记录一个爬虫过程,从基础爬虫到逆向,再到jsrpc,再到selenium,啥都包括了
这篇文章记录一下我跟一个网站的恩怨纠葛,为了爬这个网站,不断学习新知识,不断尝试,水平提高了不少。总算有点成就了,这里做一个记录,当然还是不完美,期待未来可能技术更精进,能有更好的方法吧。
这个网站是:aHR0cDovL3NkLmNoaW5hdm9sdW50ZWVyLm1jYS5nb3YuY24vc3Vic2l0ZS9zaGFuZG9uZy9ob21l
读者可以自己解码(后面的爬取过程还是有很多提示,不会解码也没关系,可以看后面的一些截图)。
说起这个网站,跟它的缘分应该是从好几年前开始,那时候需要写一篇志愿服务的论文,正好看到这个网站,只不过——那时候网站是静态网页,爬取静态网页的技术我还是有的,可以说没费什么力气,只不过花些时间。目前这个网站的静态版本还是可以在网上看到的。也就是说,这个网站正在经历改版,从静态网页改成动态网页。静态网页的网址是这个。
aHR0cHM6Ly9zZC56aGl5dWFueXVuLmNvbS8=
比较一下两个网站的界面
动态版本

静态版本
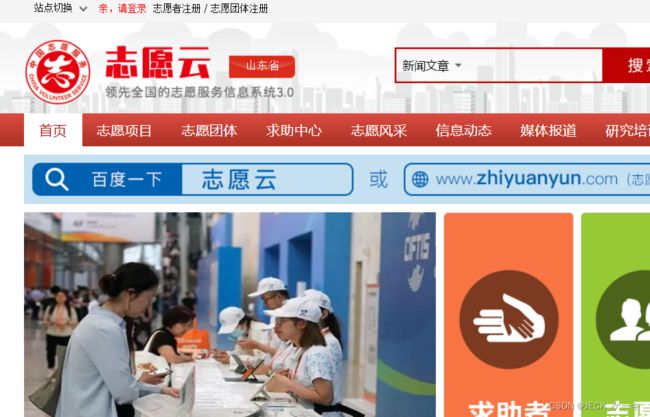
我们不是网站运维人员,当然也不知道他们怎么怎么做出来这两种效果。我估计是同一个sql的数据库吧。只不过两个页面系统,数据应该是做了迁移,或者就是前端的两种渲染方式。静态网页和动态网页所用的数据应该是一样的。
几年前爬取数据的时候,只是用了简单的requests,我的目标是爬取一些志愿者服务的时长,比如像这样的页面。
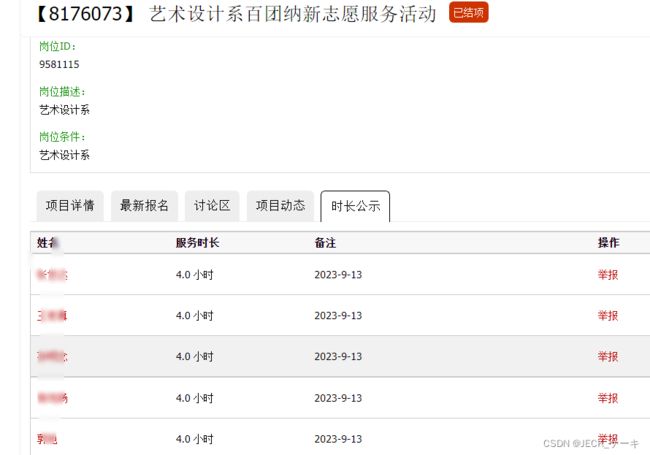
要进入到这个页面,需要每一个项目都点进去,然后再点击时长公示。当然在静态页面的网页系统下,这个时长的统计表格是也页面一起发送的,发包的时候,是一个大包,里面有时长的table,只需要把这个table提取出来就可以。
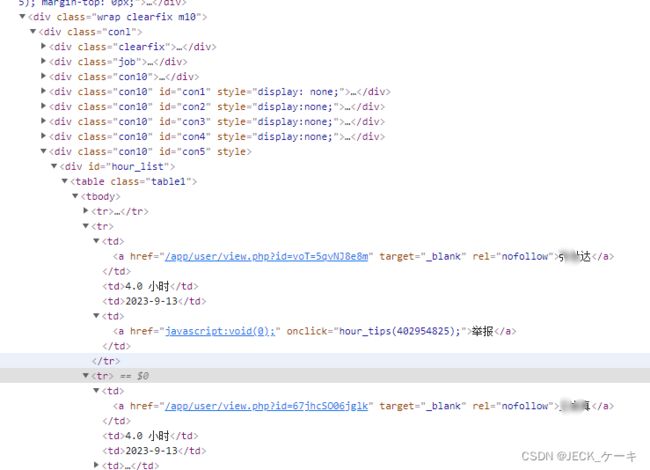
可以直接提取table里面的tr,剩下的问题就是保存数据的问题。
暑假里面没事的时候又想用这个网站的数据,本着避免麻烦的思想,我还是使用传统套路,爬取这个网站的数据。可是后来发现这个网站的数据非常多,爬起来很慢,而且相当的麻烦。主要问题是:
你不知道哪一个志愿者组织是否有项目,也不知道有几个项目,同时也不知道每一个项目是否有记录时长。而且你也不知道每一个项目的时长是几页的。每次都要做很多的判断,很多的try,except。相当麻烦,而且爬取下来数据后还要存。本来我是想着以组织为单位,每一个志愿者组织一个字典。然后把组织的信息,项目的信息都存在这个字典里。但是也很麻烦。
后来下定决心,放弃之前的静态网站,从动态的入手,毕竟动态的网站有一个优势吸引我,就是返回的数据都是json。免得我一步一步的处理。而且暑假里面也学了不少js逆向的知识,这个网站的请求参数是加密的,试试用逆向解密这个网站的加密参数,然后请求,拿到数据。
#想法还是很简单,但是实际做起来,一点也不简单。
接下来开始一步步的踩坑之旅。
首先第一步,我准备爬取这个网站的志愿队伍,
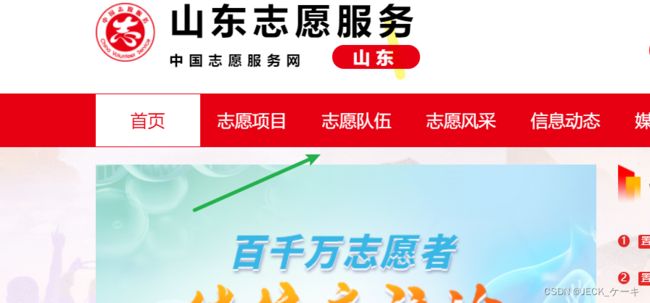
点击进去,可以看到一些条件筛选界面,如果不加筛选,默认是返回的全山东省的志愿队伍。
比如下面这样。

我想这次把爬取数据的范围缩小一些,只爬取烟台市的。
比如这样。

在地区里面,选择烟台市,然后选择各个区。
这一步需要用到js逆向了。
刷新一下网页,发现还需要重新点击选择地区,
再点击两次地区之后,发现这个网站的返回结果里面有几个query。
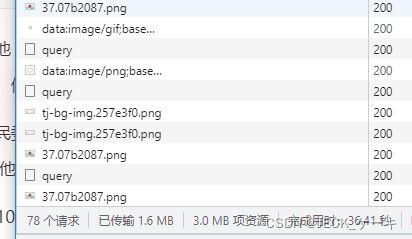
上图是开发者工具里的网络面板,搞爬虫的应该不陌生。
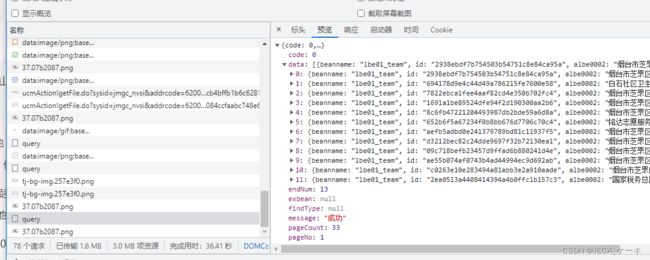
点击这个query,发现返回的都是我们想要的数据。
接下来要做的就是我们看看请求头怎么。
果然,动态的网站虽好,但是加密了就不那么友善了。
可以看到这个query请求是需要携带参数的。

这个bean参数,可以看出一大堆。初步判断,肯定不是简单的md5。所以放弃幻想吧,撸起袖子加油干吧。
我们看看源码吧,找找这个加密过程,看看能不能逆向出来这个bean。
搜索bean,发现只有一个文件,这还是不错。
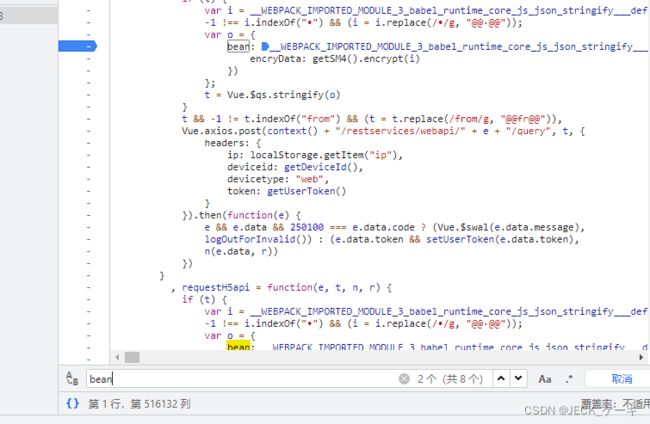
进入这个js,发现bean有8个,也很容易定位的。
还不算难,先尝试在第一bean的地方打上断点。
var o = {
bean: __WEBPACK_IMPORTED_MODULE_3_babel_runtime_core_js_json_stringify___default()({
encryData: getSM4().encrypt(i)
})这段代买很可疑。打上断点,继续跑一下。
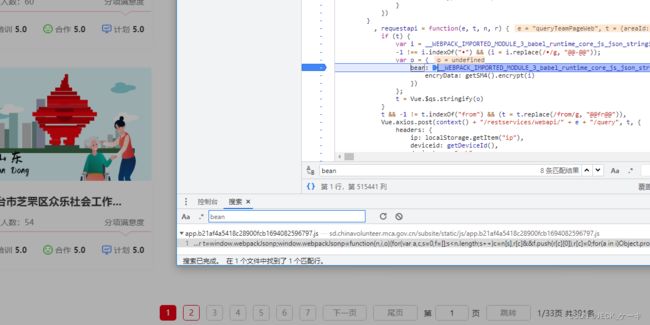
很顺利的断住了。这里可以看出,e是 请求网址的部分内容。t是请求的原始参数,i是处理后的t,不过i还有一些其他内容,
加密过程主要是
encryData: getSM4().encrypt(i)
这个getSM4函数,应该就是加密库。(后来才知道,这个SM4的加密方法应该是国产的一种加密方式,跟标准加密方式是不一样的。)我当时要是简单地认为,这个加密过程不是很复杂,点进去getSM4这个函数,看了一圈,也是没看太明白。主要是因为这个函数的代码是webpack打包的, 我逆向也就刚入门,对于分析这种webpack的代码还是很头大,上一个函数很简单,就是那个,
__WEBPACK_IMPORTED_MODULE_3_babel_runtime_core_js_json_stringify__
我初步判断这个函数就是一个JSON.stringify()函数,但还是困难就在下面的加密函数。
挑战一下,点进去看一下吧。

点进去这个app.b21af4文件。

一看这种形式,好像也并不难,没有混淆,只不过是一般的webpack打包,算是很友好了。我觉得对于大神来说,这个可能就是一般的扣代码过程,奈何我的抠代码技术不是很过关。目前只能分析,这个getsm4函数是一个大的加密库。
其实这个跳转并没有调出原来的文件,还是原来的那个app的js文件。
折叠一下代码,

这个getsm4应该是在一个大的包里面,包结束的位置是 L2RF,再网上找,
最后找到
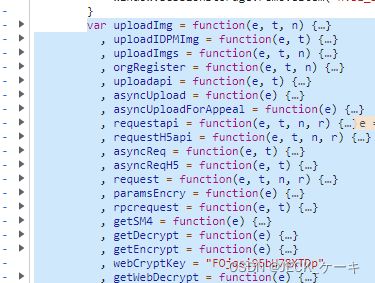
这个var的地方,应该就是包的开始部分吧。

理论上来说,这个函数应该是可以抠出来的。
只不过我想了一个取巧的方法,想直接通过标准加密还原,当时是发现这条路走不通的。后来放弃了。虽然没成功,还是把过程贴出来吧。

因为进去这个getsm4,发现有几个熟悉的东西,key,iv,mode,猜测这应该是一个aes,
我也没犹豫,直接上标准加密,
拿到函数里面的i,不是可以直接出来加密结果了吗?当时是这样想的。

ok,结果出来了。
是不是这个呢,我们把请求发出去,看看下面的query的参数是什么?

结果发现不一样,悲剧了,上面的标准加密的结果,明显和下面的esff2A这个结果不一样。
后来在B站里面也请教了一些大神。经常看他们的视频,给3个大神冲了一个月的电,发现充一个月也才6块,3个就18块,这我还是花得起。静等他们的回音。后来有一个大神回了我信息,他说他也看了,确实不是标准加密,但是他比较忙,没时间帮我抠代码,建议我使用jsrpc或者是selenium。另外两个大神到现在还是没有回音,一方面可能是因为我爬取的这个网站是.gov结尾的,大神也怕惹麻烦,另一方面可能他们也太忙吧,毕竟6块钱不是很多。
JSRPC过程
好在毕竟有热心的。跟那个回复的大神交流了以下,觉得他说的也行,不行咱就试一下jsRPC。一直觉得rpc比较高大上,不敢入门。怕自己水平达不到啊。
从网上找了一些rpc的教程看了,也在B站看了看jsrpc的视频。先看的其中一个大神的,他可能使用的是比较老的框架,看他用的很熟练,奈何我模仿他的操作方式,还是不行。后来无脑在网上乱搜一气,找到了 github上的一个黑脸怪的jsRpc框架。又看了一个视频介绍使用这个框架爬取建筑市场的一个数据,反复操作了几次,基本熟练了。接下来开始移植到这个志愿者网站上。
我的理解是jsrpc就是一个添加网络进程的方式,比如平时我们访问网页,主要走的是http过程,我们访问网页,服务器返回数据,这里面只用到了一般的网络通信。但是jsrpc的方式就是在我们进行一般网络通信的时候,再开一个进程,这个进程是实时的跟踪我们浏览网页的过程,但是我们还可以在这个新开的进程里面做一些其他的事。比如和服务器交换一些参数。类似于这样一个过程,比如我们去看一个演出,我们看就是观众,舞台上演什么我们就看什么,这个过程里面,我们自己和普通观众都是一样的。但是jsrpc就相当于,我看演出的时候,走到前排,塞给演员一个纸条,说,小姐姐,你有没有微信啊,加我一个微信吧,晚上约你吃饭吧,或者是美女,你这个演出其中有一个动作,可以这样做,飞吻可以飞出去的更妩媚一些,等等了。这个过程我们不仅仅看演出,还在另一过程里面跟台上的演员互动。达到我们的目的。
话不多说了,开始。
先去github把黑脸怪的框架下载下来,其中有一个localhost,是一个可执行文件,需要单独运行。
按照他的步骤一步步操作,应该没有啥困难。
1. 线运行localhost
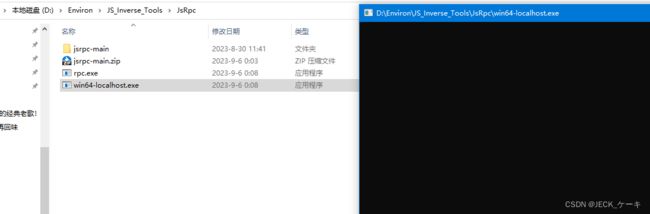
这个界面黑漆漆一片,啥也没有,不用担心,后面会有显示的。
2. 开启一个新的进程,相当于我们现在要给舞台上的演员递小纸条了。
首先你得开启一个通道,比如走到前排,这个开启通道的过程,大神已经给我们写好了,直接复制就可以。
resource里面有一个dev.js

整个文件全部复制,当然你也可以看看,里面的代码基本上是开启通信过程的各种函数,比如发送消息,接收消息。
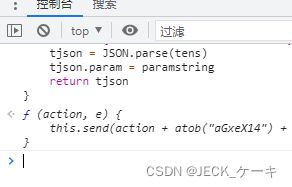
粘贴到控制台,这相当于已经有了一个政策通道了。也就是说,这个作用是什么呢?就是出台一个政策,说,以前舞台上的演员只是表演,下面只是观看,现在有一个新玩法,就是可以观众给演员提意见。这个文件就是相当于告诉观众和演员,有了一种新玩法。
接下来,我们要为自己开启一个单独的通信,我们希望给我们单独开一个小窗私聊。
var demo = new Hlclient("ws://127.0.0.1:12080/ws?group=zzz&name=hlg");这一句相当于开启私聊,我们的私聊群组就叫zzz,我们的代号就是hlg。
然后我们通过这个demo的私聊窗口给服务器,传递信息。就是提出我们的要求。
注意:这里的操作,都是需要再浏览器的非调试状态下开启的。如果还在断点的时候,是不行的。就相当于,你得等人家演员至少表演完一个节目啊,不能毫无征兆的中间就打断,说咱们有了一个新玩法,这多不礼貌。
好了,接下来,我们要往小窗里发送一个东西了。就是我们希望服务器给我们返回他的 getSM4函数的结果。
demo.regAction("hello3", function (resolve,param) {
//这里还是param参数 param里面的key 是先这里写,但到时候传接口就必须对应的上
res=getSM4().encrypt(param["i"])
resolve(res);
})这个hello3就是我们的小窗标题,我们想的是,服务器给我们返回我们的参数i的处理结果,这个处理的过程就是getSM4。
注意:这里我其实也有一个疑问,就是这个小窗私聊的过程是应该什么时候发送。其实我觉得应该是在调试的过程中发送,就是表演过程中。我也是一直这么做的。

我们先开一个小窗,显示rpc连接成功。
然后进入我们的断点,

把我们的regAction函数复制到控制台,这样就算是注入成功了。接下来,就可以等待服务器返回我们想要的结果,结果是保存到res里面,我们在爬虫的过程,使用这个res就可以了。
过掉之前的断点。接下来,就是使用python调用刚才的res了。
直接上代码了。
import requests
import json
# var demo = new Hlclient("ws://127.0.0.1:12080/ws?group=zzz&name=hlg");
# {"areaId":"370602000000000000","pageNum":3,"pageSize":12,"albe0002":"","albe0017":"","albe0005":"","albe0041":"","albe0026":1,"albe0056Start":"","albe0056End":"","albe0046Start":"","albe0046End":""}
'''
demo.regAction("hello3", function (resolve,param) {
//这里还是param参数 param里面的key 是先这里写,但到时候传接口就必须对应的上
res=getSM4().encrypt(param["i"])
resolve(res);
})
'''
dt_list = []
for i in range(1):
i = '{"areaId":"370691000000000000","pageNum":' + str(i+1) + ',"pageSize":12,"albe0002":"","albe0017":"","albe0005":"","albe0041":"","albe0026":1,"albe0056Start":"","albe0056End":"","albe0046Start":"","albe0046End":""}'
url = "http://localhost:12080/go"
data = {
"group": "zzz",
"name": "hlg",
"action": "hello3",
"param": json.dumps({"i":i})
}
print(data["param"]) #dumps后就是长这样的字符串{"user": "\u9ed1\u8138\u602a", "status": "\u597d\u56f0\u554a"}
res=requests.post(url, data=data) #这里换get也是可以的
print(json.loads(res.text)['data'])
result = json.loads(res.text)['data']
# cookies = {
# 'SF_cookie_73': '23217056',
# 'http_waf_cookie': '8cdae343-ec71-4123e94002750b074357af42a14b10c968c6',
# 'SF_cookie_135': '42503913',
# }
cookies = {
'http_waf_cookie': '8cdae343-ec71-4123e94002750b074357af42a14b10c968c6',
'SF_cookie_73': '23906175',
'SF_cookie_135': '42503913',
}
headers = {
'Origin': 'http://sd.chinavolunteer.mca.gov.cn',
'Referer': 'http://sd.chinavolunteer.mca.gov.cn/subsite/shandong/group',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.0.0',
'deviceid': 'cb5c1906-70b1-4a7d-bbf7-ab46b5f50fcc',
'devicetype': 'web',
'ip': '2001:da8:7018:1111:5c7f:9624:d218:ca8f',
'token': 'null',
}
print("\n"*2)
print('{"encryData":' + '"' + result + '"}')
data = {
'bean': '{"encryData":' + '"' + result + '"}'
}
# data = {
# '{"encryData":"'+ ' ' + result + '"}'
# }
# data = {
# 'bean': '{"encryData":"ugYbgxxHxcIFFYezD0TvCbP/B04JNieRjbRvT8Ww99NQGbXi8h5Kn/qrCqzspUE01ujy5ciNOmRRGl5dzjkqIIMv4JDWZQBKDkCwtFEIznuDWb1vJ3H8a3B4GLtl2xXJK7GFYVd3/dc5TmUDfETP/NRwk1oi1wTgFeZbYA2K/WiFQvrX8EaY1da374f6F4MHTEIPU7x8hz8hWFsko2tr1OoQ5KllYQR1+FDcimLqemJxWue01Fkgm4vn1hytfeIrYHWsVfEF/07krVTqpckVbg=="}'
# }
resp = requests.post('http://sd.chinavolunteer.mca.gov.cn/nvsidfapis/NVSIDF/restservices/webapi/queryTeamPageWeb/query', headers=headers,cookies = cookies, data=data, verify=False)
print(resp.json())
dt_list.append(resp.json())
print("============= ************ =================")
print(dt_list)
with open("team_Yantai_gaoxinqu.json", 'w', encoding='utf-8') as f:
f.write(json.dumps(dt_list, ensure_ascii=False))运行一下,可以看到返回的加密参数,也可以看到我们的请求结果。
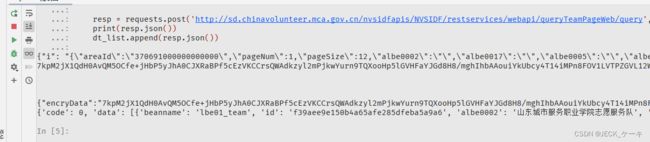
可以看到这个7kpM2开头的就是我们的加密参数,结果也符合我们的要求。
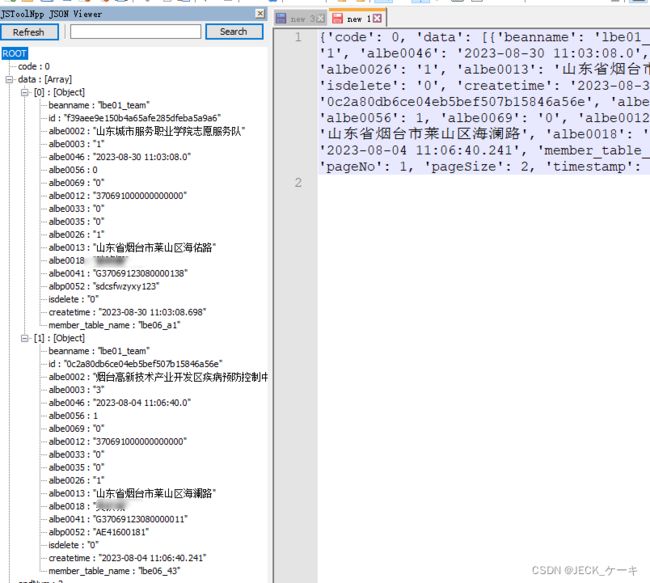
至此,我们使用jsrpc已经解决了我们爬取组织的问题。
文章先写到这里,下一篇再介绍,selenium使用和har吧。因为担心文章会有太多信息,通不过审核,我就先写到这里吧。