A Simple Baseline for Video Restoration with Grouped Spatial-temporal Shift(ShiftNet)
摘要
视频修复旨在从降质的视频中恢复清晰的帧,具有许多重要的应用。视频修复的关键在于利用帧间信息。然而,现有的深度学习方法往往依赖于复杂的网络架构,如光流估计、可变形卷积和跨帧自注意层,导致计算成本高。在这项研究中,我们提出了一个简单而有效的视频修复框架。我们的方法基于分组空间时间位移(grouped spatial-temporal shift),这是一种轻量级和直观的技术,可以隐式地捕捉多帧聚合的帧间对应关系。通过引入分组空间位移,我们获得了广阔的有效感受野。结合基本的2D卷积,这个简单的框架可以有效地聚合帧间信息。广泛的实验表明,我们的框架在视频去模糊和视频去噪任务上,使用不到前一最先进方法四分之一的计算成本,表现出更好的性能。这些结果表明,我们的方法具有显著降低计算负担的潜力,同时保持高质量的结果。
Introduction
使用手持设备拍摄视频的流行度继续上升。然而,这些视频经常遭受各种类型的退化,包括由于低成本传感器引起的图像噪声和由于相机抖动或物体移动而导致的严重模糊。因此,视频修复在近年来引起了极大的关注。
视频修复方法的关键在于设计组件以实现帧间对齐。虽然一些方法[9、42、43、58、65]采用卷积网络进行多帧融合,但没有明确的对齐,但它们的性能有限。大多数方法依赖于明确的对齐来建立时间对应关系,使用光流[51、66]或可变形卷积[13、75]等技术。然而,这些方法通常需要复杂或计算成本高的网络架构来实现大的感受野,并且它们可能在涉及大位移[30]、帧噪声[10、68]和模糊区域[9、53]的情况下失败。最近,Transformer[14、17、38]成为实现长程感受野的有前途的替代方案。开发了视频修复Transformer(VRT)[35]来模拟长期依赖关系,但其大量的自注意层使其计算成本高。受Swin Transformer[38]的成功启发,大内核卷积[16、39]成为直接解决方案,以获得大的有效感受野。然而,极大的内核(例如内核尺寸>13×13)不能保证改进性能(如图5所示)。
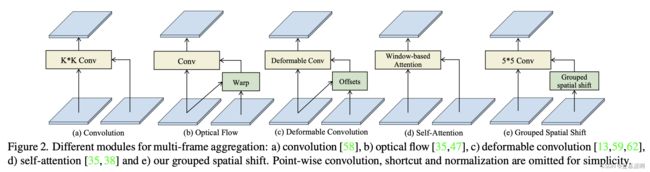
在这项研究中,我们提出了一个简单但有效的空间时间位移块,以实现对于时间对应的大有效感受野。我们引入了一个分组ShiftNet,该ShiftNet将所提出的空间时间位移块用于对齐,并将基本的2D U-Net用于帧级特征编码和恢复。分组的空间时间位移过程涉及在时间和空间维度上分别移动输入剪辑特征,然后使用2D卷积块进行融合。尽管它的计算要求很小,但是移位块提供了大的感受野,用于有效的多帧融合。通过堆叠多个空间时间位移块,实现了长期信息的聚合。这个简化的框架模拟了长期依赖关系,而不依赖于资源密集型的光流估计[22、52、66]、可变形卷积[13、59、62]或自注意[35]。
值得注意的是,尽管时间位移模块(temporal shift module, TSM)[37]最初是用于视频理解的,但它对于视频修复并不有效。我们的方法在三个基本方面与TSM有所区别:a)替代的双向时间位移(Alternative bi-directional temporal shift)。TSM[37]在训练期间采用双向通道位移,导致三帧之间通道错位,从而增加了多帧聚合的难度。相反,我们的方法采用替代的时间位移,有效地解决了这个问题。b)空间位移。此外,我们的方法还将空间位移应用于多帧特征。我们将特征分成几组,在2D维度上具有不同的位移长度和方向。这种分组的空间位移为匹配错位特征提供了多个候选位移。c)特征融合。为了无缝地合并各种位移组,卷积的核大小设置为基本位移长度。通过结合b和c元素,空间时间位移实现了大的感受野(例如23×23)。本研究的贡献有两个方面:1)我们提出了一个简单而有效的视频修复框架,引入了分组的空间时间位移,用于有效和高效的时间特征聚合。2)我们的框架在视频去模糊和视频去噪任务上的计算成本比之前的最先进方法少得多,表明了其泛化能力。
3 Method
3.1 Overview of Group Shift-Net
我们的框架采用了三阶段设计:
1)特征提取,2)带有分组空间时间位移的多帧特征融合,以及3)最终的修复。
1)特征提取。每个帧Ii通常遭受不同类型的退化(例如噪声或模糊),这会影响时间对应关系建模。受[7]的启发,采用2D U-Net-like结构[50]来减轻退化的负面影响并提取逐帧特征。
2)多帧特征融合。在这个阶段,我们提出了一个分组的空间时间位移块,将相邻帧的不同特征组移动到参考帧中,隐式建立时间对应关系。关键帧特征 f i ∈ R h × w × c f_i∈R^{h×w×c} fi∈Rh×w×c与相邻帧的特征完全聚合,以获得相应的聚合特征 A i ∈ R h × w × c A_i∈R^{h×w×c} Ai∈Rh×w×c。采用不同方向和距离的空间时间位移,为匹配帧提供多个候选位移。通过堆叠多个分组的空间时间位移块,我们的框架可以实现长期聚合。
3)最终修复。最后,U-Net-like结构将低质量的输入帧 { I i } i T \{{Ii}\}^T_i {Ii}iT和相应的聚合特征 { A i } i T \{{Ai}\}^T_i {Ai}iT作为输入,并产生每个帧的最终结果 O i O_i Oi。
损失函数采用L1 Loss
3.2. Frame-wise Processing
对于第1阶段的特征提取和第3阶段的最终恢复,我们连续堆叠N个2D slim U-Net来有效地提取特征并进行恢复。 之前曾探索过堆叠多个 U-Net [46],这会导致在相同计算成本下比单个 U-Net [69] 具有更深的网络深度和更大的感受野。 在每个 U-Net 中,我们利用残差块 [19] 来提取特征。 采用平均池化和双线性上采样来调整特征分辨率。 上一个U-Net的输出特征直接传递到下一个U-Net作为输入。 调整堆叠U-Net的数量N和通道以满足不同的计算成本要求。
3.3. Grouped Spatial-temporal Shift
多帧融合中,按帧提取的特征 f i f_i fi与相邻特征 f i − t , . . . , f i + t {f_{i−t}, . . . , f_{i+t}} fi−t,...,fi+t进行聚合,以获取时间上融合的特征 F i F_i Fi。我们采用2D U-Net结构[50]进行多帧融合,并在U-Net中保留跳跃连接。我们通过堆叠多个分组时空移位(GSTS)块来替换几个2D卷积块,以有效建立时间对应关系并进行多帧融合。为节省计算成本,GSTS块不适用于最细的尺度。GSTS块由三个组件组成:1)时间移位,2)空间移位和3)轻量级融合层,按图4所示方式组织。
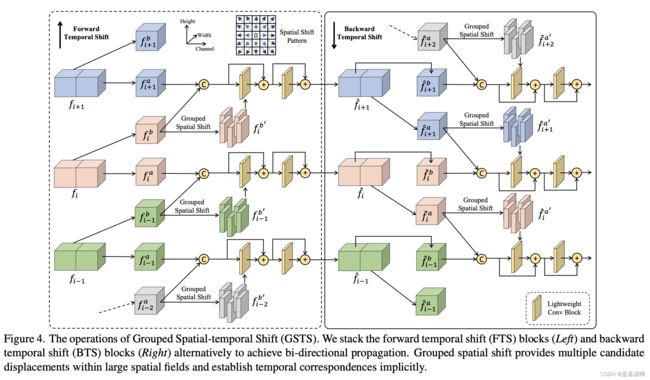
Grouped temporal shift.
我们的实验观察到(表4),同时处理三个帧[37]会增加多帧融合的难度。为了避免这种情况,我们的时间偏移过程仅处理相邻的两个帧。分组时间偏移块是前向时间偏移(FTS)块和后向时间偏移(BTS)块。前向时间偏移块将 f i − 1 , f i {f_{i-1}, f_i} fi−1,fi进行融合(图4左),后向时间偏移块将 f i + 1 , f i {f_{i+1}, f_i} fi+1,fi进行融合(图4右)。为了实现双向聚合,我们交替堆叠FTS块和BTS块。
在时间偏移中,多帧特征 f i ∈ R h × w × c f_i ∈ R^{h×w×c} fi∈Rh×w×c沿通道维度被平均分成两组特征: f i a f^a_i fia和 f i b f^b_i fib,其中 f i a , f i b ∈ R h × w × c / 2 f^a_i, f^b_i∈R^{h×w×c/2} fia,fib∈Rh×w×c/2。在前向偏移中, f i a f^a_i fia不被移动,并与时间i-1的前向移动特征 f i − 1 b f^b_{i-1} fi−1b进行聚合。在后向偏移中, f i a f^a_i fia被后向移动以与 f i b f^b_i fib进行聚合,以还原 I i − 1 I_{i-1} Ii−1。换句话说,无论是FTS块还是BTS块,都保留特征通道的一半(一个特征组)来表征当前时间i的视觉外观,并将另一半通道(另一个特征组)移位以传递信息进行帧间聚合。为简单起见,在以下段落中,我们将解释FTS块的详细信息(即 f i a f^a_i fia如何与 f i − 1 b f^b_{i-1} fi−1b聚合),BTS块的定义类似。
Grouped spatial shift
concat f i a f^a_i fia和 f i − 1 b f^b_{i-1} fi−1b来重建帧i没有考虑帧i和i-1的空间错位。因此,我们对传播的特征组 f i − 1 b ∈ R h × w × c / 2 f^b_{i-1}∈R^{h×w×c/2} fi−1b∈Rh×w×c/2执行额外的空间移位,以实现大空间范围的空间错位。即,先沿通道均等拆分 f i − 1 b f^b_{i-1} fi−1b来获得M个特征切片 f i − 1 , m b ∈ R h × w × c / 2 m f^b_{i-1,m}∈R^{h×w×c/2m} fi−1,mb∈Rh×w×c/2m,其中m=1,…,m是切片索引。对每个特征切片 f i − 1 , m b f^b_{i-1,m} fi−1,mb,我们在x,y方向空间位移(Δxm, Δym)来获得shift的特征切片 f i − 1 , m b f^b_{i-1,m} fi−1,mb
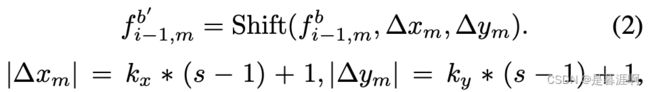
其中 k x 、 k y k_x、k_y kx、ky是整数,s被定义为空间偏移的基础长度。当空间偏移导致边缘出现空白像素时,我们将其设置为零。对于Δxm像素的偏移,相应的特征组将在空间上偏移Δxm-1像素,然后进行深度3×3卷积,该卷积可以处理两个偏移之间的对象,并在相邻的偏移特征切片之间实现平滑的转换。然后,我们沿着通道维度concat所有特征组 f i − 1 , m b ′ f^{b′}_{i-1,m} fi−1,mb′,以获取经空间偏移后的特征 f i − 1 b I f^{b^I}_{i-1} fi−1bI:

例如,当M = 9且Δxm,Δym ∈ {−1,0,1}时,空间移位操作将创建9个特征切片,并将不同的切片沿着9个方向移位。在我们的实现中,我们将M设置为25,Δxm,Δym ∈ {−9,−5,0,5,9},以扩大对齐和融合的感受野,以处理跨帧的大位移。
Fusion layer
我们利用一个融合层F来聚合多帧特征 f i a f^a_i fia, f i − 1 b f^b_{i-1} fi−1b, f i − 1 b ′ f^{b′}_{i−1} fi−1b′。融合层F包含两个轻量级卷积块,每个块采用NAFNet [11]和Super Kernels [56]之间的组合,利用逐点卷积、深度卷积和门控层来避免大量计算。第i帧的输出融合特征 f ^ i \hat{f}_i f^i计算如下:

输出特征 f ^ i \hat{f}_i f^i被馈送到下一个 GSTS 块。 来有效合并移位特征、卷积核大小被设置为等于基本移位长度s。
3.4. How Grouped Spatial Shift Help Restoration?
我们提供了可视化和分析,以探索不同的偏移特征组如何帮助视频恢复。我们将两个相邻的帧输入到Group Shift-Net中。为了分析分组空间移位的特征图,我们从结果特征图中采样一个16×16网格区域。对所有偏移特征在恢复16×16网格中的贡献权重进行局部属性映射(LAM)[18]分析。贡献权重可视化为图6中的红点。当点的颜色更饱和时,本地区域在恢复中更为重要。结果表明,当偏移方向与 I i − 1 I_{i-1} Ii−1和 I i I_i Ii之间的运动方向相似时,偏移特征在恢复 O i O_i Oi时更为重要。此外,我们的方法可以获得扩张的有效感受野,用于建立时间对应关系。
