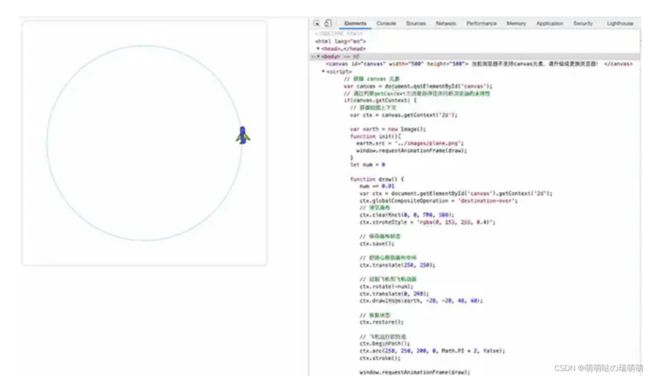
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>canvas - 动画title>
head>
<body>
<canvas
id="canvas"
width="550"
height="500"
style="box-shadow: 0px 0px 5px #ccc; border-radius: 8px;">
当前浏览器不支持canvas元素,请升级或更换浏览器!
canvas>
<script>
// 获取Canvas
const canvas = document.getElementById('canvas');
// 获取绘制上下文
const ctx = canvas.getContext('2d');
// globalCompositeOperation 属性设置或返回如何将一个源(新的)图像绘制到目标(已有的)的图像上。
// 设置或返回如何将一个源(新的)图像绘制到目标(已有的)的图像上,而属性值 destination-over 就是把源图像绘制到目标图像的上面(也就是源图像盖到目标图像的上面)
// 这里主要是为了让飞机压在运行轨迹上
ctx.globalCompositeOperation = 'destination-over';
const width = canvas.width
const height = canvas.height
let num = 0
ctx.strokeStyle = "#ccc"
const img = new Image()
img.src="../images/plane.png"
img.onload = ()=>{
requestAnimationFrame(planeRun);
}
function planeRun(){
// 清空画布
ctx.clearRect(0, 0, width, height)
// 保存画布状态
ctx.save();
// 把原心移到画布中间
ctx.translate(250, 250);
// 绘制飞机和飞机动画
num += 0.01
ctx.rotate(-num);
ctx.translate(0, 200);
ctx.drawImage(img, -20, -25, 40, 40);
// 恢复状态
ctx.restore();
// 飞机运行的轨迹
ctx.beginPath();
ctx.arc(250, 250, 200, 0, Math.PI * 2, false);
ctx.stroke();
// 执行完以后继续调用
requestAnimationFrame(planeRun);
}
script>
body>
html>
事件
给Canvas中的元素添加事件用addEventListener()方法,移除事件用removeEventListener()方法
Canvas支持所有的鼠标事件但是并不支持键盘事件,通过为windows对象添加键盘事件,从而控制canvas元素
当使用键盘时,
tabindex是个关键因素,它用来定位html元素
tabindex有三个值:0 ,-1, 以及X(X里32767是界点)原本在Html中,只有链接a和表单元素可以被键盘访问(即使是a也必须加上href属性才可以),但是aria允许
tabindex指定给任何html元素。当
tabindex=0时,该元素可以用tab键获取焦点,且访问的顺序是按照元素在文档中的顺序来focus,即使采用了浮动改变了页面中显示的顺序,依然是按照html文档中的顺序来定位。当
tabindex=-1时,该元素用tab键获取不到焦点,但是可以通过js获取,这样就便于我们通过js设置上下左右键的响应事件来focus,在widget内部可以用到。当
tabindex>=1时,该元素可以用tab键获取焦点,而且优先级大于tabindex=0;不过在tabindex>=1时,数字越小,越先定位到。在IE中,tabindex 范围在1到32767之间(包括32767),在 Chrome 无限制,不过一旦超出32768,顺序跟tabindex=0时一样,这个估计跟各个浏览器对int型的解析有关。
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>canvas - 键盘事件title>
<style>
* { margin: 0; padding: 0; }
style>
head>
<body>
<canvas
id="canvas"
width="500"
height="500"
tabindex="0"
style="box-shadow: 0px 0px 5px #ccc; border-radius: 8px;">
当前浏览器不支持canvas元素,请升级或更换浏览器!
canvas>
<script>
// 获取Canvas
const canvas = document.getElementById('canvas');
// 获取绘制上下文
const ctx = canvas.getContext('2d');
// 设置填充的颜色为橘色
ctx.fillStyle="orange";
// 获取x,y的值
let x = canvas.width / 2 - 50;
let y = canvas.height / 2 - 50;
// 绘制一个矩形
ctx.fillRect(x, y, 100, 50);
// 给canvas添加鼠标移动事件
window.addEventListener("keydown", doKeydown, false);
function doKeydown(e) {
ctx.clearRect(0, 0, 500, 500)
var keyID = e.keyCode ? e.keyCode :e.which;
switch(e.keyCode) {
case 37:
console.log(`按下左键`)
x = x - 10;
ctx.fillRect(x, y, 100, 50);
break;
case 38:
console.log(`按下上键`)
y = y - 10;
ctx.fillRect(x, y, 100, 50);
break;
case 39:
console.log(`按下右键`)
x = x + 10;
ctx.fillRect(x, y, 100, 50);
break;
case 40:
console.log(`按下下键`)
y = y + 10;
ctx.fillRect(x, y, 100, 50);
break;
}
}
script>
body>
html>
上面的例子中,事件其实都是添加到canvas元素上的,但往往在平常我们需要针对canvas元素内部的子元素做单独的事件交互,那么我们就需要考虑如何给canvas元素的内部元素添加事件。
canvas元素本身并没有提供给内部元素添加事件的Api,正常开发中我们其实也很少会直接使用原生的方式和canvas元素的内部元素进行交互,因为正常开发我们往往会使用canvas的一些成熟的框架或者库(比如Pixi.js,fabric.js )来实现这样的需求,而这样的库中肯定已经封装了为单独元素添加交互的Api。但这里咱们既然学习的是canvas本身,那么咱们就看看如何实现和canvas元素的内部元素进行交互。
Canvas拖拽相册
这里咱们就以拖拽为例,假如canvas元素内部有多个子元素,那么想拖拽其中一个子元素,我们首先得知道,在鼠标按下的时候是否按在canvas元素的子元素上,只有按在canvas元素的子元素上我们才能对它进行拖拽。
首先准备几个图片,我们先把他绘制到canvas元素中
接下来就是为canvas元素添加鼠标按下、鼠标移动和鼠标抬起三个事件
因为只有鼠标按下才能拖拽,所以我们把鼠标移动和鼠标抬起事件的添加放在鼠标按下的事件中。
定义完事件以后,我们就需要判断每次点击的元素是其中的哪一个,这样我们才能针对这个元素做交互。
判断每次点击的元素是其中的哪一个元素,有两种方法:
方法一:通过计算,如上面布局的代码,每个图片绘制的x、y、width 和 height 我们都是知道的,那么当我们每次点击下去的时候就可以遍历图片的数据,看我们是否点击到元素上。
方法二:我们还可以利用canvas元素自身提供的方法来确定咱们选中的元素是哪一个。这里利用的是:isPointInPath()方法,此方法可以把坐标传入,然后判断是否在路径之内。
语法:isPointInPath(x, y) x为监测点的 x 坐标,y为监测点的 y 坐标。
这里需要注意的是,在案例中是通过drawImage()方法把图片绘制到canvas元素上,而drawImage()方法不支持isPointInPath()方法的路径检测,这里我们就需使用绘制路径的方法,因此在绘制图片的时候,我们就需要同时绘制一个一样大小的路径。
知道选中的元素以后,我们就需要在移动的时候把移动的坐标赋值给选中的元素,让选中的元素跟着鼠标移动。
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>canvas - 事件title>
<style>
* {
margin: 0;
padding: 0;
}
style>
head>
<body>
<canvas id="canvas" width="1000" height="500" tabindex="0"
style="box-shadow: 0px 0px 5px #ccc; border-radius: 8px;">
当前浏览器不支持canvas元素,请升级或更换浏览器!
canvas>
<script>
// 获取Canvas
const canvas = document.getElementById('canvas');
const width = canvas.width;
const height = canvas.height;
// 获取绘制上下文
const ctx = canvas.getContext('2d');
const images = [
{
name: "白月魁",
url: "https://img1.baidu.com/it/u=2493717231,3996978742&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=438"
},
{
name: "鸣人",
url: "https://img1.baidu.com/it/u=2493717231,3996978742&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=438",
},
{
name: "路飞",
url: "https://img1.baidu.com/it/u=2493717231,3996978742&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=438",
},
{
name: "哪吒",
url: "https://img1.baidu.com/it/u=2493717231,3996978742&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=438",
},
{
name: "千寻",
url: "https://img1.baidu.com/it/u=2493717231,3996978742&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=438",
},
];
let imagesData = []
let clickCoordinate = { x: 0, y: 0 }
let target;
images.forEach((item) => {
// 创建image元素
const image = new Image()
image.src = item.url;
const name = item.name;
image.onload = () => {
// 控制宽度为200(等宽)
const w = 200;
// 高度按宽度200的比例缩放
const h = 200 / image.width * image.height;
const x = Math.random() * (width - w);
const y = Math.random() * (height - h);
const imageObj = { image, name, x, y, w, h }
imagesData.push(imageObj)
draw(imageObj)
}
})
// 渲染图片
function draw(imageObj) {
ctx.drawImage(imageObj.image, imageObj.x, imageObj.y, imageObj.w, imageObj.h);
ctx.beginPath();
ctx.strokeStyle = "#fff";
ctx.rect(imageObj.x, imageObj.y, imageObj.w, imageObj.h);
ctx.stroke();
}
// 为canvas添加鼠标按下事件
canvas.addEventListener("mousedown", mousedownFn, false)
// 鼠标按下触发的方法
function mousedownFn(e) {
// 获取元素按下时的坐标
clickCoordinate.x = e.pageX - canvas.offsetLeft;
clickCoordinate.y = e.pageY - canvas.offsetTop;
// 判断选中的元素是哪一个
checkElement()
// 未选中元素则return
if (target == undefined) return;
// 为canvas添加鼠标移动和鼠标抬起事件
canvas.addEventListener("mousemove", mousemoveFn, false)
canvas.addEventListener("mouseup", mouseupFn, false)
}
// 鼠标移动触发
function mousemoveFn(e) {
const moveX = e.pageX
const moveY = e.pageY
// 计算移动元素的坐标
imagesData[target].x = imagesData[target].x + (moveX - clickCoordinate.x);
imagesData[target].y = imagesData[target].y + (moveY - clickCoordinate.y);
// 清空画布
ctx.clearRect(0, 0, width, height);
// 清空画布以后重新绘制
imagesData.forEach((i) => draw(i))
// 赋值
clickCoordinate.x = moveX;
clickCoordinate.y = moveY;
}
// 鼠标抬起触发
function mouseupFn() {
// 鼠标抬起以后移除事件
canvas.removeEventListener("mousemove", mousemoveFn, false)
canvas.removeEventListener("mouseup", mouseupFn, false)
// 销毁选中元素
target = undefined
}
// 检测选中的元素是哪一个
function checkElement() {
imagesData.forEach((item, index) => {
draw(item)
if (ctx.isPointInPath(clickCoordinate.x, clickCoordinate.y)) {
target = index
console.log("点击的元素是:", item.name)
}
})
}
script>
body>
html>
Canvas截图保存
在日常中,我们会看到一些H5小游戏或者类似支付宝年度账单之类的小应用,其中就会有保存图片的按钮,或者说长按保存图片之类的功能,我们来看看这个功能是如何实现的
我们知道在保存图片的案例中,需要用到toDataURL(type, encoderOptions)
toDataURL(type, encoderOptions)方法可以返回一个包含图片的Data URL
Data URL也就是前缀为 data: 协议的URL,其允许内容创建者向文档中嵌入小文件
type:type为图片格式,默认为image/png,也可指定为:image/jpeg、image/webp等格式encoderOptions:图片的质量,默认值0.92。在指定图片格式为image/jpeg或image/webp的情况下,可以从0到1的区间内选择图片的质量。如果不在这个范围内,则使用默认值0.92
下面咱们以上面的相册拖拽为例,把每次拖拽好的相册截屏保存起来
// 点击截图函数
function clickFn(){
// 将canvas转换成base64的url
let url = canvas.toDataURL("image/png");
// 把Canvas 转化为图片
Img.src = url;
// 将base64转换为文件对象
let arr = url.split(",")
let mime = arr[0].match(/:(.*?);/)[1] // 此处得到的为文件类型
let bstr = atob(arr[1]) // 此处将base64解码
let n = bstr.length
let u8arr = new Uint8Array(n);
while (n--) {
u8arr[n] = bstr.charCodeAt(n);
}
// 通过以下方式将以上变量生成文件对象,三个参数分别为文件内容、文件名、文件类型
let file = new File([u8arr], "filename", { type: mime });
// 将文件对象通过a标签下载
let aDom = document.createElement("a"); // 创建一个 a 标签
aDom.download = file.name; // 设置文件名
let href = URL.createObjectURL(file); // 将file对象转成 UTF-16 字符串
aDom.href = href; // 放入href
document.body.appendChild(aDom); // 将a标签插入 body
aDom.click(); // 触发 a 标签的点击
document.body.removeChild(aDom); // 移除刚才插入的 a 标签
URL.revokeObjectURL(href); // 释放刚才生成的 UTF-16 字符串
};
Canvas主题滤镜
实现滤镜的方式有很多种方式,这里既然咱们介绍的是canvas的应用,那么就用canvas的方式来实现看看。
具体实现我们可以遍历所有像素然后改变他们的数值,再将被修改的像素数组通过 putImageData() 方法放回到画布中去,以达到反相颜色。
getImageData()方法可以返回一个ImageData对象。
putImageData()方法和getImageData()方法正好相反,可以将数据从已有的ImageData对象绘制为位图。如果提供了一个绘制过的矩形,则只绘制该矩形的像素。
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>canvas - 主题title>
<style>
canvas {
box-shadow: 0px 0px 5px #ccc;
border-radius: 8px;
}
style>
head>
<body>
<canvas id="canvas" width="450" height="800">
当前浏览器不支持canvas元素,请升级或更换浏览器!
canvas>
<div class="btnBox">
<button id="original">还原button>
<button id="blackWhite">黑白主题button>
<button id="exposure">曝光主题button>
div>
<script>
// 获取 canvas 元素
var canvas = document.getElementById('canvas');
var originalEl = document.getElementById('original');
var blackWhiteEl = document.getElementById('blackWhite');
var exposureEl = document.getElementById('exposure');
var sepiaEl = document.getElementById('sepia');
// 通过判断getContext方法是否存在来判断浏览器的支持性
if (canvas.getContext) {
// 获取绘图上下文
var ctx = canvas.getContext('2d');
var img = new Image();
img.crossOrigin = 'anonymous';
img.src = 'https://img1.baidu.com/it/u=4141276181,3458238270&fm=253&fmt=auto&app=138&f=JPEG';
img.onload = function () {
ctx.drawImage(img, 0, 0, 450, 800);
};
var original = function () {
ctx.drawImage(img, 0, 0, 450, 800);
};
// 黑白主题, 用红绿和蓝的平均值来实现
var exposure = function () {
ctx.drawImage(img, 0, 0, 450, 800);
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
const data = imageData.data;
for (var i = 0; i < data.length; i += 4) {
data[i] = 255 - data[i]; // red
data[i + 1] = 255 - data[i + 1]; // green
data[i + 2] = 255 - data[i + 2]; // blue
}
ctx.putImageData(imageData, 0, 0);
};
// 曝光主题, 减掉颜色的最大色值255来实现
var blackWhite = function () {
ctx.drawImage(img, 0, 0, 450, 800);
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
const data = imageData.data;
for (var i = 0; i < data.length; i += 4) {
var avg = (data[i] + data[i + 1] + data[i + 2]) / 3;
data[i] = avg; // red
data[i + 1] = avg; // green
data[i + 2] = avg; // blue
}
ctx.putImageData(imageData, 0, 0);
};
originalEl.addEventListener("click", function (e) {
original()
})
blackWhiteEl.addEventListener("click", function (e) {
blackWhite()
})
exposureEl.addEventListener("click", function (e) {
exposure()
})
}
script>
body>
html>
Canvas拾色器

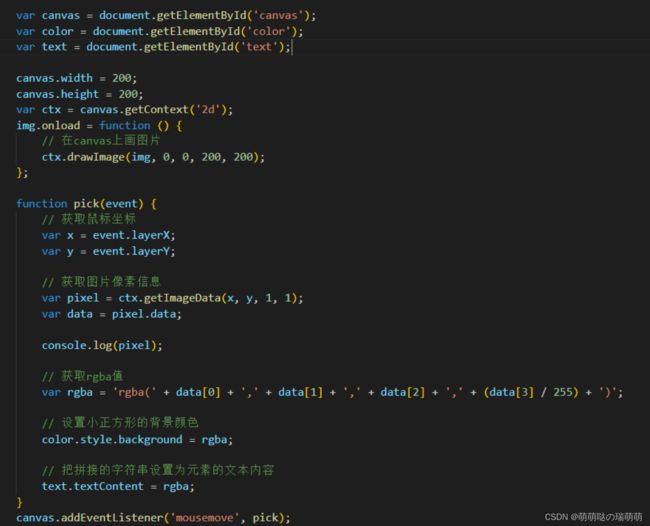
实现思路
1、先通过canvas.getContext('2d').drawImage(img, 0, 0, 200, 200)把图片画到 canvas 上;
2、然后canvas.addEventListener('mousemove', pick);获取鼠标移动时的实时坐标并通过 ctx.getImageData(x, y, 1, 1).data 获取这一个点的像素信息;
3、得到像素信息后,拼接出 rgba 的字符串,再设置下面的小正方形的背景是这个颜色color.style.background = 'rgba(' + data[0] + ',' + data[1] + ',' + data[2] + ',' + (data[3] / 255) + ')';

Canvas马赛克
let canvas = document.createElement("canvas");
let ctx = canvas.getContext("2d");
let img = new Image();
img.onload = function () {
let w = img.width;
let h = img.height;
canvas.width = w;
canvas.height = h;
ctx.drawImage(img, 0, 0);
// 获取图片像素点列表
let pixList = ctx.getImageData(0, 0, w, h).data;
// 打码的格子尺寸
const sampleSize = 40;
// 图像行列遍历
for (let y = 0; y < h; y += sampleSize) {
for (let x = 0; x < w; x += sampleSize) {
// x列前面多少个 + y多少行 * 宽 * 4 (4代表rgba) 得到坐标
let p = (x + y * w) * 4;
// 通过索引获取color
ctx.fillStyle ="rgba(" + pixList[p] + "," + pixList[p + 1] + "," + pixList[p + 2] + "," + pixList[p + 3] + ")";
ctx.fillRect(x, y, sampleSize, sampleSize);
}
}
};
Canvas简易画板
制作画笔
- 声明一个变量作为标识
- 鼠标按下的时候,记录起点位置
- 鼠标移动的时候,开始描绘并连线
- 鼠标抬起的时候,关闭开关
var cas = document.querySelector('canvas')
var ctx = cas.getContext('2d')
var isDraw = false
// 鼠标按下事件
cas.addEventListener('mousedown', function () {
isDraw = true
ctx.beginPath()
})
// 鼠标移动事件
cas.addEventListener('mousemove', function (e) {
if (!isDraw) {
// 没有按下
return
}
// 获取相对于容器内的坐标
var x = e.offsetX
var y = e.offsetY
ctx.lineTo(x, y)
ctx.stroke()
})
cas.addEventListener('mouseup', function () {
// 关闭开关了!
isDraw = false
})
手动涂擦
原理和画笔相似,只不过用的是clearRect()方法。
var cas = document.querySelector('canvas')
var ctx = cas.getContext('2d')
ctx.fillRect(0, 0, 600, 600)
// 开关
var isClear = false
cas.addEventListener('mousedown', function () {
isClear = true
})
cas.addEventListener('mousemove', function (e) {
if (!isClear) {
return
}
var x = e.offsetX
var y = e.offsetY
var w = 20
var h = 20
ctx.clearRect(x, y, w, h)
})
cas.addEventListener('mouseup', function () {
isClear = false
})
如何实现圆形的橡皮檫?
canvas的API中,可以清除像素的就是clearRect方法,但是clearRect方法的清除区域矩形
毕竟大部分人的习惯中的橡皮擦都是圆形的,所以就引入了剪辑clip方法 :
ctx.save()
ctx.beginPath()
ctx.arc(x2,y2,a,0,2*Math.PI);
ctx.clip()
ctx.clearRect(0,0,canvas.width,canvas.height);
ctx.restore();
上面那段代码就实现了圆形区域的擦除
也就是先实现一个圆形路径,然后把这个路径作为剪辑区域,再清除像素就行了
有个注意点就是需要先保存绘图环境,清除完像素后要重置绘图环境
如果不重置的话以后的绘图都是会被限制在那个剪辑区域中
实现撤销
实现思路:可以把每一步操作都记下来,撤回功能就进行重新绘制
class WrappedCanvas {
constructor (canvas) {
this.ctx = canvas.getContext('2d');
this.width = this.ctx.canvas.width;
this.height = this.ctx.canvas.height;
this.imgStack = [];
}
drawImage (...params) {
const imgData = this.ctx.getImageData(0, 0, this.width, this.height);
this.imgStack.push(imgData);
this.ctx.drawImage(...params);
}
undo () {
if (this.imgStack.length > 0) {
const imgData = this.imgStack.pop();
this.ctx.putImageData(imgData, 0, 0);
}
}
}
封装了一下 canvas 的 drawImage 方法,每次调用该方法之前都会保存上一个状态的快照到模拟的栈中
执行 undo 操作时,从栈中取出最新保存的快照,然后重新绘制画布,即可实现撤销操作
撤销改进
这种实现方法其实挺粗犷的,为什么呢?
一个很显而易见的原因就是此方案性能不好,这个方案相当于每次都是重新绘制整个画布
假设操作步骤很多,在模拟栈也就是内存中就会保存很多预存的画布数据
此外,在绘制图片过于复杂时,getImageData 和 putImageData 这两个方法会产生比较严重的性能问题
关于这个问题可以参考stackoverflow 上的讨论:
Why is putImageData so slow?
在下面的性能优化中我们也会说到这一项:尽可能调用那些渲染开销较低的 API
我们来从这里入手思考如何进行优化
刚刚提到,我们通过对整个画布保存快照的方式来记录每个操作
如果我们把每次绘制的动作保存到一个数组中,在每次执行撤销操作时,首先清空画布,然后重绘这个绘图动作数组,也可以实现撤销操作的功能
首先这样可以减少保存到内存的数据量,其次还避免了使用渲染开销较高的 putImageData
class WrappedCanvas {
constructor (canvas) {
this.ctx = canvas.getContext('2d');
this.width = this.ctx.canvas.width;
this.height = this.ctx.canvas.height;
this.executionArray = [];
}
drawImage (...params) {
this.executionArray.push({
method: 'drawImage',
params: params
});
this.ctx.drawImage(...params);
}
clearCanvas () {
this.ctx.clearRect(0, 0, this.width, this.height);
}
undo () {
if (this.executionArray.length > 0) {
// 清空画布
this.clearCanvas();
// 删除当前操作
this.executionArray.pop();
// 逐个执行绘图动作进行重绘
for (let exe of this.executionArray) {
this.ctx[exe.method](...exe.params)
}
}
}
}
刮刮乐
- 首先需要设置奖品和画布,将画布置于图片上方盖住,
- 随机设置生成奖品。
- 当手触摸移动的时候,可以擦除部分画布,露出奖品区。
<div>
<img src="./images/2.jpg" alt="" />
<canvas width="600" height="600">canvas>
div>
img {
width: 600px;
height: 600px;
position: absolute;
top: 10%;
left: 30%;
}
canvas {
width: 600px;
height: 600px;
position: absolute;
top: 10%;
left: 30%;
border: 1px solid #000;
}
// 鼠标拖拽不会选中文字
document.addEventListener("selectstart", function (e) {
e.preventDefault();
})
var cas = document.querySelector('canvas')
var ctx = cas.getContext('2d')
var img = document.querySelector('img')
// 加一个遮罩层
ctx.fillStyle = '#ccc'
ctx.fillRect(0, 0, cas.width, cas.height)
// 设置图片背景
setImgUrl()
// 开关
var isClear = false
cas.addEventListener('mousedown', function () {
isClear = true
})
cas.addEventListener('mousemove', function (e) {
if (!isClear) {
return
}
var x = e.offsetX
var y = e.offsetY
ctx.clearRect(x, y, 30, 30)
// 也可以选择画圆覆盖
ctx.beginPath();
ctx.arc(x, y, 30, 0, 2 * Math.PI);
// globalCompositeOperation 该属性用于设置在绘制新形状时应用的合成操作的类型
ctx.globalCompositeOperation = 'destination-out';
ctx.fill();
ctx.closePath();
})
cas.addEventListener('mouseup', function () {
isClear = false
})
function setImgUrl() {
var arr = ['./images/1.jpg', './images/2.jpg', './images/3.jpg', './images/4.jpg']
var random = Math.round(Math.random() * 3)
img.src = arr[random]
}
Canvas水印图片
什么叫图片添加水印?常见的添加水印都是在图片上面添加一个图层(内容:防伪标识或者是公司的logo之类)
水印功能的目的是为了保护网站或作者版权,防止内容被别人利用或白嫖
方法一:
水印就是两张图片,一张是我们的原图,另一张就是水印图片,然后水印图片就是那种透明背景的图片,这样两张图片叠加,既可以看见原图的内容,还加了标识。
首先我们就是借助HTML5 的 FileReader 读取文件的信息,将原图以及logo图片分别变成二进制流(base64)。
然后以canvas为画板,先画一层原图的样式,然后再将的logo覆盖上去。
这种方法局限性太大,需要我们有两张图片,不建议使用
方法二:
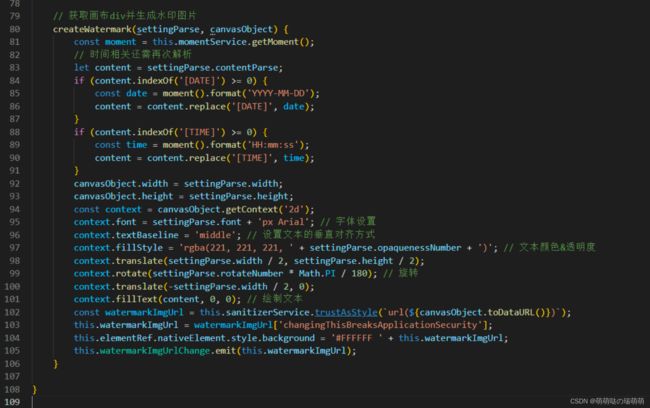
通过 canvas.toDataURL 生成一张水印图片作为背景

addWaterMark = ({
url = '', // 作为图片的内容,这个应该是必传项,传入 base64 格式的图片或者图片的 url
textAlign = 'left',
font = "30px Microsoft Yahei",
fillStyle = 'rgba(255, 255, 255, 0.8)',
content = 'E-Office',
callback = null, // 图片添加完水印后的回调事件,这个也应该是必传项
} = {}) => {
const img = new Image(); // 创建一个图片对象用来存放要改造的图片
img.src = url;
img.crossOrigin = 'anonymous'; // 解决跨域
img.onload = () => {
const canvas = document.createElement('canvas');
canvas.width = img.width; // 设置画布大小,这里如果将原图的长宽缩小,是可以对图片进行压缩处理的
canvas.height = img.height;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0, imageWidth, imageHeight);
ctx.textAlign = textAlign; // 设置水印内容样式
ctx.font = font;
ctx.fillStyle = fillStyle;
ctx.fillText(content, 10, 20);
// 将画布数据提取出来,第二个参数是对图片压缩
const base64Url = canvas.toDataURL("image/jpeg", 0.5);
callback && callback(base64Url); // 生成新的图像数据后进行接下来的操作,比如base64转文件对象
}
}
// base64转文件对象
dataURLtoBlob(dataurl, name) {
const arr = dataurl.split(',')
const mime = arr[0].match(/:(.*?);/)[1]
const bstr = atob(arr[1])
let n = bstr.length
const u8arr = new Uint8Array(n)
while (n--) {
u8arr[n] = bstr.charCodeAt(n)
}
return new File([u8arr], name, {
type: mime
})
}
Canvas性能优化
尽量避免浮点运算
利用 canvas进行动画绘制时,如果计算出来的坐标是浮点数,那么可能会出现 CSS Sub-pixel的问题,也就是会自动将浮点数值四舍五入转为整数
那么在动画的过程中,由于元素实际运动的轨迹并不是严格按照计算公式得到,那么就可能出现抖动的情况
同时也可能让元素的边缘出现抗锯齿失真 这也是可能影响性能的一方面,因为一直在做不必要的取整运算
使用多层画布绘制复杂场景
分层的目的是降低完全不必要的渲染性能开销
将变化频率高、幅度大的部分和变化频率小、幅度小的部分分成两个或两个以上的 canvas 对象
也就是说生成多个 canvas 实例,把它们重叠放置,每个 Canvas 使用不同的 z-index 来定义堆叠的次序。
动画请使用requestAnimationFrame
上面我们说过了原因
尽量少改变Canvas状态机
将画布的函数调用集合到一起, 不要频繁调度beginPath, closePath, stroke,fill, 同时减少调用canvas的api
如下代码:
for (let i = 0; i < points.length - 1; i++) {
let p1 = points[i];
let p2 = points[i + 1];
context.beginPath();
context.moveTo(p1.x, p1.y);
context.lineTo(p2.x, p2.y);
context.stroke();
}
可以改成:
context.beginPath();
for (let i = 0; i < points.length - 1; i++) {
let p1 = points[i];
let p2 = points[i + 1];
context.moveTo(p1.x, p1.y);
context.lineTo(p2.x, p2.y);
}
context.stroke();
tips: 写粒子效果时,可以使用方形替代圆形,因为粒子小,所以方和圆看上去差不多。有人问为什么?很容易理解,画一个圆需要三个步骤:先
beginPath,然后用arc画弧,再用fill。而画方只需要一个fillRect。当粒子对象达一定数量时性能差距就会显示出来了。
离屏Canvas
在离屏 Canvas 上预渲染相似的图形或者重复的对象
常用于使用 drawImage 来剪切图片,当每一帧需要调用的对象需要多次调用 canvasAPI 时,也可以使用离屏绘制进行预渲染的方式来提高性能
drawImage 方法的第一个参数不仅可以接收 Image 对象,也可以接收另一个 Canvas 对象
而且,使用 Canvas 对象绘制的开销与使用 Image 对象的开销几乎完全一致
实现思路:
先将数据绘制到一个离屏 canvas中,然后再通过 drawImage把离屏 canvas 画到主 canvas中
把离屏 canvas当成一个缓存区,把需要重复绘制的数据缓存起来,减少调用 canvas的 API的消耗
let cacheCanvas = document.createElement("canvas");
let cacheCtx = this.cacheCanvas.getContext("2d");
cacheCtx.save();
cacheCtx.lineWidth = 1;
cacheCtx.beginPath();
for(let i = 1; i < 40; i++){
cacheCtx.strokeStyle = this.color[i];
cacheCtx.arc(this.r , this.r , i , 0 , 2 * Math.PI);
}
cacheCtx.stroke();
this.cacheCtx.restore();
// 在绘制每一帧的时候,绘制这个图形
context.drawImage(cacheCtx, x, y);
注意事项:
- 虽然离屏
canvas在绘制之前视野内看不到,但其宽高尽量设置成实际使用的宽高,性能会比较好,否则过多空白区域也会造成性能的损耗;- 在离屏
canvas中缓存图片的时候,不要在用drawImage时缩放图像- 离屏
canvas不再使用时最好手动将引用重置为null,避免因为js和dom之间存在的关联,导致垃圾收机制无法正常工作,占用资源
关闭透明度
const ctx = canvas.getContext('2d', { alpha: false })
创建 canvas上下文的 API存在第二个参数:
canvas.getContext(contextType, contextAttributes)
contextType 是上下文类型,一般值都是 2d,除此之外还有 webgl、webgl2、bitmaprenderer三个值,
只不过后面三个浏览器支持度太低,一般不用
contextAttributes 是上下文属性,用于初始化上下文的一些属性,对于不同的 contextType,
contextAttributes的可取值也不同,对于常用的 2d,contextAttributes可取值有:
alpha
boolean类型值,表明 canvas包含一个 alpha通道. 默认为 true
如果设置为 false, 浏览器将认为 canvas背景总是不透明的, 这样可以加速绘制透明的内容和图片
willReadFrequently
boolean类型值,表明是否有重复读取计划。
经常使用 getImageData(),这将迫使软件使用 2D canvas 并节省内存(而不是硬件加速)。
这个方案适用于存在属性 gfx.canvas.willReadFrequently的环境,并设置为 true
支持度低,目前只有 Gecko内核的浏览器支持,不常用
storage
string 这样表示使用哪种方式存储,默认为:持久(persistent)
支持度低,目前只有 Blink内核的浏览器支持,不常用
尽量利用 CSS
如果有大的静态背景图,直接绘制到 canvas可能并不是一个很好的做法
如果可以,将这个大背景图作为 background-image 放在一个 DOM元素上(例如,一个 div)
然后将这个元素放到 canvas后面,这样就少了一个 canvas的绘制渲染
CSS的 transform性能优于 canvas的 transform,因为前者可以很好地利用 GPU
所以如果可以,transform变幻请使用 CSS来控制
利用裁剪进行局部重绘
由于 Canvas 的绘制方式是画笔式的,在 Canvas 上绘图时每调用一次 API 就会在画布上进行绘制,一旦绘制就成为画布的一部分。绘制图形时并没有对象保存下来,一旦图形需要更新,需要清除整个画布重新绘制 Canvas 。
如果只是简单操作,那么擦除并重绘画布上所有内容是可取的操作
但如果背景比较复杂,那么可以使用剪辑区域技术,通过每帧较少的绘制来获得更好的性能
清除指定区域的颜色,并设置 clip 所有同这个区域相交的图形重新绘制
利用剪辑区域技术来恢复上一帧动画所占背景图的执行步骤:
- 调用
context.save(),保存屏幕canvas的状态 - 通过调用
beginPath来开始一段新的路径 - 在
context对象上调用arc()、rect()等方法来设置路径 - 调用
context.clip()方法,将当前路径设置为屏幕canvas的剪辑区域 - 擦除屏幕
canvas中的图像(实际上只会擦除剪辑区域所在的这一块范围) - 将背景图像绘制到屏幕
canvas上(绘制操作实际上只会影响剪辑区域所在的范围,所以每帧绘制图像像素数更少) - 恢复屏幕
canvas的状态参数,重置剪辑区域
尽量少用性能开销高的api
尽可能避免使用 shadowBlur 和 text rendering, 阴影渲染的性能开销通常比较高
清除画布尽量使用clearRect
一般情况下清除的性能:clearRect > fillRect > 调整canvas大小
Canvas注意事项
Canvas宽高与CSS宽高
<canvas width="600" height="300" style="width: 300px; height: 150px">canvas>
style中的width/height代表canvas元素在界面上所占据的宽/高, 即样式上的CSS宽高。- 属性中的
width/height则代表canvas实际像素的宽高,用来控制Canvas画布绘制区域的宽高。
当使用Canvas API绘制图形时使用的坐标、尺寸大小是基于Canvas宽高属性的,而与CSS样式宽高无关
而CSS宽高则决定canvas图形的视觉显示大小,canvas画布的宽高会等比例缩放成CSS宽高显示
实际使用时尽量避免这种因尺寸不一致比例缩放渲染,导致的图形模糊、锯齿化等问题
Canvas图片跨域
getImageData() 、toDataURL()方法不允许操作非此域名外的图片资源
这是受限于 CORS 策略,会存在跨域问题,虽然可以使用图像,但是绘制到画布上会污染画布,一旦画布被污染,就无法提取画布上的数据
Canvas图片跨域解决方案:
将图片转换为base64格式,图片地址不存在域名,自然不会跨域
注意:图片转换成base64加增加图片文件大小,如果图片比较大,不建议转换base64,否则会增加网页加载时间,影响网站速度,这种方式一般适用于小图图片服务器设置允许跨域,即请求图片返回的响应头中带有Access-Control-Allow-Origin切值为 *(允许所有网站跨域请求)或者当前网站域名(只允许固定域名下跨域请求), 然后前端在加载图片时设置图片跨域属性 img.crossOrigin=“anonymous”
把图片放到当前域名下通过nginx转发解决跨域问题

思考题:100*100的 canvas 占多少内存?
ctx.getImageData(sx, sy, sw, sh);
返回的是一个 ImageData 数组,包含了 sx, sy, sw, sh 表示的矩形的像素数据
而且这个数组是 Uint8 类型的,且四位表示一个像素
Uint8ClampedArray 描述了一个一维数组,包含以 RGBA 顺序的数据,数据使用 0 至 255(包含)的整数表示
Uint8ClampedArray中从0开始,每连续的四个Uint8表示一个像素的信息,分别对应r,g,b,a
我们在定义颜色的时候就是使用 rgba(r,g,b,a) 四个维度来表示,
每个像素值用十六位 00-ff 表示,即每个维度的范围是 0~255,即 2^8 位,即 1 byte, 也就是 Uint8 能表示的范围
所以 100 * 100 canvas 占的内存是 100 * 100 * 4 bytes = 40,000 bytes
看 webkit 源码就知道了,确实是宽 * 高 * 4
https://github.com/WebKit/webkit/blob/main/Source/WebCore/html/HTMLCanvasElement.cpp#L365
在移动端或者高 ppi 屏幕的pc上,1 px 可能占2- 3 个像素,这时候占用的内存是不是也会随之加倍?
不会,取决于canvas上设置的width和height
内存中一个像素就是一个像素,不管显示器上是什么长度
渲染的时候显卡怎么处理,那就是显存里面的事情了,不算内存的占用了
写在最后
我们想在画布上画些基本的简单形状的时候,使用 Canvas 不会觉得有什么繁琐。
但当需要在画布上绘制复杂的图形和动画、添加各种鼠标键盘事件的互动、在特定情况需要改变图片的时候
使用原生 canvas API 将会变得很困难和繁琐,代码量大而且工作效率低
因此本文只作为学习Canvas 参考,真正工作中使用的时候建议还是用一些强大库,比如 Fabric 和 Pixi
切图用的蓝湖就是用 Fabric 实现的
Fabric 官网 :http://fabricjs.com/
Pixi 官网: https://pixijs.com/