【深度学习】P1 单层神经网络 - 线性回归(待完成)
单层神经网络 - 线性回归
- 线性回归基本要素
-
- 1. 模型
- 2. 模型训练
- 3. 训练数据
- 4. 损失函数
- 5. 优化算法
- 6. 模型预测
- 线性回归与神经网络
-
- 1. 神经网络图
以一个简单的房屋价格预测为例,介绍解释线性回归这一单层神经网络。无需纠结于什么是单层神经网络,在本文的下半段将引入。首先我们假设影响房价只有两个因素,其一是面积,其二是房龄。
线性回归基本要素
1. 模型
设房屋面积为 x 1 x_1 x1,房龄为 x 2 x_2 x2,售出价格为 y y y。
我们建立基于驶入 x 1 x_1 x1 和 x 2 x_2 x2 来计算输出 y y y 的表达式,即模型(model):
y ^ = w 1 x 1 + w 2 x 2 + b \hat y = w_1x_1+w_2x_2+b y^=w1x1+w2x2+b
其中 w 1 w_1 w1 与 w 2 w_2 w2 称为权重, b b b 称为偏差;其三为线性回归模型的参数。模型的输出 y ^ \hat y y^,是线性回归对真实价格 y y y 的预测或估计。实际上,预测值 y ^ \hat y y^ 与实际价格 y y y 存在误差。
2. 模型训练
所谓模型训练(model training),就是通过数据来寻找模型的参数值,即上述模型中的 w 1 w_1 w1, w 2 w_2 w2 与 b b b,目标是使模型在数据上的误差尽可能小。这个过程,称为模型训练。
3. 训练数据
为训练上述模型,我们需要一些房屋的售卖真实数据。房屋的售价,与其对应的面积和房龄。在机器学习的术语中,这些数据构成的数据集,称为训练数据集,简称训练集(training set)。
| 房屋面积(特征) | 房屋房龄(特征) | 房屋价格(标签) |
|---|---|---|
| 100 | 2 | ¥100,000,000 |
| 120 | 0 | ¥125,000,000 |
每个房屋的售卖数据称为一个样本(sample),真实的售出价格 y y y 则称为标签(label),两个属性(房屋面积、房龄)称为特征(feature),特征用来表征样本的特点。
4. 损失函数
衡量模型优劣的标准为损失最小。而所谓损失,即预测值 y ^ \hat y y^ 与真实值 y y y 之间的误差。一般,我们使用的是误差是平方函数,表达式为:
l ( i ) ( w 1 , w 2 , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 l^{(i)}(w_1,w_2,b)=\frac 1 2 (\hat y^{(i)}-y^{(i)})^2 l(i)(w1,w2,b)=21(y^(i)−y(i))2
其中 l l l 为 l o s s loss loss, l ( i ) l^{(i)} l(i) 可以理解为第 i i i 个样本的损失值。所以所有样本损失值为:
l ( w 1 , w 2 , b ) = 1 n ∑ i = 1 n l ( i ) ( w 1 , w 2 , b ) = 1 n ∑ i = 1 n 1 2 ( w 1 x 1 ( i ) + w 2 x 2 ( i ) + b − y ( i ) ) 2 l(w_1,w_2,b)=\frac 1 n \sum _{i=1} ^n l^{(i)}(w_1,w_2,b)=\frac 1 n \sum ^n _{i=1} \frac 1 2 (w_1x_1^{(i)}+w_2x_2^{(i)}+b-y^{(i)})^2 l(w1,w2,b)=n1i=1∑nl(i)(w1,w2,b)=n1i=1∑n21(w1x1(i)+w2x2(i)+b−y(i))2
5. 优化算法
当模型和损失函数形式较为简单时,误差最小化问题的解可以直接用公式表达出。这类解叫做解析解。
然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值,这类解称为数值解。
在求解数值解的优化算法中,小批量随机梯度下降在深度学习中广泛应用。通过对参数的多次迭代,每次目标都是降低损失函数的值。
在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量 β β β,然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数(往往小于1,一般取值0.01,称为学习率,表示为 η η η )的乘积作为本次迭代的减小量。
w 1 = w 1 − η ∣ β ∣ ∑ i ∈ β δ l ( i ) ( w 1 , w 2 , b ) δ w 1 w_1 = w_1-\frac η {|β|} \sum _{i∈β} \frac {δl^{(i)}(w_1,w_2,b)} {δw_1} w1=w1−∣β∣ηi∈β∑δw1δl(i)(w1,w2,b)
w 2 = w 2 − η ∣ β ∣ ∑ i ∈ β δ l ( i ) ( w 1 , w 2 , b ) δ w 2 w_2 = w_2-\frac η {|β|} \sum _{i∈β} \frac {δl^{(i)}(w_1,w_2,b)} {δw_2} w2=w2−∣β∣ηi∈β∑δw2δl(i)(w1,w2,b)
b = b − η ∣ β ∣ ∑ i ∈ β δ l ( i ) ( w 1 , w 2 , b ) δ b b = b-\frac η {|β|} \sum _{i∈β} \frac {δl^{(i)}(w_1,w_2,b)} {δb} b=b−∣β∣ηi∈β∑δbδl(i)(w1,w2,b)
其中 ∣ β ∣ |β| ∣β∣ 为每个小批量中样本的个数, η η η 为学习率。
6. 模型预测
在完成 5. 优化算法 后,我们将模型参数 w 1 , w 2 , b w_1, w_2, b w1,w2,b 在优化后的值分别记为 w 1 ^ , w 2 ^ , b ^ \hat {w_1}, \hat {w_2}, \hat b w1^,w2^,b^
但是事实上,这只是对最优解的一种近似。就像我们攀登一座山一样,我们希望走的最优路线,但是往往我们只是最优路线的近似。
我们使用优化后的参数值,使用线性回归模型来估算一个房屋的价格,称为模型的预测。也称模型的推断。
线性回归与神经网络
1. 神经网络图
深度学习中,我们使用神经网络图直观地表现模型结构。
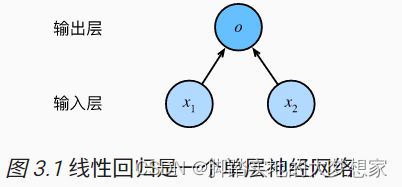
输入分别为 x 1 x_1 x1 与 x 2 x_2 x2