Linux 文件系统(VFS、EXT、proc)
主要参考了《深入linux内核》和《Linux内核深度解析》,另外简单浅析了一下相关内容
文章目录
- 通用文件模型及VfS文件结构
-
- 基础知识
-
- 文件系统种类
- 常见的文件系统
- VFS的通用文件模型
-
- inode 文件元信息
-
- struct inode
- 文件分类
- 链接
- VFS结构
-
- 文件表示
- 文件系统和超级块信息
- 目录项 dentry (缓存)
- 小结
- 处理VFS对象及标准操作
-
- 处理VFS对象
-
- 注册文件系统 file_system_type
- 装载和卸载
-
- struct mount
- 超级块管理
- mount系统调用及共享子树
- 相关命令
- 标准函数
-
- read & vfs_read
- write & vfs_write
- 小结
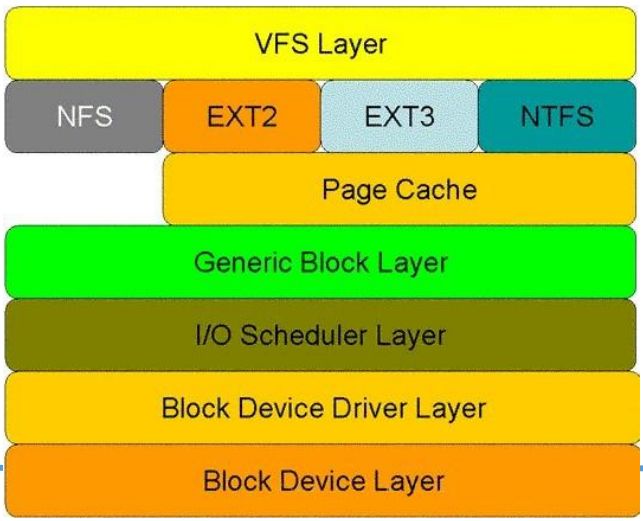
- EXT文件系统
-
- Ext2文件系统
-
- 物理结构
- Ext2数据结构
-
- 超级块
- 组描述符
- inode
- 目录和文件
- Ext2文件系统操作
- Ext4文件系统
-
- Ext3
- Ext4文件系统特性
- 磁盘布局
- 元块组(Meta Block Groups)
- 数据结构
-
- 灵活块组(flex_bg)
- 超级块
- 块组描述符
- inode
- Extent tree
- Ext4_日志JBD2
- proc文件系统
-
- /proc的内容
- proc常见文件
- proc数据结构
- 管理/proc数据项
- 简单的文件系统 libfs
-
- 顺序文件seq_file 系统
-
- 编写顺序文件
- 使用libfs编写FS
通用文件模型及VfS文件结构
基础知识
为支持各种本机文件系统,且在同时允许访问其他操作系统的文件,Linux内核在用户进程(或C标准库)和文件系统实现之间引入了一个抽象层。该抽象层称之为虚拟文件系统(Virtual File System),简称VFS。
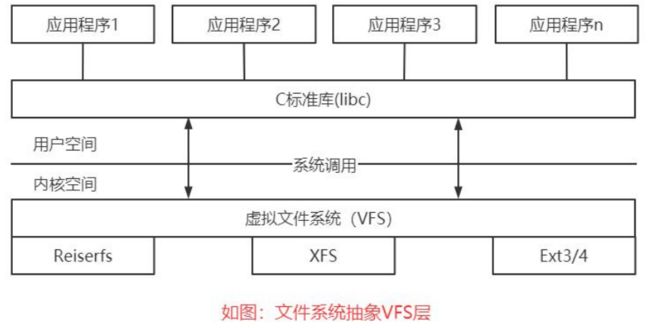
VFS的任务并不简单。一方面,它用来提供一种操作文件、目录及其他对象的统一方法。另一方面,它必须能够与各种方法给出的具体文件系统的实现达成妥协,这些实现在具体细节、总体设计方面都有一些不同之处。但VFS的回报很高,它使得Linux内核更加灵活了。
内核支持40多种文件系统,其来源各种各样:来自MS-DOS的FAT文件系统、UFS(Berkeley UNIX)、用于CD-ROM的iso9660、网络文件系统(如coda和NFS)和虚拟的文件系统(如proc)。
文件系统种类
内存文件系统,文件在内存中,断电以后文件丢失,常用的内存文件系统是tmpfs,用来创建临时文件。
-
基于磁盘的文件系统(Disk-based Filesystem) 块文件系统
是在非易失介质上存储文件的经典方法,用以在多次会话之间保持文件的内容。实际上,大多数文件系统都由此演变而来。比如,一些众所周知的文件系统,包括Ext2/3、Reiserfs、FAT和iso9660。
- 所有这些文件系统都使用面向块的介质,必须解决以下问题:如何将文件内容和结构信息存储在目录层次结构上。
- 在这里我们对与底层块设备通信的方法不感兴趣,内核中对应的驱动程序对此提供了统一的接口。从文件系统的角度来看,底层设备无非是存储块组成的一个列表,文件系统相当于对该列表实施一个适当的组织方案。
-
虚拟文件系统(Virtual Filesystem) 可以抽象设备
在内核中生成,是一种使用户应用程序与用户通信的方法。proc文件系统是这一类的最佳示例。
它不需要在任何种类的硬件设备上分配存储空间。相反,内核建立了一个层次化的文件结构,其中的项包含了与系统特定部分相关的信息。- 举例来说,文件/proc/version在用ls命令查看时,标称长度为0字节。
wolfgang@meitner> ls -l /proc/version
-r–r–r–1 root root 0 May 27 00:36 /proc/version
但如果用cat输出文件内容,内核会产生一个有关系统处理器的信息列表。这列表从内核内存中的数据结构提取而来。
wolfgang@meitner> cat /proc/version
Linux version 2.6.24 (wolfgang@schroedinger) (gcc version 4.2.1 (SUSE Linux))
#1 Tue Jan 29 03:58:03 GMT 2008
- 举例来说,文件/proc/version在用ls命令查看时,标称长度为0字节。
-
网络文件系统(Network Filesystem)
是基于磁盘的文件系统和虚拟文件系统之间的折中。这种文件系统允许访问另一台计算机上的数据,该计算机通过网络连接到本地计算机。在这种情况下,数据实际上存储在一个不同系统的硬件设备上。
- 这意味着内核无需关注文件存取、数据组织和硬件通信的细节,这些由远程计算机的内核处理。对此类文件系统中文件的操作都通过网络连接进行。**在进程向文件写数据时,数据使用特定的协议(由具体的网络文件系统决定)发送到远程计算机。**接下来远程计算机负责存储传输的数据并通知发送者数据已经到达。
常见的文件系统
1、ReiserFS(新型的文件系统)
Reiser4它通过一种与众不同的方式–完全平衡树结构来容纳数据,包括文件数据、文件名、日志支持。它还可以支持少量磁盘和磁盘阵列,并能在上面继续保持很快的搜索速度和很高的效率。
特点:
先进的日志机制。日志机制保证了在每个实际数据修改之前,相应的日志已经写入硬盘,文件与数据的安全性有了很大提高。
高效的磁盘空间利用、独特的搜寻方式、支持海量磁盘、优异的性能、搜寻方式、空间分配和利用情况。
如果应用系统具有很多小文件,同时有大量读/写操作,ReiserFS文件系统绝对是首选。
2、Ext4
Linux系统下的日志式文件系统,Ext3应用广泛更大的文件系统和更大的文件(Ext3文件系统最多只能支持32TB文件系统和2TB文件,实际要比容量少很多,文件系统2TB和16GB文件。Ext4文件系统容量达到1EB,文件容量则达到16TB。)﹔更多的子目录数量;更多的块和i-节点数(Ext3文件系统使用32位空间,Ext4文件系统扩充到64位)﹔多块分配;持久性预分配;延迟分配,盘区结构;新的i节点结构;日志检验功能;在线碎片整理。
3、XFS
高性能的日志文件系统:XFS极具伸缩性、非常健壮数据完全性、可扩展性(最大支持文件大小为9exabytes,最大文件系统尺寸为18exabytes)、传输特性、传输带宽(单个文件系统测试,吞吐量最高达7GB每秒,对意念文件读写操作吞吐量可达4GB每秒)。
内核支持40多种文件系统,MS-DOS的FAT文件系统,UFS(berkeley UNIX)、网络文件系统(coda和NFS)和虚拟文件系统(如proc) 。
VFS的通用文件模型
VFS的方案完全:提供一种结构模型,包含了一个强大文件系统所应具备的所有组件。但该模型只存在于虚拟中,必须使用各种对象和函数指针与每种文件系统适配。所有文件系统的实现都必须提供与VFS定义的结构配合的例程,以弥合两种视图之间的差异。
inode 文件元信息
内核处理文件的关键是inode。每个文件(和目录)都有且只有一个对应的indoe,其中包含元数据(如访问权限、上次修改的日期,等等)和指向文件数据的指针。但inode并不包含一个重要的信息项,即文件名,这看起来似乎有些古怪。(通常,假定文件名称是其主要特征之一,因此应该被归入用于管理文件的对象(inode)中)
inode对文件实现来说是一个主要的概念,但它也用于实现目录。换句话说,目录只是一种特殊的文件,它必须正确地解释。inode的成员可能分为下面两类。
(1) 描述文件状态的元数据。例如,访问权限或上次修改的日期。
(2) 保存实际文件内容的数据段(或指向数据的指针)。就文本文件来说,用于保存文本。
目录(特殊文件)由一个inode表示,其数据段并不包含普通数据,而是根目录下的各个目录项。
这些项可能代表文件或其他目录。每个项由两个成员组成。
- 文件或目录的名称。
- 该项的数据所在inode的编号。
系统中所有inode都有一个特定的编号,用于唯一地标识各个inode。文件名和inode之间的关联即通过该编号建立。
inode区
-
文件数据存储在“块”当中,很显示我们必须要找到一个地方存储此文件“元信息”,比如文件大小、文件作者、文件创建日期等,存储文件元信息的区域就叫做inode(索引节点)。
-
inode也会占用硬盘空间,所以我们在硬盘格式化的时候,操作系统自动将硬盘分为两个区域:一个是数据区,存放文件数据;另一个是inode区,存放inode所包含的信息。每个inode节点的大小,一般是128字节或256字节。
在文件系统中,每个文件对应一个索引节点,索引节点描述两类数据信息。
- 文件的属性,也称为元数据(metadata);
- 文件数据的存储位置。当内核访问存储设备上的一个文件时,会在内核中创建索引节点的一个副本:结构体inode(对应相应的inode区)
为阐明如何用inodes来构造文件系统的目录层次结构,我们来考察内核查找对应于/usr/bin/emacs的inode过程。
查找起始于inode,它表示根目录/,对系统来说必须总是已知的。该目录由一个inode表示,其数据段并不包含普通数据,而是根目录下的各个目录项。这些项可能代表文件或其他目录。每个项由两个成员组成。
(1) 该目录项的数据所在inode的编号。
(2) 文件或目录的名称。
系统中所有inode都有一个特定的编号,用于唯一地标识各个inode。文件名和inode之间的关联即通过该编号建立。
- 查找操作中的第一步是查找根目录usr的inode。这一步会扫描根inode的数据段,直至找到一个名为usr的目录项(如果查找失败,则返回File not found错误)。相关的inode可以根据inode编号定位。
- 重复上述步骤,但这一次在usr对应inode的数据段中查找名为bin的目录项,以便根据其inode编号定位inode。下一步在bin的inode数据段中,将查找名为emacs的目录项。这仍然会返回一个inode编号,这一次的inode表示文件而非目录。图8-2给出了查找过程结束时的情形(所经由的路径由对象之间的指针表示)。
- 最后一个inode的文件内容,与前三个inode不同。前三个inode都表示目录,其文件内容是目录项的一个列表,包括子目录和文件。与emacs文件关联的inode,其数据段存储了文件的内容。
- 尽管上述的分步文件查找过程,其基本思想与VFS的实际实现相同,但有一些细节上的差异。例如,实际的实现使用了缓存来加速查找操作,因为频繁打开文件是一个很慢的过程。此外,VFS层必须与提供实际信息的底层文件系统通信。
struct inode
include\linux\fs.h
super_block,即超级块代表的是一种文件系统类型,比如ext3、ext4都有对应的super_block结构体。一台机器可以有多块硬盘,一个硬盘可以有多个分区,每个分区都有自己的文件系统类型,可以是一样的,也可以不一样。我们来了解下超级块的主要成员变量。
struct inode {
umode_t i_mode; // 文件类型和访问权限
unsigned short i_opflags;
kuid_t i_uid; // 创建文件的用户的标识符
kgid_t i_gid; // 创建文件的用户所属的组标识符
unsigned int i_flags;
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
...
const struct inode_operations *i_op;
struct super_block *i_sb; // 文件所属的文件系统的超级块
struct address_space *i_mapping; // 指向文件所属的地址空间
...
unsigned long i_ino; // 索引编号
...
struct timespec i_atime; // 上一次访问文件时间
struct timespec i_mtime; // 上一次修改文件时间
struct timespec i_ctime; // 上一次修改文件索引的时间
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes; // 最后一个块的长度
unsigned int i_blkbits; // 块长度以2为底的对数
blkcnt_t i_blocks; // 文件块数
...
atomic_t i_count; // 索引节点的引用计数
...
union {
struct pipe_inode_info *i_pipe; // 管道
struct block_device *i_bdev; // 块设备
struct cdev *i_cdev; // 字符设备
char *i_link;
unsigned i_dir_seq;
};
...
文件分类
普通文件、目录、符号链接、字符设备文件、块设备文件、命名管道(FIFO)、套接字(socket)。
字符设备文件、块设备文件、命名管道(FIFO)、套接字(socket)这4种是特殊文件,这些文件只有索引节点,没有数据。字符设备文件和块设备文件用来存储设备号、直接把设备号存储在索引节点中。
要注意,上述的某些对象不一定联系到文件系统中的某个项。例如,管道是通过特殊的系统调用生成,然后由内核在VFS的数据结构中管理,管道并不对应于一个可以用通常的rm、ls等命令访问的真正的文件系统项。
我们特别感兴趣的(尤其是,从第6章的上下文来考虑)是访问块设备和字符设备的设备文件。这些是真正的文件(相比管道和套接字),通常位于/dev目录。其内容是在进行读写操作时由相关的设备驱动程序动态生成的。
链接
在linux系统中有种文件是链接文件,可以为解决文件的共享使用。
链接分为两种:一种是硬链接(Hard Link),另一种是软链接或者也称为符号链接(Symbolic Link)。
【硬连接】相当于给一个文件取了多个名称,多个文件名称对应同一个索引节点,索引节点的成员i_nlink是硬链接计数。
【软链接】这种文件的数据是另一个文件的路径,软链接可对文件或目录创建。
索引节点的成员i_op指向索引节点操作命令inode_operations,i_ fop指向文件操作集合file_operations。
两者间区别: inode_operations用来操作目录和文件属性,file_operations用业访问文件的数据。
-
硬链接:通过索引节点来进行链接,在Linux文件系统中,保存在磁盘分区中的文件不管理是什么类型都会给它分配一个编号,这个编号被称为索引节点编号(inode index)。
硬链接作用之一是允许一个文件拥有多个有效路径名称这样用户就可以建立硬链接到重要的文件,以防止”误删除“源数据。
-
符号连接可以认为是“方向指针”(至少从用户程序来看是这样),表示某个文件存在于特定的位置。当然我们都知道,实际的文件在其他地方。有时使用软链接来表示此类链接。这是因为链接和链接目标彼此并未紧密耦合。链接可以认为是一个目录项,其中除了指向文件名的指针,并不存在其他数据。目标文件删除时,符号链接仍然继续保持。
对每个符号链接都使用了一个独立的inode。相应inode的数据段包含一个字符串,给出了链接目标的路径。
软链接作用:
- 便于文件的管理,比如把一个复杂路径下的文件链接到一个简单路径下方便用户访问;
- 节省空间解决空间不足总是,某个文件文件系统空间已用完,但是瑞必须在该文件系统下创建一个新的目录并存储
大量的文件,可以把另一个剩余空间比较多的文件系统中的目录链接到该文件系统当中。 - 删除软链接并不影响被指向的文件,但是被指向的原文件被删除,则相关的软连接就成死链接。
-
软链接特点:
- 软链接是存放另一个文件的路径的形式存在;
- 软链接可以跨文件系统,硬链接不可以;
- 软链接可以对一个不存在的文件名进行链接,硬链接必须要有源文件;
- 软链接可以对目录进行链接;
-
硬链接特点:
- 硬链接以文件副本形式存在,但不占用实际空间;
- 不允许给目录创建硬链接;
- 硬链接只有在同一个文件系统中才能创建;
- 删除其中一个硬链接并不影响其他有相同inode号的文件。
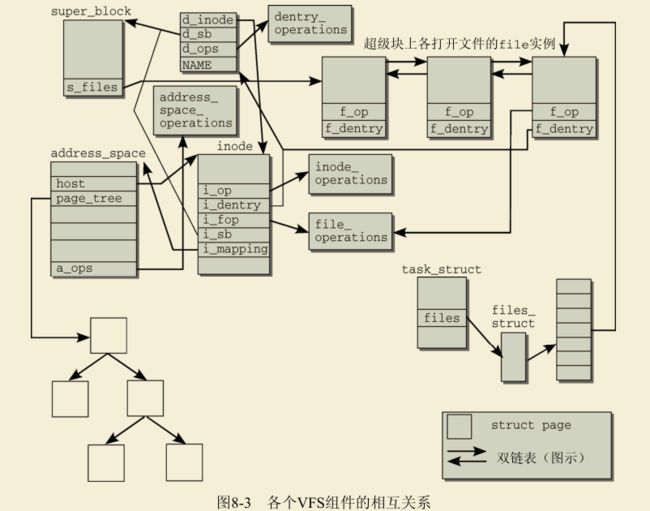
VFS结构
在VFS接口实现当中,涉及大量的数据结构。VFS结构由两个部分组成:文件和文件系统,这些都需要管理和抽象。
如下图linux 2.x版本的VFS结构
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
...
文件表示
inode是Linux内核选择用于表示文件内容和相关元数据的方法。在抽象对底层文件系统的访问时,并未使用固定的函数,而是使用了函数指针。这函数指针保存在两个结构中,包括了所有相关的函数。
- (1) inode操作:创建链接、文件重命名、在目录中生成新文件、删除文件。
- (2) 文件操作:作用于文件的数据内容。它们包含一些显然的操作(如读和写),还包括如设置文件位置指针和创建内存映射之类的操作。
因为打开的文件总是分配到系统中一个特定的进程,内核必须在数据结构中存储文件和进程之间的关联。task_struct包含一个成员,其中保存了所有打开的文件(通过一种迂回方式)。该成员是一个数组,访问时使用文件描述符作为索引。各个数组项包含的对象不仅关联到对应文件的inode,还包含一个指针,指向用于加速查找操作的目录项缓存的一个成员。 各个文件系统的实现也能在VFS inode中存储自身的数据(不通过VFS层操作)。
文件系统和超级块信息
VFS支持的文件系统类型通过一种特殊的内核对象连接进来,该对象提供了一种读取超级块的方法。除了文件系统的关键信息(块长度、最大文件长度,等等)之外,超级块还包含了读、写、操作inode的函数指针。
内核还建立了一个链表,包含所有活动文件系统的超级块实例。之所以使用活动( active)这个术语替代已装载( mounted),是因为在某些环境中,有可能使用一个超级块对应几个装载点。
尽管每个文件系统在file_system_type中只出现一次,但所有超级块实例的链表中,可能有几个同一文件系统类型的超级块实例,因为在各个块设备/分区上可能存储了同一类型的几个文件系统。例如,大多数系统都有root和home分区,二者可能在不同的分区上,
但通常使用同样类型的文件系统。在file_system_type中,同一文件系统类型只需定义一次,但这两个装载点的超级块不同,虽然都使用了同样的文件系统。超级块结构的一个重要成员是一个列表,包括相关文件系统中所有修改过的inode(内核相当不敬地称之为脏inode)。根据该列表很容易标识已经修改过的文件和目录,以便将其写回到存储介质。回写必须经过协调,保证在一定程度上最小化开销,因为这是一个非常费时的操作(硬盘、软盘驱动器及其他介质与系统其余组件相比,速度很慢)。另一方面,如果写回修改数据的间隔太长也可能有严重后果,因为系统崩溃(或者,就Linux的情形而言,更可能的是停电)会导致不能恢复的数据丢失。内核会周期性扫描脏块的列表,并将修改传输到底层硬件。
inode 操作
内核提供了大量函数,对inode进行操作。为此定义了一个函数指针的集合,以抽象这些操作,因为实际数据是通过具体文件系统的实现操作的。调用接口总是保持不变,但实际工作是由特定于实现的函数完成的。
inode结构有两个指针(i_op和i_fop),指向实现了上述抽象的数组。一个数组与特定于inode的操作有关,另一个数组则提供了文件操作。inode结构和file结构都包括了一个指向file_operations结构的指针。在这里,知道以下这些就足够了:file_operations用于操作文件中包含的数据,而inode_operations负责管理结构性的操作(例如删除一个文件)和文件相关的元数据(例如,属性)。
目录项 dentry (缓存)
inode仅仅只是保存了文件对象的属性信息,包括:权限、属组、数据块的位置、时间戳等信息。但是并没有包含文件名,文件在文件系统的目录树中所处的位置信息。那么内核又是怎么管理文件系统的目录树呢?答案是目录项。
目录项在内核中起到了连接不同的文件对象inode的作用,进而起到了维护文件系统目录树的作用。dentry是一个纯粹的内存结构,由文件系统在提供文件访问的过程中在内存中直接建立(并没有实际对应的磁盘上的描述)。
include\linux\dcache.h
由于块设备速度较慢,可能需要很长时间才能找到与一个文件名关联的inode。即使设备数据已经在页缓存。
Linux使用目录项缓存(简称dentry缓存)来快速访问此前的查找操作的结果。
该缓存围绕着struct dentry建立,此前已经提到几次这个结构。在VFS连同文件系统实现读取的一个目录项(目录或文件)的数据之后,则创建一个dentry实例,以缓存找到的数据。
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; // 目录项缓存标识,protected by d_lock
seqcount_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; // 用于查找的散列表
struct dentry *d_parent; // 父目录名称
struct qstr d_name; // 目录项名称
struct inode *d_inode; // 文件名所属的inode,如果为NULL,则表示不存在的文件名
unsigned char d_iname[DNAME_INLINE_LEN]; // 存放短的文件名称
/* Ref lookup also touches following */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
...
};
缓存的组织
dentry结构不仅使得易于处理文件系统,对提高系统性能也很关键。dentry对象在内存中的组织,涉及下面两个部分。
(1) 一个散列表( dentry_hashtable)包含了所有的dentry对象。
(2) 一个LRU(最近最少使用, least recently used)链表,其中不再使用的对象将授予一个最后宽限期,宽限期过后才从内存移除。
struct dentry_operations {
// 网络文件系统
int (*d_revalidate)(struct dentry *, unsigned int);
int (*d_weak_revalidate)(struct dentry *, unsigned int);
// 计算hash值(放置到dentry散列表中)
int (*d_hash)(const struct dentry *, struct qstr *);
// 比较两个dentry对象的文件名称
int (*d_compare)(const struct dentry *,
unsigned int, const char *, const struct qstr *);
int (*d_delete)(const struct dentry *);
int (*d_init)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_prune)(struct dentry *);
// 从一个不再使用的dentry对象中释放inode
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
struct vfsmount *(*d_automount)(struct path *);
int (*d_manage)(const struct path *, bool);
struct dentry *(*d_real)(struct dentry *, const struct inode *,
unsigned int);
} ____cacheline_aligned;
小结
超级块对象super block,对应已装载的文件系统
- 索引节点对象inode,对应介质上的一个文件;
- 目录项对象dentry,对应一个目录项
- 文件对象file,对应由进程所打开的文件
所有定义在linux/fs.h。
- 超级块对象:用来描述整个文件系统的信息,每个具体的文件系统都有自己的超级块,所有超级块对象以双向链循环链表的形成连接,超级块对象在文件系统装载时创建,保存在内存中,在文件系统超载时它会自动删除。
- 索引节点对象:索引节点对象包含内核在操作文件或目录时需要的全部信息。
- 目录项对象:目录项对象没有对应的磁盘数据结构(三种状态:被使用、未使用、负状态)。
- 文件对象∶文件对象表示进程已打开的文件。由open()系统调用创建,由close()系统调用删除,多个进程同时打开和操作同—对象,存在多个对应的文件对象。
处理VFS对象及标准操作
处理VFS对象
文件系统操作
首先,我们从标准库用来与内核通信的系统调用来研究。尽管文件操作对所有应用程序来说都属于标准功能,但对文件系统的操作只限于少量几个系统程序,即用于装载和卸载文件系统的mount和umount程序。
注册文件系统 file_system_type
文件系统在内核中是以模块化形式实现的。这意味着可以将文件系统编译到内核中,而内核自身在编译时也完全可以限制不支持某个特定的文件系统。事实上大约有50个文件系统,把这些代码都编译到内核中几乎没有意义。 因此,每个文件系统在使用以前必须注册到内核,这样内核能够了解可用的文件系统,并按需调用装载功能。
在文件系统注册到内核时,文件系统是编译为模块,或者持久编译到内核中。如果不考虑注册的时间(持久编译到内核的文件系统在启动时注册,模块化文件系统在相关模块载入内核时注册),在两种情况下所用的技术方法是同样的。
struct file_system_type {
const char *name; // 文件系统名称
int fs_flags; // fs_flags是使用的标志,例如标明只读装载、禁止setuid/setgid操作或进行其他的微调。
#define FS_REQUIRES_DEV 1 // 文件系统必须在物理设备上
#define FS_BINARY_MOUNTDATA 2 // 文件系统需要使用二进制数据结构 mount data*,常见的nfs使用这种mount data
#define FS_HAS_SUBTYPE 4 // 系统含有子类型,最常见的就是FUSE,FUSE本不是真正的文件系统,
// 所以要通过文件系统类型区别,通过FUSE实现不同文件系统
#define FS_USERNS_MOUNT 8 // 每次挂载后都是不同的user namespace,比如deytpes
#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */
// 用户调用sys mount挂载某一个文件系统时,最终会调到该回调函数
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *); // 删除内存中的superblock,在卸载文件系统时使用
struct module *owner; // owner是一个指向实现这个文件系统的模块的指针,仅当文件系统以模块形式加载时,
// owner才包含有意义的值(NULL指针表示文件系统已经持久编译到内核中)。
struct file_system_type * next; // 指向下一个文件系统类型
struct hlist_head fs_supers; // //此文件系统类型的文件系统超级块结构串都在这个表头
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key s_writers_key[SB_FREEZE_LEVELS];
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
};
fs\filesystems.c中的register_filesystem用来向内核注册文件系统。该函数的结构非常简单。所有文件系统都保存在一个(单)链表中,各个文件系统的名称存储为字符串。在新的文件系统注册到内核时,将逐元素扫描该链表,直至到达链表尾部或找到所需的文件系统。在后一种情况下,会返回一个适当的错误信息(一个文件系统不能注册两次);否则,将描述新文件系统的对象置于链表末尾,这样就完成了向内核的注册。
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
BUG_ON(strchr(fs->name, '.'));
if (fs->next)
return -EBUSY;
write_lock(&file_systems_lock);
p = find_filesystem(fs->name, strlen(fs->name));
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
装载和卸载
**目录树的装载和卸载比仅仅注册文件系统复杂得多,因为后者只需要向一个链表添加对象,而前者需要对内核的内部数据结构执行很多操作,所以要复杂得多。**文件系统的装载由mount系统调用发起。我们需要阐明在现存目录树中装载新的文件系统必须执行的任务。还需要用于描述装载点的数据结构。
-
UNIX采用了一种单一的文件系统层次结构,新的文件系统可以集成到其中,如下图所示
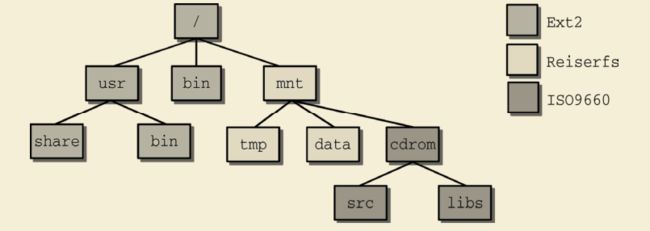
图中给出了3种不同的文件系统。全局的根目录/使用了Ext2文件系统,/mnt为Reiserfs文件系统,而/mnt/cdrom使用了ISO9660格式,这通常用于光盘。使用mount可查询目录树中各种文件系统的装载情况。
/mnt和/mnt/cdrom目录被称为装载点,因为这是附接(装载)文件系统的位置。每个装载的文件系统都有一个本地根目录,其中包含了系统目录(就光盘来说是source和libs目录)。在将文件系统装载到一个目录时,装载点的内容被替换为即将装载的文件系统的相对根目录的内容。前一个目录数据消失,直至新文件系统卸载才重新出现(当然,在此期间旧文件系统的数据不会被改变,但是无访问)。
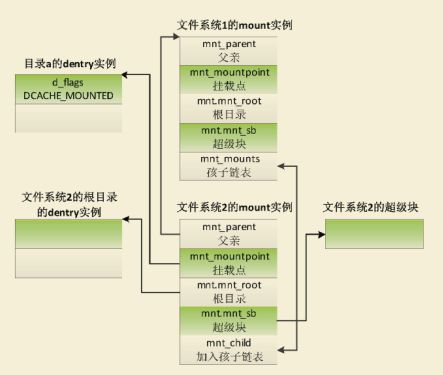
把文件系统2挂载到目录“/a”下,目录a属于文件系统1,挂载描述符的数据结构如下图
在我们的例子中,装载是可以嵌套的。光盘装载在/mnt/cdrom目录中。这意味着ISO9660文件系统的相对根目录装载在一个Reiser文件系统内部,因而与用作全局根目录的Ext2文件系统是完全分离的。
在内核其他部分常见的父子关系,也可以用于更好地描述两个文件系统之间的关系。Ext2是/mnt中的Reiserfs的父文件系统。/mnt/cdrom中包含的是/mnt的子文件系统,与根文件系统Ext2无关(至少从这个角度看是这样)
使用mount可查询目录树中各种文件系统的装载情况如下:
struct mount
Linux操作系统的一个文件系统,只有挂载到内存中目录树的一个目录下,进程才能够访问这个文件系统。每次挂载文件系统,虚拟文件系统就会创建一个挂载描述符(mount结构体)。挂载描述符用来描述文件系统的一个挂载实例,同一个存储设备上的文件系统可以多次挂载,每次挂载到不同的目录下。
mount结构描述一个独立文件系统的挂载信息,每个不同挂载点对应一个独立的mount结构,属于同一文件系统的所有目录和文件隶属于同一个mount,该mount结构对应于该文件系统顶层目录,即挂载目录。
- 文件系统之间的父子关系由上述我们所讲两个成员实现链表表示,mnt_mounts表头是子文件系统链表的起点,而mnt_child字段则用作该链表的链表元素。
- 系统当中的每个mount实例,通过两种途径标识,一个命名空间的所有装载的文件系统都保存在namespace->list链表中。使用mount的mnt_list成员作为链表元素。
fs\mount.h
struct mount {
struct hlist_node mnt_hash;
struct mount *mnt_parent; // 装载点所在的父文件系统
struct dentry *mnt_mountpoint; // 装载点在父文件系统中的dentry
struct vfsmount mnt;
union {
struct rcu_head mnt_rcu;
struct llist_node mnt_llist;
};
#ifdef CONFIG_SMP
struct mnt_pcp __percpu *mnt_pcp;
#else
int mnt_count;
int mnt_writers;
#endif
struct list_head mnt_mounts; // 子系统链表
struct list_head mnt_child; // 链表元素,用于父文件系统中的mnt_mounts链表
struct list_head mnt_instance; /* mount instance on sb->s_mounts */
const char *mnt_devname; // 设备名称,例如/dev/dsk/hda1
struct list_head mnt_list;
struct list_head mnt_expire; // 链表元素,用于特定文件系统中的到期链表中
struct list_head mnt_share; // 链表元素,用于共享装载的循环链表
struct list_head mnt_slave_list; // 从属装载的链表
struct list_head mnt_slave; // 链表元素,用于从属装载链表
struct mount *mnt_master; // 指向主装载,从属装载位于master->mnt_slavve_list链表上
struct mnt_namespace *mnt_ns; // 所属的命名空间
struct mountpoint *mnt_mp; /* where is it mounted */
struct hlist_node mnt_mp_list; /* list mounts with the same mountpoint */
struct list_head mnt_umounting; /* list entry for umount propagation */
#ifdef CONFIG_FSNOTIFY
struct fsnotify_mark_connector __rcu *mnt_fsnotify_marks;
__u32 mnt_fsnotify_mask;
#endif
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
int mnt_expiry_mark; /* true if marked for expiry */
struct hlist_head mnt_pins;
struct fs_pin mnt_umount;
struct dentry *mnt_ex_mountpoint;
};
超级块管理
在装载新的文件系统时, vfsmount并不是唯一需要在内存中创建的结构。装载操作开始于超级块的读取。
因每种文件系统的超级块的格式不同,所每种文件系统需要向虚拟文件系统注册文件系统类型file_system_type,并且实现mount方法用来读取和解析超级块。
file_system_type对象当中保存的read _super函数指针返回一个类型为super_block的对象。用于在内存中表示一个超级块,它是借助于底层实现产生的。
struct super_block {
struct list_head s_list; // 将该成员置于起始位置
dev_t s_dev; // 搜索索引,不是kdev_t
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; // 最大文件长度
struct file_system_type *s_type;
// 指向一个包含函数指针的结构,提供一个接口,用于处理超级块相碰操作,具体是由底层文件系统的代码实现
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
...
void *s_fs_info; // 文件系统私有信息
...
/* s_inode_list_lock protects s_inodes */
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes; // 所有的inode链表
spinlock_t s_inode_wblist_lock;
struct list_head s_inodes_wb; /* writeback inodes */
};
struct super_operations
该结构中的操作并不改变inode的内容,但会控制从底层文件系统实现获取和返回inode数据的方式。该结构还包括一些方法,用于执行其他操作,如重新装载文件系统。由于这些函数指针的名称清楚地表示了函数的作用,下面只是简单讲述一下
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
// 将inode从内存和底层存储介质删除
void (*destroy_inode)(struct inode *);
// 将inode结构标记为”脏“的
void (*dirty_inode) (struct inode *, int flags);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
void (*put_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_super) (struct super_block *);
int (*freeze_fs) (struct super_block *);
int (*thaw_super) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct dentry *);
int (*show_devname)(struct seq_file *, struct dentry *);
int (*show_path)(struct seq_file *, struct dentry *);
int (*show_stats)(struct seq_file *, struct dentry *);
#ifdef CONFIG_QUOTA
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
struct dquot **(*get_dquots)(struct inode *);
#endif
int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
long (*nr_cached_objects)(struct super_block *,
struct shrink_control *);
long (*free_cached_objects)(struct super_block *,
struct shrink_control *);
};
在讨论文件系统实现时,读者会看到,从存储介质删除inode时,会移除指向相关数据块的指针,但文件数据不受影响(在未来的某个无法确定的时间,数据可能被覆盖)。只有能接触到计算机并了解文件系统结构,才足以恢复删除的文件(这对于敏感数据来说可能是一个问题)
mount系统调用及共享子树
mount系统调用的入口点是sys_mount函数,在fs\namespace.c里
在装载选项(类型、设备和选项)已经由sys_mount从用户空间复制到内核空间之后,内核将控制转移给do_mount,该函数将分析传递的信息,并设置相应的标志。其中还将使用下文讨论的path_lookup函数,找到装载点的dentry项。
do_mount充当一个多路分解器,将仍然需要完成的工作委派给与装载类型相关的各个函数。

(1)调用函数user_path,根据目录名称找到挂载描述符和dentry实例。
(2)调用函数get_fs_type,根据文件系统类型的名称查找
file_system_type实例。
(3)调用函数alloc_vfsmnt,分配挂载描述符。
(4)调用文件系统类型的挂载方法,读取并且解析超级块。
(5)把挂载描述符添加到超级块的挂载实例链表中。
(6)把挂载描述符加入散列表。
(7)把挂载描述符加入父亲的孩子链表
共享子树
共享子树最核心的特征是允许挂载和卸载事件以一种自动的,可控的方式在不同的namespaces间传递(propagation)。这就意味着,在一个命名空间中挂载光盘的同时也会触发对于其他namespace对同一张光盘的挂载。 在共享子树中,每个挂载点都存在一个名为传递类型(propagationtype)的标记,该标记决定了一个namespace中创建或者删除的挂载点是否会传递到其他的namespaces。
共享子树有4种传输类型:
- MS_SHARED:该挂载点和它的共享挂载和卸载事件。
- MS_PRIVATE:和共享挂载相反,标记为private的事件不会传递到任何的对等组,挂载操作默认使用此标志
- MS_SLAVE:这个传递类型介于shared和slave之间,一个slave mount拥有一个master (一个共享的对等组) , slave mount不能将事件传递给master mount
- MS_UNBINDABLE:该挂载点是不可绑定的
相关命令
管理员权限可以执行命令:cat /proc/filesystems来查看已注册的文件系统类型。
查询第一列说明文件系统是否需要挂载一个块设备上,nodev表示后面的文件系统不需要挂接在块设备上。第二列是内核支持的文件系统(比如: ext2/3/4等)。
nodev sysfs
nodev rootfs
nodev ramfs
nodev bdev
nodev proc
nodev cpuset
nodev cgroup
nodev cgroup2
nodev tmpfs
nodev devtmpfs
nodev configfs
nodev debugfs
nodev tracefs
nodev securityfs
nodev sockfs
nodev dax
nodev bpf
nodev pipefs
nodev hugetlbfs
nodev devpts
ext3
ext2
ext4
挂载命令
虚拟文件系统在内存中把目录组织为一棵树,一个文件系统,人有挂载到内存中目录树的一个目录,进程才能访问这个文件系统。
管理员权限可以执行命令:mount -t fstype [-0 options] device dir。把存储设备device上类型为fstype的文件系统挂载到目录dir下。
glibc库封装挂载文件系统的函数 mount ,两个卸载文件系统的的函数 oldumount / umount2 。
绑定挂载
绑定挂载(bind mount)用来把目录树的一棵子树挂载到其它地方。
执行绑定挂载命令:mount --bind olddir newdir。 把目录olddir为根的子树挂载到目录newold,以后从目录newdir和目录olddir可以看到相同的内容。
标准函数
VFS层提供的有用资源是用于读写数据的标准函数。这些操作对所有文件系统来说,在一定程度上都是相同的。如果数据所在的块是已知的,则首先查询页缓存。如果数据并未保存在其中,则向对应的块设备发出读请求。如果对每个文件系统都需要实现这些操作,则会导致代码大量复制,我们应该不惜代价防止这种情况发生。
VFS(虚拟文件系统,Virtual File System)是物理文件系统与服务之间的接口层,向下对文件系统提供标准接口,方便其他文件系统移植,向上对应用层提供标准文件操作接口,使open()、read()、write()等系统调用可以跨越各种文件系统和不同介质执行。
大多数文件系统在其file_operations实例中,都将read和write分别指向do_sync_read和do_sync_write标准例程。
read系统调用
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_read(f.file, buf, count, &pos);
if (ret >= 0)
file_pos_write(f.file, pos);
fdput_pos(f);
}
return ret;
}
write系统调用
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
if (ret >= 0)
file_pos_write(f.file, pos);
fdput_pos(f);
}
return ret;
}
read & vfs_read
Linux内核机制总结文件系统之读写文件及文件回写
read方法和read_iter方法的区别是:read方法只能传入一个连续的缓冲区,read_iter方法可以传入多个分散的缓冲区。‘

write & vfs_write

小结
UNIX操作系统的核心概念之一就是,几乎每个资源都可以表示为一个文件,并且Linux继承了这种观点。因此,文件是内核世界中非常重要的成员,文件的表示涉及了相当多的工作量。本章介绍了虚拟文件系统,这是一个胶水层,位于内核的底层和用户层之间。它提供了各种抽象数据结构来表示文件和inode,而真实文件系统的实现必须填充这些结构,使得应用程序无需考虑底层文件系统,总是可以使用同样的接口访问和操作文件。
我讨论了文件系统如何装载到用户层应用程序可见的文件系统树中,并且说明了可使用共享子树来根据命名空间创建“全局”文件系统的不同视图。读者还了解到,内核采用了许多用户层不可见的伪文件系统,但这些文件系统包含了一些信息,用于内核内部。
EXT文件系统
文件系统设计的问题
在管理基于磁盘文件系统的存储空间时,会遇到一个特殊的问题:碎片。随着文件的移动和新文件增加,可用空间变得越来越支离破碎,特别是在文件很小的情况下。由于这对访问速度有负面影响,文件系统必须尽可能减少碎片产生。
另一个重要的需求是**有效利用存储空间,在这里文件系统必须作出折中。要完全利用空间,必须将大量管理数据**存储在磁盘上。这抵消了更紧凑的数据存储带来的好处,甚至可能使情况更糟糕。此外,我们还要避免浪费磁盘容量。如果空间未能有效使用,那么就失去了减少管理数据带来的好处。各个文件系统实现处理该问题的方法均有所不同。通常会引入由管理员配置的参数,以便针对预期的
使用模式来优化文件系统(例如,预期使用大量的大文件或小文件)。**维护文件内容的一致性**也是一个关键问题,需要在规划和实现文件系统期间审慎考虑。即使最稳定的内核也可能猝然停工,可能是软件错误,也可能由于断电、硬件故障等其他原因。即使此类事故造成不可恢复的错误(例如,如果修改被缓存在物理内存中,没有写回磁盘,那么修改会丢失),文件系统的实现必须尽可能快速、全面地纠正可能出现的损坏。在最低限度上,它必须能够将文件系统还原到一个可用状态。
最后,在评价文件系统的质量时,**速度**也是一个重要的因素。即使硬盘与CPU或物理内存相比极其很慢,但糟糕的文件系统会进一步降低系统的速度。
虚拟文件系统接口和数据结构构成了一个框架,各个文件系统实现都必须在框架内运转。但这并不要求每个文件系统在持久存储其内容的块设备上组织文件时,需要采用同样的思想、方法和概念。
完全相反:Linux支持多种文件系统概念,包括那些易于实现和理解但功能并不特别强大的文件系统(例如Minix文件系统);经过验证的Ext2文件系统,其使用者数以百万计;特别设计的文件系统,以支持基于RAM和ROM的存储;高可用性的集群文件系统;还有现代的、基于树的文件系统,能够通过事务日志快速恢复一致性。
Ext2文件系统
虽然现在大部分Linux安装都优先使用Ext3而不是Ext2,但首先讨论Ext2仍然是有意义的。由于其代码无须实现任何日志功能,与Ext3实现相比通常简单些,因而更容易理解它们的基本原理。除了日志外,两种文件系统几乎完全相同,许多起源于Ext3的一般性改进已经反向移植到Ext2。
Ext2第二代扩展文件系统(英语:second extended filesystem,缩写为ext2),是LINUX内核所用的文件系统。
Ext2文件系统特性(专注于高性能):
- 当创建Ext2文件系统时,系统管理员可以根据预期的文件平均长度来选择最佳的块大小(从1024B——4096B)。例如,当文件的平均长度小于几千字节时,块的大小为1024B是最佳的,因为这会产生较少的内部碎片——也就是文件长度与存放块的磁盘分区有较少的不匹配。另一方面,大的块对于大于几千字节的文件通常比较合合适,因为这样的磁盘传送较少,因而减轻了系统的开销。
- 当创建Ext2文件系统时,系统管理员可以根据在给定大小的分区上预计存放的文件数来选择给该分区分配多少个索引节点。这可以有效地利用磁盘的空间。
- 文件系统把磁盘块分为组。每组包含存放在相邻磁道上的数据块和索引节点。正是这种结构,使得可以用较少的磁盘平均寻道时间对存放在一个单独块组中的文件并行访问。
- 在磁盘数据块被实际使用之前,文件系统就把这些块预分配给普通文件。因此当文件的大小增加时,因为物理上相邻的几个块已被保留,这就减少了文件的碎片。
- 支持快速符号链接。如果符号链接表示一个短路径名(小于或等于60个字符),就把它存放在索引节点中而不用通过由一个数据块进行转换。
物理结构
块组是Ext2文件系统的核心要素。块组是该文件系统的基本成分,容纳了文件系统的其他结构。

磁盘上剩余的空间由连续的许多块组占用,存储了文件系统元数据和各个文件的有用数据,如上图清楚地说明了,每个块组包含许多冗余信息。
为什么Ext2文件系统允许这样浪费空间?
有两个原因,可以证明提供额外空间的做法是正确的。
- 如果系统崩溃破坏了超级块,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的(难度极高,大多数用户可能一点也恢复不了)。
- 通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
实际上,数据并非在每个块组中都复制,内核也只用超级块的第一个副本工作,通常这就足够了。在进行文件系统检查时,会将第一个超级块的数据传播到剩余的超级块,供紧急情况下读取。因为该方法也会消耗大量的存储空间,Ext2的后续版本采用了稀疏超级块(sparse superblock)技术。该做法中,超级块不再存储到文件系统的每个块组中,而是只写入到块组0、块组1和其他ID可以表示为3、5、7的幂的块组中。
块组中各个结构的作用都是什么呢?在回答该问题之前,最好简要概述其语义。
- **超级块是用于存储文件系统自身元数据的核心结构。**其中的信息包括空闲与已使用块的数目、块长度、当前文件系统状态(在启动时用于检测前一次崩溃)、各种时间戳(例如,上一次装载文件系统的时间以及上一次写入操作的时间)。它还包括一个表示文件系统类型的魔数,这样mount例程能够确认文件系统的类型是否正确。内核只使用第一个块组的超级块读取文件系统的元信息,即使在几个超级块中都有超级块,也是如此。
- 组描述符包含的信息反映了文件系统中各个块组的状态,例如,块组中空闲块和inode的数目。每个块组都包含了文件系统中所有块组的组描述符信息。
- **数据块位图和inode位图用于保存长的比特位串。**这些结构中的每个比特位都对应于一个数据块或inode,用于表示对应的数据块或inode是空闲的,还是被使用中。
- inode表包含了块组中所有的inode,inode用于保存文件系统中与各个文件和目录相关的所有元数据。
- 顾名思义,数据块部分包含了文件系统中的文件的有用数据。
Ext2数据结构
必须建立各种结构(在内核中定义为C语言数据类型),来存放文件系统的数据,包括文件内容、目录层次结构的表示、相关的管理数据(如访问权限或与用户和组的关联),以及用于管理文件系统内部信息的元数据。这些对从块设备读取数据进行分析而言,都是必要的。这些结构的持久副本显然需要存储在硬盘上,这样数据在两次会话之间不会丢失。下一次启动重新激活内核时,数据仍然是可用的。因为硬盘和物理内存的需求不同,同一数据结构通常会有两个版本。一个用于在磁盘上的持久存储,另一个用于在内存中的处理。
超级块
超级块是文件系统的核心结构,保存了文件系统所有的特征数据。内核在装载文件系统时,最先看到的就是超级块的内容。使用ext2_super_block结构定义超级块
s_magic字段存储一个魔数,该数值确认装载的文件系统确实是Ext2类型,s_ minor_rev_level用于区分文件系统的不同的版本。
struct ext2_super_block {
__le32 s_inodes_count; /* inode数目 */
__le32 s_blocks_count; /* 块数目 */
__le32 s_r_blocks_count; /* 已分配块的数目 */
__le32 s_free_blocks_count; /* 空闲块数目 */
__le32 s_free_inodes_count; /* 空闲inode数目 */
__le32 s_first_data_block; /* 第一个数据块 */
__le32 s_log_block_size; /* 块长度 */
__le32 s_log_frag_size; /* 碎片长度*/
__le32 s_blocks_per_group; /* 每个块组包含的块数 */
__le32 s_frags_per_group; /* # 每个块组包含的碎片*/
__le32 s_inodes_per_group; /* 每个块组的inode数目 */
__le32 s_mtime; /* 装载时间 */
__le32 s_wtime; /* 写入时间 */
__le16 s_mnt_count; /* 装载计数 */
__le16 s_max_mnt_count; /* 最大装载计数 */
__le16 s_magic; /* 魔数,标记文件系统类型 */
__le16 s_state; /* 文件系统状态 */
__le16 s_errors; /* 检测到错误时的行为 */
__le16 s_minor_rev_level; /* 副修订号 */
__le32 s_lastcheck; /* 上一次检查的时间 */
__le32 s_checkinterval; /* 两次检查允许间隔的最长时间 */
__le32 s_creator_os; /* 创建文件系统的操作系统 */
__le32 s_rev_level; /* 修订号 */
__le16 s_def_resuid; /* 能够使用保留块的默认UID */
__le16 s_def_resgid; /* 能够使用保留块的默认GID */
...
组描述符
每个块组都有k个组描述符,组描述符紧随超级块之后。其中保存的信息反映了文件系统每个块组的内容,因此不仅关系到当前块组的数据块,还与其他块组的数据块和inode块相关。用于定义单个组描述符的数据结构比超级块结构短得多,具体源码如下:
每个块组中都包含了文件系统中所有块组的组描述符。因此从每个块组,都可以确定系统中所有其他块组的下列信息:
- 块和inode位图的位置;
- inode表的位置;
- 空闲块和inode的数目。
用作块和inode位图的数据块,则只是用于一个块组,而不会复制到文件系统的每个块组。实际上,文件系统中的每个块组,都只有一个块位图和inode位图。每个块组都有一个用于块位图的local块,和一个用于inode位图的extra块。但从每个块组,都可以访问所有其他块组的块位图和inode位图。因为可以借助组描述符中的数据项,来确定其位置。
因为文件系统的块长是可变的,一个块位图可表示的块的数目也是可变的。如果块长度为2048字节,那么一个块有2048 × 8 = 16 384个比特位,可用于描述数据块的状态。类似地,块长为1024和4096时,一个块用作位图,可管理8192和32768个块。
由于块长度的限制,一个块组只能管理一定数目的数据块**(数据位图是一个块)**,因而对文件长度有最大限制。如果超出限制,文件就必须散布到几个块组,因此寻道的距离会更长,进而会降低性能。
struct ext2_group_desc
{
__le32 bg_block_bitmap; /* 块位图块 */
__le32 bg_inode_bitmap; /* inode位图块 */
__le32 bg_inode_table; /* inode表块 */
__le16 bg_free_blocks_count; /* 空闲块数目 */
__le16 bg_free_inodes_count; /* 空闲inode数目 */
__le16 bg_used_dirs_count; /* 目录数目 */
__le16 bg_pad;
__le32 bg_reserved[3];
};
inode
每个块组都包含一个inode位图和一个本地的inode表,inode表可能延续到几个块。位图的内容与本地块组相关,不会复制到文件系统中任何其他位置。
inode位图用于概述块组中已用和空闲的inode。通常,每个inode对应到一个比特位,有“已用”和“空闲”两种状态。inode数据保存在inode表中,包括了许多顺序存储的inode结构。这些数据如何保存到存储介质,由下列冗长的结构定义:
struct ext2_inode {
__le16 i_mode; /* 文件模式 */
__le16 i_uid; /* 所有者UID的低16位 */
__le32 i_size; /* 长度,按字节计算 */
__le32 i_atime; /* 访问时间 */
__le32 i_ctime; /* 创建时间 */
__le32 i_mtime; /* 修改时间 */
__le32 i_dtime; /* 删除时间 */
__le16 i_gid; /* 组ID的低16位 */
__le16 i_links_count; /* 链接计数 */
__le32 i_blocks; /* 块数目 */
__le32 i_flags; /* 文件标志 */
union {
struct {
__le32 l_i_reserved1;
} linux1;
struct {
__le32 h_i_translator;
} hurd1;
struct {
__le32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
个块组有多少个inode?答案取决于文件系统创建时的设置。在创建文件系统时,每个块组的inode数目可以设置为任意(合理的)值。这个数目保存在s_inodes_per_group字段中。因为inode结构的长度固定为120字节,利用inode数目和块长度即可算出块组中的inode会占用多少个块。不管块长度如何,每个块组的inode数目的默认设置是128。对大多数应用场景来说,这都是一个可接受的值。
指向文件数据块的指针(块号)保存在i_block数组中,该数组有EXT2_N_BLOCKS个数组项。默认情况下,EXT2_N_BLOCKS设置为12 + 3。前12个元素用于寻址直接块,后3个用于实现简单、二次和三次间接。尽管理论上该值可以在编译时改变,但一般不建议这样做,因为这可能导致与所有其他Ext2标准格式的不兼容。
目录和文件
经典的UNIX文件系统中,目录不过是一种特殊的文件,其中是inode指针和对应的文件名列表,表示了当前目录下的文件和子目录。
对于Ext2文件系统,也是这样。每个目录表示为一个inode,会对其分配数据块。数据块中包含了用于描述目录项的结构。在内核源代码中,目录项结构定义如下:
struct ext2_dir_entry_2 {
__le32 inode; /* inode编号 */
__le16 rec_len; /* 目录项长度 */
__u8 name_len; /* 名称长度 */
__u8 file_type;
char name[EXT2_NAME_LEN]; /* 文件名 */
};
enum {
EXT2_FT_UNKNOWN = 0,
EXT2_FT_REG_FILE = 1, // 普通文件
EXT2_FT_DIR = 2, // 目录
EXT2_FT_CHRDEV = 3, // 字符串设备
EXT2_FT_BLKDEV = 4, // 块设备
EXT2_FT_FIFO = 5, // 管道
EXT2_FT_SOCK = 6, // 套接字
EXT2_FT_SYMLINK = 7, // 符号链接
EXT2_FT_MAX
};
Ext2文件系统操作
虚拟文件系统和具体实现之间的关联大体上由3个结构建立,结构中包含了一系列的函数指针。所有的文件系统都必须实现该关联。
-
用于操作文件内容的操作保存在file_operations中。
-
用于此类文件对象自身的操作保存在inode_operations中
-
用于一般地址空间的操作保存在address_space_operations中。
目录也有自身的file_operations实例和inode_operations实例
fs/ext2/file.c
Ext2文件系统对不同的文件类型提供了不同的file_operations实例。很自然,最常用的变体是用于普通文件
const struct file_operations ext2_file_operations = {
.llseek = generic_file_llseek,
.read_iter = ext2_file_read_iter,
.write_iter = ext2_file_write_iter,
.unlocked_ioctl = ext2_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext2_compat_ioctl,
#endif
.mmap = ext2_file_mmap,
.open = dquot_file_open,
.release = ext2_release_file,
.fsync = ext2_fsync,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
};
fs/ext2/inode.c
struct inode_operations ext2_file_inode_operations = {
.truncate = ext2_truncate,
.setxattr = generic_setxattr,
.getxattr = generic_getxattr,
.listxattr = ext2_listxattr,
.removexattr = generic_removexattr,
.setattr = ext2_setattr,
.permission = ext2_permission,
};
文件系统和块层通过address_space_operations关联(进程虚拟内存)。在Ext2文件系统中,这些操作初始化如下:
深入理解Linux虚拟内存管理 linux 2.x版本
现在的dentry在file的struct path里

struct address_space_operations ext2_aops = {
.readpage = ext2_readpage,
.readpages = ext2_readpages,
.writepage = ext2_writepage,
.sync_page = block_sync_page,
.write_begin = ext2_write_begin,
.write_end = generic_write_end,
.bmap = ext2_bmap,
.direct_IO = ext2_direct_IO,
.writepages = ext2_writepages,
};
第4个结构(super_operations)用于与超级块交互(读、写、分配inode)。对于Ext2文件系统的,该结构初始化如下:
static struct super_operations ext2_sops = {
.alloc_inode = ext2_alloc_inode,
.destroy_inode = ext2_destroy_inode,
.read_inode = ext2_read_inode,
.write_inode = ext2_write_inode,
.delete_inode = ext2_delete_inode,
.put_super = ext2_put_super,
.write_super = ext2_write_super,
.statfs = ext2_statfs,
.remount_fs = ext2_remount,
.clear_inode = ext2_clear_inode,
.show_options = ext2_show_options,
};
Ext4文件系统
Ext3
事务(transaction)概念起源于数据库领域,它有助于在操作未能完成的情况下保证数据的一致性。一致性问题同样也会发生在文件系统中(不是Ext特有的)。如果文件系统操作被无意中断(例如,停电或用户直接切断电源),这种情况下元数据的正确性和一致性如何保证?
Ext3的基本思想在于,将对文件系统元数据的每个操作都视为事务,在执行之前要先行记录到日志中。在事务结束后(即,对元数据的预期修改已经完成),相关的信息从日志删除。如果事务数据已经写入到日志之后,而实际操作执行之前(或期间),发生了系统错误,那么在下一次装载文件系统时,将会完全执行待决的操作。接下来,文件系统自动恢复到一致状态。如果在事务数据尚未写到
日志之前发生错误,那么在系统重启时,由于关于该操作的数据已经丢失,因而不会执行该操作,但至少保证了文件系统的一致性。
事务日志当然是需要额外开销的,因而Ext3的性能与Ext2相比,是有所降低的。为了在所有情况下,在性能和数据完整性之间维持适当的均衡,内核能够以3种不同的方式访问Ext3文件系统。
(1) 回写(writeback)模式,日志只记录对元数据的修改。对实际数据的操作不记入日志。这种模式提供了最高的性能,但数据保护是最低的。
(2) 顺序(ordered)模式,日志只记录对元数据的修改。但对实际数据的操作会群集起来,总是在对元数据的操作之前执行。因而该模式比回写模式稍慢。
(3) 日志模式,对元数据和实际数据的修改,都写入日志。这提供了最高等级的数据保护,但速度是最慢的(除了几种病态情况以外)。丢失数据的可能性降到最低。
1、使用Ext3文件系统的Linux内核中实现三个级别的日志记录:日记journal、顺序ordered和回写writeback。
2、案例Ext3文件系统,数据块分配器每次分配一个4kb的块,如果我们要写一个100mb文件就需要调用25600次数据块分配器。
EXT3与EXT4的主要区别
Ext4文件系统特性
Ext4文件系统架构分析
EXT4是第四代扩展文件系统(Fourth extended filesystem,缩写为ext4)是Linux系统下的日志文件系统,是ext3文件系统的后继版本。内核2.6.28引入Ext4文件系统成为稳定版。
Ext4文件系统特性
- 更大的文件系统和更大的文件;更多的子目录数量;更多的块和i-节点数量;
- 多块分配;持久性预分配;延迟分配;
- 盘区结构;日志校验功能;支持“无日志”模式;在线碎片整理;支持快速fsck;支持纳秒级时间戳。
数据块和Inode分配策略
在机械磁盘上,保持相关的数据块相互接近可以总的磁头移动时间,因而可以加速磁盘IO。在SSD上虽然没有磁头转动,数据局部性可以增加每次IO请求的传输的数据大小,因而减少响应IO请求的传输次数。数据的局部性对单个擦除块的写入产生影响,可以加速文件重写的速度。因而尽可能减少碎片是必要的。inode和数据块的分配策略可以保证数据的局部集中。以下为inode和数据块的分配策略:
(1) 多块分配可以减少磁盘碎片。当文件初次创建的时候,块分配器预测性地分配8KB的磁盘空间给文件。当文件关闭的时候,未使用的空间当然也就释放了。但是如果推测是正确的,那么文件数据将写到一个多个块的extent中。
(2) 延迟分配。当一个文件需要更多的数据块引起写操作时,文件系统推迟决定新数据在磁盘上的存放位置,直到脏的buffer写到磁盘为止。
(3) 尽量保持文件的数据块与其inode在同一个块组中。可以减少磁盘寻道时间.
(4) 尽量保持同一个目录中的所有inodes与目录位于同一个块组中。这样的假设前提是一个目录中的文件是相关的。
(5) 磁盘卷被分成128MB的块组。当在根目录中创建目录时,inode分配器扫描块组并将新目录放到它找到的使用负荷最小的块组中。这可以保证目录在磁盘上的分散性。
(6) 即使上述机制无效,仍然可以使用e4defrag整理碎片文件。
磁盘布局
一个Ext4文件系统被分成一系列块组。为减少磁盘碎片产生的性能瓶颈,块分配器尽量保持每个文件的数据块都在同一个块组中,从而减少寻道时间。以4KB的数据块为例,一个块组可以包含32768个数据块,也就是128MB。每个块组一般包括超级块、块组描述符表、预留块组描述符表、数据位图、inode位图、inode表、数据块。Ext4文件系统主要使用块组0中的超级块和块组描述符表,在特定的块组(譬如说0,3,5,7)才有超级块和块组描述符表的冗余备份。普通块组中不含冗余备份,那么块组就以数据块位图开始。如下图所示:

当格式化磁盘成为Ext4文件系统的时候,mkfs将在块组描述符表后面分配预留GDT表数据块(“Reserve GDT blocks”)以用于将来扩展文件系统。紧接在预留GDT表数据块后的是数据块位图与inode表位图,这两个位图分别表示本块组内的数据块与inode表的使用,inode表数据块之后就是存储文件的数据块了。在这些各种各样的块中,超级块、GDT、块位图、Inode位图都是整个文件系统的元数据,当然inode表也是文件系统的元数据,但是inode表是与文件一一对应的,我更倾向于将inode当做文件的元数据,因为在实际格式化文件系统的时候,除了已经使用的十来个inode表外,其他inode表中实际上是没有任何数据的,直到创建了相应的文件才会分配inode表,文件系统才会在inode表中写入与文件相关的inode信息。
引导块是硬盘上的一个区域,在系统加电启动时,其内容由BIOS自动装载并执行。它包含一个启动装载程序,用于从计算机安装的操作系统中选择一个启动,还负责继续启动过程。显然,该区域不可能填充文件系统的数据
元块组(Meta Block Groups)
Meta Block Groups 特性:由于块组描述符表和超级块是磁盘系统的全局信息,需要全局备份,那么加入每个都备份块描述符表就很占空间,而且限制了文件系统的大小。所以我们将多个块组组合为一个元块组。
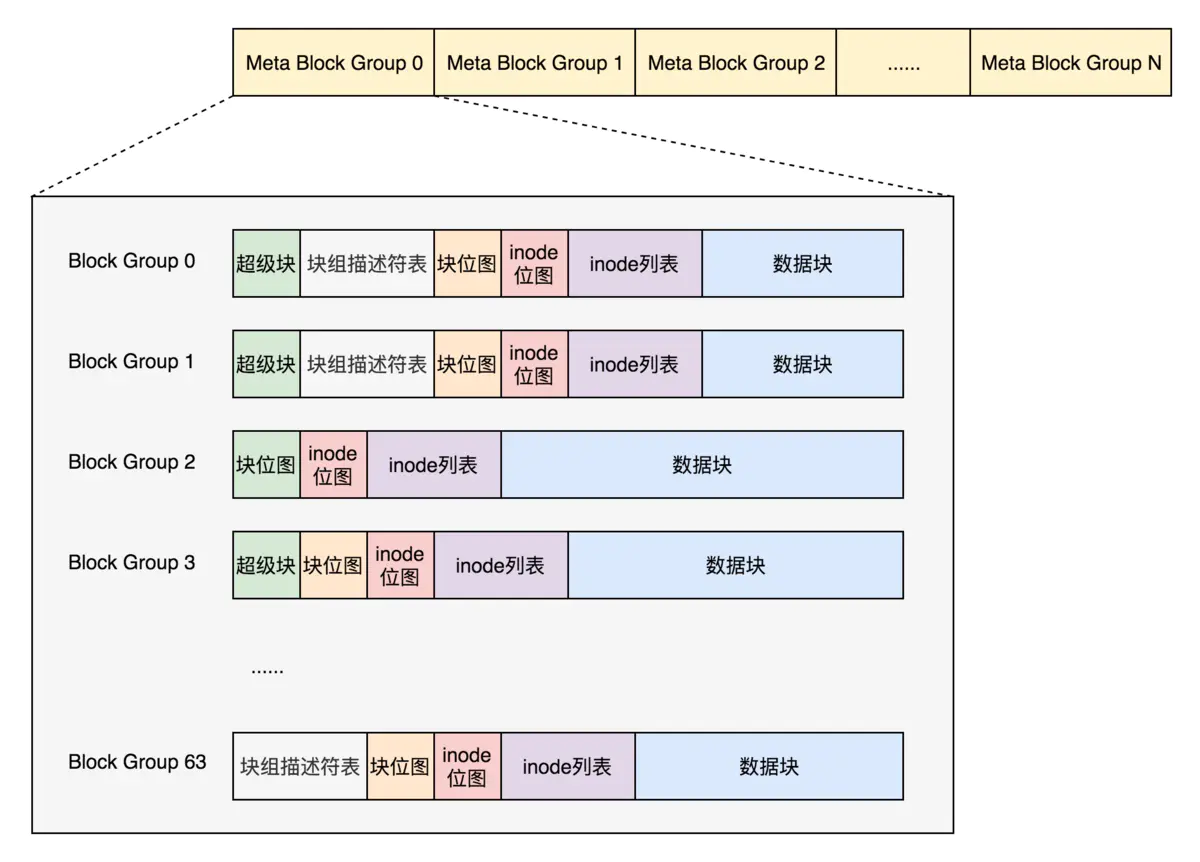
如图,每个元块组之只维护自己的块组描述符,然后保存在第一个第二个和最后一个块组中,超级块则是保存在0,3,5,7 的幂的块组中。
在两种情况下我们可能会用到这种新布局:
(1)文件系统创建时。用户可以指定使用这种布局。
(2)当前文件系统增长而且预留的组描述符块耗尽时。目前超级块中有一个域s_first_meta_bg用于描述第一个使用元块组的块组。
当增加新块组时,我们不需要给组描述符表预留空间,而是在当前文件系统后面直接添加新的元块组就可以了。
数据结构
灵活块组(flex_bg)
struct flex_groups {
atomic64_t free_clusters;
atomic_t free_inodes;
atomic_t used_dirs;
};
灵活块组(flex_bg)是从Ext4开始引入的新特性。在一个flex_bg中,几个块组在一起组成一个逻辑块组。flex_bg.Flex_bg的第一个块组中的位图空间和inode表空间扩大为包含了flex_bg中其他块组上位图和inode的表。
比如flex_bg包含4个块组,块组0将按序包含超级块,块组描述符表,块组0-3的数据块位图,块组0-3的索引节点位图,块组0-3的i节点表,块组0中的其他空间用于存储文件数据。同时,其他块组上的数据块位图,索引节点位图,索引节点表元数据就不存在了,但是SB和GDT还是存在的。

灵活的块组的作用是:
(1)聚集元数据,加速元数据载入;
(2)使得大文件在磁盘上尽量连续;
即使开启flex_bg特性,超级块和块组描述符的冗余备份仍然位于块组的开头。Flex_bg中块组的个数由2 ^ ext4_super_block.s_log_groups_per_flex给出。
超级块
超级块记录整个文件系统的大量信息,如数据块个数、inode个数、支持的特性、管理信息,等待。如果设置sparse_super特性标志,超级块和块组描述符表的冗余备份仅存放在编号为0或3、5、7的幂次方的块组中。如果未设置sparse_super特性标志,冗余备份存在与所有的块组中。
struct ext4_super_block {
/*00*/ __le32 s_inodes_count; //inode数量
__le32 s_blocks_count_lo;//块数量
__le32 s_r_blocks_count_lo;//保留块的数量
__le32 s_free_blocks_count_lo;//空闲块的数量
/*10*/ __le32 s_free_inodes_count;//空闲inode的数量
__le32 s_first_data_block;//第一块数据块
__le32 s_log_block_size;//块大小
__le32 s_log_cluster_size; /* Allocation cluster size */
/*20*/ __le32 s_blocks_per_group;//每个块组的块数量
__le32 s_clusters_per_group; /* # Clusters per group */
__le32 s_inodes_per_group;//每个块组的索引数量
__le32 s_mtime;//挂载时间
/*30*/ __le32 s_wtime;//最后一次写入时间
__le16 s_mnt_count;//挂载次数
__le16 s_max_mnt_count;//允许最大挂载数量
__le16 s_magic;//魔数
__le16 s_state;//文件系统状态
__le16 s_errors; /* 检测到错误时的动作 */
__le16 s_minor_rev_level;//最小版本
/*40*/ __le32 s_lastcheck;//最近检查时间
__le32 s_checkinterval;//最长检查时间,超过就回调检查
__le32 s_creator_os; /* 要创建文件系统的os */
__le32 s_rev_level;//修订版本
/*50*/ __le16 s_def_resuid;//默认预留块的用户id
__le16 s_def_resgid;//默认预留块的用户组id
/*
* These fields are for EXT4_DYNAMIC_REV superblocks only.
*
* Note: the difference between the compatible feature set and
* the incompatible feature set is that if there is a bit set
* in the incompatible feature set that the kernel doesn't
* know about, it should refuse to mount the filesystem.
*
* e2fsck's requirements are more strict; if it doesn't know
* about a feature in either the compatible or incompatible
* feature set, it must abort and not try to meddle with
* things it doesn't understand...
*/
__le32 s_first_ino; /* 第一个非保留的inode号码 */
__le16 s_inode_size; /* inode结构大小 */
__le16 s_block_group_nr; /* 该超级块所在的块组号 */
__le32 s_feature_compat; /* 兼容特性集 */
/*60*/ __le32 s_feature_incompat; /* 非兼容特性集 */
__le32 s_feature_ro_compat; /* 只读兼容特性集 */
/*68*/ __u8 s_uuid[16]; /* 128的卷uuid */
/*78*/ char s_volume_name[16]; /* 卷名字 */
/*88*/ char s_last_mounted[64] __nonstring; /* 最近一次的挂载目录 */
/*C8*/ __le32 s_algorithm_usage_bitmap; /* 用于压缩 */
/*
* Performance hints. Directory preallocation should only
* happen if the EXT4_FEATURE_COMPAT_DIR_PREALLOC flag is on.
*/
__u8 s_prealloc_blocks; /* 预分配的块数 */
__u8 s_prealloc_dir_blocks; /* 为目录预分配的块数 */
__le16 s_reserved_gdt_blocks; /* 因为数据增长为块组描述符保留的块数 */
/*
* Journaling support valid if EXT4_FEATURE_COMPAT_HAS_JOURNAL set.
*/
/*D0*/ __u8 s_journal_uuid[16]; /* 日志超级快的uuid */
/*E0*/ __le32 s_journal_inum; /* 日志文件的索引号 */
__le32 s_journal_dev; /* 日志文件的设备号 */
__le32 s_last_orphan; /* 待删除的inode链表起始位置 */
__le32 s_hash_seed[4]; /* HTREE散列表种子 */
__u8 s_def_hash_version; /* 默认使用的哈希版本 */
__u8 s_jnl_backup_type;
__le16 s_desc_size; /* 块组描述符大小 */
/*100*/ __le32 s_default_mount_opts;
__le32 s_first_meta_bg; /* 第一个块组 */
__le32 s_mkfs_time; /* 文件系统创建时间 */
__le32 s_jnl_blocks[17]; /* 日志inode的备份 */
/* 64bit support valid if EXT4_FEATURE_COMPAT_64BIT */
/*150*/ __le32 s_blocks_count_hi; /* 块数量高位 */
__le32 s_r_blocks_count_hi; /* 保留块的数量高位 */
__le32 s_free_blocks_count_hi; /* 空闲块的数量高位 */
__le16 s_min_extra_isize; /* inode最小大小,单位字节 */
__le16 s_want_extra_isize; /* 新的inode需要保留大小,单位字节 */
__le32 s_flags; /* 各种标志位 */
__le16 s_raid_stride; /* RAID stride */
__le16 s_mmp_update_interval; /* 多挂载检查等待时间,单位秒 */
__le64 s_mmp_block; /* 多挂载保护块 */
__le32 s_raid_stripe_width; /* blocks on all data disks (N*stride)*/
__u8 s_log_groups_per_flex; /* Flexible 块组大小 */
__u8 s_checksum_type; /* 元数据校验算法类型 */
__u8 s_encryption_level; /* 加密的版本级别 */
__u8 s_reserved_pad; /* Padding to next 32bits */
__le64 s_kbytes_written; /* 写生命周期,单位千字节 */
__le32 s_snapshot_inum; /* 活动快照的Inode数 */
__le32 s_snapshot_id; /* 活动快照ID */
__le64 s_snapshot_r_blocks_count; /* 供活动快照将来使用的保留块数量 */
__le32 s_snapshot_list; /* 磁盘上快照列表头的Inode号 */
#define EXT4_S_ERR_START offsetof(struct ext4_super_block, s_error_count)
__le32 s_error_count; /* fs错误个数 */
__le32 s_first_error_time; /* fs第一个错误发生时间 */
__le32 s_first_error_ino; /* 第一个错误涉及的Inode */
__le64 s_first_error_block; /* 第一个错误涉及的块 */
__u8 s_first_error_func[32] __nonstring; /* 第一个错误发生的函数 */
__le32 s_first_error_line; /* 发生第一个错误的行号 */
__le32 s_last_error_time; /* 最近一次错误的时间 */
__le32 s_last_error_ino; /* 最近一次错误中涉及的inode */
__le32 s_last_error_line; /* 最近一次发生错误的行号 */
__le64 s_last_error_block; /* 最近一次错误涉及的块 */
__u8 s_last_error_func[32] __nonstring; /* 最近一次错误发生的函数 */
#define EXT4_S_ERR_END offsetof(struct ext4_super_block, s_mount_opts)
__u8 s_mount_opts[64];
__le32 s_usr_quota_inum; /* 用于跟踪用户配额的inode */
__le32 s_grp_quota_inum; /* 用于跟踪组配额的inode */
__le32 s_overhead_clusters; /* 文件系统的开销块/集群 */
__le32 s_backup_bgs[2]; /* groups with sparse_super2 SBs */
__u8 s_encrypt_algos[4]; /* 使用加密算法种类 */
__u8 s_encrypt_pw_salt[16]; /* 用于string2key算法的Salt */
__le32 s_lpf_ino; /* 索引节点的位置 */
__le32 s_prj_quota_inum; /* 用于跟踪项目配额的inode */
__le32 s_checksum_seed; /* crc32c(uuid) if csum_seed set */
__u8 s_wtime_hi; //写入时间
__u8 s_mtime_hi; //修改时间
__u8 s_mkfs_time_hi;//简历文件系统时间
__u8 s_lastcheck_hi;//最近一次检查
__u8 s_first_error_time_hi;//第一次错误发生时间
__u8 s_last_error_time_hi;//最近一次错误发生时间
__u8 s_pad[2];
__le32 s_reserved[96]; /* Padding to the end of the block */
__le32 s_checksum; /* crc32c(superblock) */
};
块组描述符
一个块组中,具有固定位置的数据结构是超级块和块组描述符。其他数据结构位置都可以不固定。Flex_bg机制使用这个性质将几个块组聚合成一个flex块组,将flex_bg中所有位图和inode 表放到flex_bg的第一个块组中。详细情况可以参考我的上一篇Ext4分析博文的Flexible 块组(flex_bg)部分。
struct ext4_group_desc
{
__le32 bg_block_bitmap_lo; /* 数据块位图 */
__le32 bg_inode_bitmap_lo; /* Inodes位图 */
__le32 bg_inode_table_lo; /* 块组中第一个Inodes表的数据块号 */
__le16 bg_free_blocks_count_lo;/* 空闲数据块数量 */
__le16 bg_free_inodes_count_lo;/* 空闲数据块数量 */
__le16 bg_used_dirs_count_lo; /* D块组中目录个数 */
__le16 bg_flags; /* EXT4_BG_flags (INODE_UNINIT, etc) */
__le32 bg_exclude_bitmap_lo; /* 排除快照的位图 */
__le16 bg_block_bitmap_csum_lo;/* crc32c(s_uuid+grp_num+bbitmap) LE 数据块位图校验 */
__le16 bg_inode_bitmap_csum_lo;/* crc32c(s_uuid+grp_num+ibitmap) LE Inodes位图校验 */
__le16 bg_itable_unused_lo; /* 未使用inodes数量 */
__le16 bg_checksum; /* crc16(sb_uuid+group+desc)校验 */
__le32 bg_block_bitmap_hi; /* 数据块位图 MSB */
__le32 bg_inode_bitmap_hi; /* Inodes位图 MSB */
__le32 bg_inode_table_hi; /* Inodes表块 MSB */
__le16 bg_free_blocks_count_hi;/* 空闲块计数MSB */
__le16 bg_free_inodes_count_hi;/* 空心啊节点数MSB */
__le16 bg_used_dirs_count_hi; /* 已经使用的目录数量MSB */
__le16 bg_itable_unused_hi; /* 未使用节点数MSB */
__le32 bg_exclude_bitmap_hi; /* 不包括位图块 MSB */
__le16 bg_block_bitmap_csum_hi;/* crc32c(s_uuid+grp_num+bbitmap) BE */
__le16 bg_inode_bitmap_csum_hi;/* crc32c(s_uuid+grp_num+ibitmap) BE */
__u32 bg_reserved;
};
inode
inode i为index的意思,inode用于保存文件的元数据信息,包括权限,文件名。
struct ext4_inode {
__le16 i_mode; /* 文件类型和访问权限 */
__le16 i_uid; /* 文件所有者ID */
__le32 i_size_lo; /* 文件大小,单位字节 */
__le32 i_atime; /* 访问时间 */
__le32 i_ctime; /* 索引修改时间 */
__le32 i_mtime; /* 文件内容修改时间 */
__le32 i_dtime; /* 删除时间 */
__le16 i_gid; /* 用户组ID */
__le16 i_links_count; /* 连接数量 */
__le32 i_blocks_lo; /* 块数量 */
__le32 i_flags; /* 文件类型 */
union {
struct {
__le32 l_i_version;
} linux1;
struct {
__u32 h_i_translator;
} hurd1;
struct {
__u32 m_i_reserved1;
} masix1;
} osd1; /* 特定的os信息1 */
__le32 i_block[EXT4_N_BLOCKS];/* 文件内容块号码 */
__le32 i_generation; /* 文件版本 */
__le32 i_file_acl_lo; /* File ACL */
__le32 i_size_high; //文件大小的高位
__le32 i_obso_faddr; /* Obsoleted fragment address */
union {
struct {
__le16 l_i_blocks_high; /* 数据块数高16位 */
__le16 l_i_file_acl_high;//高16位的文件ACL
__le16 l_i_uid_high; /* 所有者id的高16位 */
__le16 l_i_gid_high; /* 组ID的高16位 */
__le16 l_i_checksum_lo;/* crc32c(uuid+inum+inode) LE */
__le16 l_i_reserved;
} linux2;
struct {
__le16 h_i_reserved1; /* Obsoleted fragment number/size which are removed in ext4 */
__u16 h_i_mode_high;
__u16 h_i_uid_high;
__u16 h_i_gid_high;
__u32 h_i_author;
} hurd2;
struct {
__le16 h_i_reserved1; /* Obsoleted fragment number/size which are removed in ext4 */
__le16 m_i_file_acl_high;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* 特定的os信息2 */
__le16 i_extra_isize;//extra大小
__le16 i_checksum_hi; /* crc32c(uuid+inum+inode) BE */
__le32 i_ctime_extra; /* extra修改inode时间(nsec << 2 | epoch) */
__le32 i_mtime_extra; /* extra修改文件时间(nsec << 2 | epoch) */
__le32 i_atime_extra; /* extra访问时间(nsec << 2 | epoch) */
__le32 i_crtime; /* 文件创建时间(nsec << 2 | epoch) */
__le32 i_crtime_extra; /* extra 文件创建时间 (nsec << 2 | epoch) */
__le32 i_version_hi; /* 64位版本号高32位 */
__le32 i_projid; /* 项目ID */
};
Ext4预留了一些inode做特殊特性使用
| Inode号 | 用途 |
|---|---|
| 0 | 不存在0号inode |
| 1 | 损坏数据块链表 |
| 2 | 根目录 |
| 3 | ACL索引 |
| 4 | ACL数据 |
| 5 | Boot loader |
| 6 | 未删除的目录 |
| 7 | 预留的块组描述符inode |
| 8 | 日志inode |
| 11 | 第一个非预留的inode,通常是lost+found目录 |
Extent tree
Ext4中用extent树代替了逻辑块映射。使用extents,用一个struct ext4_extent结构就可以映射多个数据块,减少元数据块的使用。如果设置了flex_bg,甚至可以用一个extent分配一个非常大的文件。使用extent特性,inode必须设置extents flag。
ext2和ext3的i_block 的结构如下
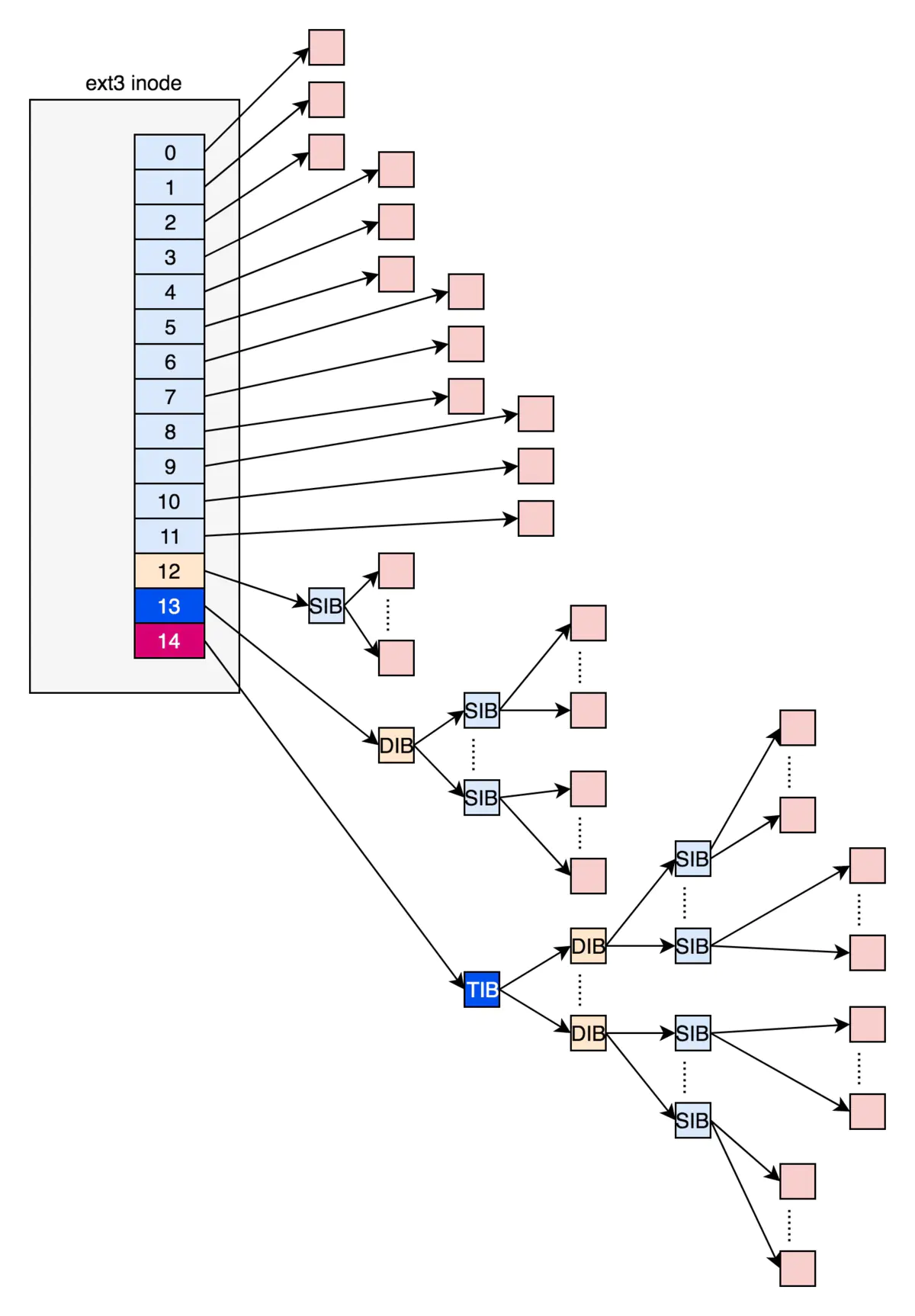
其中0-11号直接存放块位置,12为指向间接块的位置,13 指向二层间接块的位置,14指向三层间接块的位置
上面的方法第一个就是大文件搜索比较耗时,第二个文件存储比较散乱,ext4 文件系统引入了extens的特性,其结构如下。
fs\ext4\ext4_extents.h
/*
* This is the extent on-disk structure.
* It's used at the bottom of the tree.
*/
struct ext4_extent { // 12字节
__le32 ee_block; /* extent包含的第一个逻辑块 */
__le16 ee_len; /* extent包含的块个数 */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};
/*
* This is index on-disk structure.
* It's used at all the levels except the bottom.
*/
struct ext4_extent_idx { // 12字节
__le32 ei_block; /* 索引包含的逻辑数据块 */
__le32 ei_leaf_lo; /* 指向下一级的物理数据块,可以是叶子节点或者是下一级索引 */
__le16 ei_leaf_hi; /* high 16 bits of physical block */
__u16 ei_unused;
};
/*
* Each block (leaves and indexes), even inode-stored has header.
*/
struct ext4_extent_header { // 16字节
__le16 eh_magic; /* 可能支持的不同格式 */
__le16 eh_entries; /* 有效项个数 */
__le16 eh_max; /* 项存储的容量 */
__le16 eh_depth; /* 树的深度 */
__le32 eh_generation; /* 树的代数 */
};
它是一个树形结构,i_block 中只存储四个 exten_entry 其指向连续的内存块或者下一个extend_header ,其中只有叶子节点存储数据。每个exten_entry 大小为12个字节

每个extent节点由一个头部和多个body组成,无论是索引节点还是叶子节点,甚至是直接存储在inode中的extent节点。当一个文件占用的extent数量较少的时候,其extent可直接存储在inode.i_block[ ]中,当extent数量超过inode.i_block[ ]的存储容量的时候( 由上图inode结构表可知,inode.i_block最大值是60bytes (4*15),去除了extent_header 12bytes之后剩下48bytes只够存4个extent),ext4便会用B树来组织所有的extent。B树上的每个节点,无论是索引节点还是叶子节点,其主体包含两个部分:extent_header和extent_body。每个节点包含一个extent_header和多个extent_body。
Ext4_日志JBD2
从性能方面考虑,Ext4默认直接将文件系统元数据写到日志。因而不能保证文件数据块的一致性。所以需要JBD2(Journaling Block Device 2)
自从Linux系统引入了Ext4文件系统了,就有一个JBD2为之服务,其实JBD2也可以为其它的文件系统服务,但是目前来说只有Ext4和OCFS2文件系统用它。JBD2作用的原理是在Ext4文件系统把数据提交到驱动前先调用它,JBD2根据系统的不同设置来完成数据或是操作的备份后,再让Ext4系统提交数据,当文件系统把数据写入了设备后,就通过JBD2把刚才数据或是操作备份删除,这样来保证数据的一致性。
流程
1、 在数据准备提交的时候,先由JBD2根据系统设置的不同(writeback, ordered, journal)把对数据的操作写入备份,如果在这之前或是还没写完的时候系统发生了故障(如断电),那么在系统下次完整性检查时就把这些日志数据删除,而不对文件系统做任何改变。
2、 如果到这一步,说明备份数据已经写完,在以后的任何一步发生故障,系统都能根据日志把完整的备份数据写到相应的文件系统里去。当然这些完整情只能保证一个原子操作不完整性。假如你在拷贝一个600M的电影,一个原子操作是10M,那么JBD2系统只能保证下在提交的10M的数据的完成性,页不能保证这个电影的完整性。
3、如果到这一步发生故障,那么数据还没有写入设备,或是没有完全写入设备,那么下次进行完整性检查时就会把数据补全,然后执行4-5这个两个。4、5也一样的,不过起点不一样,终点都一样的,所谓的殊途同归。
文件系统在磁盘上保留一段小的连续区域(默认128MB)作为JBD。被提交的数据一份记录也被写到日志。一旦该重要数据事务完全写到磁盘,将其从JBD中刷出。这样保证日志在擦除提交记录前将事务写到它们在磁盘上的最终位置(可能包含大量的寻道或者大量的读-写-擦除)。
日志布局

一个事务以描述符和一些数据或者block revocation链表开始。一个结束的事务总是以一个提交块结束。如果没有提交记录(或者校验和不匹配),事务在日志重演的时候将被丢弃。
数据块头部结构:日志中的每个数据块的开头都是一个12bytes的数据结构,struct journal_header_s:
超级块:日志的超级块保存在日志的超级块中是日志的关键数据。日志超级块使用数据结构struct journal_superblock_s表示,大小为1024 bytes
描述数据块Descriptor Block:它包含一个日志数据块tags的数组,这些tags描述日志中接下来的数据块的最终位置
撤消块Revocation Block:用于记录本事务中的数据块链表,取代任何潜在日志中的更陈旧的数据块这样可以加速恢复,因为陈旧的数据块不必要写到磁盘。
提交块:提交块表明了一个事务已完整写到日志
事务最核心属性就是状态,当事务正在提交,它的生命周期经过如下阶段running–>locked–>flush–>commit–>ok
kjournald线程与每个进行日志的设备关联,此线程保证运行中的事务会在一个特定间隔后被提交。事务提交分成阶段操作(日志的逻辑结构):
恢复(journal_recover) 发现日志记录的尾部–>为日志记录准备一串被撤消的块–>未被撤消的块以确保磁盘一致性的顺序被重新写入(重放操作)。
proc文件系统
**proc文件系统(进程数据系统)**是一种虚拟文件系统,其信息不能从块设备读取。只有在读取文件内容时才动态生成相应的信息。使用proc文件系统,可以获得有关内核各子系统的信息(如内存利用率、附接的外设,等等),也可以在不重新编译内核源代码的情况下修改内核的行为,或重启系统。
与该文件系统密切相关的是系统控制机制(system control mechanism,简称sysctl)。proc文件系统提供了一种接口,可用于该机制导出的所有选项,使得可以不费力气地修改参数。无需开发专门的通信程序,只需要一个shell和标准的cat、echo程序。
/proc的内容
/proc信息
尽管proc文件系统的容量依系统而不同,其中仍然包含了许多深层嵌套的目录、文件、链接。信息可以分为以下几大类:
内存管理;系统进程的特征数据;
文件系统;设备驱动程序;
系统总线;电源管理;
终端;系统控制参数。
其中一些类别在本质上差别很大(上述列表很不全面),共性很少。过去,proc文件系统的信息过载问题,经常成为批评的潜在来源(有时候会猛烈地爆发)。借助虚拟文件系统提供数据当然是有用的,但更结构化的方法会更好
- 特定于进程的数据
每个系统进程,无论当前状态如何,都有一个对应的子目录(与其PID同名),包含了该进程的有关信息。顾名思义,进程数据系统(process data system,简称proc)的初衷就是传递进程数据。 特定于进程的目录保存了哪些信息?简单的一个ls-l命令,就能看到一些信息:
wolfgang@meitner> cd /proc/7748
wolfgang@meitner> ls -l
total 0
dr-xr-xr-x 2 wolfgang users 0 2008-02-15 04:22 attr
-r-------- 1 wolfgang users 0 2008-02-15 04:22 auxv
--w------- 1 wolfgang users 0 2008-02-15 04:22 clear_refs
-r--r--r-- 1 wolfgang users 0 2008-02-15 00:37 cmdline ## 起点进程的命令行
-r--r--r-- 1 wolfgang users 0 2008-02-15 04:22 cpuset
lrwxrwxrwx 1 wolfgang users 0 2008-02-15 04:22 cwd -> /home/wolfgang/wiley_kbook
-r-------- 1 wolfgang users 0 2008-02-15 04:22 environ ## 环境变量
lrwxrwxrwx 1 wolfgang users 0 2008-02-15 01:30 exe -> /usr/bin/emacs
dr-x------ 2 wolfgang users 0 2008-02-15 00:56 fd
dr-x------ 2 wolfgang users 0 2008-02-15 04:22 fdinfo
-rw-r--r--1 wolfgang users 0 2008-02-15 04:22 loginuid
-r--r--r--1 wolfgang users 0 2008-02-15 04:22 maps ## 进程使用的所有库(和进程本身的二进制文件)的内存映射
-rw-------1 wolfgang users 0 2008-02-15 04:22 mem
-r--r--r--1 wolfgang users 0 2008-02-15 04:22 mounts
-r--------1 wolfgang users 0 2008-02-15 04:22 mountstats
-r--r--r--1 wolfgang users 0 2008-02-15 04:22 numa_maps
-rw-r--r--1 wolfgang users 0 2008-02-15 04:22 oom_adj
-r--r--r--1 wolfgang users 0 2008-02-15 04:22 oom_score
lrwxrwxrwx1 wolfgang users 0 2008-02-15 04:22 root -> /
-rw-------1 wolfgang users 0 2008-02-15 04:22 seccomp
-r--r--r--1 wolfgang users 0 2008-02-15 04:22 smaps
-r--r--r--1 wolfgang users 0 2008-02-15 00:56 stat ## 有关进程状态的一般信息
-r--r--r--1 wolfgang users 0 2008-02-15 01:30 statm
-r--r--r--1 wolfgang users 0 2008-02-15 00:56 status ## 类似 gdb的bt
dr-xr-xr-x3 wolfgang users 0 2008-02-15 04:22 task
-r--r--r--1 wolfgang users 0 2008-02-15 04:22 wchan
-
一般性系统信息
不仅/proc的子目录包含了信息,/proc本身也包含了一些信息。与特定的内核子系统无关(或由几个子系统共享)的一般性信息,一般存放在/proc下的文件中。
前面各章提到了其中一些文件。例如,iomem和ioports提供了用来与设备通信的内存地址和端口的有关信息, -
网络信息
/proc/net子目录提供了内核的各种网络选项的有关数据。其中保存了各种协议和设备数据,包括以下几个有趣的数据项。- udp和tcp提供了IPv4的UDP和TCP套接字的统计数据。IPv6的对应数据保存在udp6和tcp6中。UNIX套接字的统计数据记录在unix。
- 用于反向地址解析的ARP表,可以在arp文件中查看。
- dev保存了通过系统的网络接口传输的数据量的统计数据(包括环回接口)。该信息可用于检查网络的传输质量,因为其中也包括了传输不正确的数据包、被丢弃的数据包和冲突相关的数据。
-
系统控制参数
用于动态地检查和修改内核行为的系统控制参数,在proc文件系统的数据项中,属于最多的一部分。
sysctl参数由一个独立的子目录/proc/sys管理,它进一步划分为各种子目录,对应于内核的各个子系统。ls -l /proc/sys total 0 dr-xr-xr-x 1 root root 0 Jul 9 23:10 abi dr-xr-xr-x 1 root root 0 Jul 9 23:10 debug dr-xr-xr-x 1 root root 0 Jul 9 23:10 dev dr-xr-xr-x 1 root root 0 Apr 21 23:37 fs dr-xr-xr-x 1 root root 0 Apr 22 07:37 kernel dr-xr-xr-x 1 root root 0 May 26 04:37 net dr-xr-xr-x 1 root root 0 Jul 9 23:10 user dr-xr-xr-x 1 root root 0 Apr 22 16:36 vm不同于此前讨论的文件,这些文件的内容不仅可以读,还可以通过普通的文件操作,向其中写入新值。例如,vm子目录包含了一个swappiness文件,表示交换算法在换出页时的“积极”程度。默认值是60,从cat显示的文件内容可以看到。
但该值可以通过下列命令修改(以root用户的身份):
wolfgang@meitner> echo "80" > /proc/sys/vm/swappiness wolfgang@meitner> cat /proc/sys/vm/swappiness 80
proc常见文件
-
buddyinfo:用于诊断内存碎片问题。
-
cmdline:在启动时传递至内核的相关参数信息,这些信息通常由lilo或grub等启动管理工具进行传递;
-
cpuinfo:处理器的相关信息的文件;
-
crypto:系统上已安装的内核使用的密码算法及每个算法的详细信息列表;
-
devices:系统已经加载的所有块设备和字符设备的信息;
-
diskstats:每块磁盘设备的磁盘I/O统计信息列表;
-
filesystems:当前被内核支持的文件系统类型列表文件,被标示为nodev的文件系统表示不需要块设备的支持;
-
interrupts:X86或X86_64体系架构系统上每个IRQ相关的中断号列表;
-
iomem:每个物理设备上的记忆体(RAM或者ROM)在系统内存中的映射信息;
-
ioports:当前正在使用且已经注册过的与物理设备进行通讯的输入-输出端口范围信息列表;
-
kallsyms:模块管理工具用来动态链接或绑定可装载模块的符号定义,由内核输出;
-
locks:保存当前由内核锁定的文件的相关信息,包含内核内部的调试数据;每个锁定占据一行,且具有一个惟一的编号;
-
meminfo:系统中关于当前内存的利用状况等的信息,常由free命令使用;
-
mounts:在内核2.4.29版本以前,此文件的内容为系统当前挂载的所有文件系统;
-
modules:当前装入内核的所有模块名称列表,可以由lsmod命令使用,也可以直接查看;
-
partitions:块设备每个分区的主设备号(major)和次设备号(minor)等信息;
-
stat:实时追踪自系统上次启动以来的多种统计信息;
-
swaps:当前系统上的交换分区及其空间利用信息;
-
uptime:系统上次启动以来的运行时间;
-
version:当前系统运行的内核版本号;
-
vmstat:当前系统虚拟内存的多种统计数据;
-
zoneinfo:内存区域(zone)的详细信息列表;
proc数据结构
1、proc核心数据结构源码
实现proc文件系统的代码紧围绕这些结构而建立的,proc大量使用VFS的数据结构,因为作为一种文件系统,它必须集成到内核的VFS抽象层中。还有一些特定于proc的数据结构,用于组织内核提供的数据信息。还必须提供一个到内核各个子系统的接口,使得内核能从其数据结构中提取信息,然后借助/proc提供给用户空间。proc文件系统中的每个数据项都由proc_dir_entry的一个实例描述,具体源码如下:
struct proc_dir_entry {
unsigned int low_ino; // inode编号
umode_t mode; // 此成员主要反映对应的数据项的类型(文件、目录等),以及访问权限
nlink_t nlink; // 子目录和软链接项目
kuid_t uid; // 用户ID
kgid_t gid; // 组ID
loff_t size; // 表示按字节计算的文件长度
const struct inode_operations *proc_iops; // 文件操作
const struct file_operations *proc_fops; // 节点操作
struct proc_dir_entry *parent; // 父目录指针
struct rb_root subdir; // 指向一个目录的一个数据项
struct rb_node subdir_node; // 子目录节点
void *data;
atomic_t count; /* use count */
atomic_t in_use; /* number of callers into module in progress; */
/* negative -> it's going away RSN */
struct completion *pde_unload_completion;
struct list_head pde_openers; /* who did ->open, but not ->release */
spinlock_t pde_unload_lock; /* proc_fops checks and pde_users bumps */
u8 namelen;
char name[];
};
2、装载proc文件系统
内核内部用于描述proc文件系统结构和内容的数据已初始化之后,下一步是将该文件系统装载到目录树中。在内核添加新文件系统时,会扫描一个链表,查找与该文件系统相关的file_system_type实例。源码如下:
static struct file_system_type proc_fs_type = {
.name = "proc",
.mount = proc_mount,
.kill_sb = proc_kill_sb,
.fs_flags = FS_USERNS_MOUNT,
};
proc文件系统的超级块由proc_get_sb提供。该函数基于另一个内核辅助例程( get_sb_single),借助proc_fill_super来填充一个super_block的新实例。
int proc_fill_super(struct super_block *s, void *data, int silent)
{
struct pid_namespace *ns = get_pid_ns(s->s_fs_info);
struct inode *root_inode;
int ret;
if (!proc_parse_options(data, ns))
return -EINVAL;
/* User space would break if executables or devices appear on proc */
s->s_iflags |= SB_I_USERNS_VISIBLE | SB_I_NOEXEC | SB_I_NODEV;
s->s_flags |= MS_NODIRATIME | MS_NOSUID | MS_NOEXEC;
s->s_blocksize = 1024;
s->s_blocksize_bits = 10;
s->s_magic = PROC_SUPER_MAGIC;
s->s_op = &proc_sops;
s->s_time_gran = 1;
/*
* procfs isn't actually a stacking filesystem; however, there is
* too much magic going on inside it to permit stacking things on
* top of it
*/
s->s_stack_depth = FILESYSTEM_MAX_STACK_DEPTH;
...
proc_sops中对超级块的各个操作,其中收集内核管理proc文件系统所需的各个函数,具体源码如下:
static const struct super_operations proc_sops = {
.alloc_inode = proc_alloc_inode,
.destroy_inode = proc_destroy_inode,
.drop_inode = generic_delete_inode,
.evict_inode = proc_evict_inode,
.statfs = simple_statfs,
.remount_fs = proc_remount,
.show_options = proc_show_options,
};
静态的proc_dir_entry实例:
/*
* This is the root "inode" in the /proc tree..
*/
struct proc_dir_entry proc_root = {
.low_ino = PROC_ROOT_INO,
.namelen = 5,
.mode = S_IFDIR | S_IRUGO | S_IXUGO,
.nlink = 2,
.count = ATOMIC_INIT(1),
.proc_iops = &proc_root_inode_operations,
.proc_fops = &proc_root_operations,
.parent = &proc_root,
.subdir = RB_ROOT,
.name = "/proc",
};
管理/proc数据项
虽然很容易创建新的proc数据项,但事实上,用代码来创建新的数据项并不是常例。尽管如此,在进行测试时,这些接口很有用处。借助这些简单、轻量级的接口,我们就可以用很小的代价在内核与用户空间之间打开一条通信渠道用于测试。
1、数据项的创建和注册
新数据项分两个步骤添加到proc文件系统。首先,__proc_create创建proc_dir_entry的一个新实例,填充描述该数据项的所有需要的信息。 使用fs/proc/generic.c中的proc_register将其注册到proc文件系统当中:
因为这两个步骤从来都不独立执行,所以内核提供辅助函数合并了这两个操作,使得可以快捷地创建新的proc数据项。
具体函数见 include\linux\proc_fs.h
fs\proc\generic.c
static struct proc_dir_entry *__proc_create(struct proc_dir_entry **parent,
const char *name,
umode_t mode,
nlink_t nlink)
{
struct proc_dir_entry *ent = NULL;
const char *fn;
struct qstr qstr;
if (xlate_proc_name(name, parent, &fn) != 0)
goto out;
qstr.name = fn;
qstr.len = strlen(fn);
if (qstr.len == 0 || qstr.len >= 256) {
WARN(1, "name len %u\n", qstr.len);
return NULL;
}
if (*parent == &proc_root && name_to_int(&qstr) != ~0U) {
WARN(1, "create '/proc/%s' by hand\n", qstr.name);
return NULL;
}
if (is_empty_pde(*parent)) {
WARN(1, "attempt to add to permanently empty directory");
return NULL;
}
ent = kzalloc(sizeof(struct proc_dir_entry) + qstr.len + 1, GFP_KERNEL);
if (!ent)
goto out;
memcpy(ent->name, fn, qstr.len + 1);
ent->namelen = qstr.len;
ent->mode = mode;
ent->nlink = nlink;
ent->subdir = RB_ROOT;
atomic_set(&ent->count, 1);
spin_lock_init(&ent->pde_unload_lock);
INIT_LIST_HEAD(&ent->pde_openers);
proc_set_user(ent, (*parent)->uid, (*parent)->gid);
out:
return ent;
}
切记:该函数只填充了proc_dir_entry结构的一些必要的成员。因此必须对产生的结构作一些手工校正。
创建数据项之后,注册到/proc文件系统步骤:
a.生成一个唯一proc内部编号,向数据项赋予身份。get_inode_number返回一个未使用的编号,用于为动态
生成的数据项;
b.必须适当地设备proc_dir_entry实例的next和parent成员,将新数据项集成到proc文件系统的层次结构中;
c.如果此proc_dir_entry成员的proc_iops或proc_fops为NULL指针,那么需要根据文件类型,适当地设备指向file_operations和inode_operations结构实例的指针。
static int proc_register(struct proc_dir_entry * dir, struct proc_dir_entry * dp)
{
int ret;
ret = proc_alloc_inum(&dp->low_ino);
if (ret)
return ret;
write_lock(&proc_subdir_lock);
dp->parent = dir;
if (pde_subdir_insert(dir, dp) == false) {
WARN(1, "proc_dir_entry '%s/%s' already registered\n",
dir->name, dp->name);
write_unlock(&proc_subdir_lock);
proc_free_inum(dp->low_ino);
return -EEXIST;
}
write_unlock(&proc_subdir_lock);
return 0;
}
用于管理proc数据项:
- proc_mkdir创建一个新目录;
- proc_mkdir_mode创建一个新目录,目录的访问权限可以显式指定;
- proc_symlink生成一个符号链接;
- remove_proc_entry从proc目录中删除一个动态生成的数据项;
内核源码相关示例文件,在Documentation/DocBook/procfs_example.c。负责proc文件系统的读/写例程和内核子系统之间的交互。
简单的文件系统 libfs
全功能的文件系统很难编写,在达到可用、高效、正确的状态之前,需要投入大量的工作量。如果文件系统负责在磁盘上实际存储数据,那么这是合理的。但文件系统(特别是虚拟文件系统)除了在块设备上存储文件之外,还可用于许多目的。这样的文件系统仍然在内核中运行,其代码因而要经受内核开发者提出的严格质量要求的考验。但也提出了各种标准方法,使得编写此类文件系统更为容易。
一个小的文件系统库libfs,包含了实现文件系统所需的几乎所有要素。开发者只需要提供到其数据的一个接口,文件系统就完成了。
此外,还有一些以seq_file机制提供的标准例程可用,使得顺序文件的处理毫不费力。最后,开发者可能只是想要向用户空间导出一两个值,而不想和现存的文件系统(如proc)打交道。内核对此也提供了一种方案:debugfs文件系统允许只用几个函数调用,就实现一个双向的调试接口。
顺序文件seq_file 系统
- 顺序文件
换言之,文件物理结构中记录的排列顺序和 文件逻辑结构中记录的排列顺序一致。- 操作特点
1、顺序文件是根据 记录或序号的相对位置 来进行存取的文件组织方式
2、便于进行 顺序存取,不便于进行 直接存取。若要取 第 i 个记录,必须先读出 前 i-1 个记录 ,对于 等长连续记录文件 可以进行 折半查找(因为文件序号是有序的)。
3、插入新的记录时只能加在 文件末尾 。
4、删除记录不是真正的删除,只是对该条记录做一个特殊标记。
5、更新文件中的某个记录,则必须将 整个文件 进行复制,生成 新的文件。
在讨论任何文件系统库之前,我们都需要看一看顺序文件接口。小的文件系统中的文件,通常用户层是从头到尾顺序读取的,其内容可能是遍历一些数据项创建的。这些数据项,举例来说,可能是数组元素。内核从头到尾遍历整个数组,对每个数组项创建一个文本表示。翻译成内核的术语,我们可以将其称之为根据记录序列来合成文件。
fs/seq_file.c中的例程容许用最小代价来实现此类文件。不论名称如何,但顺序文件是可以进行定位(seek)操作的,但其实现不怎么高效。顺序访问,即逐个读取数据项,显然是首选的访问模式。某个方面具有优势,通常会在其他方面付出代价。
kprobe机制包含了到上述debugfs文件系统的一个接口。一个顺序文件向用户层提供了所有注册的探测器。我将讲解kprobe的实现,来说明顺序文件的思想。
编写顺序文件
顺序文件处理程序基本上,必须提供一个struct file_operations的实例,其中一些函数指针指向一些seq_例程,这样就可以利用顺序文件的标准实现了。kprobes子系统的做法如下:
kernel/kprobes.c
static struct file_operations debugfs_kprobes_operations = {
.open = kprobes_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
};
唯一需要实现的方法是open。实现该函数不需要多少工作量,简单的一行代码就可以将文件关联到顺序文件接口:
static struct seq_operations kprobes_seq_ops = {
.start = kprobe_seq_start,
.next = kprobe_seq_next,
.stop = kprobe_seq_stop,
.show = show_kprobe_addr
};
static int __kprobes kprobes_open(struct inode *inode, struct file *filp)
{
return seq_open(filp, &kprobes_seq_ops);
}
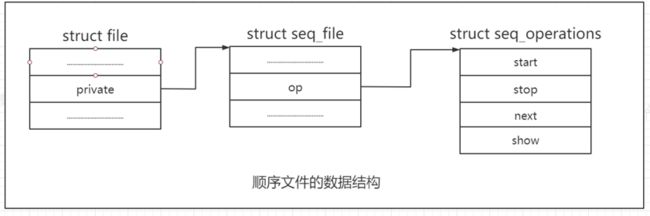
seq_open建立顺序文件机制所需的数据结构,结果如图10-8所示。回忆第8章的内容,struct file的private成员可以指向文件私有的任意数据,通用的VFS函数不会访问该数据。在这里,seq_open使用该指针建立了与struct seq_file的一个实例之间的关联,struct seq_file中包含了顺序文件的状态信息:
struct seq_file {
char *buf;
size_t size;
size_t from;
size_t count;
size_t pad_until;
loff_t index;
loff_t read_pos;
u64 version;
struct mutex lock;
const struct seq_operations *op;
int poll_event;
const struct file *file;
void *private;
};
buf指向一个内存缓冲区,用于构建传输给用户层的数据。count指定了需要传输到用户层的剩余的字节数。复制操作的起始位置由from指定,而size给出了缓冲区中总的字节数。index是缓冲区的另一个索引。它标记了内核向缓冲区写入下一个新记录的起始位置。请注意,index和from的演变过程是不同的,因为从内核向缓冲区写入数据,与将这些数据复制到用户空间,这两种操作是不同的。
从文件系统实现者的角度来看,最重要的成员是指针op,它指向seq_operations的一个实例。这将通用的顺序文件实现与提供具体文件内容的例程关联起来。内核需要4个方法,这需要由文件提供者实现:
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};
这些函数的第一个参数总是所述的seq_file实例。每当对一个顺序文件开始一个操作时,都调用start方法。位置参数pos是文件中的一个游标,其语义由实现解释。它可以作为字节偏移量使用,也可以解释为数组索引。kprobes实现了所有上述这些例程。
使用libfs编写FS
libfs是一个库,提供了几个非常通用的标准例程,可用于创建服务于特定用途的小型文件系统。这些例程很适合于没有后备存储器的内存文件。显然,libfs的代码无法与特定的磁盘格式交互。这需要由完整的文件系统实现来正确处理。该库的代码包含在一个文件中,即fs/libfs.c。
libfs是一个库,提供了几个非常通用的标准例程,可用于创建服务于特定用途的小型文件系统。函数原型定义在中,没有头文件!libfs提供的例程通常带有前缀simple_。使用libfs建立的虚拟文件系统,其文件和目录层次结构可使用dentry树产生和遍历。
其simple_dir_operations数据结构源码如下:
const struct file_operations simple_dir_operations = {
.open = dcache_dir_open,
.release = dcache_dir_close,
.llseek = dcache_dir_lseek,
.read = generic_read_dir,
.readdir = dcache_readdir,
.fsync = simple_sync_file,
};
普通文件不能使用libfs的file_operations模板。至少要手工指定read、write和open方法,这是必需的。 read负责从内核内存准备数据并将其复制到用户空间,而write可用于读取用户的输出并以一定方式应用它。文件系统还需要一个超级块。懒惰的程序员应当感恩,libfs提供了simple_fill_super方法,可用于填充给出的超级块。
一个struct tree_descr的数组用来描述初始的文件集合。该结构定义如下:
struct tree_descr {
char *name;
const struct file_operations *ops;
int mode;
};
name表示文件名,ops指向相关的文件操作,而mode指定了访问权限位。
调试文件系统
使用了libfs函数的一个特别的文件系统是调试文件系统debugfs。它向内核开发者提供了一种向用户层提供信息的可能方法。这些信息并不会编译到产品内核中。它只是开发新特性时的一种辅助手段。仅当内核编译时启用了DEBUG_FS配置选项,才会激活对debugfs的支持。因而向debugfs注册文件的代码,都会被C预处理器条件语句包围,来检查CONFIG_DEBUG_FS。
伪文件系统
内核支持伪文件系统,其中收集了一些相关的inode,但不能装载,因而对用户层也是不可见的。libfs也提供了一个辅助函数,来实现这种特殊类型的文件系统。 内核使用了一个伪文件系统来跟踪表示块设备的所有inode:
fs/block_dev.c
static int bd_get_sb(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data, struct vfsmount *mnt)
{
return get_sb_pseudo(fs_type, "bdev:", &bdev_sops, 0x62646576, mnt);
}
static struct file_system_type bd_type = {
.name = "bdev",
.get_sb = bd_get_sb,
.kill_sb = kill_anon_super,
};
代码看起来类似于普通的文件系统,但libfs提供的get_sb_pseudo方法可以确保不能从用户空间装载该文件系统。这很简单,只需要设置MS_NOUSER标志。另外,还填充了一个struct super_block的实例,并分配了伪文件系统根目录的inode。
为使用伪文件系统,内核需要使用kern_mount或kern_mount_data装载它。它可用于收集inode,而无需写一个专门的数据结构。对于bdev,所有表示块设备的inode都群集起来。但该集合只能从内核看到,用户空间无法看到。