强化学习:基于pygame和pytorch实现ppo算法在扫雷小游戏上的AI决策
目录
一.介绍
二.环境搭建
一.实现代码
二.效果展示
编辑
三.PPO算法
一.PPO算法介绍
二.代码实现
一.policy和value网络设定
二.PPO类定义
四.环境交互
一.主函数定义
二.训练结果展示
五.总结
文章完整源码:github源码
一.介绍
扫雷游戏是一种单人游戏,其目标是在一个方形区域内找到并标记出所有地雷。游戏板可以被分成若干个格子,每个格子可以为没有地雷的空或一个地雷。玩家可以点击面板上的不同格子来探测地雷的位置,并使用旗帜标记出潜在的地雷以避免触雷。这个游戏的难度级别通常可以由不同的元素来调整,包括面板尺寸、地雷密度等等。
强化学习是一种可以让机器自我提高的机器学习技术。在扫雷游戏中应用强化学习技术可以使AI模型在没有人类指导的情况下学习并提高其决策能力。强化学习使AI能够自主地探索和试验不同的决策,并逐渐改进其决策能力。这种技术特别适用于扫雷游戏,因为游戏中充满了未知的、不确定的可能性,需要AI模型有能力自主地探索,并逐渐学习如何在未知情况下做出更好的决策。
PPO算法(Proximal Policy Optimization)是一种特别适用于扫雷游戏的强化学习算法。它基于一个近邻政策优化算法,经过了一些逐渐改进和优化的步骤,以获得更好的AI决策性能。使用PPO算法可以允许AI模型在扫雷游戏上自己学习如何进行最优化的决策,并从中获取最大的利益。
当使用强化学习技术来玩扫雷游戏时,实际上是让AI模型去学习扫雷游戏中的最佳策略,以便在按照策略行动时最大化成功的可能性。强化学习可以帮助AI模型自主地探索各种策略并逐渐提高其决策能力。在扫雷游戏中应用强化学习技术的好处在于,游戏的情况与人类玩家具有不同的难度和挑战性,因为它需要玩家在面对不同的环境和情境时做出正确的决策。但是,AI模型在没有任何人类指导的情况下可以通过强化学习来自行找到最佳策略,并在游戏中取得最佳表现。这也是强化学习在扫雷游戏中应用的重要意义之一。
具体来说,当AI模型使用PPO算法在扫雷游戏中学习时,算法将调整松紧有度地优化模型的策略,并通过与环境交互来逐渐改进AI的性能。而这种技术的使用意味着AI模型可以学习如何在不确定和复杂的环境中做出最佳决策,以最大化游戏中的胜利概率。因此,在扫雷游戏中应用强化学习技术可以解决一些较困难的问题,将AI模型的表现提高到更高的水平,并使游戏变得更有乐趣和挑战性。
二.环境搭建
搭建扫雷游戏时,首先要考虑两大内容,一是扫雷游戏机制的真实实现,二是对于智能体交互环境搭建,最后还要考虑与智能体交互展示。所以本人搭建的扫雷游戏设置了三种模式:人机交互式、智能体交互式及可视化智能体交互式。对此本人基于pygame编写了Minesweeper类。
一.实现代码
-
__init__
在类初始化函数中,初始化Minesweeper类是可传递五个参数,分别为:
grid_width(地图宽度) grid_height(地图高度) cell_size(单元格大小) mine_count(地雷数量) window(是否视窗)
def __init__(self, grid_width=10, grid_height=10, cell_size=50, mine_count=13, window=True):
self.GRID_WIDTH = grid_width
self.GRID_HEIGHT = grid_height
self.CELL_SIZE = cell_size
self.MINE_COUNT = mine_count
self.RED = (255, 0, 0)
self.WHITE = (255, 255, 255)
self.BLACK = (0, 0, 0)
self.GREY = (128, 128, 128)
self.font = pygame.font.SysFont(None, 30)
self.window = window
self.akc = False
if self.window:
pygame.display.set_caption("Minesweeper")
self.screen = pygame.display.set_mode((self.GRID_WIDTH * self.CELL_SIZE, self.GRID_HEIGHT * self.CELL_SIZE))
self.r = 0.
self.R = []
self.actions = []
self.condition = True
self.map = np.zeros([self.GRID_WIDTH, self.GRID_HEIGHT])
self.t = 0
self.count = np.zeros([self.GRID_WIDTH, self.GRID_HEIGHT])
else:
self.r = 0.
self.R = []
self.actions = []
self.condition = True
self.map = np.zeros([self.GRID_WIDTH, self.GRID_HEIGHT])
self.t = 0
self.count = np.zeros([self.GRID_WIDTH, self.GRID_HEIGHT])
self.grid = [[0 for _ in range(self.GRID_HEIGHT)] for _ in range(self.GRID_WIDTH)]
self.mines = []
for i in range(self.MINE_COUNT):
while True:
x = random.randint(0, self.GRID_WIDTH - 1)
y = random.randint(0, self.GRID_HEIGHT - 1)
if (x, y) not in self.mines:
self.mines.append((x, y))
self.grid[x][y] = -1
break
self.revealed = np.array([[False for _ in range(self.GRID_HEIGHT)] for _ in range(self.GRID_WIDTH)])
if not self.window:
self.status = self.get_status()
else:
self.status = self.get_status()代码实现了扫雷游戏的一些常量元素的定义,设置了pygame的视窗元素,以及定义了环境交互的元素和相关信息
-
get_adjacent_cells
函数getadjacentcells的实现功能是获取目标位置的相邻元素格。具体实现是通过遍历目标位置周围的格子,将其添加到一个列表中并返回。
def get_adjacent_cells(self, x, y):
cells = []
for i in range(max(0, x - 1), min(x + 2, self.GRID_WIDTH)):
for j in range(max(0, y - 1), min(y + 2, self.GRID_HEIGHT)):
if i != x or j != y:
cells.append((i, j))
return cells函数接受两个参数x和y,表示目标位置的坐标。函数通过遍历目标位置周围的格子,将其添加到一个列表中并返回。具体实现是通过两个for循环遍历目标位置周围的格子,将其添加到一个列表中。在遍历时,需要注意边界情况,即不能超出地图的范围。同时,需要排除目标位置本身,因为目标位置不是相邻元素格。最后,函数返回一个包含相邻元素格坐标的列表。
-
get_status
类的子函数 get_status的功能为获取环境当前状态,状态为当前游戏中每个格子的信息(未揭示为1)和点击次数,用作为智能体的输入信息,其返回参数为状态信息status
def get_status(self):
status = (self.revealed.astype(np.float64) - 1) + self.map
status = np.stack((status, self.count), axis=0)
return status-
reveal_cell
函数reveal_cell的实现功能是揭示指定位置的格子。具体实现是通过获取目标位置的相邻元素格,计算相邻元素格中地雷的数量,然后将目标位置的状态设置为已揭示并更新相关元素。
def reveal_cell(self, x, y):
self.revealed[x][y] = True
if self.window:
rect = pygame.Rect(x * self.CELL_SIZE, y * self.CELL_SIZE, self.CELL_SIZE, self.CELL_SIZE)
pygame.draw.rect(self.screen, self.WHITE, rect)
if self.grid[x][y] == -1:
self.map[x, y] = -10
pygame.draw.circle(self.screen, self.RED, rect.center, self.CELL_SIZE // 3)
else:
pygame.draw.rect(self.screen, self.GREY, rect)
self.map[x, y] = self.count_adjacent_mines(x, y)
if self.count_adjacent_mines(x, y) >= 0:
text = self.font.render(str(self.count_adjacent_mines(x, y)), True, self.BLACK)
text_rect = text.get_rect(center=rect.center)
self.screen.blit(text, text_rect)
else:
if self.grid[x][y] == -1:
self.map[x, y] = -10
else:
self.map[x, y] = self.count_adjacent_mines(x, y)函数接受两个参数x和y,表示目标位置的坐标。函数首先判断目标位置是否为地雷,如果是地雷,则揭示所有位置并将游戏状态设置为失败;否则,将目标位置的状态设置为已揭示,并计算相邻元素格中地雷的数量。如果相邻元素格中没有地雷,则递归调用reveal_cell函数揭示相邻元素格。
-
reveal_all_cells
函数reveal_all_cells的实现功能是将所有未揭示的格子都揭示出来。具体实现是遍历整个游戏区域,将所有未揭示的格子都揭示出来。
def reveal_all_cells(self):
for i in range(self.GRID_WIDTH):
for j in range(self.GRID_HEIGHT):
if not self.revealed[i][j]:
self.reveal_cell(i, j)函数没有参数,遍历整个游戏区域,将所有未揭示的格子都揭示出来。在遍历过程中,如果发现某个格子未揭示,则调用reveal_cell函数揭示该格子。
-
agent_click
函数agent_click的实现功能是智能体点击指定位置的格子。具体实现是调用reveal_cell函数揭示指定位置的格子,并判断点击位置是否无效(已被揭示)或是地雷。且据此给出相应奖励。该函数在与智能体交互时使用
def agent_click(self, x, y):
if self.revealed[x][y]:
self.r += 0.
elif self.grid[x][y] != -1:
self.reveal_cell(x, y)
self.r = 1.
if self.count_adjacent_mines(x, y) == 0:
for i, j in self.get_adjacent_cells(x, y):
if self.grid[i][j] != -1 and not self.revealed[i][j]:
self.agent_click(i, j)
else:
self.reveal_all_cells()
self.r += 0.
self.condition = False-
handle_left_click
函数handle_left_click的实现功能与是处理鼠标左键点击事件 ,具体功能与函数agent_click类似,最不同的地方是当点击到雷时会重置游戏。
def handle_left_click(self, x, y):
if self.revealed[x][y]:
self.r += 0.
elif self.grid[x][y] != -1:
self.reveal_cell(x, y)
self.r = 1.
if self.count_adjacent_mines(x, y) == 0:
for i, j in self.get_adjacent_cells(x, y):
if self.grid[i][j] != -1 and not self.revealed[i][j]:
self.handle_left_click(i, j)
else:
self.reveal_all_cells()
self.r += 0.
self.condition = False
pygame.display.flip()
if self.akc:
time.sleep(2.)
self.reset()-
draw_grid
函数draw_grid的实现功能是在游戏窗口中绘制/更新游戏区域的网格。具体实现是使用pygame库中的draw模块,绘制游戏区域的水平和垂直线条,并显示揭示格子的信息。
def draw_grid(self):
for i in range(self.GRID_WIDTH):
for j in range(self.GRID_HEIGHT):
rect = pygame.Rect(i * self.CELL_SIZE, j * self.CELL_SIZE, self.CELL_SIZE, self.CELL_SIZE)
pygame.draw.rect(self.screen, self.WHITE, rect, 1)
if self.revealed[i][j]:
if self.grid[i][j] == -1:
pygame.draw.circle(self.screen, self.RED, rect.center, self.CELL_SIZE // 3)
else:
pygame.draw.rect(self.screen, self.GREY, rect)
if self.count_adjacent_mines(i, j) > 0:
text = self.font.render(str(self.count_adjacent_mines(i, j)), True, self.BLACK)
text_rect = text.get_rect(center=rect.center)
self.screen.blit(text, text_rect)函数没有参数,使用pygame库中的draw模块,绘制游戏区域的水平和垂直线条。在绘制水平线条时,循环次数为self.width + 1,绘制的起点和终点分别为(self.x + i*CELL_SIZE, self.y)和(self.x + i *CELL_SIZE, self.y + self.height*CELL_SIZE);在绘制垂直线条时,循环次数为self.height + 1,绘制的起点和终点分别为(self.x, self.y + j*CELL_SIZE)和(self.x + self.width*CELL_SIZE, self.y + j*CELL_SIZE)。如果绘制位置为地雷则显示红色白底圆圈,如果绘制位置周围有地雷,则显示地雷个数。
-
count_adjacent_mines
函数count_adjacent_mines的实现功能是计算指定位置周围的地雷数量
def count_adjacent_mines(self, x, y):
count = 0
for i, j in self.get_adjacent_cells(x, y):
if self.grid[i][j] == -1:
count += 1
return count函数接受两个参数x和y,表示目标位置的坐标。函数首先初始化计数器count为0,然后使用两个嵌套的循环遍历目标位置周围的所有位置。对于每个位置,如果该位置是地雷,则将计数器count加1。最后返回计数器count的值,即为指定位置周围的地雷数量。
-
reset
函数reset的实现功能是重置游戏状态和游戏区域,函数会初始化所有游戏元素和环境元素的状态,并在self.running=True时重置游戏视窗。
def reset(self):
self.grid = [[0 for _ in range(self.GRID_HEIGHT)] for _ in range(self.GRID_WIDTH)]
self.mines = []
for i in range(self.MINE_COUNT):
while True:
x = random.randint(0, self.GRID_WIDTH - 1)
y = random.randint(0, self.GRID_HEIGHT - 1)
if (x, y) not in self.mines:
self.mines.append((x, y))
self.grid[x][y] = -1
break
self.revealed = np.array(
[[False for _ in range(self.GRID_HEIGHT)] for _ in range(self.GRID_WIDTH)])
if not self.window:
self.r = 0.
self.R = []
self.actions = []
self.condition = True
self.map = np.zeros([self.GRID_WIDTH, self.GRID_HEIGHT])
self.status = self.get_status()
self.t = 0
self.count = np.zeros([self.GRID_WIDTH, self.GRID_HEIGHT])
else:
self.r = 0.
self.R = []
self.actions = []
self.condition = True
self.map = np.zeros([self.GRID_WIDTH, self.GRID_HEIGHT])
self.status = self.get_status()
self.t = 0
self.count = np.zeros([self.GRID_WIDTH, self.GRID_HEIGHT])
self.screen = pygame.display.set_mode(
(self.GRID_WIDTH * self.CELL_SIZE, self.GRID_HEIGHT * self.CELL_SIZE))
self.screen.fill(self.BLACK)
self.draw_grid()
pygame.display.flip()-
update
函数update的实现功能是更新的环境游戏状态。函数接受一个参数a,表示智能体选择的动作(格子的坐标),函数首先会揭示该位置(其它参数更新再次过程中进行),并更新点击状态,之后函数会判断游戏是否达到胜利条件,如果达到则返回高额奖励并更新游戏状态为False表示游戏结束,否则则判断交互次数是否达到阈值(50)次,如果达到则更新游戏状态为False表示游戏结束。最后函数返回给智能体游戏的状态信息,奖励,游戏状态等信息。
def update(self, a):
[x, y] = a
self.r = 0.
self.agent_click(x, y)
self.count[x, y] += 1
if self.revealed.sum() <= (self.GRID_WIDTH * self.GRID_HEIGHT - self.MINE_COUNT) and self.revealed.sum() >= (
self.GRID_WIDTH * self.GRID_HEIGHT - self.MINE_COUNT - 10):
self.r = 50.
self.condition = False
self.status = self.get_status()
self.R.append(self.r)
self.actions.append([x, y])
self.t += 1
if self.t == 50:
self.condition = False
self.r = 0.
return [torch.tensor(self.status, dtype=torch.float32), self.r, self.condition]-
agengt_run
函数agent_run的实现功能是智能体与游戏的可视化交互,函数接收智能体的决策a,并更新视窗,具体功能与函数undate相似。
def agengt_run(self, a):
[x, y] = a
self.r = 0.
self.handle_left_click(x, y)
self.draw_grid()
pygame.display.flip()
self.count[x, y] += 1
if self.revealed.sum() <= (self.GRID_WIDTH * self.GRID_HEIGHT - self.MINE_COUNT) and self.revealed.sum() >= (
self.GRID_WIDTH * self.GRID_HEIGHT - self.MINE_COUNT - 10):
self.r = 10.
self.condition = False
self.status = self.get_status()
self.R.append(self.r)
self.actions.append([x, y])
self.t += 1
if self.t == 50:
self.condition = False
self.r = 0.
return [torch.tensor(self.status, dtype=torch.float32), self.r, self.condition]-
run
run函数实现功能是人机交互时处理事件和更新游戏状态的游戏主循环。函数首先将akc属性设置为True,将running属性设置为True。然后,它进入一个while循环,只要运行为True,该循环就会运行。在while循环中,它使用for循环来处理事件,该循环迭代事件队列中的所有事件。如果事件是一个QUIT事件,它会将running设置为False以退出循环。如果事件是MOUSEBUTTONDOWN事件,它会获取鼠标单击的位置,并将其转换为游戏网格中的相应单元格。如果鼠标按钮是左键,那么它将使用单元格坐标调用handle_left_click函数。如果鼠标按钮是右键,它将使用单元格坐标调用handle_right_click函数。处理完事件后,它使用draw_grid函数绘制游戏网格,并使用pygame.display.fip()更新屏幕。一旦循环退出,它就会使用pygames.quit()退出pygame。
def run(self):
# 设置视频驱动为dummy
# os.environ['SDL_VIDEODRIVER'] = 'dummy'
self.akc = True
self.running = True
while self.running:
for event in pygame.event.get():
if event.type == pygame.QUIT:
self.running = False
elif event.type == pygame.MOUSEBUTTONDOWN:
x, y = event.pos
x //= self.CELL_SIZE
y //= self.CELL_SIZE
if event.button == 1:
self.handle_left_click(x, y)
elif event.button == 3:
self.handle_right_click(x, y)
self.draw_grid()
pygame.display.flip()
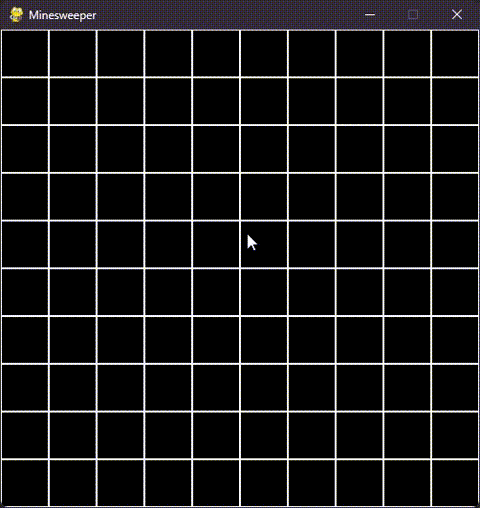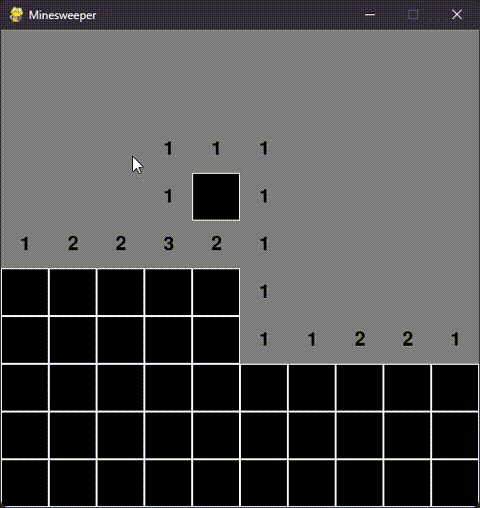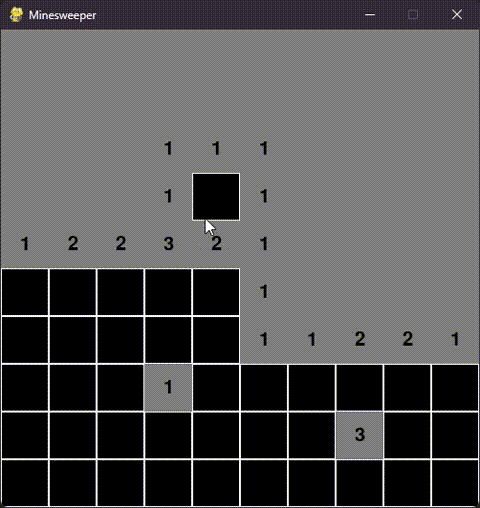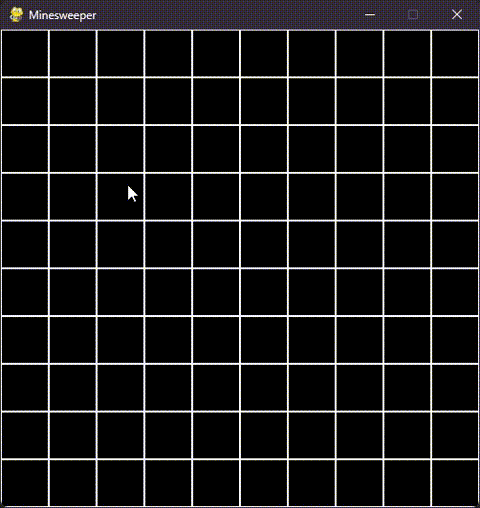
pygame.quit()二.效果展示
目前演示人机交互时,代码运行结果,当执行以下代码时:
if __name__=='__main__':
minesweeper = Minesweeper()
minesweeper.run()会出现可视化窗口,结果如图:

效果如下:
三.PPO算法
一.PPO算法介绍
PPO(Proximal Policy Optimization)算法是一种强化学习算法,旨在解决学习策略的连续优化问题,特别是针对连续动作空间的问题,PPO算法的理论原理主要基于两个方面:策略梯度定理和近端策略优化。
策略梯度定理:策略梯度定理指出策略函数的梯度可以被用来更新策略函数,从而提高智能体的性能。具体来说,策略梯度定理可以被用来计算策略函数的梯度,以最大化预期回报。
近端策略优化:近端策略优化是PPO算法的核心思想。近端策略优化通过限制策略更新的步幅,来保证策略函数的稳定性。具体来说,PPO算法使用了一种称为“裁剪”的技术,通过比较当前策略函数和旧策略函数的比率,来确定裁剪比例。这样可以保证策略函数的更新不会过大,从而避免过度拟合和不稳定性。
PPO算法的具体实现方法可以分解为两个方面: 更新策略以及梯度裁剪。
首先,对于策略的更新。PPO算法采用一种称为Proximal Policy Objective的目标函数来更新策略。其目标是最大化目标函数Jθ(πθ,πold) – βKL(πold||πθ),其中πold是当前策略,πθ是更新后的策略,βKL是一个控制更新步长的参数。目标函数实际上是由两个独立的部分组成的。第一个部分是我们希望最大化的累积奖励的期望值,第二个部分是我们想要最小化的KL散度。目标函数中的KL散度实际上是我们给出足够的余地来调整更新步长,以免更新步伐太大导致新的策略跳过了我们希望优化的重要状态。
其次,对于梯度裁剪。在训练神经网络时,梯度更新可能会导致梯度爆炸或梯度消失的问题。为了应对这些问题,PPO算法使用两种梯度裁剪方法,即clip和surrogate分别用于policy gradient以及value function的更新。clip使用一个超级参数epsilon定义一个上下限范围,以限制梯度增量的大小。然后,当前网络的概率分布和旧网络的概率分布相比较,以保证在新旧策略之间只进行小的概率变更。Surrogate则以一种先验方式,通过测量新旧策略之间的相对概率,来度量选择新策略的程度。这个度量实际上也会影响policy和value函数的更新。
对于此PPO算法,本人则使用的是基于梯度裁剪方法的PPO算法实现。因为对于此问题,相比于更新策略,梯度裁剪方法可以使得更新过程中,新旧策略之间的距离控制得更好,且梯度裁剪方法可以使得更新过程中的梯度平稳变化,在学习过程中提高了稳定性,可以进一步保证学习结果的可靠性。
详细的PPO算法原理介绍可以参看文章:Proximal Policy Optimization(PPO)算法原理及实现
如有对强化学习研究感兴趣的朋友可以看PPO算法原文:Proximal Policy Optimization Algorithms
二.代码实现
一.policy和value网络设定
对于此扫雷游戏的环境设定,网络输入的数据张量形状为[b,2,w,h],其中b为batch_size,w、h分别为游戏横、纵格子数量,其中w、h默设置认为10。
policy分别设置了两种网络结构,分别为卷积网络结构(CNN)和全连接网络结构(DNN),两种网络输出维度为[b,w*h]
class Action1(nn.Module):
def __init__(self,input_shape=[10,10]):
super(Action1,self).__init__()
self.input_dim=input_shape
self.conv_layers = nn.Sequential(
nn.Conv2d(in_channels=2, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=1, kernel_size=3, stride=1, padding=1),
)
self.softmax = nn.Softmax(dim=1)
self.relu = nn.ReLU()
def forward(self,x):
x=self.conv_layers(x).view(x.shape[0],-1)
out = self.softmax(x)
return out
class Action2(nn.Module):
def __init__(self,input_shape=[10,10]):
super(Action2,self).__init__()
self.input_dim=input_shape[0]*input_shape[1]
self.output_dim=(input_shape[0]+6)*(input_shape[1]+6)
self.liner=nn.Linear(self.input_dim,512)
self.liner2=nn.Linear(512,self.output_dim)
self.liner3 = nn.Linear(self.output_dim,self.input_dim)
self.softmax = nn.Softmax(dim=1)
self.relu = nn.ReLU()
def forward(self,x):
x=x.view(x.shape[0],-1)
x=self.relu(self.liner(x))
x=self.relu(self.liner2(x))
out=self.softmax(self.liner3(x))
return outvalue网络结构输出维度则是[b,1]
class Bvalue(nn.Module):
def __init__(self):
super(Bvalue,self).__init__()
self.relu = nn.ReLU()
self.liner=nn.Linear(200,256)
self.liner2=nn.Linear(256,512)
self.liner3 = nn.Linear(512,1)
def forward(self,x):
x = x.view(x.shape[0], -1)
x=self.relu(self.liner(x))
x=self.relu(self.liner2(x))
# out=self.relu(self.liner3(x))
out = self.liner3(x)
return out二.PPO类定义
PPO算法初始化时接受input_shape,up_time,batch_size,a_lr,b_lr,gama,epsilon七个参数,分别代表这游戏环境网格大小、一次交互训练次数、数据批量大小、policy网络学习率、value网络、价值超参数以及clip,PPO定义了序列池suffer、智能体网络和价值网络以及其对于的Adam梯度优化其和用来计算价值网络损失的损失函数loss。
def __init__(self,input_shape=[10,10],up_time=10,batch_size=32,a_lr=1e-5,b_lr=1e-5,gama=0.9,epsilon=0.1):
self.up_time=up_time
self.batch_size=batch_size
self.gama=gama
self.epsilon=epsilon
self.suffer = []
self.action = Action1(input_shape)
self.action.to(device)
self.bvalue = Bvalue()
self.bvalue.to(device)
self.acoptim = optim.Adam(self.action.parameters(), lr=a_lr)
self.boptim = optim.Adam(self.bvalue.parameters(), lr=b_lr)
self.loss = nn.MSELoss().to(device)
self.old_prob = []update(self)函数是PPO中用于更新策略和价值网络的主函数,实现了PPO算法的核心训练循环。
首先,函数从存储在self.suffer列表中的经验缓冲区中检索状态、动作、奖励、完成标志和旧动作概率。
然后,它使用折扣因子self.gama计算每个经验的折扣奖励。
之后,该函数按照指定迭代次数(self.up_time)来训练策略和价值网络。对于每次迭代,都会从缓冲区中随机抽取一批经验,并使用采样的索引将折扣奖励计算为价值网络的目标值。
其次,使用当前价值网络计算相同批次状态的预测值。
最后,通过从目标值中减去预测值来计算优势估计,并使用PPO损失函数更新策略网络。使用预测值和目标值之间的均方误差损失更新价值网络。
def update(self):
states = torch.stack([t.state for t in self.suffer],dim=0).to(device)
actions = torch.tensor([t.ac for t in self.suffer], dtype=torch.int).to(device)
rewards = [t.reward for t in self.suffer]
done=[t.done for t in self.suffer]
old_probs = torch.tensor([t.ac_prob for t in self.suffer], dtype=torch.float32).to(device) # .detach()
false_indexes = [i+1 for i, val in enumerate(done) if not val]
if len(false_indexes)>=0:
idx,reward_all=0,[]
for i in false_indexes:
reward=rewards[idx:i]
R = 0
Rs = []
reward.reverse()
for r in reward:
R = r + R * self.gama
Rs.append(R)
Rs.reverse()
reward_all.extend(Rs)
idx=i
else:
R = 0
reward_all = []
rewards.reverse()
for r in rewards:
R = r + R * self.gama
reward_all.append(R)
reward_all.reverse()
Rs = torch.tensor(reward_all, dtype=torch.float32).to(device)
for _ in range(self.up_time):
self.action.train()
self.bvalue.train()
for n in range(max(10, int(10 * len(self.suffer) / self.batch_size))):
index = torch.tensor(random.sample(range(len(self.suffer)), self.batch_size), dtype=torch.int64).to(device)
v_target = torch.index_select(Rs, dim=0, index=index).unsqueeze(dim=1)
v = self.bvalue(torch.index_select(states, 0, index))
adta = v_target - v
adta = adta.detach()
probs = self.action(torch.index_select(states, 0, index))
pro_index = torch.index_select(actions,0,index).to(torch.int64)
probs_a = torch.gather(probs, 1, pro_index)
ratio = probs_a / torch.index_select(old_probs, 0, index).to(device)
surr1 = ratio * adta
surr2 = torch.clip(ratio, 1 - self.epsilon, 1 + self.epsilon) * adta.to(device)
action_loss = -torch.mean(torch.minimum(surr1, surr2))
self.acoptim.zero_grad()
action_loss.backward(retain_graph=True)
self.acoptim.step()
bvalue_loss = self.loss(v_target, v)
self.boptim.zero_grad()
bvalue_loss.backward()
self.boptim.step()
self.suffer = []
四.环境交互
一.主函数定义
最后一步,编写一个主函数mian.py文件将PPO算法与扫雷游戏交互起来,进行智能体的训练、展示等内容。
训练函数trian函数接受四个参数:times、x、y 和 mine_num。这些参数分别指定了要运行的迭代次数、扫雷网格的宽度和高度以及要放置的地雷数量。
首先,函数初始化了一个扫雷环境和一个 PPO 代理网络。
然后,函数运行了一个循环,循环次数为指定的迭代次数。在每个迭代中,函数运行了另一个循环,循环次数为指定的 epoch 数。在每个 epoch 中,函数重置了扫雷环境,获取了环境的当前状态,并使用 PPO 代理根据当前状态选择一个动作。然后,函数使用所选动作更新环境,记录结果状态、奖励和完成状态,并将此信息添加到缓冲区中。如果缓冲区大于指定的批量大小,则使用缓冲区的内容更新 PPO 代理。
之后,在所有迭代和 epoch 完成后,将保存 PPO 代理的动作网络到文件中。
最后,函数计算每组 50 次迭代的平均奖励,并使用 pyecharts 库将这些值绘制在一条线图上。
def train(times,x,y,mine_num):
env=Minesweeper(grid_width=x,grid_height=y,mine_count=mine_num,window=False)
net=PPO(input_shape=[x,y],up_time=up_time,batch_size=batch_size,a_lr=a_lr,b_lr=b_lr,gama=gama,epsilon=epsilon)
# path='net_model.pt'
# net.load_net(path)
Rs=[]
for i in range(times):
with tqdm(total=epoch, desc='Iteration %d' % i) as pbar:
for e in range(epoch):
env.reset()
s=torch.tensor(env.get_status(),dtype=torch.float32)
while env.condition and env.t<51:
a,a_p=net.get_action(s)
at=get_a(a[0],x,y)
[s_t,r,d]=env.update(at)
buffer=Transition(s,a,a_p,r,d)
net.appdend(buffer)
s=s_t
R=np.array(env.R).sum()
Rs.append(R)
if len(net.suffer)>batch_size:
net.update()
pbar.set_postfix({'return': '%.2f' % R})
pbar.update(1)
torch.save(net.action,'net_model.pt')
Re=[]
for i in range(int(len(Rs)/50)):
idx=i*50
Re.append(sum(Rs[idx:idx+50])/50)
x=[str(i) for i in range(len(Re))]
line=Line()
line.add_xaxis(xaxis_data=x)
line.add_yaxis(y_axis=Re,series_name='Recall')
line.render('result.html')网络训练完成之后,调用test()函数对训练的结果进行展示
def test(path,x=10,y=10,mine_num=10):
env = Minesweeper(grid_width=x, grid_height=y, mine_count=mine_num)
net = torch.load(path)
device = torch.device("cpu")
net = net.to(device)
s = torch.tensor(env.get_status(), dtype=torch.float32)
a_p = 0
for i in range(5):
while env.condition:
a, a_p = test_get_action(s, net, x_idx=x, y_idx=y, a_p=a_p)
[s_t, r, d] = env.agengt_run(a)
time.sleep(1.)
s = s_t
env.reset()二.训练结果展示
当超参数batch_size=32,a_lr=0.0001,b_lr=0.002,gama=0.995,epsilon=0.2,up_time=10,epoch=50时,执行代码
mian(times=100,x=10,y=10,mine_num=10)
训练结果如下:
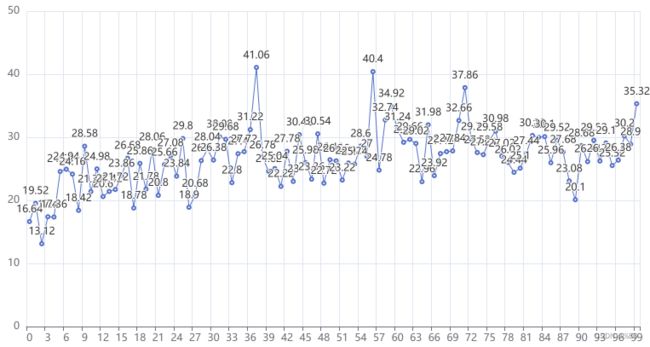
最终智能体获得的奖励回报在32左右除去开始时10%(地雷数/格子总数)随机失败概率,智能体的成功率平均在70%左右,最高阶段的成功率在85%左右。下面是智能体的效果演示:

五.总结
此博客介绍了强化学习PPO算法在扫雷游戏上的应用,代码基于pygame和pytorch实现,其中游戏环境为自行搭建,游戏实现基本的扫雷游戏机制且更易与PPO算法进行交互。文章主要写了以强化学习为主的相关说明以及环境代码和PPO算法代码的实现,并介绍了主要代码的具体实现内容,最后展示了算法的训练过程和运行效果。总体来说代码不够完善,还是有许多不足,算法最终效果也有待提高。最后,希望文章能给大家在学习之路上带来帮助。
CSDN作为程序员分享交流社区,社区中拥有非常丰富且开源的资源,是国人的技术交流平台,它帮助许多相关领域人员解决了各种技术、知识上的“疑难杂症”,本人也是其中之一,从入门小白到现在,CSDN帮助了我许多,在学习之路伴我前行。所谓知恩报德、授之以渔,也希望今后CSDN能帮助更多人解决更多问题,这也是本人发布这个篇博客的主要原因。感谢CSDN,感谢每一位博客!
声明
此文章和代码为本人原创,如有转载、参照,望引用