人脸签到系统 pyQT+数据库+深度学习
一、简介
人脸签到系统是一种基于人脸识别技术的自动签到和认证系统。它利用计算机视觉和深度学习算法来检测、识别和验证个体的面部特征,以确定其身份并记录其出现的时间。这个系统通常用于各种场景,包括企业、学校、会议、活动和公共交通等,以替代传统的签到方式,如签到表或磁卡,提供更高的安全性、准确性和便捷性。
二、效果展示
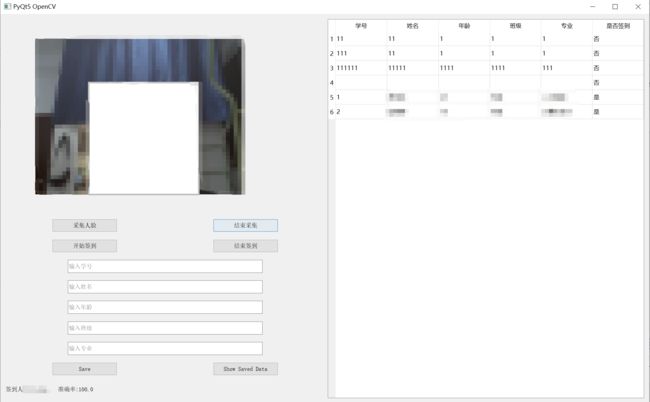
*左上角是采集人脸和签到的界面显示
*左下角输入采集人脸的信息
*右侧实时展示已经存放人脸的各种属性信息
三、实现细节
1、多线程实时现实摄像头内容
采用QT多线程实时对摄像头捕捉到的画面进行显示,当点击结束签到时,程序退出摄像头线程
class SignThread(QThread):
changePixmap = pyqtSignal(QImage)
update_database=pyqtSignal(str)
def run(self):
self.is_running=True
cap = cv2.VideoCapture(0,cv2.CAP_DSHOW)
while True:
ret, frame = cap.read()
if ret and self.is_running:
cls,rate=predict(frame)
if float(rate)>70:
print(rate)
conn = sqlite3.connect("data.db")
cursor = conn.cursor()
# cursor.execute("INSERT OR REPLACE INTO students VALUES (?, ?, ?, ?, ?, ?)",
# (student_id, name, age, classname, major, sign_up))
cursor.execute("UPDATE students SET sign_up=? WHERE name=?", ('是', cls))
conn.commit()
conn.close()
self.update_database.emit("签到人:"+cls+", 准确率:"+rate)
rgbImage = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
h, w, ch = rgbImage.shape
bytesPerLine = ch * w
image = QImage(rgbImage.data, w, h, bytesPerLine, QImage.Format_RGB888)
self.changePixmap.emit(image)
else:
#当按下暂停键,停止键以后,界面变为白色
width = 640
height = 480
# 创建一个全白色的 QImage
white_color = QColor(255, 255, 255) # 白色
image = QImage(width, height, QImage.Format_RGB888)
image.fill(white_color)
self.changePixmap.emit(image)
break
def stop(self):
self.is_running=False2、深度学习
在train.py对录取人脸手动进行训练,训练完成后,打开main.py主界面进行预测识别,开始签到
#数据增强的方式
traintransform = transforms .Compose([
transforms .RandomRotation (20), #随机旋转角度
transforms .ColorJitter(brightness=0.1), #颜色亮度
transforms .Resize([224, 224]), #设置成224×224大小的张量
transforms .ToTensor(), # 将图⽚数据变为tensor格式
# transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225]),
])
valtransform = transforms .Compose([
transforms .Resize([224, 224]),
transforms .ToTensor(), # 将图⽚数据变为tensor格式
])
trainData = dsets.ImageFolder (trainpath, transform =traintransform ) # 读取训练集,标签就是train⽬录下的⽂件夹的名字,图像保存在格⼦标签下的⽂件夹⾥
valData = dsets.ImageFolder (valpath, transform =valtransform ) #读取演正剧
trainLoader = torch.utils.data.DataLoader(dataset=trainData, batch_size=batch_size, shuffle=True) #将数据集分批次 并打乱顺序
valLoader = torch.utils.data.DataLoader(dataset=valData, batch_size=batch_size, shuffle=False) #将测试集分批次并打乱顺序
train_sum=len(trainData) #计算 训练集和测试集的图片总数
test_sum = len(valData)
import numpy as np
import torchvision.models as models
model = models.resnet50(pretrained=True) #pretrained表⽰是否加载已经与训练好的参数
model.fc = torch.nn.Linear(2048, num_of_classes) #将最后的fc层的输出改为标签数量(如3),512取决于原始⽹络fc层的输⼊通道
model = model.to(device) # 如果有GPU,⽽且确认使⽤则保留;如果没有GPU,请删除
criterion = torch.nn.CrossEntropyLoss() # 定义损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 定义优化器
from torch.autograd import Variable
#定义训练的函数
def train(model, optimizer, criterion):
model.train()
total_loss = 0
train_corrects = 0
for i, (image, label) in enumerate (tqdm(trainLoader)):
image = Variable(image.to(device)) # 同理
label = Variable(label.to(device)) # 同理
#print(i,image,label)
optimizer.zero_grad ()
target = model(image)
loss = criterion(target, label)
loss.backward()
optimizer.step()
total_loss += loss.item()
max_value , max_index = torch.max(target, 1)
pred_label = max_index.cpu().numpy()
true_label = label.cpu().numpy()
train_corrects += np.sum(pred_label == true_label)
return total_loss / float(len(trainLoader)), train_corrects / train_sum
testLoader=valLoader
#定义测试的函数
def evaluate(model, criterion):
model.eval()
corrects = eval_loss = 0
with torch.no_grad():
for image, label in tqdm(testLoader):
image = Variable(image.to(device)) # 如果不使⽤GPU,删除.cuda()
label = Variable(label.to(device)) # 同理
pred = model(image)
loss = criterion(pred, label)
eval_loss += loss.item()
max_value, max_index = torch.max(pred, 1)
pred_label = max_index.cpu().numpy()
true_label = label.cpu().numpy()
corrects += np.sum(pred_label == true_label)
return eval_loss / float(len(testLoader)), corrects, corrects / test_sum3、数据库设计
例如下:对新生信息进行插入操作
student_id = self.studentID.text()
name = self.name.text()
age = self.age.text()
classname = self.classname.text()
major = self.major.text()
sign_up='否'
conn = sqlite3.connect("data.db")
cursor = conn.cursor()
cursor.execute("INSERT OR REPLACE INTO students VALUES (?, ?, ?, ?, ?, ?)",
(student_id, name, age, classname, major,sign_up))
conn.commit()
conn.close()
self.label_txt.setText(f"Saved: {name}")
self.show_data()如果这份博客对大家有帮助,希望各位给恒川一个免费的点赞作为鼓励,并评论收藏一下⭐,谢谢大家!!!
制作不易,如果大家有什么疑问或给恒川的意见,欢迎评论区留言。