锁 - linux内核锁(零)
经典博客:
- 术道经纬 - 知乎
目录:
一、铺垫知识
1、指令执行流
2、上下文
3、抢占
二、内核锁基础知识
1、为什么要用锁?why
2、锁保护什么?what
3、锁是如何保护资源的?How
三、各类锁的介绍
1、原子操作
2、spinlock
3、mutex
4、…
进程指令执行流
代码在CPU上执行的指令数据流,由一系列代码组成。可分为两大类:线程维度和中断维度
 1、cpu只要上电,就需要不停的执行指令,永不停歇,若无事可做,那就执行空指令,直到下电。cpu类似一个跑道,各个task轮流到跑道上跑。
1、cpu只要上电,就需要不停的执行指令,永不停歇,若无事可做,那就执行空指令,直到下电。cpu类似一个跑道,各个task轮流到跑道上跑。
2、用户态视角:cpu执行一个个进程或者线程,一个线程就是一个执行流。内核态视角:CPU调度执行一个个task(对应一个进程或者线程),一个task就是一个执行流。CPU就这样永不疲倦的轮换执行各个task(调度)。8个CPU,同一时刻,最多有8个执行流。
3、并发:用户态系统调用的代码编译成so,当so被多个bin链接时,运行时,就可能有多个指令执行流,就有可能分别在cpu0和cpu1上执行。宏观并行,微观串行。
4、代码是静态的,执行流是动态的,这是两个不同的视角。若只存在一个cpu,那就只有一个执行流,那就不存在微观上的并发,也就不需要锁。但我们往往使用多个cpu,因而有多个执行流,同一个代码可能在两个执行流上执行。如上图。
上下文(context)
分类:进程上下文,中断上下文(硬中断上下文、软中断上下文,不可屏蔽中断上下文)
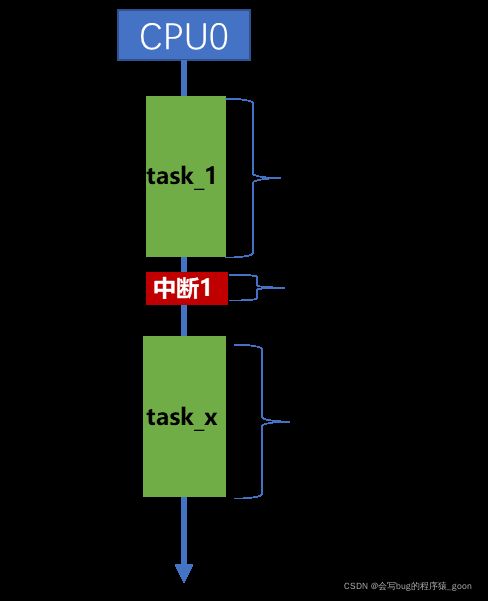
中断能够打断进程的执行流,无论进程优先级多高,都会被打断。因此原本执行流被打断,CPU转而执行中断的指令流。因此,与上下文对应,执行流也可分为:进程执行流和中断执行流
1、cpu在用户态运行时,外部中断触发,程序会先陷入内核态,保存上下文后,再执行中断代码。
2、cpu在内核态运行时,外部中断触发,保存上下文后,执行中断代码。
3、中断处理函数(中断上半部)必须要快速执行完成,以便返回继续执行各个进程。中断返回时,会发生调度,原来被打断的进程未必能够得到执行。
假设进程和中断都调用如下函数,那么就有可能出现如下场景:
进程执行流:
1、某进程执行完743行后,全局变量enable=1;
2、外部触发中断。
程序执行流:
7、从744行继续执行,此时enable变成0了。后边就会出错
中断执行流:
3、中断处理函数恰好也调用这个函数;
4、走了case1的分支,将enable又改成0。
5、中断执行完毕返回。
抢占
什么是抢占? 一张图展现
1、抢占可以分为用户态抢占和内核态抢占。抢占时机?(中断、返回用户态、主动schedule())
2、Linux kernel是抢占式内核。
为什么要使用锁?-Why
为了性能,引入了多核。
但多核导致了并发,并发就导致了争抢,为了保证争抢有序,就出现了锁。
备注:
网上关于锁的介绍的文档很多,推荐知乎兰新宇的博客
术道经纬 - 知乎
关于锁的介绍,有一系列文章,个人感觉写的非常不错,我主要从这个博客学习锁的知识。
锁保护什么?-What
锁保护的对象:公共资源。公共资源,从某一方面讲,就是全局变量,或者从堆里面申请的共用内存。
如右图内核代码:
1、锁保护的是全局变量zone(从堆上申请的)。
2、无法保护局部变量tmp和low,局部变量也不需要保护,想想这是为什么?
3、代码段不需要保护,因为它是只读的。
误区:常认为锁保护的是一段代码和变量。
其实:从保护资源的角度,锁只是为了保护全局变量,公共资源是一种更严谨的通用的说法。若非要说“锁也保护了代码”,那也只是在保护全局变量的时候,顺便保护了代码而已。
使用锁,首先要搞清楚使用锁的目的是什么?要保护什么?
锁是如何保护资源的?--How
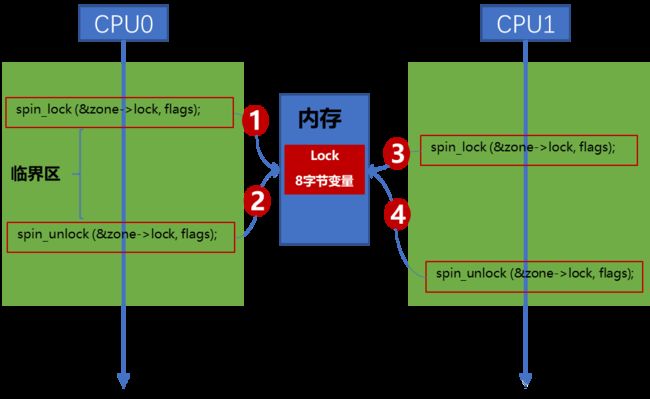
核心原理:根据全局变量的状态来实现锁的控制。
“统一到门口排队,依次获得钥匙”
无进程持锁时,lock=0;
进程0持锁后,lock=1;
进程1再尝试持锁时,由于lock=1,无法获取,只能等待。
因此:lock一定要是全局的,8字节,其实只用1bit即可。Spinlock就充分利用这8个字节,仅用1bit表示锁状态。
衍生出锁的两大功能:同步和保护。
锁的种类
锁的分类
相关API
特点
注意点
原子操作:atomic
atomic_read(atomic_t * v);
atomic_set(atomic_t * v, int i);
void atomic_add(int i, atomic_t *v);
最小执行单元,未操作完成前,不允许被任何事件打断。
是实现其他锁的基础。
自旋锁:spinlock
spin_lock(&lock);
spin_unlock(&lock)
等锁时,在原地打转,所以叫自旋。理解为:等锁急得团团转。
1、等锁时,占着cpu不释放,不睡眠,关闭调度。
2、访问临界区就要持锁,无论读还是写?
3、谁持锁,那就谁来释放
1、同一把锁,不能被进程上下文和中断上下文一起使用。
2、临界区内不能调用可能阻塞的函数,如sleep,io操作等
互斥锁:mutex lock
mutex_init(&mutex);
mutex_lock(struct mutex *lock)
mutex_unlock(struct mutex *lock)
1、等锁时,可进入睡眠等待,让出cpu,不需要自旋。
2、持锁后,也可进入睡眠。
3、谁持锁,那就谁来释放。
信号量:semaphore
int down (struct semaphore *sem) //加锁
int up (struct semaphore *sem) //释放锁
1、与mutex有相似之处,等锁或持锁时,可睡眠
2、可设置资源数为多个,能多个进程都获取锁。
3、A持锁,可以B释放。
共享资源为1时,为二意信号量,就非常接近mutex了。唯一的差异是信号量可以A持锁,B释放锁。
读写锁
rw_lock
read_lock(); read_unlock();
write_lock(); write_unlock();
“reader-writer spin lock”,是spin lock衍生出来的。
分为读锁和写锁,适用于读多写少的场景,可以多个进程同时读取,但写时,只能唯一,且写时关闭调度。
看似非常合理,但对“写”不公平。如果读者太多,写者需要等很长时间才能拿到锁。
读写信号量
rw_semaphore
down_read(); up_read() //读锁
down_write();up_write(); //写锁
可视作是rwlock的可睡眠版本
“写”一样受到不公平待遇。
顺序锁
seqlock
read_seqlock()
read_sequnlock()
write_seqlock()
write_sequnlock()
读写锁的进一步完善,诞生了顺序写。相比起rwlock,它进一步解除了reader与writer之间的互斥,只保留了writer与writer之间的互斥。reader在读取一个共享变量之前,需要先读取一下sequence number的值。读取变量之后,reader需要再次读取一下sequence number的值,并和读取之前的sequence number的值进行比较,看是否相等,若不等,再重新读取一次。
也有其不足之处,使用场景也很少。逐渐被RCU取代
RCU锁
Read copy update
主要有5大接口函数
内核现在非常流行的锁,使用量逐年增加,主要保护链表。
读写可同时进行。核心思想:先创建一个旧数据的copy,然后writer更新这个copy,最后再用新的数据替换掉旧的数据
GP区的处理是核心关键。“当你感觉岁月静好的时候,一定是另外有一个人帮你承担了”
原子操作
1、 最小执行单元,未操作完成前,不允许被任何事件打断。
2、 是实现其他锁的基础,是基础中的基础。 Spin lock 是实现其他锁的基础,原子操作是实现 spin lock 的基础。
3、ARM 原子操作采用的方法主要是 LL/SC (Load-Link/Store-Conditional) 。
Arm内存单元上的数据不允许被直接操作,而是必须先放到寄存器中,不能直接对内存进行更改操作。例如,写操作“x=5;”, 需要先将内存的值读取到寄存器内,修改后,再从寄存器写会内存。
原子操作是:通过指令和硬件的配合,保证”x=5;”这一过程不被打断,一次执行完毕。
Spin lock
特点:
1、自旋,性格刚烈,不达目的誓不罢休,一直占着CPU不放,不进入睡眠,关闭了抢占,故也不做调度 。
2、无论读写,只要访问临界区,就需要加锁。
3、谁持锁,谁释放。
4、是实现其他锁的基础,其他锁基本都是基于spin lock衍生出来的。若要理解其他锁,须先理解spinlock
简述:
Linux中spinlock机制发展到现在,其实现方式的大致有3种:
一、经典的CAS(Compare And Swap),现在已经不使用,理解经典CAS,有助于理解后面的锁。
二、Ticket Spinlock,中间态,并未广泛使用,但为qspinlock打下了坚实的基础。
三、qspinlock,目前Linux中广泛使用的spinlock机制,高通、MTK平台等当然使用此种机制。
锁的实现与CPU架构体系强相关,下面以ARM架构体系为例,说明spinlock的实现。
详解:
一、经典的CAS(Compare And Swap):
最古老的一种做法是:spinlock用一个整形变量表示,其初始值为1,表示available的状态。当一个CPU(设为CPU A)获得spinlock后,会将该变量的值设为0,之后其他CPU试图获取这个spinlock时,会一直等待,直到CPU A释放spinlock,并将该变量的值设为1。
二、Ticket Spinlock:
CAS spinlock存在不足:他是不公平的,一旦锁被释放,下一个获得锁的cpu不确定,有可能后到先得。大家都抢,没有排队。
为了解决这种「无序竞争」带来的不公平问题,spinlock的另一种实现方法是采用排队形式的"ticket spinlock"。
核心原理:去银行办理业务,需要先取个号,例如号码位5,然后排队等待叫号,此时银行正在给2号办理业务,2号办理完业务后,号码加1,变为3号,直到变为5号,就会轮到自己。
Linux 版本的实现如下:
不足:
1、尽管实现了排队,但当有多个cpu等锁时,每个cpu都要通过cache line不停的访问同一块内存,即便是值没有变,也要不停的刷新cache line去读值,浪费功耗。只有一个cpu的刷新是有意义的,其他cpu都是在做无用功。
二、Ticket Spinlock-MCS实现方法:
如果在ticket spinlock的基础上进行一定的修改,让每个CPU不再是等待同一个spinlock变量,而是基于各自不同的per-CPU的变量进行等待,那么每个CPU平时只需要查询自己对应的这个变量所在的本地cache line,仅在这个变量发生变化的时候,才需要读取内存和刷新这条cache line,这样就可以解决上述的这个问题。
要实现类似这样的spinlock的「分身」,其中的一种方法就是使用MCS lock。试图获取一个spinlock的每个CPU,都有一份自己的MCS lock。
不足:
排队问题解决了,功耗问题也解决了。但该机制仍存在不足之处:MCS lock多了一个指针,要多占4(或者8)个字节,消耗的存储空间是原来的2-3倍。Spinlock在操作系统中使用非常广泛,数量很大,那么消耗的内存空间也很大。
那有没有更优的方案呢?
qspinlock(queue spinlock)
三、qspinlock: (queue spin lock)
qspinlock是目前被广泛使用的spinlock的实现方式,我们正在使用的就是这种机制。同时解决了排队、功耗和内存消耗的问题。
qspinlock的实现比较复杂,若要深入理解,建议读兰新宇的博客:Linux中的spinlock机制[三] - qspinlock - 知乎
以下内容是从他的博客上copy的。
qspinlock
1、第一个cpu获得锁后,三元数组(0,0,1)(皇帝登基,住在皇宫。 )
2、第二个cpu排队等锁,(0,1,1)(太子排队,住在东宫,仍属皇宫。 )
3、第三个cpu排队等锁,(0,1,1),tail指向per cpu的mcs node,tail的值为等待cpu的编号,若tail=5,代表第5个cpu正在等待锁。(皇宫外建府邸。 )
spinlock API调用流程
慢速等待路径里面,又实现了排队机制,第一顺位继承人(太子),第二顺位继承人(宫外建府)。又是一堆复杂的代码逻辑。
spinlock 死锁问题举例
Raw_lock状态分析:
Locked =1; //说明申请锁时,锁已经被其他线程持有,只能等。
Pending =1; //说明申请锁时,前面已经有线程排队,本次申请只能是第二顺位以后的申请,前面有1个线程已经持续,至少有1个线程在排队等待持续。
Locked_pending = 0x0101; //就是count的前半段,联合体的另一种表达方式,表示的仍然是locked和pending的状态。
tail =0x10; // 这8bit用于表示已经持锁的cpu和其所处的上下文,算法是:高6bit表示持锁的cpu,低2bit表示当前所属的上下文context,(Linux中一共有4种context,分别是task, softirq, hardirq和nmi)。高6bit的二进制是:000100,值为4,4-1表示当前持锁的cpu,即cpu3当前正在持锁。
当前进程运行在cpu3上,申请持锁的函数也正运行在cpu3上。
AA型死锁。
spinlock与抢占
特点:自旋,性格刚烈,不达目的誓不罢休,一直占着CPU不放,不进入睡眠,关闭了抢占,故也不做调度 。
那么,如何理解上面的意思?
普通API:spin_lock()/spin_unlock()
普通API建立的临界区,还是能被中断打断的,还能不能更霸道一些?当然可以。
关中断API:
spin_lock_irq()/spin_unlock_irq()
spin_lock_irqsave()/spin_unlock_irqstore()
Spinlock 霸占CPU不释放的情况举例
长时间占着CPU不释放,不参与调度。只有在关闭抢占的情况下会发生。
而spinlock首先要关闭抢占。
一般情况下,我们的代码是不会主动关闭抢占的。
Spinlock 与中断是我,不建议使用spinlock1、中断处理函数内,不建议使用spinlock1、中
断1、中断处理函数指的中断上半部,需要快速执行完毕,以便响应下次硬件中断。软中断、tasklet、中断线程化、中断工作队列等都是中断下半部,处理耗时操作。
2、中断处理函数要快速执行完毕,若使用锁,那就有可能出现等锁的情况,那就要耗时等待。若在中断处理函数内等待,就会造成cpu资源浪费,cpu空转等待。占着XX,不XX。
假设一个CPU上的线程Task_1持有了一个spinlock,发生中断后,该CPU转而执行对应的hardirq。如果该hardirq也试图去持有这个spinlock,那么将无法获取成功,导致hardirq无法退出。在hardirq主动退出之前,线程T是无法继续执行以释放spinlock的,最终将导致该CPU上的代码不能继续向前运行,形成死锁(dead lock)
spinlock使用注意点
spinlock保护资源时,临界区应尽可能的短,临界区不能有太耗时的操作
Spinlock的特点是spin,也就是自旋,一直占着CPU,性格刚烈。若是在临界区内耗时太长,则其他任务得不到执行,影响调度,进而影响性能,严重时,甚至会导致watchdog。
案例:手机因watchdog而panic。
1、cpu卡死的堆栈如右图。
2、原因就是xchi_stop()先持spinlock锁,并关闭中断。世界安静了,无人再打扰该线程的执行,但该线程在读取硬件寄存器时,深深的沉睡下去,硬件异常,一直无法返回信号。软件一直等到,超过10s,触发watchdog。
Spinlock的不足及改进
1、若是想在临界区内睡眠,spinlock就不能使用。那该如何解决呢?
2、访问要保护公共资源就需要解锁。若读多写少,每次读时,也需要加锁,读也要排队等待,浪费资源。那能不能读的时候不加锁,而写时候加锁呢?
为了解决这两个问题,内核社区的大神们付出了很大努力,给出了各种解决方案,各个方案都有各自的优缺点和使用场景。
充分体现了内核工匠们精益求精的精神。
睡眠相关概念:
系统睡眠:不多解释
CPU睡眠:cpu只有掉电才能睡眠,CPU睡眠,系统也就睡眠了。
进程(线程)睡眠:进程让出cpu,不再运行。在内核调用schdeule()后,即进入睡眠。用户态是无法进入睡眠的。通常说的阻塞(block)其实就是进程睡眠了。此处的睡眠就是进程睡眠。
Mutex lock
spinlock临界区内不能进入睡眠,为了实现临界区内也能睡眠的功能,内核社区开发出mutex lock,也叫互斥锁
1、task首次持锁时,要先判断owner的低4bit是否为0,若为0,直接获得锁,并将第0bit置位1,代表已经有task持锁。同时将该task地址记录高60bit。
2、若低4bit不为零,就比较复杂了,就有乐观等待和慢速等待路径两种情况了,为了容易理解,暂时先这样理解:第二个申请锁的task会将自己挂到mutex锁的等待队列上,然后task进入睡眠。因此,mutex允许睡眠。
3、spinlock wait_lock此处是为了保护竞争mutex锁的owner,防止出现竞争。
临界区应尽可能的短,临界区内不能有太耗时的操作。ock保护资源时,临界区应尽可能的短,临界区内不Mutex lock问题举例
右图,
1、当前task 19722处于等mutex锁状态,将自己挂在了等待队列上,然后调度出去,让出cpu。
2、由于:
owner = (
counter = 0xFFFFFF87A5136041),
所以:mutex锁已经被其他task持有,
当前持有mutex锁的task地址是:
0xFFFFFF87A5136040,红色1代表锁已经被持有。
3、可以看到wait_list已经有3个等待者了。为什么不是4? 又有几个task竞争锁呢?
4、第1066行的spin_unlock()又是什么意思呢?
Mutex lock & spinlock
混合类型:
spinlock临界区不能嵌套mutex,否则死机。
mutex可视作是spinlock的可睡眠版本,等锁时,同样是线程无法继续向前执行,但:
1、spinlock是“spin”,导致该CPU上无法发生线程切换。临界区内不能调用可能阻塞的函数,例如:不能调用sleep(), copy_from_user()或者kmalloc(GFP_KERNEL)等。
2、而mutex是“block”,阻塞,可以发生线程切换,让所在CPU上执行其他线程。阻塞既可以发生在线程试图获取mutex时,也可以发生在线程持有mutex时。临界区内可以调用sleep(), copy_from_user()或者kmalloc(GFP_KERNEL)等。
驱动开发过程中,需要根据实际情况来选择。首先要明确使用锁的目的,要保护什么?还是要同步?
Spinlock 使用举例
以printk(fmt, …)为例:
printk()会调用到vprintk_emit(),为了保证log有序打印到logbuf内,每条日志打印时,都需要持spinlock锁,并关闭中断。
关中断,持spinlock锁。目的:“同步”。
想想,此处能使用mutex吗?
从技术上讲,此处当然可以使用mutex,但是谁又希望自己在打印log的时候被调度出去呢?即便此时有task在持锁打印log,那应该也会很快完成,我就稍等一会呗。因此选用了spinlock。
还是那句话,一定要清楚自己持锁的目的是什么?根据自己的目的才能选择合适的锁。
mutex 使用举例
以电源管理的regular_enable()为例,讲述锁的使用,中间省略了一些次要调用的过程。内核中各个器件都要使用电源,经常是多任务并发,而设置电源电压有时候需要路由到AOP侧。AOP是一个简单的RTOS系统,不可能有多任务对应AP侧的请求,那么。多对一,为什么没有发送条件竞争了?
rwlock读写锁
rwlock的全称是“reader-writer spin lock”,是有spinlock衍化过来的,和普通的spinlock不同,它对"read"和"write"的操作进行了区分。
1、如果当前没有writer,那么多个reader可以同时获取这个rwlock。
2、如果当前没有任何的reader,那么一个writer可以获取这个rwlock。
使用方法:
1、对于reader,依靠read_lock()和read_unlock()来限定读取一侧的临界区
每当一个reader进入临界区,就需要将读取一侧的cnts加1,退出则减1。只有当这个cnts的值为0,writer才可以执行自己的临界区代码
2、对于writer,依靠write_lock()和write_unlock()来限定写入一侧的临界区。
不足之处:
设想,当有很多读者进入临界区后,若想写,那就必须要等读者读完。这对写来说,不公平。 目前读写锁使用越来越少,新代码基本不在使用这个锁。
seqlock顺序锁
seqlock是由Stephen Hemminger负责开发,自Linux 2.6版本引入的,其全称是“sequential lock”。相比起rwlock,它进一步解除了reader与writer之间的互斥,只保留了writer与writer之间的互斥。只要没有其他的writer持有这个seqlock(即便当前存在reader持有该seqlock),那么第一个试图获取该seqlock的writer就可以成功地持有。
那么,若正在读时,有写修改,如何保证读的一致性呢?
l写开始时,有writter持有seqlock之后,seqcount的值就会加1;
l写结束后,writter释放seqlock, seqcount的值再次加1;
l读开始时,记录seqcount的值;
l读结束后,再次读取seqcount ,若发现本次读取的值和前面读开始时记录的值不同,则说明有写修改,那么,将放弃本次的读操作,重新读取一次。
l
很显然,seqlock存在不足,若是读的临界区比较长,那么再重来一次,耗时很长,影响效率。
适用场景:读多写少,在Linux中的一个重要应用就是表示时间的jiffies。但整体的使用场景不多。
信号量semaphore
不管是mutex还是spinlock,都限定了某一时刻只有一个线程可以获得临界区资源,但在某些场景下,临界区资源允许多个线程同时访问,这时就可以使用semaphore。Linux中semaphore的定义同mutex很相似,都是包含一个保护该结构体的spinlock和一个等待队列"wait_list"。
semaphore是没有"owner"的,它只需要一个标识共享资源数目的"count",因而也被称为counting semaphore。
只要semaphore对应的“count”的值大于0,线程获取semaphore就可以成功,但它会使可进入临界区的线程数目减少(对应“count”值减1),所以有两个API:
down(); //加锁,counter减1,花钱。
up(); //释放锁,counter加1,挣钱。
semaphore是没有“owner”的,故有一显著特点:
A task加的锁,B task可以释放锁,这是与spinlock和mutex的显著区别。 Linux内核主要是使用了信号量的这个特点。
(内核一般将counter设置为1,即二义信号量。 类似mutex,但又有区别)
读写信号量rw_semaphoresa建议使用spinlock操作抵抗力理函数处理数内,不建议使用
为了区分读写,spinlock衍生出rwlock,同理,semaphore也衍生出了rw_semaphore。
读写信号量(rw_semaphore)持锁逻辑:
1、读时,要判断是否有写锁。
l若有写者持锁,则等待。此时,类似mutex等待。
l若无写者持锁,则获取读锁成功,conut的高8位以上的数加1, count低8位用作记录写相关的标记。
2、写时,判断是否有读者和写者持锁。只有没有读者和写者持锁时,才能申请到写锁。
l若有写者持锁,则等待,此时,类似mutex等待。
l若无写者,只有读者,情况就比较复杂。首先置位count的bit1,阻止后面的读者再次持读锁。然后进入等待期,等待前面的读者完成读操作。
持有写锁后,owner设置为写者,记录当前谁持有写锁。
关于owner:
"owner"用于表示获得rwsem的reader或writer信息。当一个writer线程获得rwsem后,它就会将自己的"task_struct"指针填入"owner",直到释放时才清除。如果排在等待队列首位的线程是一个reader,那么队列中将可能有多个reader被唤醒来获取这个rwsem,"owner"填入的将是最后一个获得rwsem的reader线程的"task_struct"指针。
读写信号量使用还是比较多的,尤其常见与内存管理相关,核心数据结构mm_struct的成员mmap_lock就是读写信号量。在binder调用时,必定要申请内存,频繁调用mmap_read_lock();
这里面的实现就是使用了读写信号量。
RCU锁-read copy update
【核心思想】:
1、若要读取公共资源时,那就尽情的读。
2、若要写公共资源,那就将原来的公共资源copy出一份来,修改完成后,替换原来旧的公共资源,旧的公共资源需要释放掉。
【使用场景】:
1、读多写少。
2、访问内核链表资源。(内核中存在各种各样的链表,RCU发挥了其用武之地)
RCU 锁的原理比较简单,但其实现原来非常复杂,涉及到的知识非常广泛,涉及到中断、进程切换、tick时钟、RCU软中断、内核rcu的gp专有线程、RCU tree的各个数据结构。大家若有兴趣研究RCU锁,推荐如下博客:
https://zhuanlan.zhihu.com/p/89439043
https://zhuanlan.zhihu.com/p/374902282
关于RCU锁,有一句话想说:当你感觉岁月静好的时候,一定是另外有一个人帮你承担了。
reader 是轻松了,但对于 RCU 中的一个 writer 来说(包括 updater 和 reclaimer),需要申请新的内存空间,向内核注册回调函数,以及进行数据的更新操作,同时还要考虑与其他 writer 之间的互斥问题,开销较大。为了减少writer的负担,又引入了专有线程。最终的实现非常的复杂,主要还是为了解决“什么时候释放、谁来释放” 的问题。
RCU锁我们最常遇到的问题是RCU stall,直接原因是在指定的时间(21s)内没有释放旧内存。总结了一下,基本就是如下两种情况:
1、持rcu读锁的task无法得到执行,即无法获取cpu资源。这类问题需要分析调度信息,看看为什么task无法调度到,往往是由于高通优先级的task占用了cpu资源,低优先级的task无法调度,例如中断风暴,RT task太多等。
2、持rcu读锁的task A能够执行,但在RCU临界区内又需要等待其他锁,A长时间无法出RCU临界区,这种情况也会发生rcu stall,需要恢复堆栈分析那个task长时间占用了锁,往往是锁套锁,相互依赖
RCU锁--GP(Grace Period)
GP:常翻译成宽限期,RCU之所以实现复杂,主要是围绕GP展开的。
RCU实现了读写并行,那么就有一种情况:
1、updater正在更新数据,此时有reader需要读取数据,reader是可以读取旧数据的。
2、updater更新完毕数据以后,reader仍然还在读,这时,updater是不能释放旧内存的,那怎么办呢?
3、此时,updater调用synchronize_rcu()或call_rcu(),做好标记,声明进入GP。等old reader读取完成后,再释放旧内存。
GP开始的时候,容易判定,那么GP退出,如何判定呢?
若是有多个reader,那就需要这些reader都得退出临界区,GP才能结束,那又如何判断这些reader都退出临界区了呢?
这些判定,涉及调度、中断、多cpu协同等方面的配合,实现复杂。
因此,GP的时间长度不定,若GP持续时间太长,超过21s,则触发RCU Stall。
例如:
1、有一个reader迟迟得不到调度,不能运行,GP就会一直持续,21s后stall
2、reader发生死锁,无法执行。
3、reader在等外部事件(中断),外部事件一直不来。
RCU锁-read copy update
最后,贴一张网上的RCU锁的图,看懂这个图,也就理解了RCU锁的实现机制。
————————————————
版权声明:本文为CSDN博主「会写bug的程序猿_chbgoon」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chbgoon/article/details/123495480
在linux系统当中存在很多独占性的资源,他在同一个时间只能被一个进程使用。常见的有打印机、内存或者系统内部表现等资源。如果打印机同时被两个进程使用,打印结果就会混乱输出结果;如果一个内存资源被多个进程同时修改,进程实际的执行结果就没有办法被保证。因此,操作系统中会通过几种锁(原子变量,关中断,信号量,自旋锁)授权某一个进程排他性的访问某一种资源。
在很多应用中,需要一个进程排他性的访问的若干资源而不是一个资源。如果进程A写一片内存位置的A资源,进程B进程写一片内存位置B的资源。在进程B释放内存B的之前,B同时也申请写内存A位置的资源,A进程这个时候也没有释放A位置资源,同时请求内存B位置资源,这种情况下变回出现死锁问题,两个进程都会阻塞在这一种状态中。
总结,关于锁需要掌握linux内核中常见的锁资源使用和实现原理,同时能够在使用过程中学习避免死锁的一些方法。
1. 资源
计算机系统当中资源有硬件和软件区分,其概念是指随着时间的推移,必须能够获得、使用以及释放的任何东西。资源分为可抢占和不可抢占两种情况。具体某一项内容是抢占还是非抢占资源是根据具体上下文来确定的。比方说,在很多情况下,我们通过资源的划分,例如内存分布情况,可以将内存资源做成非抢占资源;但是在另外一些情况,比方说某个设备资源映射的内存区域,需要使用设备时就必须实用这片内存,这种情况下这个内存资源就是不可抢占资源。对于抢占资源我们通过锁临时对数据区域进行保护,当然也就会有出现死锁的可能性。
1.1. 资源访问流程
使用资源需要时间顺序抽象表示为:1) 请求资源;2) 使用资源;3)释放资源。当一个进程请求资源失败的情况下会重复这样的小循环:请求(失败),休眠,在请求。至于多次请求失败以后怎么处理决定于具体的系统或者业务设计者,可以在多次请求以后直接退出,也可以让请求者处于睡眠状态,一段时间以后再次唤醒。
2. 锁
2.1. 原子操作必要性
下面代码描述一个线程中的函数和中断处理函数,它们对同一个全局变量执行加 1 操作:
int a = 0;
void interrupt_handle()
{
a++;
}
void thread_func()
{
a++;
}
对于ARM处理器,经过编译器翻译后是{ ldr r0,=addr; add r0, r0, 1; str r0, [addr]}。这种才做在单进程无中断情况下是没有任何问题,单如果如上面粒子存在中断情况下,可能导致结果不确定。thread_func 函数还没运行完第 2 条指令时,中断就来了。CPU 转而处理中断,也就是开始运行 interrupt_handle 函数,这个函数运行完 a=1,CPU 还会回去继续运行第 3 条指令,此时 a 依然是 1,这显然是错的。下面来看一下表格,你就明白了。显然在 t2 时刻发生了中断,导致了 t2 到 t4 运行了 interrupt_handle 函数,t5 时刻 thread_func 又恢复运行,导致 interrupt_handle 函数中 a 的操作丢失,因此出错。

在单核无中断情况下资源都比较简单,在单核有中断的情况下,我们可以通过关闭中断方式实现资源的原子访问。但是,现在CPU都是多核了,关闭多个CPU的中断显然是不合适的。因此,原子操作,自旋锁,信号量这些类型的锁资源就出现了。
今天谈谈linux中常见并发访问的保护机制设计原理。为什么要写这篇文章呢?其实想帮助自己及读者更深入的了解背后的原理(据可靠消息,锁的实现经常出现在笔试环节。既可以考察面试者对锁的原理的理解,又可以考察面试者编程技能)。我们抛开linux中汇编代码。用C语言为大家呈现背后实现的原理。同时,文章中的代码都没有考虑并发情况(例如某些操作需要原子性,或者数据需要保护等)。
注:部分代码都是根据ARM64架构汇编代码翻译成C语言并经过精简(例如:spin lock、read-write lock)。也有部分代码实现是为了呈现背后设计的原理自己编写的,而不是精简linux中实现的代码(例如mutex)。
自旋锁(spin lock)
自旋锁是linux中使用非常频繁的锁,原理简单。当进程A申请锁成功后,进程B申请锁就会失败,但是不会调度,原地自旋。就在原地转到天昏地暗只为等到进程A释放锁。由于不会睡眠和调度的特性,在中断上下文中,数据的保护一般都是选择自旋锁。如果有多个进程去申请锁。当第一个申请锁成功的线程在释放的时候,其他进程是竞争的关系。因此是一种不公平。所以现在的linux采用的是排队机制。先到先得。谁先申请,谁就先得到锁。
原理
举个例子,大家应该都去过银行办业务吧。银行的办事大厅一般会有几个窗口同步进行。今天很不巧,只有一个窗口提供服务。现在的银行服务都是采用取号排队,叫号服务的方式。当你去银行办理业务的时候,首先会去取号机器领取小票,上面写着你排多少号。然后你就可以排队等待了。一般还会有个显示屏,上面会显示一个数字(例如:"请xxx号到1号窗口办理"),代表当前可以被服务顾客的排队号码。每办理完一个顾客的业务,显示屏上面的数字都会增加1。等待的顾客都会对比自己手上写的编号和显示屏上面是否一致,如果一致的话,就可以去前台办理业务了。现在早上刚开业,顾客A是今天的第一个顾客,去取号机器领取0号(next计数)小票,然后看到显示屏上显示0(owner计数),顾客A就知道现在轮到自己办理业务了。顾客A到前台办理业务(持有锁)中,顾客B来了。同样,顾客B去取号机器拿到1号(next计数)小票。然后乖乖的坐在旁边等候。顾客A依然在办理业务中,此时顾客C也来了。顾客C去取号机器拿到2号(next计数)小票。顾客C也乖乖的找个座位继续等待。终于,顾客A的业务办完了(释放锁)。然后,显示屏上面显示1(owner计数)。顾客B和C都对比显示屏上面的数字和自己手中小票的数字是否相等。顾客B终于可以办理业务了(持有锁)。顾客C依然等待中。顾客B的业务办完了(释放锁)。然后,显示屏上面显示2(owner计数)。顾客C终于开始办理业务(持有锁)。顾客C的业务办完了(释放锁)。3个顾客都办完了业务离开了。只留下一个银行柜台服务员。最终,显示屏上面显示3(owner计数)。取号机器的下一个排队号也是3号(next计数)。无人办理业务(锁是释放状态)。

linux中针对每一个spin lock会有两个计数。分别是next和owner(初始值为0)。进程A申请锁时,会判断next和owner的值是否相等。如果相等就代表锁可以申请成功,否则原地自旋。直到owner和next的值相等才会退出自旋。假设进程A申请锁成功,然后会next加1。此时owner值为0,next值为1。进程B也申请锁,保存next得值到局部变量tmp(tmp = 1)中。由于next和owner值不相等,因此原地自旋读取owner的值,判断owner和tmp是否相等,直到相等退出自旋状态。当然next的值还是加1,变成2。进程A释放锁,此时会将owner的值加1,那么此时B进程的owner和tmp的值都是1,因此B进程获得锁。当B进程释放锁后,同样会将owner的值加1。最后owner和next都等于2,代表没有进程持有锁。next就是一个记录申请锁的次数,而owner是持有锁进程的计数值。
实现
我们首先定义描述自旋锁的结构体arch_spinlock_t。
- typedef struct {
- union {
- unsigned int slock;
- struct __raw_tickets {
- unsigned short owner;
- unsigned short next;
- } tickets;
- };
- } arch_spinlock_t;
如上面的原理描述,我们需要两个计数,分别是owner和next。slock所占内存区域覆盖owner和next(据说C语言学好的都能看得懂)。下面实现申请锁操作 arch_spin_lock。
- static inline void arch_spin_lock(arch_spinlock_t *lock)
- {
- arch_spinlock_t old_lock;
- old_lock.slock = lock->slock; /* 1 */
- lock->tickets.next++; /* 2 */
- while (old_lock.tickets.next != old_lock.tickets.owner) { /* 3 */
- wfe(); /* 4 */
- old_lock.tickets.owner = lock->tickets.owner; /* 5 */
- }
- }
- 继续上面的举例。顾客从取号机器得到排队号。
- 取号机器更新下个顾客将要拿到的排队号。
- 看一下显示屏,判断是否轮到自己了。
- wfe()函数是指ARM64架构的WFE(wait for event)汇编指令。WFE是让ARM核进入低功耗模式的指令。当进程拿不到锁的时候,原地自旋不如cpu睡眠。节能。睡下去之后,什么时候醒来呢?就是等到持有锁的进程释放的时候,醒过来判断是否可以持有锁。如果不能获得锁,继续睡眠即可。这里就相当于顾客先小憩一会,等到广播下一位排队者的时候,醒来看看是不是自己。
- 前台已经为上一个顾客办理完成业务,剩下排队的顾客都要抬头看一下显示屏是不是轮到自己了。
释放锁的操作就非常简单了。还记得上面银行办理业务的例子吗?释放锁的操作仅仅是显示屏上面的排队号加1。我们仅仅需要将owner计数加1即可。arch_spin_unlock实现如下。
- static inline void arch_spin_unlock(arch_spinlock_t *lock)
- {
- lock->tickets.owner++;
- sev();
- }
sev()函数是指ARM64架构的SEV汇编指令。当进程无法获取锁的时候会使用WFE指令使CPU睡眠。现在释放锁了,自然要唤醒所有睡眠的CPU醒来检查自己是不是可以获取锁。
信号量(semaphore)
信号量(semaphore)是进程间通信处理同步互斥的机制。是在多线程环境下使用的一种措施,它负责协调各个进程,以保证他们能够正确、合理的使用公共资源。 它和spin lock最大的不同之处就是:无法获取信号量的进程可以睡眠,因此会导致系统调度。
原理
信号量一般可以用来标记可用资源的个数。老规矩,还是举个例子。假设图书馆有2本《C语言从入门到放弃》书籍。A同学想学C语言,于是发现这本书特别的好。于是就去学校的图书馆借书,A同学成功的从图书馆借走一本。这时,A同学室友B同学发现A同学竟然在偷偷的学习武功秘籍(C语言)。于是,B同学也去借一本。此时,图书馆已经没有书了。C同学也想借这本书,可能是这本书太火了。图书馆管理员告诉C同学,图书馆这本书都被借走了。如果有同学换回来,会第一时间通知你。于是,管理员就把C同学的信息登记先来,以备后续通知C同学来借书。所以,C同学只能悲伤的走了(如果是自旋锁的原理的话,那么C同学将会端个小板凳坐在图书馆,一直要等到A同学或者B同学还书并借走)。
实现
为了记录可用资源的数量,我们肯定需要一个count计数,标记当前可用资源数量。当然还要一个可以像图书管理员一样的笔记本功能。用来记录等待借书的同学。所以,一个双向链表即可。因此只需要一个count计数和等待进程的链表头即可。描述信号量的结构体如下。
- struct semaphore {
- unsigned int count;
- struct list_head wait_list;
- };
在linux中,每个进程就相当于是每个借书的同学。通知一个同学,就相当于唤醒这个进程。因此,我们还需要一个结构体记录当前的进程信息(task_struct)。
- struct semaphore_waiter {
- struct list_head list;
- struct task_struct *task;
- };
struct semaphore_waiter的list成员是当进程无法获取信号量的时候挂入semaphore的wait_list成员。task成员就是记录后续被唤醒的进程信息。
一切准备就绪,现在就可以实现信号量的申请函数。
- void down(struct semaphore *sem)
- {
- struct semaphore_waiter waiter;
- if (sem->count > 0) {
- sem->count--; /* 1 */
- return;
- }
- waiter.task = current; /* 2 */
- list_add_tail(&waiter.list, &sem->wait_list); /* 2 */
- schedule(); /* 3 */
- }
- 如果信号量标记的资源还有剩余,自然可以成功获取信号量。只需要递减可用资源计数。
- 既然无法获取信号量,就需要将当前进程挂入信号量的等待队列链表上。
- schedule()主要是触发任务调度的示意函数,主动让出CPU使用权。在让出之前,需要将当前进程从运行队列上移除。
释放信号的实现也是比较简单。实现如下。
- void up(struct semaphore *sem)
- {
- struct semaphore_waiter waiter;
- if (list_empty(&sem->wait_list)) {
- sem->count++; /* 1 */
- return;
- }
- waiter = list_first_entry(&sem->wait_list, struct semaphore_waiter, list);
- list_del(&waiter->list); /* 2 */
- wake_up_process(waiter->task); /* 2 */
- }
- 如果等待链表没有进程,那么自然只需要增加资源计数。
- 从等待进程链表头取出第一个进程,并从链表上移除。然后就是唤醒该进程。
读写锁(read-write lock)
不管是自旋锁还是信号量在同一时间只能有一个进程进入临界区。对于有些情况,我们是可以区分读写操作的。因此,我们希望对于读操作的进程可以并发进行。对于写操作只限于一个进程进入临界区。而这种同步机制就是读写锁。读写锁一般具有以下几种性质。
- 同一时间有且仅有一个写进程进入临界区。
- 在没有写进程进入临界区的时候,同时可以有多个读进程进入临界区。
- 读进程和写进程不可以同时进入临界区。
读写锁有两种,一种是信号量类型,另一种是spin lock类型。下面以spin lock类型讲解。
原理
老规矩,还是举个例子理解读写锁。我绞尽脑汁才想到一个比较贴切的例子。这个例子来源于生活。我发现公司一般都会有保洁阿姨打扫厕所。如果以男厕所为例的话,我觉得男士进入厕所就相当于读者进入临界区。因为可以有多个男士进厕所。而保洁阿姨进入男士厕所就相当于写者进入临界区。假设A男士发现保洁阿姨不在打扫厕所,就进入厕所。随后B和C同时也进入厕所。然后保洁阿姨准备打扫厕所,发现有男士在厕所里面,因此只能在门口等待。ABC都离开了厕所。保洁阿姨迅速进入厕所打扫。然后D男士去上厕所,发现保洁阿姨在里面。灰溜溜的出来了在门口等着。现在体会到了写者(保洁阿姨)具有排他性,读者(男士)可以并发进入临界区了吧。
既然我们允许多个读者进入临界区,因此我们需要一个计数统计读者的个数。同时,由于写者永远只存在一个进入临界区,因此只需要一个bit标记是否有写进程进入临界区。所以,我们可以将两个计数合二为一。只需要1个unsigned int类型即可。最高位(bit31)代表是否有写者进入临界区,低31位(0~30bit)统计读者个数。
+----+-------------------------------------------------+| 31 | 30 0 |+----+-------------------------------------------------+| || +----> [0:30] Read Thread Counter+-------------------------> [31] Write Thread Counter
实现
描述读写锁只需要1个变量即可,因此我们可以定义读写锁的结构体如下。
- typedef struct {
- volatile unsigned int lock;
- } arch_rwlock_t;
既然区分读写操作,因此肯定会有两个申请锁函数,分别是读和写。首先,我们看一下read_lock操作的实现。
- static inline void arch_read_lock(arch_rwlock_t *rw)
- {
- unsigned int tmp;
- sevl(); /* 1 */
- do {
- wfe();
- tmp = rw->lock;
- tmp++; /* 2 */
- } while(tmp & (1 << 31)); /* 3 */
- rw->lock = tmp;
- }
- sevl()函数是ARM64架构中SEVL汇编指令。SEVL和SEV的区别是,SEVL仅仅修改本地CPU的PE寄存器值,这样下面的WFE指令第一次执行的时候不会睡眠。
- 增加读者计数,最后会更新到rw->lock中。
- 更新rw->lock前提是没有写者,因此这里会判断是否有写者已经进入临界区(判断方法是rw->lock变量bit31的值)。如果,有写者已经进入临界区,就在这里循环,并WFE指令睡眠。类似上面介绍的spin lock实现。
当读进程离开临界区的时候会调用read_unlock释放锁。read_unlock实现如下。
- static inline void arch_read_unlock(arch_rwlock_t *rw)
- {
- rw->lock--;
- sev();
- }
实现很简单,和spin_unlock如出一辙。递减读者计数,然后使用SEV指令唤醒所有的CPU,检查等待状态的进程是否可以获取锁。
读操作看完了,我们看看写操作是如何实现的。arch_write_lock实现如下。
- static inline void arch_write_lock(arch_rwlock_t *rw)
- {
- unsigned int tmp;
- sevl();
- do {
- wfe();
- tmp = rw->lock;
- } while(tmp); /* 1 */
- rw->lock = 1 << 31; /* 2 */
- }
- 由于写者是排他的(读者和写者都不能有),因此这里只有rw->lock的值为0,当前的写者才可以进入临界区。
- 置位rw->lock的bit31,代表有写者进入临界区。
当写进程离开临界区的时候会调用write_unlock释放锁。write_unlock实现如下。
- static inline void arch_write_unlock(arch_rwlock_t *rw)
- {
- rw->lock = 0; /* 1 */
- sev(); /* 2 */
- }
- 同样由于写者是排他的,因此只需要将rw->lock置0即可。代表没有任何进程进入临界区。毕竟是因为同一时间只能有一个写者进入临界区,当这个写者离开临界区的时候,肯定是意味着现在没有任何进程进入临界区。
- 使用SEV指令唤醒所有的CPU,检查等待状态的进程是否可以获取锁。
以上的代码实现其实会导致写进程饿死现象。例如,A、B、C三个进程进入读临界区,D进程尝试获得写锁,此时只能等待A、B、C三个进程退出临界区。如果在退出之前又有F、G进程进入读临界区,那么将出现D进程饿死现象。
互斥量(mutex)
前文提到的semaphore在初始化count计数的时候,可以分为计数信号量和互斥信号量(二值信号量)。mutex和初始化计数为1的二值信号量有很大的相似之处。他们都可以用做资源互斥。但是mutex却有一个特殊的地方:只有持锁者才能解锁。但是,二值信号量却可以在一个进程中获取信号量,在另一个进程中释放信号量。如果是应用在嵌入式应用的RTOS,针对mutex的实现还会考虑优先级反转问题。
原理
既然mutex是一种二值信号量,因此就不需要像semaphore那样需要一个count计数。由于mutex具有“持锁者才能解锁”的特点,所以我们需要一个变量owner记录持锁进程。释放锁的时候必须是同一个进程才能释放。当然也需要一个链表头,主要用来便利睡眠等待的进程。原理和semaphore及其相似,因此在代码上也有体现。
实现
mutex的实现代码和linux中实现会有差异,但是依然可以为你呈现设计的原理。下面的设计代码更像是部分RTOS中的代码。mutex和semaphore一样,我们需要两个类似的结构体分别描述mutex。
- struct mutex_waiter {
- struct list_head list;
- struct task_struct *task;
- };
- struct mutex {
- long owner;
- struct list_head wait_list;
- };
struct mutex_waiter的list成员是当进程无法获取互斥量的时候挂入mutex的wait_list链表。
首先实现申请互斥量的函数。
- void mutex_take(struct mutex *mutex)
- {
- struct mutex_waiter waiter;
- if (!mutex->owner) {
- mutex->owner = (long)current; /* 1 */
- return;
- }
- waiter.task = current;
- list_add_tail(&waiter.list, &mutex->wait_list); /* 2 */
- schedule(); /* 2 */
- }
- 当mutex->owner的值为0的时候,代表没有任何进程持有锁。因此可以直接申请成功。然后,记录当前申请锁进程的task_struct。
- 既然不能获取互斥量,自然就需要睡眠等待,挂入等待链表。
互斥量的释放代码实现也同样和semaphore有很多相似之处。不信,你看。
int mutex_release(struct mutex *mutex){struct mutex_waiter *waiter;if (mutex->owner != (long)current) /* 1 */return -1;if (list_empty(&mutex->wait_list)) {mutex->owner = 0; /* 2 */return 0;}waiter = list_first_entry(&mutex->wait_list, struct mutex_waiter, list);list_del(&waiter->list);mutex->owner = (long)waiter->task; /* 3 */wake_up_process(waiter->task); /* 4 */return 0;}
- mutex具有“持锁者才能解锁”的特点就是在这行代码体现。
- 如果等待链表没有进程,那么自然只需要将mutex->owner置0,代表没有锁是释放状态。
- mutex->owner的值改成当前可以持锁进程的task_struct。
- 从等待进程链表取出第一个进程,并从链表上移除。然后就是唤醒该进程。
一. 基本概念
● linux内核中产生竞态的原因
SMP对称多处理器 (多核CPU)
比如都要操作LCD
进程和进程之间的抢占共享资源,进程和中断之间发生共享资源的抢占,中断和中断之间的资源抢占(中断是有优先级的)
比如:LCD 网卡 可见的内存 (文件 共享内存 全局变量)。
● 共享资源
文件、硬件设备、共享内存、内核中的全局变量等
● 并发
多任务同时执行,对于单核的CPU来说,宏观上并行,微观上串行。而并发的执行单元对共享资源的访问则很容易导致竞态(Race Conditions)
● 临界区
访问共享资源的代码段
对某段代码而言,可能会在程序中多次被执行,每次执行的过程我们称作代码的执行路径。当两个或多个代码路径要竞争共同的资源的时候,该代码段就是临界区。
二. 解决竞争状态的策略
常用一下四种策略:(速记:中原武林很自信)
1)中断屏蔽(内核空间)
不推荐使用
2)原子操作(内核空间)
事务的原子性:要么做完 ,要么不做
3)自旋锁(内核空间)
自旋锁相应快,逻辑不允许重入,要等待锁释放的
4)信号量 (用户空间)
相对慢,要从睡眠态唤醒
1. 中断屏蔽
中断屏蔽可以保证正在执行的内核执行路径不被中断处理程序抢占,防止竞态的产生,但内核的正常运行依赖于中断机制。在屏蔽中断期间,任何中断都无法得到处理,而必须等待屏蔽解除。所以关中断的时间要非常短, 如果关中断时间过长,可能直接造成内核崩溃,建议在写驱动过程中尽量不使用。
使用流程为:关中断----访问共享资源----开中断
使用方法如下:
local_irq_disable()
local_irq_enable()
//更安全的:
local_irq_save() //保存中断的状态(开/关) 关闭中断
local_irq_restore() //恢复保存的中断状态
1
2
3
4
5
2. 原子操作
原子操作底层表现为一条汇编指令(ldrex、strex)。所以他们在执行过程中不会被别的代码路径所中断。
事务的原子性就是要么做完 要么不做。而如何实现的原子性不被打断,不需要去关注,内核中实现的原子操作都是与CPU架构息息相关的,只需要掌握原子的使用方法即可。
很好理解,用上厕所的例子来说明。厕所就是共享资源,去上厕所的行为被称作代码路径。
原子操作就是大家每次上厕所都用时非常短,短到什么程度呢,只要一条汇编指令的时间。当然拉的量也非常少(只改变一个整型或者是位)。所以就不存在抢厕所的问题了。
2.1 位原子操作
// arch/arm/include/asm/bitops.h
set_bit(nr, void *addr) // addr内存中的nr位置1
clear_bit
change_bit
test_bit
...
1
2
3
4
5
6
2.2 整型原子操作
使用步骤:
//1)定义原子变量 atomic_t tv; //就是用原子变量来代替整形变量
//核心数据结构:
typedef struct {
int counter;
} atomic_t;
//2) 设置初始值的两种方法
tv = ATOMIC_INIT(0); //① 定义原子变量 v 并初始化为0
atomic_set(&tv, i) //② 设置原子变量的值为 i
//3) 操作原子变量
int atomic_read(atomic_t *v) //返回原子变量的值
atomic_add(int i, atomic_t *v); //v += i
atomic_sub(int i, atomic_t *v); //v -= i
atomic_inc(atomic_t *v); //v++;
atomic_dec(atomic_t *v) //v--
...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
代码过长,具体代码:Linux内核的竞态与并发——原子操作实例
3. 自旋锁
多处理器之间设置一个全局变量V,表示锁。并定义当V=1时为锁定状态,V=0时为解锁状态自旋锁同步机制是针对多处理器设计的,属于忙等机制。
自旋锁,逻辑不允许重入,要等待锁释放的,注意以下:
1) 自旋锁的获取与释放逻辑上要保证成对出现
2) 只允许一个持有单元,获取锁不成功原地自旋等待
3) 临界区中不能调用引起阻塞或者睡眠的函数
4) 临界区执行速度要快, 持有自旋锁期间,整个系统几乎不做任务切换,持有自旋锁时间过长,会导致整个系统性能严重下降
5) 避免死锁, A,B互相锁死,可以建议使用spin_trylock(&btn_lock)
还是用上厕所的例子:这次给厕所上把锁,只有拥有这个锁钥匙的人A才能进厕所。进去后把锁锁上,外面的人B急得团团转(自旋),A出来后把锁释放,在门口等着的B拿了钥匙赶紧开了锁进去了。但是缺点就是,B在外面团团转,没有功夫去做别的事情,所以一旦A 上厕所的时间很长,B就浪费了很长时间在自旋上。对系统的性能有所影响。
使用步骤:
// 1)定义一个自旋锁变量:
spinlock_t btn_lock;
// 2) 初始化自旋锁 :
spin_lock_init(&btn_lock)
// 3) 获取自旋锁 (获取权利)
spin_lock(&btn_lock); //获取自旋锁不成功,原地自旋等待,直到锁被释放,获取成功才返回
//或:
int spin_trylock(&btn_lock);//不成功,直接返回一个错误信息,调试的时候可用,可以避免死锁
// 4) 访问共享资源
// 5) 释放自旋锁
spin_unlock(&btn_lock);
1
2
3
4
5
6
7
8
9
10
11
自旋锁还有很多衍生自旋锁:读锁 写锁 顺序锁 内核的大锁:
// 1)定义一个自旋锁变量:
spinlock_t btn_lock;
// 2) 初始化自旋锁 :
spin_lock_init(&btn_lock)
// 3) 获取自旋锁 (获取权利)
unsigned long flags;
spin_lock_irq(&lock); // = spin_lock() + local_irq_disable()
//或
spin_lock_irqsave(&lock, flags); // = spin_lock() local_irq_save()
// 4) 访问共享资源
// 5) 释放自旋锁
spin_unlock_irq(&lock); // = spin_unlock()+ local_irq_enable()
//或
spin_unlock_irqrestore(&lock, flags); // = spin_unlock() + local_irq_restore()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Linux内核的竞态与并发——自旋锁实例
Q:编程时有可能需要在临界区代码中执行阻塞睡眠函数 怎么办?
A:这时可以考虑使用信号量来保护临界区。
4 信号量
在用户空间只有进程的概念。当一个临界区有多个用户态进程竞争时,最好的方法是用信号量保护这个临界区。只有得到信号量进程才能执行临界区代码,当获取不到信号量时,进程进入休眠状态。
因此,我们可以说,信号量是进程级的互斥机制,它代表进程来争夺共享资源,如果竞争失败,就会发生进程上下文切换,当前进程进入睡眠状态,CPU运行其他进程。
此外,信号量在SMP(对称多处理器)系统同样起作用;内核中的信号量也只能用于内核态编程
比方说:一间公共厕所N 个坑位,N 不为 1, 且 N为有限个,算是N个资源。在同一时间可以容纳N个人,当满员的时候,外面的人必须等待里面的人出来,释放一个资源,然后才能在进一个,当他进去之后,厕所又满员了,外面的人还得继续等待……
● 特点:
a.基于自旋锁机制实现的
b.可以有多个持有者,获取信号量不成功睡眠等待
c. 可以调用引起阻塞或者睡眠的函数
d. 用信号量保护的临界区执行速度相对慢(见图二 )
1
2
3
4
● 内核中关于信号量的核心数据结构
struct semaphore {
raw_spinlock_t lock;
unsigned int count;//计数器
...
};
1
2
3
4
5
● 使用步骤:
// 1)定义一个信号量
struct semaphore btn_sem;
// 2) 初始化信号量
void sema_init(&btn_sem, 5); //该信号量可以被5个执行单元持有
//还可以通过以下宏完成信号量的定义和赋值为1
DEFINE_SEMAPHORE(btn_sem);
// 3) 获取信号量,本质就是给其中的计数-1(获取权利)
//成功立即返回,失败使用调用者进程进入睡眠状态(深度睡眠kiii -9都杀不死) ,
//直到可以获取信号量成功才被唤醒、返回
void down(struct semaphore *sem);
//成功立即返回,失败进入可中断的睡眠状态(潜睡眠,可被ctrl+c打断)
//可以获取信号量 + 收到信号(ctrl+c)
int down_interruptible(struct semaphore *sem); //关注返回值
//失败立即返回一个错误信息,不会导致睡眠
//可以在中断上下文中使用
int down_trylock(struct semaphore *sem);
//失败进入可以kill的睡眠状态
int down_killable(struct semaphore *sem);
//获取信号量,指定超时时间为x
//如果获取信号量不成功,对应的进程进入睡眠状态
//可能因为信号量可用而被唤醒/也可能因为定时时间到而被唤醒
int down_timeout(struct semaphore *sem, long jiffies);
// 4) 执行临界区代码,访问共享资源
// 5)释放信号量,本质就是给计数器+1
void up(struct semaphore *sem);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Linux内核的竞态与并发——信号量实例
5 互斥体
在 FreeRTOS 和 UCOS 中也有互斥体,将信号量的值设置为 1 就可以使用信号量进行互斥访问了,虽然可以通过信号量实现互斥,但是 Linux 提供了一个比信号量更专业的机制来进行互斥,它就是互斥体—mutex。互斥访问表示一次只有一个线程可以访问共享资源,不能递归申
请互斥体。在我们编写 Linux 驱动的时候遇到需要互斥访问的地方建议使用 mutex。 Linux 内核
使用 mutex 结构体表示互斥体,定义如下(省略条件编译部分):
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock;
};
1
2
3
4
5
在使用 mutex 之前要先定义一个 mutex 变量。在使用 mutex 的时候要注意如下几点:
①、 mutex 可以导致休眠,因此不能在中断中使用 mutex,中断中只能使用自旋锁。
②、和信号量一样, mutex 保护的临界区可以调用引起阻塞的 API 函数。
③、因为一次只有一个线程可以持有 mutex,因此,必须由 mutex 的持有者释放 mutex。并
且 mutex 不能递归上锁和解锁。
1. 资源
2. 锁的基本概念
互斥锁:
当有一个线程要访问共享资源(临界资源)之前会对线程访问的这段代码(临界区)进行加锁。如果在加锁之后没释放锁之前其他线程要对临界资源进行访问,则这些线程会被阻塞睡眠,直到解锁,如果解锁时有一个或者多个线程阻塞,那么这些锁上的线程就会变成就绪状态,然后第一个变为就绪状态的线程就会获取资源的使用权,并且再次加锁,其他线程继续阻塞等待。
读写锁:
也叫做共享互斥锁,读模式共享,写模式互斥。有点像数据库负载均衡的读写分离模式。它有三种模式:读加锁状态,写加锁状态和不加锁状态。简单来说就是只有一个线程可以占有写模式的读写锁,但是可以有多个线程占用读模式的读写锁。
当写加锁的模式下,任何线程对其进行加锁操作都会被阻塞,直到解锁。
当在读加锁的模式下,任何线程都可以对其进行读加锁的操作,但所有试图进行写加锁操作的线程都会被阻塞。直到所有读线程解锁。但是当读线程太多时,写线程一直被阻塞显然是不对的,所以一个线程想要对其进行写加锁时,就会阻塞读加锁,先让写加锁线程加锁
自旋锁
自旋锁和互斥锁很像,唯一不同的是自旋锁访问加锁资源时,会一直循环的查看是否释放锁。这样要比互斥锁效率高很多,但是只会占用CPU。所以自旋锁适用于多核的CPU。但是还有一个问题是当自旋锁递归调用的时候会造成死锁现象。所以慎重使用自旋锁。
乐观锁
这其实是一种思想,当线程去拿数据的时候,认为别的线程不会修改数据,就不上锁,但是在更新数据的时候会去判断以下其他线程是否修改了数据。通过版本来判断,如果数据被修改了就拒绝更新,之所以叫乐观锁是因为并没有加锁。
悲观锁
当线程去哪数据的时候,总以为别的线程会去修改数据,所以它每次拿数据的时候都会上锁,别的线程去拿数据的时候就会阻塞。
这两种锁一般用于数据库,当一个数据库的读操作远远大于写的操作次数时,使用乐观锁会加大数据库的吞吐量。
互斥锁:同一时间,只有一个线程可以访问共享变量。
自选锁:不让线程切换。
原子操作:操作不可分割。
CAS 比较并交换,比较变量有没有被修改。