MySQL数据同步&归档使用工具总结
数据迁移方式&工具总结
- kettel的使用
- dataX的使用
- pt-archiver的使用
kettel的使用
1、中文网:http://www.kettle.org.cn/

2、下载地址

3、使用kettle进行数据迁移
3.1 打开文件夹,运行spoon.bat

3.2 点击文件,新建转换

3.3 新建数据库连接,一个为源数据库,另一个为目的数据库

3.4 建立表输入和表输出(表输入为源数据表,表输出为要写入的表)
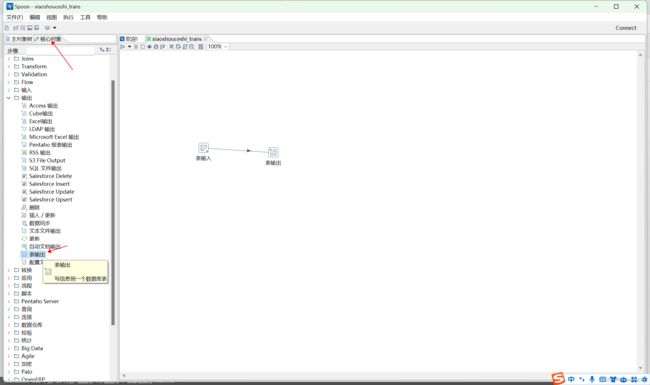
3.5 点击运行转换,即可进行数据迁移

注:运行过程中出现问题可查看下方控制台中的日志。
dataX的使用
1、datax下载
相关文档:https://developer.aliyun.com/article/59373
github地址:https://github.com/alibaba/DataX.git
安装包快速下载:https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202308/datax.tar.gz
# 解压安装包至Linux目录
tar -zxvf datax.tar.gz -C /usr/local/

2、使用dataX进行增量同步
# 进入job目录下
cd job
vim trans.job
# 文件内容如下
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "pass",
"column": [
"*" #表示进行所有字段的同步
],
"where": "order_date = '${order_date}' and com_code in ('103','104','205','176','178','118')", #定义同步的数据条件
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://10.106.17*..2*5:3306/my_db?useUnicode=true&characterEncoding=utf8"
],
"table": [
"my_order" #数据源表
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://10.106.2*5.6*:3306/my_db?useUnicode=true&characterEncoding=utf8",
"table": [
"my_order"
]
}
],
"password": "pass",
"username": "root",
"writeMode": "replace"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
执行一次同步,就会将where条件查询出来的数据同步到目标表中,注意参数的传递${order_date}
python /usr/local/datax/bin/datax.py /usr/local/datax/job/trans.json -p "-Dorder_date=$order_date"
以上为使用dataX进行增量同步的简单描述,如果每日都需要根据日志进行增量同步,可以添加Linux定时任务完成。
vim my_trans.sh
#!/bin/bash
. /etc/profile #定时任务若初始执行不成功,可以添加此行
order_date="$(date +%Y-%m-%d)"
cd /usr/local/datax/log
logfile=datax_$order_date.log
# 同步测试数据
nohup python /usr/local/datax/bin/datax.py /usr/local/datax/job/trans.json -p "-Dorder_date=$order_date" >> $logfile
nohup python /usr/local/datax/bin/datax.py /usr/local/datax/job/trans2.json -p "-Dorder_date=$order_date" >> $logfile
注:Linux定时任务五个*的意思,从左到右分别是[分钟,小时,几号,月份,星期几]

比如,每天8点38分执行一次同步
38 8 * * * /bin/bash /usr/local/datax/job/my_trans.sh
pt-archiver的使用
1、安装下载
下载地址:https://www.percona.com/downloads

# 安装相关
tar xvf percona-toolkit-3.3.1_x86_64.tar.gz
cd percona-toolkit-3.3.1
yum install perl-ExtUtils-MakeMaker perl-DBD-MySQL perl-Digest-MD5
perl Makefile.PL
make
make install
2、进行数据归档
pt-archiver --source h=192.168.253.128,P=3306,u=root,p=VWVqlLvS4kfONYRG,D=my_slaughter_logistics,t=my_city --dest h=192.168.253.129,P=3306,u=test,p=VWVqlLvS4kfONYRG,D=my_slaughter_logistics,t=my_city --where "1=1"
执行完之后会发现,源数据表已被清空,因为使用pt-archiver进行同步的步骤如下:
(1)源库查询记录。
(2)目标库插入记录。
(3)源库删除记录。
(4)目标库 COMMIT。
(5)源库 COMMIT。
当进行大表归档的时候,可以采用批量归档的方式,需要增加以下几个参数:
![]()
–bulk-delete:批量删除。
–limit:每批归档的记录数。
–commit-each:对于每一批记录,只会 COMMIT 一次。
–bulk-insert:归档数据以 LOAD DATA INFILE 的方式导入到归档库中。