晴天学长小日子
大家好,我是你们的晴天学长,在日常的生活中,总是有些突如其来的灵感想记录下来,这篇小日子就是我在生活中的小灵感!
2022/10/29
天气:阴
1 ). 学习心得
- trunk解决的是跨交换机的同一vlan之间的通信,而不是不同vlan之间的通信
- 路由表的更新
A.改成邻居的名字并加一,并改成邻居的名字。
B.相同更新最新的,不同的选最短的。 - for-each循环的运用
A.格式:
for (int j : N
) {
System.out.print(j+" ");
}
B.是把N中的元素依次赋值给int j 去接收。
2 ). 小日子
- 今天要录制河工比赛的讲解视频,任务量不小呢!
2022/11/1
天气:阴
1 ). 学习心得
- 计算机网络:
1.RIP协议用的UDP(不可靠),每30秒发一次,最大距离为15,16为不可达。
2.OSPF协议用到IP数据报(可靠)。
3.网络层是主机到主机之间的逻辑通信。
4.传输层是端口到端口之间的通信。 - 4级:21版的6月。
- 算法
一个五位或者六位的十进制数(回文数),满足各位数字之和等于n,并从大到小的输出这个数。
1.先在五位数中找
A.又是回文数并且数字之和加起来等于n
B.三位数里找,后两位跟前面一样
12321
2.后在六位数中找
A.又是回文数并且数字之和加起来等于n
B.三位数里找!
123321
注意从小到大!! - ArrayList是一个可变化长度的数组队列
2 ). 小日子
- 今天和女朋友去教室学习!!
2022/11/5
天气:晴
1 ). 学习心得
- 1.3个实验报告
- 2.IP地址和子网掩码进行与运算,结果是网络地址(即主机号全0是网络地址)
- 3.B类子网的划分?
- 4.算法(杨辉三角形)
1.创建一个二维数组,并用循环去给列复制
2.数组的首位和末尾是1,其他的是上一排的前一位加上上面位置的哪一位。
3.格式化输出
2 ). 小日子
- 要提前放假了==
2022/11/6
- 天气:晴
- 算法(1)
方法1:二维数组
1.建立一个大小为32行,5列的二维数组。
2.从最后一位开始每次加一,然后进行判断,逢2进一,用到
%2 = ;(该位是啥)
/ 2 = ;(下一位是啥);
3.打印二维数组(用for循环)。
方法2:一位数组
与上题方法类似,主要区别是判断一次就打印一次。
方法3:字符串的拼接
1.设立初值0,判断位数
2.用两个for循环,一个控制大小,一个检查字符串的大小。 - 算法(2)
1.n行,每一行表示要转换的字符串。
2.用for去接收到一个数组N
3.用for去循环数组的元素,并输出他们的8进制数
2 ). 小日子
- 转进制Java虽然有进制转换的类但是数据太大,不能用。
2022/11/12
1 ). 学习心得
- VPN和NAT技术
1.VPN是虚拟局域网,使两个主机处在同一局域网,不管距离多远。
2.NAT使本地地址转换为全球唯一的IP地址。 - 域名和IP地址
1.域名是为了方便人们的记忆而规定的一种规范,与IP地址一一对应
2.域名系统DNS(用的递归(本地服务器和根域名服务器)和迭代查询)
www.hait.edu.cn(学校官网) - 邮件发送协议:FTP
邮件读取协议:POP3 和 IMAP - DHCP(简答题)
向主机动态分配IP地址及其相关信息。
DHCP报文采用UDP封装。
2 ). 小日子
- 参加了4个小时的蓝桥本的模拟赛。
2022/11/15
1 ). 学习心得
应用层:产生网络流量的程序
表示层:传输之前是否进行加密或者压缩处理
会话层:查看会话,查木马 netstat-n
传输层:可靠传输、流量控制、不可靠传输(报文)
网络层:负责选择最佳路径、规划ip地址(数据报)
数据链路层:帧的开始和结束、透明传输、差错校验(帧)
物理层:接口标准、电器标准、如何更快传输数据(比特流)
-
网络层:点到点
-
传输层:端到端
-
TCP的参考模型
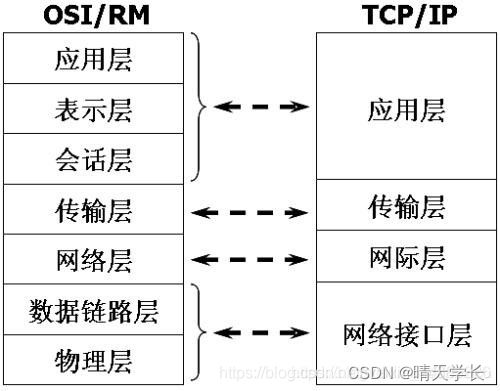
-
表示层:加密功能
-
SPX是OSI模型中的传输层
-
局域网中CSMA/CD:发前先听,边发边听,冲突停止,随机重发
-
WIFI局域网:CSMA/CA :通过信道预约机制,ACK机制等来避免冲突的发生。
-
CSMA/CD是指带冲突检测的载波侦听多路访问,CSMA/CA 是指带冲突检测的载波侦听多路访问。首先,两者的应用场景不同,CSMA/CD主要应用于冲突检测相对较容易的以太网等介质,CSMA/CA主要应用于存在隐藏站等问题的无线网络中;其次,两者的着眼点不同,CSMA/CD主要通过在发送数据前进行信道检测,空闲时才发送,发送数据时检测信道一旦冲突立马停止发送并发送一个短的冲突信号帧,不能避免冲突的发生;CSMA/CA主要通过信道预约机制、RTS-CTS机制、ACK机制来尽量避免冲突的发生,但不能完全避免冲突的发生。最后,冲突发生以后,两者都使用二进制指数退避算法来选择时机重发信息。
2 ). 小日子
- 这周有两个答辩!!!
2022/11/16
1 ). 学习心得
- 第二范式
2NF 定义:R 是1NF,且每一个非主属性完全函数依赖于任何一个候选码,则 R 是第二范式。
一个表只能保存一种数据,消除部分函数依赖,不可以把多种数据保存在同一张表上。 - 第三范式
若R∈3NF,则每一个非主属性既不部分依赖于码也不传递依赖于码。
通过外键建立表间的联系。
范式的总结
2 ). 小日子
- 周末还有传智杯的模拟赛。
2022/11/17
1 ). 学习心得
- IPV4的缺点
- IPV6的优势
- 掩码最长匹配原则
当路由器收到一个IP数据包时,会将数据包的目的IP地址与自己本地路由表中的表项进行bit by bit的逐位查找,直到找到匹配度最长的条目,这叫最长匹配原则。
下面我们总结一下路由器关于路由查找的几个重点内容: - 不同的前缀(网络号+掩码,缺一不可),在路由表中属于不同的路由
相同的前缀,通过不同的协议获取,先比AD,后比metric
这是一般情况,当然有二般情况,这就要看特定的环境和特定的路由协议了
默认采用最长匹配原则,匹配,则转发;无匹配,则找默认路由,默认路由都没有,则丢弃
路由器的行为是逐跳的,到目标网络的沿路径每个路由器都必须有关于目的地的路由
数据是双向的,考虑流量的时候,要关注流量的往返。
A.无分类编址CIDR
消除了传统的A类,B类和c类地址以及划分子网的概念。
B.融合子网地址与子网掩码,方便子网划分。
C.CIDR记法:IP地址后加上/,然后写上网络前缀(可以任意长度)的位数。
IP地址=网络前缀+主机号
eg:128.14.32.0/20(前20bit位是网络前缀)
- 最长前缀匹配:
使用CIDR时,查找路由表可能得到几个匹配结果(跟子网掩码按位相与),应选择具有最长网络前缀的路由。前缀越长,地址块越小,路由越具体。 - Mac地址多少位(48位(6个字节))
- IPV6
一个16进制由4个二进制组成。 - 本地链路地址怎么生成(考试题)
2022/11/20
1 ). 学习心得
明天早上学习到ppt的内容:
1.MVVM思想
2.dom对象
3.通过浏览器的检查按钮去调节自己想要的样式
4.下午的传智杯模拟赛(复习格式的准换,向上或者向下)
// 向上取整。
System.out.println(Math.ceil(target));
// 向下取整。
System.out.println(Math.floor(target));
5.按位异或
计算方法:
参加运算的两个数,换算为二进制(0、1)后,进行异或运算。只有当 相应位上的数字不相同时取1, 相同为0。
2 ). 小日子
今天两个答辩啊
2022/11/17
1 ). 学习心得
- IPv6的基本首部长度为40个字节IPv4为20到60字节,可变
- IPV6中的一般中间路由器不处理首部长度,除非遇到逐跳选项
- IPv6的本地链路地址的生成
1.前64位地址:前64位地址是固定的,为FE80::,
2.后64位地址:把mac地址换算成二进制,在mac地址中间插入FFFE,然后将第七位取反,这样就得到了后面的64位地址;
3.将前64位地址和后64位地址整合在一起 - ARP协议:根据IP地址解析MAC地址
- URL:统一资源定位符
- IPv6地址分类
- 候选码
1.划分L,R,LR,N
L和N肯定是候选码中的。
2.看LN用闭包判断是否能推出全部。
3.不能的话,分别与LR中的元素组合,看是否推出全部,推出全部就是候选码
2022/11/24
1 ). 学习心得
- 计算机网络考试题
大题:
1.DNS
2.Ipv6本地链路
3.CSMA-CA和CD的工作原理
4.滑动窗口机制(学习通上,再总结)
5.计算器网络拓扑结构的分类及其特点(5种)
6.网络安全涉及的技术:
(1).报文鉴别,证明来源
报文完整性,防伪证
不可否认性,防否认
(2).消息认证(message authentication)就是验证消息的完整性,当接收方收到发送方的报文时,接收方能够验证收到的报文是真实的和未被篡改的。它包含两层含义:一是验证信息的发送者是真正的而不是冒充的,即数据起源认证;二是验证信息在传送过程中未被篡改、重放或延迟等。
(3).通过加密算法和加密密钥将明文转变为密文,而解密则是通过解密算法和解密密钥将密文恢复为明文
(4).防火墙的原理是指设置在不同网络(如可信任的企业内部网和不可信的公共网)或网络安全域之间的一系列部件的组合。它是不同网络或网络安全域之间信息的唯一出入口,通过监测、限制、更改跨越防火墙的数据流,尽可能地对外部屏蔽网络内部的信息、结构和运行状况,有选择地接受外部访问,对内部强化设备监管、控制对服务器与外部网络的访问,在被保护网络和外部网络之间架起一道屏障。 - 计算题
1.子网划分
2.路由更新的距离矢量算法(81到83)和范围。 - 知识点:
1.数据通信方式(17)
2.多路复用三个技术(24)
3.数据交换技术(27)
三个方式的优缺点。
4.调试解调器(19)
所谓调制,就是把数字信号转换成电话线上传输的模拟信号;解调,即把模拟信号转换成数字信号。合称调制解调器。
5.TCP/UDP是传输层
6.MAC是在数据链路层
7.交换器和集线器的区别
8.局域网中,和主机相连的是非屏蔽双绞线
9.逐跳选项
10.路由器要写,主机不写 (no shut down)
2 ). 小日子
要期末考试了
2022/11/29
1 ). 学习心得
1.笛卡尔积X:R表中的每一行都与S表中的每一行组合一次 R X S
2.等值连接不去除重复项,自然连接需要。
3.除运算:被除数找相同的元组,把相同的去掉,剩下的元素合并。(46页)。
4.建表看一下(79),enum。
5.外键的建立
constraint 外键名字 foreign key (字段名) referernces 主键位置。
6.索引
create index 索引名 on 表名
7.触发器
create trigger 触发器的名字
before insert
on 表名
for each row
begin
if then
end if;
end;
8.第二范式
2NF 定义:R 是1NF,且每一个非主属性完全函数依赖于任何一个候选码,则 R 是第二范式。
一个表只能保存一种数据,消除部分函数依赖,不可以把多种数据保存在同一张表上。
第三范式
若R∈3NF,则每一个非主属性既不部分依赖于码也不传递依赖于码。
通过外键建立表间的联系。
9.数据操纵功能是指数据的查询,添加,删除,修改。
10.候选码的求法
(1).划分L,R,LR,N
L和N肯定是候选码中的。
(2).看LN用闭包判断是否能推出全部。
(3).不能的话,分别与LR中的元素组合,看是否推出全部,推出全部就是候选码
11.事务的特性:原子性,一致性,隔离性,持久性。
12.实验报告
(1).升序 asc
降序desc
(2).查询
条件查询(WHERE)
聚合函数(count、max、min、avg、sum)
分组查询(group by)
排序查询(order by)
(3)is exists
(4)报告中的查询
(5)视图
create view 视图名字 as
(6)去重 distinct
2 ). 小日子
- 46级又取消了。
- 王的50
2022/12/11
1 ). 学习心得
算法
一.最小的2022
1.substring的用法
2.字符串的对比用equals
二.经过天数
1.算出闰年和不是闰年的个数
2.闰年乘以366,不是闰年乘以355
3,加起来再家伙加上92
三.特殊的数
1.从10开始,一次递增
2.看成16进制,再转化为10进制,看是否满足是自己的整数倍
3.输出
注意,初始化的值一定不要放在循环里面
四.最长的矩阵和(动态规划)
1.数字输入格式
五,拆分质数
1.从最小的开始拆,从1开始增加
2.判断是不是质数,是的话sum++,n++;
3.如果sum>2022,就输出n;
注意:
1.只初始化一次的在开头。初始化很多次的在循环
2.质数的定义,1不是质数(除了1和此整数自身外,不能被其他自然数整除的数)
六.拷贝文件
1.接收数据,先算拷贝的速度
2.剩下的文件/速度,需要整数输出
注意:精度和输出格式的问题
七.去除重复的单词
1.接收一个整数n,把接下来的数据输入到一个字符数组N中
2.创建一个Arraylist List ,循环N,当List没有的时候,add进去
3.最后遍历List
八.
1.接收字符串,建立一个ans的StringBuffer数组
2.第一个和最后一个对比,没有就ans连接上
有就跳过.
2 ). 小日子
- 成都生活之旅开始啦
2022/12/22
1 ). 学习心得
1.一个包中只能有一个公共类,但类中可以很有多个公共方法。
2.break只是跳出了本循环,但如果是多重循环的话,要直接结束,要用return。
3.Math.max(a,b)返回最大的那个值
4.贪心必排序
5.Arrays.sort(a, 0, n);只排序下标为0到n的数
6.要有回馈感,多去参加比赛(每周的)和写博客
7.求余
8.前缀和+双数组+二分(省一基底)
2 ). 小日子
- 耶!今天我生日,出去吃好的。
2022/12/31
1 ) 学习心得
1.前缀和就是前面的和
2.判断素数,有一个数学结论,只循环到i=2到根号n就行(如果要是合数,一定有一个小于等于根号n的质因数)
3.埃氏筛法(输出最小素数,删除它的倍数),用于筛选素数
4.欧拉筛法(推荐)
5.求最后几位,用取余
比如后5位,100000
6.String s=Integer.toString(int n,int r);//转化为 r 进制,r 的范围[2,36]
int n=Integer.parseInt(String s,int r);//将 r 进制的字符串 s 转化为十进制
7…toUpperCase()将结果的小写字母写成大写字母
8.快输和快读
2 ). 小日子
- 今年的最后一天啦,希望明年能不负韶华!勇往直前!去北京参加蓝桥杯全国总决赛!
2023/1/4
1 ) 学习心得
1.异或^(相同的位数上,不相同为1,相同为0)
2.按位与&(相同的位数上,两个为1才为1,其他全是0)
3.break是结束循环,continue是结束本次循环,进行下次循环。
4.int ans = Integer.bitCount(n); 二进制中1的数量
5.位运算 >> << 比如:1001 >>=1 之后就是100 ,所以就是乘以2或者除以2的问题。
6.贪心有前缀和和排序。
7.定义最大最小值,用题目的最大最小的范围。
8.字符数组统计的排序
9.字符数组变成字符串。
10.双指针:双指针之间的赋值。
2 ). 小日子
- 蓝桥杯省赛时间确定啦!冲冲冲!
2023/1/6
- 动态规划问题就是一堆简单的子问题的集合
- 双指针
1.for初始i,j (i的条件)
2.while定位j(j的条件)
3.题目要求
4.i=j+1(下标传递) - 最大公约数(递归:一个大问题的解转化一个小问题的解,有点像dp的儿子,哈哈哈)
a>b
return b==0? a:gad(b,a%b); (递归思想)
四.最小公倍数
1.等于a*b除以最大公约数 - 向下取整
需要的都是double类型的,因为int没有小数点的计算.
2 ). 小日子
- 天气晴起来了!
2023/1/10
1 ) 学习心得
一.动态规划问题就是一堆简单的子问题的集合
二.双指针
1.for初始i,j (i的条件)
2.while定位j(j的条件)
3.题目要求
4.i=j+1(下标传递)
三.最大公约数(递归:一个大问题的解转化一个小问题的解,有点像dp的儿子,哈哈哈)
a>b
return b==0? a:gad(b,a%b); (递归思想)
四.最小公倍数
1.等于a*b除以最大公约数
五.向下(向下)取整
需要的都是double类型的,因为int没有小数点的计算,所以要通过除以3.0来转换 类型,然后最后强转回去,因为向上取整已经是列如3.0了,所以强转回去不影响。
(int) Math.ceil(max/3.0));
(int) Math.floor(max/3.0));
六.平时的除数取余法是从第二位的位权开始的(因为所有数的零次方都是零),整除不了的,就是前一位数乘以该位的位权。
六.堆
大顶堆
小顶堆
七.优先队列:元素被赋予优先级,当访问元素时,具有最高级优先级的元素先被访问。(比如大顶堆和小顶堆)
八.队列
队列是一种操作受限的线性表,只允许在表的前端(front)进行删除操作又称作出队,在表的后端进行插入操作,称为入队。
九.队列的基本用法
十.当用API转换进制的时候麻烦的时候,可以考虑用取余(r进制)除数(r进制)法来与题意相结合。
十一.模拟 + 枚举法
2 ). 小日子
欧耶!字节跳动青训营后端专场进去啦
2023/1/10
1 ) 学习心得
1.a &(a-1)==0 作用是把最后最后一位1变成0,可以用在统计1的个数和是否是2的倍数
2.能被2整除,那二进制中只有1个1,其他都是零
3.异或减
x^x= 0 x^0=0
异或就是减
可以用在找不同或者找相同的题目中。
- 两个值,要想取到两个值乘以下标的最大值ans,就要把最大值放在后面。(结论,这样会让ans大于等于其他的情况,贪心思想)。
2 ). 小日子
- 开始学习Git了
2023/1/15
1 ) 学习心得
1.a &(a-1)==0 作用是把最后最后一位1变成0,可以用在统计1的个数和是否是2的倍数
2.能被2整除,那二进制中只有1个1,其他都是零
3.异或减
x^x= 0 x^0=0
异或就是减
可以用在找不同或者找相同的题目中。
- 两个值,要想取到两个值乘以下标的最大值ans,就要把最大值放在后面。(结论,这样会让ans大于等于其他的情况,这就是贪心)
5.git有缓存区,可以删除,然后再提交到本地库形成历史版本
2 ). 小日子
- 即将过年咯!
2023/1/21
1 ) 学习心得
12/25
1GB=1024MB
1MB=1024KB
1KB=1024Byte(字节)
1Byte=8bit(位)
1.最大公约数的含义:可以求几个不同的数中都有的那个值的最大值
2.唯一分解定理:任何大于1的自然数,都可以唯一分解成有限个质数的乘积(它的质因子大于根号n的要不没有,要`不就只有一个。
3.质因数是什么:
4.判断是否为质数2循环到i<=n/i就行,因为后面的数都能被前面整除,
5.素数和质数一样的
6.约数和因数一样的
- 对于任意一个正整数数n, 最多只包含一个大于sqrt(n)的质因子
//证明过程:
//反证法,如果存在两个的话,这两个质因数相乘,结果必然大于n,与实际情况不符,因此只有一个。
比如36,根号36就是6,大于36的就只能有1个,就是12。
8.欧拉筛(线性筛):每个合数只被最小的质因数筛掉
时间复杂度为O(n),遍历数组,是素数的添加进去,不是素数的,首先遍历素数数组,标记乘以素数数组的数,如果能被素数数组中整除,就break;
9.标记数组的运用,能在循环中对另一个下标相同的数组进行是否进去执行语句的操作
(质数一类的题经常使用)
10.!st[j]是false才能进去循环
11.质数循环建立数组都要比条件的大一些,并且条件一般都是i<=n ,要取到n
2 ). 小日子
- 新年快乐!!
2023/2/5
1 ) 学习心得
1.求解质因数的时候,为什么n%i==0一定是一个质数(并且一定是它的质因数之一),看n,因为i是个合数的话,已经在前面了,所以只有是一个新的质数才能整除!!!!切记,合数的含义,
2.记得质因子最后n大于1的时候,还有一个
3.对于数据量比较大的题,直接用long,避免爆掉(范围大就开long)
4.求余等于除(只是看能不能整除),有些题的乘积很大,所以要在循环里面去乘
5.判断复杂度O(n)是个好习惯
6.质数的预处理
7.唯一分解定理还可以用于判断几个零(2和5的个数)
8.二分复杂度(logn)用于一段二段性的范围中找到特定条件的需求
9.n的阶乘中质因子p的个数(就是看p的倍数在n中有几个)
从p的角度去考虑,依次判断p,p2,p3,…这些个p的倍数在1~n中的质因子的贡献
10.二分的书写(找中间的那个二段性的临界值,范围要开大一些)
2 ). 小日子
- 即将开学。
2023/2/6
1 ) 学习心得
1.&&逻辑与 ||逻辑或 它们都是逻辑运算符
& 按位与 | 按位或 它们都是位运算符
2.(a == ‘a’ || a == ‘e’ ) &&( b == ‘a’ || b == ‘e’)
&&记得打括号,才是一体的。
要是太多的话,可以写成set
3.前缀和之子数组的差
[1,0,1,1,0]
如果2到4就等于4为底的前缀和减去1为底的前缀和(d减去c-1)
当0到2
这时候要注意小标为0的情况,这是一个完整的以d为底的子数组
4.小顶堆和大顶堆的运用
PriorityQueue 优先级队列
5.一个字节等于8位
int 4个字节32位 十进制的范围是10位
long 8个字节64位 十进制的范围是19位
6.判断质数和质因子循环的范围都是i<=i/n
7.统计质数是要到n的
埃氏先 i
8.注意循环中,符合条件的语句都要放在if语句中,不然会出现不符合条件的也会执行语句的情况
9.约数定理和约数和定是再循唯一分解定理之后的。
2 ). 小日子
- 靠自己了!
2023/2/15
1 ) 学习心得
1.最小的最大值,最大的最小值,想到跟二分有关
2.二分中(我的左开右闭区间)
中间值符合条件的(>=)不±1,不符合的需要±1,找到那个有二段性的临界下标。
3.二分还要考虑找不到那个二段性的可能,l就会等于数组长度
4.新变量x,y可以用于循环中重复定义的变量
5.二分运用的真的很多,有些题很隐晦,但是确实要用
范围单调性找二分
2 ). 小日子
- 明天开学!
2023/2/25
1 ) 学习心得
1.n的阶乘中,质因数p的个数。(不是唯一分解定理,是算p的倍数在n中有几个)
2.一个数中,质因子p的个数(唯一分解定理)
3.$ 是用gitbash下载的
4.round是取int的,但floor和ceil是double类型的
5.n&-n应用:
求能被2的次方整除的最大数,如:
96/32(2^5)=3,所以96&-96=32;
19/1(2^0)=19,所以19&-19=1
负数的二进制:
1.是正数的补码
先把正数反码,在补码(加个1)
所以就是正数的二进制其他都是反的,就最后一位是相同的
10: 0000 1010
-10: 1111 0110
n&-n 就是获取到正数二进制n的最后一个1
,注意不是1,是0010(2)或者0100(8)
6.想到二分就研究它的二段性:一边满足,一边不满足
7.二分有一个特点
最大值,最小值,我直接取判断不好判断的,但我可以去判断某个值是否符合,mid新升级。
8.二分法当左面满足,右面不满足时候,就反过来就行,就是不满足的-1了,并且mid = (r-l)/2+l+1。
9.我的二分法有两种形态,注意区分
左不满右满有一个点(不满足的+1)
左满右不满足有两个点(不满足的–1,并且
每次mid = (r-l)/2+l+1)。
10.我的左闭右开二分法最后的下标都是在满足的临界点那边。
11.数组的大小不能是long,只能说int,所以就强转一下,也不奇怪
12.二分要考虑一下查找范围有没有的问题
13.最大值和最小值就设为最不可能的数
14.进制转换都是Integer,类型一个String,一个Integer。
15.S = S.replaceAll(String.valueOf(s),“9”);
max = Integer.parseInt(S);
2 ). 小日子
- 加油就是淦!! 我命由我不由天!
2023/3/1
1 ) 学习心得
1.括号()控制优先级。
2.字符串行输入方式
String[] s = sc.nextLine().split(" ");
- 取模的性质(理解为除法一样)
4.大整数只能和大整数进行计算或者比较
5.要能想到用二分啊!!能否用二分,二段性很重要,算法没事就想到3大件。
6.有难度的题,二分只是一个其中的突破点,研究它的二段性才是最重要的
7.算法成对要从中间劈开(因为最多有length/2=k对),不能用二分去研究那个临界值,可能会越过中间,导致答案错误,这时取对半刚好是右边那半第一个的下标。e
8.一般情况下,题目答案不是很明确的在原来的数组上,都是要重新以题目范围开一个研究二段性的答案k。
9.ArrayList list = new ArrayList<>();
2 ). 小日子
- 流感来咯!冲,加油!!
2023/3/15
1 ) 学习心得
3.快读就是一排一排的读入数据,再去覆盖字符串数组
4.二维矩阵的前缀和,数组的大小都要+1
5.快读单独做笔记
- List list = new ArrayList<>();
Queue queue = new LinkedList();
7./ 代表根目录
./ 代表当前文件所在目录(可省略)
…/ 代表当前文件所在目录的上级目录
8.DFS(结束条件,补丁,答案)
1.出口
2.剪枝(补丁)
3.开枝散叶(for循环表示叶子的值)
9.BFS(比较推荐)
1.初始条件入队(用for)
2.首元素出队
3.补丁
4.判断是否开花散叶(for循环表示叶子的值),压入队尾,否则就输出。 - eclipse控制台中文输出乱码解决方法
1.运行->运行配置
2.公共->手动输入gbk
11.DFS和BFS或者二维数组的题其实都需要枚举,找到题目最后的答案。
12.题目已给的矩阵,直接建立一个字符串数组就行。
13.Step over(F6):单步调试,进入下一行代码
14.删除最后一个字符
ans = ans.substring(0, ans.length() - 1);
15.回溯相当于悔棋,重新以新的方式去下
2 ). 小日子
- 开始学Bfs和Dfs了,加油!
2023/3/23
1 ) 学习心得
1.绝对差值=最大值减最小值
2.反向广搜,起始点为终点,然后向其他点走,走到某个点的步数就是该点到终点的步数,注意,这样搜索必然是最短路径,因为BFS有最短路效应。
3.map空指针的问题不想写复杂的,就判断一下是否为空,在设置一下初值,思路更清晰一些
4.
a.static Map
b.List list = new ArrayList<>();
c.if (!map.containsKey(x1 * n + y1)) map.put(x1 * n + y1, new ArrayList<>());
Map可以存链表,链表也可以存数组为单位的元素。
5.二维数组的映射技巧,可以把一个二维的两个坐标变成一个唯一的值。(二维坐标有规律的情况下),公式x*m+y,适用于判断是否为同一个坐标,前提必须是0.0开头,不是的话要把接收的数据-1,-1(1.1开始的);
6.
PriorityQueue pq = new PriorityQueue<>((o1, o2) -> (o2 - o1));
7.别人定义了的数,直接拿来用就行、
8.快速建立一个数组元素
new int[]{x2,y2}
9.Map 接口中有两个常用的方法:put(key, value) 和 get(key)。
put(key, value) 方法用于向 Map 中添加元素,其中参数 key 为该元素的键,参数 value 为该元素的值。如果该键之前不存在于 Map 中,该方法将会添加新元素;如果该键之前已经存在于 Map 中,该方法将会更新该键对应的值。
get(key) 方法用于获取 Map 中与指定键相关联的值。如果该键不存在于 Map 中,该方法将会返回 null。
10.利用存储结构获取元素(不需要new)
int[] curr = queue.poll();
List
int a = curr[0], b = curr[1];
11.学姐,所以是“hashmap随机排序,treemap递增排序,linkedhashmap按输入顺序排序”对吗?
12.段错误可能是快读输入中右多个空格
13.算星期的时候,就是把星期天放在了第一位,下标为0
14.
写题之前认真看题,以及数据说明,先看题10篇
尤其是bfs,是算的层数还是,叶子的数量
并且做完之后检查,反正省一看的是正确率,
后面不是我做的就不做,也照样可以拿到省一,加油!
2 ). 小日子
- 省赛要开始了,冲!
2023/3/25
1 ) 学习心得
1.绝对差值=最大值减最小值
2.反向广搜,起始点为终点,然后向其他点走,走到某个点的步数就是该点到终点的步数,注意,这样搜索必然是最短路径,因为BFS有最短路效应。
3.map空指针的问题不想写复杂的,就判断一下是否为空,在设置一下初值,思路更清晰一些
4.
a.static Map
b.List list = new ArrayList<>();
c.if (!map.containsKey(x1 * n + y1)) map.put(x1 * n + y1, new ArrayList<>());
Map可以存链表,链表也可以存数组为单位的元素。
5.二维数组的映射技巧,可以把一个二维的两个坐标变成一个唯一的值。(二维坐标有规律的情况下),公式x*m+y,适用于判断是否为同一个坐标,前提必须是0.0开头,不是的话要把接收的数据-1,-1(1.1开始的);
6.
PriorityQueue pq = new PriorityQueue<>((o1, o2) -> (o2 - o1));
7.别人定义了的数,直接拿来用就行、
8.快速建立一个数组元素
new int[]{x2,y2}
9.Map 接口中有两个常用的方法:put(key, value) 和 get(key)。
put(key, value) 方法用于向 Map 中添加元素,其中参数 key 为该元素的键,参数 value 为该元素的值。如果该键之前不存在于 Map 中,该方法将会添加新元素;如果该键之前已经存在于 Map 中,该方法将会更新该键对应的值。
get(key) 方法用于获取 Map 中与指定键相关联的值。如果该键不存在于 Map 中,该方法将会返回 null。
10.利用存储结构获取元素(不需要new)
int[] curr = queue.poll();
List
int a = curr[0], b = curr[1];
11.学姐,所以是“hashmap随机排序,treemap递增排序,linkedhashmap按输入顺序排序”对吗?
12.段错误可能是快读输入中右多个空格
13.算星期的时候,就是把星期天放在了第一位,下标为0
14.
写题之前认真看题,以及数据说明,先看题3篇!!!
尤其是bfs,是算的层数还是,叶子的数量
并且做完之后检查,反正省一看的是正确率,
后面不是我做的就不做,也照样可以拿到省一,加油!
-
字符串转换为字符有三种解决方式:
其中number表示字符串名称,chs表示字符数组名称 1. charAt() 命令; chs[i]=number.chaAt(i); 2.substring()命令; chs[i]=number.substring(i,i+1); //将number字符串中第i个字符赋值给chs[i],i到i+1表示第i个字符到第i+1个字符,不包括第i+1个字符,且 chs 需要时string型 3、toCharArray(); char[] chs=toCharArray();
16.差分(一段区域加上某个数)
17.有时候在接收数据的时候就可以搞事情
18.英文字母是26个
19.怎么遍历hashmap
for (char key : hashMap.keySet()) {
2 ). 小日子
- 北京北京,我一定来!!
2023/3/30
1 ) 学习心得
1.乘法逆元
2.字符串的包含判定方法(字符串数组)
3.动态规划(O(n2))
a.建立表格,二维(横纵坐标),一维(最优子解的方向的问题)
b.动态规划转移方程(选和不选的问题,在比较条件,能选的话从上一排的最优子解中选)
c.填表
d.统计(看题意)
4.滚动数组
5.做题的时候,数组尽量开大一点,但也不用开太大,比实际数据多10就行,不然可能会超时
6.填空题可以暴力枚举,10个for循环也行
7.二分枚举题目给的数据或者枚举答案.
2 ). 小日子
- 干掉动规!!
2023/4/7
1 ) 学习心得
1.乘法逆元
2.字符串的包含判定方法(字符串数组)
3.滚动数组
4.二分插入
重新赋值
增加边界(r在右边界的情况)
5.dp一个重要思想
不用关心所有状态,只用关心我的上一个状态
6.三维数组的使用(可以理解为3个for循环)
7.背包问题也可以在接入数据的时候装
8.
贪心并不考虑子问题。
动规考虑。
9.bfs的开枝散叶能把所有情况都当成叶子节点(枚举一层的所有情况)
10.字符串快读用一个字符串接收,给一个字符数组
scanner用next接收。
11.参数传参逻辑问题,尤其是在for循环的时候
12.bfs的size控制一层的循环次数
13.并查集合(找根节点(路径压缩),在合并)
(1)查找根节点和路径压缩
已经是路径压缩了,每在根节点添加一次父节点的时候,下次查询就会自动更新自己的根节点。不影响,查询的都是自己的路径压缩
(3)合并
1.查找元素的集,是一个递归的过程,直到元素的值和它的集相等,就找到了根结点的集
s[i] = i(只有父节点的值是和编号一样的)
2.并查集路径压缩是指在查找某个元素的根节点时,将该元素到根节点路径上的所有节点直接指向根节点,以减小树的高度,提高查找效率。具体实现方式可以在查找时,每次找到根节点后,将路径上的所有节点直接指向根节点。
16。已经定义好的变量就不用重复去定义类型了,不然会造成空指针错误
17.temp = strings.substring(i);
substring怎么获取到字符串结尾的元素
18.最后几题骗分(暴力)就好,就是想简单点
19.hashmap很有用的(一对多的操作)
20.字符串的含于操作
a.contains(s[i])
21.贪心先想Priorityqueue(默认小顶堆)有关系
(o1, o2) -> (o2 - o1)
只能是int
22.逆向思维(对数组元素进行排序,写比较器)
23.滑动窗口(注意窗口大小和移动中数组元素的变化)
24.图论(最短路)
25.二维数组怎么存一个种类的三个元素,用二维数组的一排就好了。
26.比较器的写法(比较器的优先级)
2 ). 小日子
- 明天就是决战省赛了,一起加油吧!
2023/4/22
1 ) 学习心得
1.document.getElementById()
2.比较最大值之后
maxline=i;
max=temp;
记得最大值要更新。
3.遍历标记数组不能拿最后一位的看,会出错
,应该用continue。
4.python
列表list
元组tuple(不可替换)
字典dict
5.
** 幂运算,求一个值的几次幂
// 整除,只会保留计算后的整数位,总会返回一个整型
/ 除法运算符,运算时结果总会返回一个浮点类型
& 是and
|| 是or
a=input(‘请输入’)
6.函数
7.open函数
8.序列化和反序列化
json.dumps
9.爬虫(就是获取信息)
1.导入包
2.创建url地址
3.模拟服务器请求
4.获取响应中的页面的源码
5.打印数据
10.
urllib.request.urlopen() 模拟浏览器向服务器发送请求
urllib.request.urlretrieve()
请求对象的定制
request = urllib.request.Request()、
2 ). 小日子
- 开始学习python了,做一个爬虫高手。
2023/7/12
1 ) 学习心得
1.set输出要转化为list
2.分配问题,刚刚好,考虑是不是进制转换的问题
3.list怎么转数组
4.进制运算中,可以用大整数的技巧实现不同进制的运算
5.字符串的删除操作
6.字符串的回文数判断
7.方案数的复习,dfs
8.解题思路:将数字转化为字符串,按照索引下标从小到大(从左往右)进行分割。每次遍历中切下一刀,获取当前分割所得到数字串(前半段),剩余的字符串(后半段)继续递归搜索。
剪枝:如果当前分割得到的数字,加上前面累加计算得到的结果sum后,超出了 i ,那么说明当前这一刀分割后,累加统计得到的结果已经超出了i的大小范围,因此后面的位置都不需要再进行分割。
举例:25×25=625。第一刀分割后得到62,而此时62大于25,因此无论是继续拿剩下数字串的5进行dfs递归,还是往后遍历第一刀切的位置(在5后面得到625),所得到的结果肯定都比62大,因此剪枝。
2 ). 小日子
- 眨眼间那么久没有更新了,这个假期要继续冲啊!
2023/7/12
1 ) 学习心得
1.平时写业务代码,Java那遇到分割的情况,也就是按空格或逗号来分割,比如
String[] asp1 = “one two three”.split(" “); //能出来正常的结果[“one”,“two”,“three”]
String[] asp2 = “one,two,three”.split(”,"); //能出来正常的结果[“one”,“two”,“three”]
都是能正常跑出来的。
2.按照示例1 用点号来分割
String[] asp3 = “one.two.three”.split(“.”); //出来结果居然是个空数组
3.然后评论区告诉我说,Java的split传的参会看作正则,然后我看了下Java的split函数源码上的注释,说是 围绕给定正则表达式的匹配拆分此字符串。
4.然后我去搜了下 asp2、asp3为什么得到的结果不同?得知
5.使用逗号 , 作为分隔符。逗号被视为普通字符而非正则表达式的一部分,因此字符串 “one,two,three” 会按逗号进行拆分
6.使用点号 . 作为分隔符。然而,在正则表达式中,点号 . 有特殊的含义,表示匹配任意字符。因此,这里需要对点号进行转义。由于 Java 字符串中的反斜杠 \ 是一个转义字符,
所以我们需要使用双反斜杠 \ 进行转义。因此,正确的语法应该是 split(“\.”)
String[] asp1 = “one two three”.split(" “); //能出来正常的结果[“one”,“two”,“three”]
String[] asp2 = “one,two,three”.split(”,“); //能出来正常的结果[“one”,“two”,“three”]
String[] asp3 = “one.two.three”.split(”.“); //出来结果居然是个空数组
String[] asp4 = “one.two.three”.split(”\.“); //能出来正常的结果[“one”,“two”,“three”]
String[] asp5 = “one,two,three”.split(”\,"); //能出来正常的结果[“one”,“two”,“three”]
2.爬虫最重要的是requests(urllib)和xpath,还有一个模拟器selenium(web应用模拟浏览器)
3.升序相加会出问题。(因为升序相加可能会出现突然比前面那个sum大的情况)
降序相加就不会出问题。(因为计算的是前缀和,可以算到每一个值,假如一个数 6 大于后面的所有的前缀和,那最大值就是6了,假如6加了前面的会变小,那最大值还是6,或者会变大当然就更好了)
4.cf中不能有包名
2 ). 小日子
- 人生漫漫,学习无岸!
2023/8/16
1 ) 学习心得
- 在一些数据量及其大的运算中,转化成数据类型会出现溢出的问题,这时要考虑可以用到字符串的运算,StringBuilder就是一个用于字符串拼接的类。
- 利用 TreeSet 获取距离最近的值
celling
floor
2 ). 小日子
- 快乐的时光总是短暂的。