Redis系列之9种数据结构
概述
5种基础数据结构:String,List,Hash,Set,Sorted Set
4种高级数据结构:HyperLogLog、Geo、Bitmaps、Streams(5.0+版本)
内部编码
String,List,Hash,Set,Sorted Set只是对外的编码,实际上每种数据结构都有自己底层的内部编码实现,且是多种实现,这样Redis可以在合适的场景选择更合适的内部编码。

注:intset编码,而不是inset编码。如上图,每种数据结构都有2种以上的内部编码实现,有些内部编码可以作为多种外部数据结构的内部实现。Redis这样设计有两个好处:
- 可以偷偷的改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发出更优秀的内部编码,无需改动对外数据结构和命令
- 多种内部编码实现可以在不同场景下发挥各自的优势。例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降。这时候Redis会根据配置选项将列表类型的内部实现转换为linkedlist。
ziplist
Hash的内部编码是ziplist的条件:
- 当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)
- 所有值都小于hash-max-ziplist-value配置(默认64个字节)
Sorted Set的内部编码是ziplist的条件:
- 元素个数小于zset-max-ziplist-entries配置,默认128
- 所有值都小于zset-max-ziplist-value配置,默认64
ziplist充分体现Redis对于存储效率的追求。一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。而ziplist却是将表中每一项存放在前后连续的地址空间内,一个ziplist整体占用一大块内存。它是一个表(list),但其实不是一个链表(linked list)。
ziplist源码ziplist.c:
-- The general layout of the ziplist is as follows:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
- zlbytes:表示这个ziplist占用多少空间,或说占多少字节,包括zlbytes本身占用的4个字节
- zltail:表示到ziplist中最后一个元素的偏移量,有了这个值,pop操作的时间复杂度就是O(1)了,即不需要遍历整个ziplist
- zllen:表示ziplist中有多少个entry,即保存多少个元素。由于这个字段占用16个字节,最大值是
2^16-1,即如果entry的数量超过2^16-1时,需遍历整个ziplist才知道entry的数量; - entry:真正保存的数据,有它自己的编码
- zlend:专门用来表示ziplist尾部的特殊字符,占用8个字节,值固定为255,即8个字节每一位都是1
一个真实的ziplist编码,包含2和5两个元素:
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
| | | | | |
zlbytes zltail entries "2" "5" end
linkedlist
双向链表,对应Java中的LinkedList。
skiplist
跳表
hashtable
对应Java中的HashMap。
intset
Set特殊内部编码,当满足下面的条件时Set的内部编码就是intset而不是hashtable:
- Set集合中必须是64位有符号的十进制整型
- 元素个数不能超过set-max-intset-entries配置,默认512
验证:
> sadd scores 135
(integer) 0
> sadd scores 128
(integer) 1
> object encoding scores
"intset"
是一个有序的整型数组。它在内存分配上与ziplist有些类似,是连续的一整块内存空间,而且对于大整数和小整数采取不同的编码,尽量对内存的使用进行优化。如果执行SISMEMBER命令,即查看某个元素是否在集合中时,事实上使用的是二分查找法,intset源码:
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
// intset编码查找方法源码(人为简化),标准的二分查找法:
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
String
String的3种内部编码分别是:int、embstr、raw。当一个key的value是整型(且value字符串的长度不超过20)时,为了节省内存,Redis将其编码为int类型。Redis默认会缓存10000个整型值(#define OBJ_SHARED_INTEGERS 10000),即如果有10个不同的KEY,其value都是10000以内的值,事实上全部都是共享同一个对象:
set number "7890"
OK
object encoding number
"int"
ebmstr和raw两种内部编码的长度界限:
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
即,embstr和raw编码的长度界限是44。长度超过44以后,就是raw编码类型,不会有任何优化,是多长,就要消耗多少内存:
> set name "a1234567890123456789012345678901234567890123"
OK
> object encoding name
"embstr"
> set name "a12345678901234567890123456789012345678901234"
OK
> object encoding name
"raw"
embstr编码将创建字符串对象所需的空间分配的次数从raw编码的两次降低为一次。因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里面,所以这种编码的字符串对象比起raw编码的字符串对象能更好地利用缓存带来的优势。且释放embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码对象的字符串对象需要调用两次内存释放函数。左边是embstr编码,右边是raw编码:

Hash
Set
List
Sorted Set
Sorted Set的数据结构是一种跳表,即SkipList。
Sorted Set默认情况下只能根据一个因子score进行排序。如何借助Sorted set实现多维(多字段)排序?
将涉及排序的多个维度的列通过一定的方式转换成一个特殊的列,即result = function(x, y, z),即x,y,z是三个排序因子,通过自定义函数计算得到result。
HyperLogLog
简介
Redis 2.8.9 版本添加HyperLogLog,HLL结构,用于基数统计,HLL只会根据输入元素来计算基数,而不会储存输入元素本身,HLL不能像集合那样,返回输入的各个元素。基数估计就是在误差可接受的范围内,快速计算基数。每个HLL键最多只需要花费12 KB内存,就可以计算接近2^64个不同元素的基数。和元素越多耗费内存越大的集合形成鲜明对比。
基数:集合中不重复元素的数量。数据集 {1, 3, 5, 7, 5, 7, 8},则基数集为 {1, 3, 5 ,7, 8}, 则基数为5。
注意,算法给出的基数并不精确,但会控制在合理的范围之内,标准错误小于1%。
API:
PFADD :用于添加一个新元素到统计中
PFCOUNT :用于获取唯一元素个数近似值
PFMERGE destkey sourcekey [sourcekey ...]:将多个HLL合并为一个
适用场景
- 计算用户每天在搜索框中执行的唯一查询,即搜索页面UV统计。而Bitmaps则用于判断某个用户是否访问过搜索页面
- 独立IP统计
与集合的区别
HLL的API类似使用SETS数据结构做相同的任务,SETS结构中,通过SADD命令把每一个观察的元素添加到一个SET集合,用SCARD命令检查SET集合中元素的数量,集合里的元素都是唯一的,已经存在的元素不会被重复添加。
而使用HLL时并不是真正添加项到HLL中(和SETS结构差异很大),因为HLL的数据结构只包含一个不包含实际元素的状态
算法
随机化的算法,以少量内存提供集合中唯一元素数量的近似值。即使输入元素的数量或者体积非常非常大,计算基数所需的空间总是固定的、并且是很小的。HLL被编码成Redis字符串,可以通过调用GET命令序列化一个HLL,也可以通过调用SET命令将其反序列化到redis服务器。
Geo
地理信息,从Redis 3.2版本开始,可以将用户给定的地理位置(经度和纬度)信息储存起来,并对这些信息进行操作。经纬度坐标有具体限制,由EPSG:900913/EPSG:3785/OSGEO:41001规定如下:有效的经度从-180度到180度。有效的纬度从-85.05112878度到85.05112878度。当坐标位置超出上述指定范围时,该命令将会返回一个错误。
Geo本身不是一种数据结构,本质上还是借助于Sorted Set(ZSET),并使用GeoHash技术进行填充。Redis中将经纬度使用52位的整数进行编码,放进zset中,score就是GeoHash的52位整数值。在使用Redis进行Geo查询时,其内部对应的操作其实就是zset(skiplist)的操作。通过zset的score进行排序就可以得到坐标附近的其它元素,通过将score还原成坐标值就可以得到元素的原始坐标。
总之,Redis中处理这些地理位置坐标点的思想:二维平面坐标点 --> 一维整数编码值 --> zset(score为编码值) --> zrangebyrank(获取score相近的元素)、zrangebyscore --> 通过score(整数编码值)反解坐标点 --> 附近点的地理位置坐标。
纬度为42.6,经度为-5.6的点,转化为base32的话要如何转呢?
首先拿纬度来进行说明,纬度的范围为-90到90,将这个范围划为两段,则为[-90,0]、[0,90],然后看给定的纬度在哪个范围,在前面的范围的话,就设当前位为0,后面的话值便为1。继续将确定的范围1分为2,继续以确定值在前段还是后段来确定bit的值。就这样慢慢的缩小范围,一般最多缩小13次即可(经纬度的二进制位相加最多25位,经度13位,纬度12位)。这时的中间值,将跟给定的值最相近:
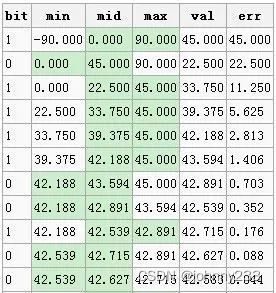
第1行,纬度42.6位于[0, 90]之间,bit=1;第2行,纬度42.6位于[0, 45]之间,所以bit=0;第3行,纬度42.6位于[22.5, 45]之间,所以bit=1,以此类推。取出图中的bit位:1011 1100 1001,同样的方法,将经度(范围-180到180)算出来为 :0111 1100 0000 0。结果:
# 经度
0111 1100 0000 0
# 纬度
1011 1100 1001
得到经纬度的二进制位后,下面需要将两者进行结合:从经度、纬度的循环,每次取其二进制的一位(不足位取0),合并为新的二进制数:01101111 11110000 01000001 0。每5位为一个十进制数,结合base32对应表映射为base32值为:ezs42。完成encode过程。
- GEOADD
GEOADD key longitude latitude member [longitude latitude member …],将指定的地理空间位置(纬度、经度、名称)添加到指定的key中。 - GEOHASH
GEOHASH key member [member …],返回一个或多个位置元素的标准Geohash值,它可以在geohash使用。 - GEOPOS
GEOPOS key member [member …],从key里返回所有给定位置元素的位置(经度和纬度)。 - GEODIST
GEODIST key member1 member2 [unit],返回两个给定位置之间的距离。GEODIST命令在计算距离时假设地球为完美的球形。极端情况下会造成0.5%的误差。单位参数unit可选值:m(默认)、km(公里)、mi(英里)、ft(英尺)。 - GEORADIUS
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count],以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。可用于查询某城市的周边城市群。 - GEORADIUSBYMEMBER
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count],和GEORADIUS命令一样,都可以找出位于指定范围内的元素,但是GEORADIUSBYMEMBER的中心点是由给定的位置元素决定的,而不是像 GEORADIUS那样,使用输入的经度和纬度来决定中心点。指定成员的位置被用作查询的中心。
适用场景
- 实现地理位置相关管理,附近的人、两地理位置间距离计算等功能
Bitmap
这个就是Redis实现的BloomFilter,BloomFilter非常简单,如下图所示,假设已经有3个元素a、b和c,分别通过3个hash算法h1()、h2()和h2()计算然后对一个bit进行赋值,接下来假设需要判断d是否已经存在,那么也需要使用3个hash算法h1()、h2()和h2()对d进行计算,然后得到3个bit的值,恰好这3个bit的值为1,这就能够说明:d可能存在集合中。再判断e,由于h1(e)算出来的bit之前的值是0,那么说明:e一定不存在集合中:
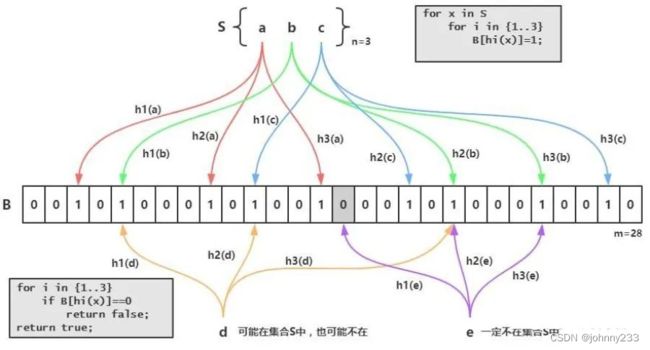
bitmap不是一个真实的数据结构,本质上是String数据结构,只不过操作的粒度变成位bit。String类型最大长度为512MB,所以bitmap最多可以存储2^32个bit。bit操作被分为两组:
- 恒定时间的单个bit操作,如把某个bit设置为0或者1。或者获取某bit的值。
- 对一组bit的操作。如给定范围内bit统计(如人口统计)。
最大优点就是存储信息时可以节省大量的空间。例如在一个系统中,不同的用户被一个增长的用户ID表示。40亿(2^32=4*1024*1024*1024≈40亿)用户只需要512M内存就能记住某种信息,例如用户是否登录过。
API
SETBIT key offset value:offset是位编号,value是这个位的值,只能是0或者1。如果bit地址超过当前string长度,会自动增大stringGETBIT key offset:返回指定位置bit的值。超过范围(寻址地址在目标key的string长度以外的位)的GETBIT总是返回0BITCOUNT key:统计位的值为1的数量BITOP [option] destkey srckey1 ... srckeyN:对一个或多个保存二进制位的字符串 key 求逻辑操作,并将结果保存到 destkey。option取值:AND 、 OR 、 NOT 、 XOR异或,其中OR只有一个srckey。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0;空的 key 也被看作是包含 0 的字符串序列BITPOS key bit [start] [end]:寻址第一个为0或者1的bit的位置(寻址第一个为1的bit的位置:bitpos dupcheck 1; 寻址第一个为0的bit的位置:bitpos dupcheck 0).BITFIELD
适用场景
- 索引
- 数据压缩
- 存储与对象ID关联的节省空间并且高性能的布尔信息.
想知道访问你的网站的用户的最长连续时间。你开始计算从0开始的天数,就是你的网站公开的那天,每次用户访问网站时通过SETBIT命令设置bit为1,可以简单的用当前时间减去初始时间并除以3600*24(结果就是你的网站公开的第几天)当做这个bit的位置。这种方法对于每个用户,都有存储每天的访问信息的一个很小的string字符串。通过BITCOUNT就能轻易统计某个用户连续访问网站的天数。通过BITPOS命令,或者客户端获取并分析这个bitmap,就能计算出最长停留时间。
pub/sub
使用主题订阅者模式,可以实现 1:N 的消息队列(即生产一次消费多次)。Redis 客户端可以订阅任意数量的频道。但在消费者下线的情况下,生产的消息会丢失。
包括命令:
# 订阅频道
> SUBSCRIBE <channel_name>
# 发布消息到频道,双引号
> PUBLISH channel_name "msg"
# 查看频道列表
> PUBSUB CHANNELS
# 取消订阅
> UNSUBSCRIBE <channel_name>
# 订阅多个频道,格式为 PSUBSCRIBE pattern [pattern ...]
> PSUBSCRIBE redis*
实现
redis支持频道,即加入一个频道的用户相当于加入一个群,客户往频道里面发的信息,频道里的所有client都能收到。
与watch_keys实现差不多,redis server中保存一个pubsub_channels的dict,里面的key是频道的名称(显然要唯一),value则是一个链表,保存加入该频道的client。同时每个client都有一个pubsub_channels,保存自己关注的频道。当用户往频道发消息时,首先在server中的pubsub_channels找到该频道,然后遍历client,给他们发消息。订阅,取消订阅频道都是操作pubsub_channels。
redis还支持模式频道。即通过正则匹配频道,如有模式频道p, 1, 则向普通频道p1发送消息时,会匹配p,1,除了往普通频道发消息外,还会往p,1模式频道中的client发消息。这里是用发布命令里面的普通频道来匹配已有的模式频道,而不是在发布命令里制定模式频道,然后匹配redis里面保存的频道。
在redis server里面有个pubsub_patterns的list(因为pubsub_patterns的个数一般较少,不需要使用dict,简单的list即可),存储pubsubPattern结构体,里面是模式和client信息,如果有多个clients监听一个pubsub_patterns的话,在list面会有多个pubsubPattern,保存client和pubsub_patterns的对应关系。在client里面,也有一个pubsub_patterns list,不过里面存储的就是它监听的pubsub_patterns的列表(就是sds),而不是pubsubPattern结构体。
typedef struct pubsubPattern {
redisClient *client; // 监听的client
robj *pattern; // 模式
} pubsubPattern;
当用户往一个频道发送消息的时候,首先会在redis server中的pubsub_channels里面查找该频道,然后往它的客户列表发送消息。然后在redis server里面的pubsub_patterns里面查找匹配的模式,然后往client里面发送消息。此处并没有去除重复的客户,在pubsub_channels可能已经给某一个client发过message,在pubsub_patterns中可能还会给用户再发一次(甚至更多次)。redis认为这是客户程序自己的问题,不处理。
/* Publish a message */
int pubsubPublishMessage(robj *channel, robj *message) {
int receivers = 0;
dictEntry *de;
listNode *ln;
listIter li;
/* Send to clients listening for that channel */
de = dictFind(server.pubsub_channels,channel);
if (de) {
list *list = dictGetVal(de);
listNode *ln;
listIter li;
listRewind(list,&li);
while ((ln = listNext(&li)) != NULL) {
redisClient *c = ln->value;
addReply(c,shared.mbulkhdr[3]);
addReply(c,shared.messagebulk);
addReplyBulk(c,channel);
addReplyBulk(c,message);
receivers++;
}
}
/* Send to clients listening to matching channels */
if (listLength(server.pubsub_patterns)) {
listRewind(server.pubsub_patterns,&li);
channel = getDecodedObject(channel);
while ((ln = listNext(&li)) != NULL) {
pubsubPattern *pat = ln->value;
if (stringmatchlen((char*)pat->pattern->ptr,
sdslen(pat->pattern->ptr),
(char*)channel->ptr,
sdslen(channel->ptr),0)) {
addReply(pat->client,shared.mbulkhdr[4]);
addReply(pat->client,shared.pmessagebulk);
addReplyBulk(pat->client,pat->pattern);
addReplyBulk(pat->client,channel);
addReplyBulk(pat->client,message);
receivers++;
}
}
decrRefCount(channel);
}
return receivers;
}
Streams
Redis5.0引入的全新数据结构,Redis实现的内存版kafka,也有Consumer Groups概念。其底层的数据结构是radix tree:
typedef struct stream {
rax *rax; /* The radix tree holding the stream. */
uint64_t length; /* Number of elements inside this stream. */
streamID last_id; /* Zero if there are yet no items. */
rax *cgroups; /* Consumer groups dictionary: name -> streamCG */
} stream;
Radix Tree(基数树) 事实上就几乎等同是传统的二叉树。仅仅是在寻找方式上,以一个unsigned int类型数为例,利用这个树的每个比特位作为树节点的推断。能够这样说,比方一个数10001010101010110101010,依照Radix 树的插入就是在根节点,假设遇到0,就指向左节点,假设遇到1就指向右节点,在插入过程中构造树节点,在删除过程中删除树节点。一个保存7个单词的Radix Tree:

参考
- memcached-redis
- redis-command
- 菜鸟教程
- Redis9种数据结构及它们的内部编码实现
- GeoDemo
- geohash基本原理
- 菜鸟教程redis-hyperloglog