ICCV 2023 | SuS-X:仅靠类别名称微调CLIP模型,剑桥大学联合DeepMind出品

论文链接: https://arxiv.org/abs/2211.16198
代码仓库: https://github.com/vishaal27/SuS-X
对比语言图像预训练(Contrastive Language-Image Pre-training,CLIP) 已成为计算机视觉社区通向自然语言领域的一种常用的方法,CLIP模型在各种下游任务上都展示除了强大的零样本(zero-shot)分类和检索性能。然而,为了在特定的下游任务上充分发挥其潜力,微调CLIP仍然是一个必需的步骤。对于普通的视觉任务而言,微调时需要访问大量目标任务分布中的图像,因而微调整个CLIP模型可能会占用大量的算力资源并且训练效果并不稳定。
本文介绍一篇来自剑桥大学和DeepMind合作完成的论文,本文已被计算机视觉顶级会议ICCV 2023录用。在本文中作者提出了一种名为SuS-X的微调方法,SuS-X可以实现一种“仅靠名称迁移(name-only transfer)”的效果,即在微调过程中,模型对下游任务所掌握的唯一知识就是下游目标类别的名称。SuS-X由两个关键构建模块“SuS”和“TIP-X”组成,其既不需要密集数据的微调,也不需要昂贵的标记数据,打造了一种全新的微调范式。作者进行了大量的实验来评估SuS-X方法的可行性和性能,SuS-X在多达19个基准数据集上均实现了SOTA零样本分类效果。
01. 介绍
在开始介绍本文工作之前,我们简单回顾一下CLIP模型[1],CLIP是在含有4亿图像文本对的超大规模语料库上训练得到,其使用对比损失来最大化成对图像文本样本之间的相似性。CLIP在视觉语言设置中率先提出了零样本迁移的概念,即可以实现对未见过的样本进行分类。例如给定一个分类任务,CLIP可以直接将类别标签转换为对应类别的文本提示。例如“一个
为了缓解这一问题,本文作者的目标是采用CLIP和其他视觉语言模型(vision language models,VLMs)仅通过名称(仅需要类别名称,而不需要来自目标域的样本)和免训练的方式进行下游分类。本文提出的SuS-X框架如下图所示,其由两个新颖的模块组成:
(1)SuS(支持集,Support Sets),通过设计一种动态支持集管理策略,来实现无需来自目标任务的样本的训练效果。
(2)TIP-X,通过部署一个免训练的适应模块来将支持集得到的类别信息迁移到各种下游任务中。
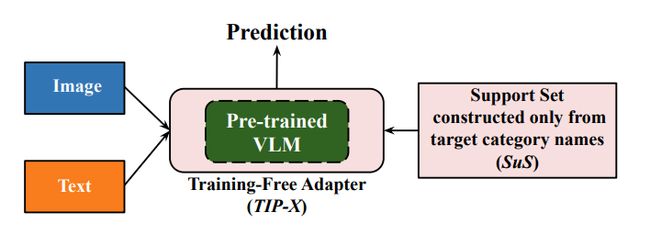
对于给定的下游任务,SuS-X首先利用任务类别标签来构建一个支持集,然后从大型视觉语言数据库中(例如,LAION-5B[2])检索一系列真实场景中的图像。然后将构建好的支持集送入到TIP-X模块中进行下游任务迁移。
02. 方法细节
下图展示了SuS-X的两个主要模块SuS和TIP-X的内部细节,其中SuS模块位于图中右上角,通过构建动态支持集,可以仅基于目标类别名称来将视觉知识注入VLM。TIP-X模块位于图中右下角,是一种新型的免训练方法,可以直接利用图像文本距离来计算支持集和测试图像之间的相似性。
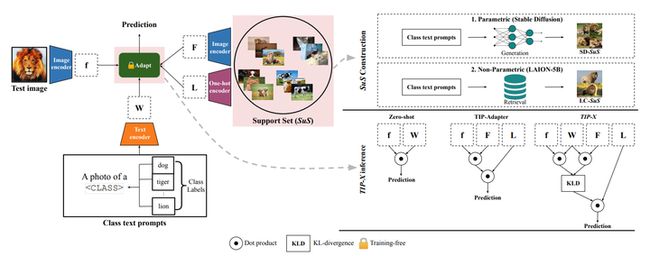
2.1 SuS的构建

2.2 TIP-X免训练推理

03. 实验效果
为了详细的评估SuS-X零样本能力,作者在多达19个数据集上对其进行了测试,并且选择了6个非常流行的baseline方法。为了对比公平,作者将所有参与实验的方法的视觉backbone都设置为ResNet50。下表展示了SuS-X与其他baseline方法分别在Zero-Shot和Name-Only两种实验设置下的性能对比结果。
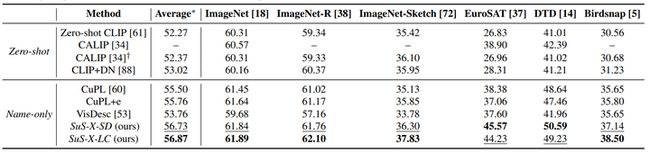
如上表所示,在所有19个数据集上,SuS-X方法的性能均达到了最佳,相比零样本CLIP,性能提升达到了4.6%。 此外,SuS-X相比目前免训练自适应方法中的两个SOTA(CuPL+ensemble 和VisDesc)平均性能提升达到1.1%和3.1%。
3.1 在不同VLM上的迁移效果
为了评估SuS-X方法的泛化性能,作者选用了其他两个常用的VLM进行实验,分别是TCL和BLIP,作者只保留了这些模型的图像和文本编码器来计算特征。下表为实验结果。
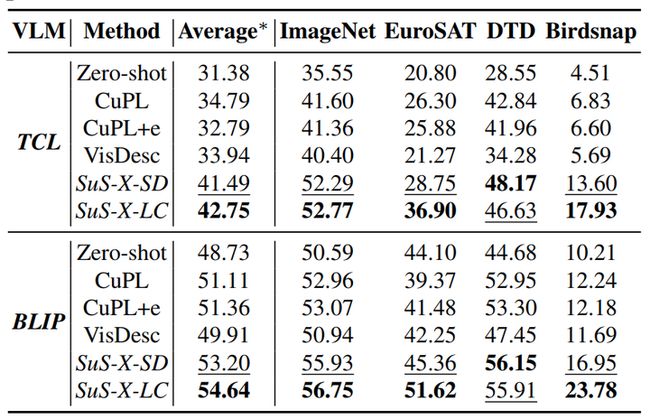
从上表中可以看出,本文提出的SuS-X方法在两个VLM中均明显优于所有基线方法,在19个数据集上的零样本性能平均提高了11.37%和5.97%。这表明本文方法并非特定于CLIP模型,而是可以轻松泛化到其他不同的VLM上。
3.2 从Zero-Shot适应到few-shot
SuS-X方法的一个关键组成部分是TIP-X模块,TIP-X可以直接扩展到few-shot设置上,其中支持集是来自目标域的标记样本。为了在这种真实环境的支持集上评估TIP-X,作者对其进行了免训练的小样本分类实验,并且与同类型的SoTA方法——TIP-Adapter进行比较。下图展示了SuS-X、TIP-Adapter以及Zero-shot CLIP在K-shot分类任务设置上使用了11个数据集子集测试效果,其中K分别取1、2、4、8和16。
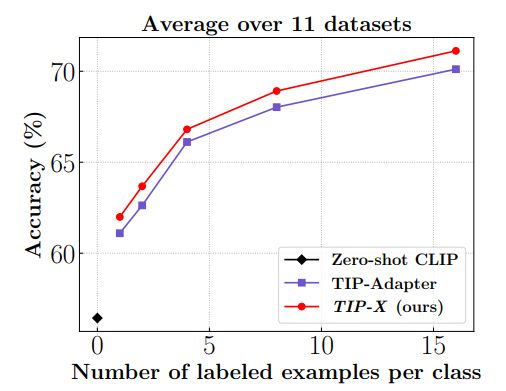
从图中可以看到,TIP-X明显优于Zero-shot CLIP和TIP-Adapter(在不同K-shot上的平均绝对增益为0.91%),这进一步证明了TIP-X方法在适应到few-shot免训练设置方面的通用性。
3.3 对SuS支持集进行可视化
为了进一步展示SuS-X方法的综合能力,作者在下图中可视化了其在ImageNet上构建的两种支持集,其中来自ImageNet的真实图片与SuS包含的支持集图像按照相同的类别名称进行划分。其实我们很难区分真实的ImageNet样本和SuS样本,因此可以使用SuS支持集来模拟真实的数据分布。

04. 总结
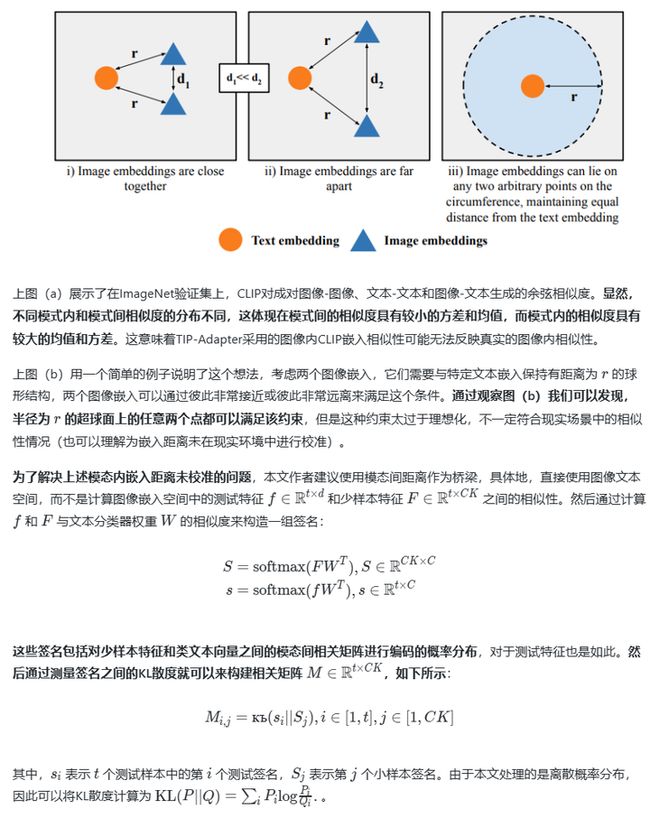
本文针对Zero-shot和Few-shot问题,提出了一种仅通过类别名称迁移的模型免训练新范式,称为SuS-X。SuS-X仍然遵循对比学习原则,可以在多种大型语言视觉模型上完成新任务适应和微调。其首先通过SuS模块系统的构建一个包含丰富知识的支持集,但是无法访问任何目标分布中的样本。随后通过TIP-X模块将原始分类器能力快速迁移到新任务上,这一过程中无需密集数据的微调,也不需要非常标准的标注数据。通过研究SuS-X框架,作者观察到了先前方法中使用CLIP模态内嵌入距离来计算模态相似性的缺陷,并基于本文方法对这种嵌入距离进行了校准。
参考
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021
[2] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. arXiv preprint arXiv:2210.08402, 2022
[3] Renrui Zhang, Wei Zhang, Rongyao Fang, Peng Gao, Kunchang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. Tipadapter: Training-free adaption of clip for few-shot classification. arXiv preprint arXiv:2207.09519, 2022.
作者:seven_
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区