第七章集成学习(AdaBoost、Bagging)
集成学习(AdaBoost、Bagging)
文章目录
- 集成学习(AdaBoost、Bagging)
-
- 基于数据集多重抽样的分类器
- 决策树桩(decision stump)
- AdaBoost的实现
- bagging
- 实验部分
基于数据集多重抽样的分类器
AdaBoost是一种集成学习算法,可用于分类。基本思想是通过迭代训练一系列“弱分类器”,再把它们组合成一个强分类器。每次迭代后都会调整样本的权重,让错误样本的权重提高,进而AdaBoost会更加关注这些错误的、难以分类的样本。
前面提到的权重叫alpha,简称α,它的大小取决于错误率 ε \varepsilon ε
ε = 错误分类的样本数 所有样本数 (1) \varepsilon = \frac{错误分类的样本数}{所有样本数} \tag1 ε=所有样本数错误分类的样本数(1)
α = 1 2 l n ( 1 − ε ε ) (2) \alpha = \frac{1}{2}ln(\frac{1-\varepsilon}{\varepsilon})\tag2 α=21ln(ε1−ε)(2)
决策树桩(decision stump)
- 得名于它只用一个特征来做决策,没法处理复杂关系的数据,如果用多个决策树桩也许可以弥补这个缺点。
- 实现过程(已经筛出不在阈值内的坏值):在加权数据集中循环,找出错误率最低的决策树桩。
具体做法为:把minError设为∞,一个for循环遍历dataset的每个特征,第二个for循环尝试各种步长,第三个for循环遍历不同label,创建一个决策树桩后用加权数据集测试它。
三个循环结束后返回一个最佳决策树桩。
AdaBoost的实现
决策树桩算是AdaBoost实现的弱分类器的方法,树桩只有一个分裂结点、俩叶子结点。前文(基于数据集多重抽样的分类器)提到,AdaBoost通过迭代的方式,根据当前样本的权重训练树桩,根据错误率再去调整样本权重,再通过每个树桩的输出结果做加权求和(取决于错误率),最后实现强分类器。
伪代码如下:
对每次迭代:
找到最佳决策树桩
把它加入到树桩数组
计算α和新的权重D
更新估计值,若错误率为0则退出循环
bagging
和adaboost的共性在于,都是通过组合多个弱分类器组成一个强分类器,主要区别在于训练过程、样本权重分配
- 训练过程:bagging是从原始数据集中有放回地抽取样本来生成多个子训练集,然后再独立训练一个弱训练器
- 样本权重:bagging中,每个子训练集的样本权重相等,所以对最终决策的贡献也相同
实验部分
内容:尝试将adaboost应用于第四章的马疝病数据集,预测马能不能活下来
工作文件夹内容
读取数据集,提取马的各种特征以及对应的标签(是否存活)
import numpy as np
import matplotlib.pyplot as plt
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
创建决策树桩,选出错误率最低的一个。stumpClassify()函数会被多次调用,每次调用会根据单个特征去做分类;
buildStump()函数负责找出效果最好的树桩;
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小于阈值,则赋值为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大于阈值,则赋值为-1
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = float('inf') #最小误差初始化为正无穷大
for i in range(n): #遍历所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特征中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #计算步长
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #计算阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#计算分类结果
errArr = np.mat(np.ones((m,1))) #初始化误差矩阵
errArr[predictedVals == labelMat] = 0 #分类正确的,赋值为0
weightedError = D.T * errArr #计算误差
if weightedError < minError: #找到误差最小的分类方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
组成强分类器,迭代40次,weakClassArr指的是最佳的特征组合
# 使用AdaBoost算法提升弱分类器性能
def adaBoostTrainDS(dataArr, classLabels, numIt = 50):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m) #初始化权重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D) #构建单层决策树
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16))) #计算弱学习算法权重alpha,使error不等于0,因为分母不能为0
bestStump['alpha'] = alpha #存储弱学习算法权重
weakClassArr.append(bestStump) #存储单层决策树
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst) #计算e的指数项
D = np.multiply(D, np.exp(expon))
D = D / D.sum() #根据样本权重公式,更新样本权重
#计算AdaBoost误差,当误差为0的时候,退出循环
aggClassEst += alpha * classEst #计算类别估计累计值
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m,1)))#计算误差
errorRate = aggErrors.sum() / m
if errorRate == 0.0: break #误差为0,退出循环
return weakClassArr, aggClassEst
def adaClassify(datToClass,classifierArr):
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
print(len(classifierArr))
for i in range(len(classifierArr)): #遍历所有分类器,进行分类
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
return np.sign(aggClassEst)
if __name__ == '__main__':
dataArr, LabelArr = loadDataSet('horseColicTraining2.txt')
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, LabelArr)
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
print(weakClassArr)
predictions = adaClassify(dataArr, weakClassArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
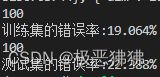
print('训练集的错误率:%.3f%%' % float(errArr[predictions != np.mat(LabelArr).T].sum() / len(dataArr) * 100))
predictions = adaClassify(testArr, weakClassArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('测试集的错误率:%.3f%%' % float(errArr[predictions != np.mat(testLabelArr).T].sum() / len(testArr) * 100))
效果:共迭代了40次,训练了40个弱分类器

尝试迭代100次,发现 虽然训练集的效果变好了一点,但测试集的效果变差了许多,出现一种“过拟合”现象