RNN模型与NLP应用笔记(3):Simple RNN模型详解及完整代码实现
一、写在前面
终于到RNN了,这篇文章首先介绍简易RNN模型,我们会以问题导向的方式一步一步对简易RNN模型进行改进。同样本文参考了王树森教授的深度学习课程内容,感谢大佬们提供的帮助。
现在开始讲述循环神经网络Recurrent Neural Networks (RNNs),以及用Keras编程实现Simple RNN, 现在RNN没有以前流行,尤其是在自然语言处理的问题上,RNN已经有些过时了,如果训练数据足够多,RNN的效果不如Transformer模型,但是在小规模的问题上RNN还是很有用的,我们先来学习RNN,之后再来学习Transformer和BERT
目录
一、写在前面
二、引人
三、Simple RNN基本概念
四、关键代码详解
五、Simple RNN的缺陷
六、代码实现
七、总结
八、参考内容
二、引人
机器学习中经常用到文本语音等Sequential date(持续数据)。
思考一个问题,怎样对持续数据来建模?
上节课我们把一段文字整体输入一个线性回归模型,让模型来做二分类这属于one-to-one模型,即一个输入对应一个输出。
全连接神经网络和卷机神经网络都属于one-to-one模型,但是人脑并不用one-to-one模型来处理时序数据,人类并不会把一整段文字全部直接输入大脑 你阅读的时候,你会从左到右阅读一段文字,阅读的时候,逐渐在大脑里积累文本的信息,阅读一段话之后,你脑子就积累了整段文字的大意。

如上图,one-to-one按模型要求一个输入对应一个输出,比如输入一张图片,输出每一类的概率值,该按模型很适合图片的问题,但是不太适合文本问题。
对于文本问题,输入和输出的长度并不固定,一句话可长可短。所以,输入的长度并不固定 输出的长度也不固定,比如把英语翻译成汉语。一句英语有十个单词,翻译成汉语,可能有十个字,可能有八个字,甚至可能是四个字的成语,输出的汉语的字数并不固定。
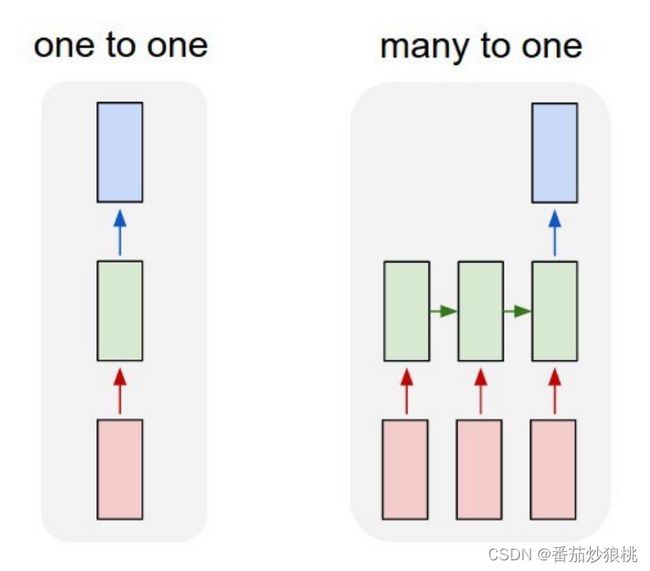
由于输入和输出的长度都不固定,one-to-one模型就不太适合了,对于持续数据更好的模型是many To one或者是many To many模型。
RNN就是这样的模型,输入和输出的长度都不需要固定。RNN很适合文本、语音持续序列等数据。
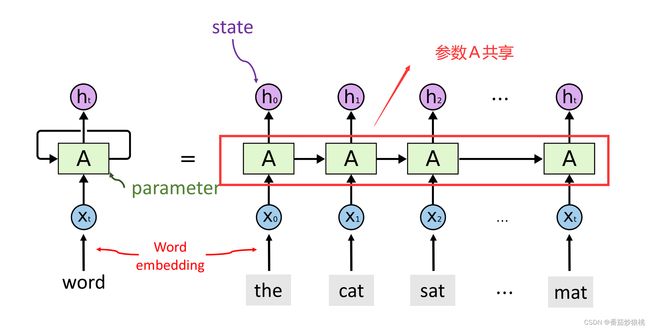
如下图,RNN跟人的阅读习惯很类似,人每次看一个词,逐渐在大脑里积累信息, RNN每次看一个词,用状态向量h来积累阅读过的信息。
如图,我们把输入的一个词用Word Embedding变成一个词向量x,每次把一个词向量输入RNN。然后RNN就会更新状态h 把新的输入积累到状态h里面,h0里面包含了第一个词the的信息。

有如下图,h1里面包含了前两个词the和cat的信息,以此类推,状态h2包含了前三个词the、cat、set的信息,最后一个状态ht包含了整句话的信息,可以把ht看作是从这句话the cat side on the match抽取的特征向量, 更新状态h的时候,需要用到参数矩阵A。

注意:整个RNN只有一个参数A, 不论这条链有多长,参数A只有一个,最开始A随机初始化,然后利用训练数据来学习A
三、Simple RNN基本概念
首先讲simple RNN简单循环神经网络
我们来具体看一下simple RNN是怎么把输入的词向量x结合到状态h里面的
上一个状态记作是ht-1,新输入的词向量记作xt。如图,把这两个向量做concatenation(串联)得到一个更高的维度的向量。

这个矩阵A是RNN的模型参数,计算矩阵A和这个向量的乘积(矩阵和向量的成积是个向量)然后把这个激活函数tanh用在向量的每一个元素上。如下图,这个激活函数是hyperbolic tangent function,即双区正切函数(输入时任意时数,输出在[-1,1]之间),把激活函数的输出作为新的状态向量,即ht

由于用了双区正切激活函数向量ht的每一个元素都在[-1,1]之间,
如下图,这张神经网络的结构图可以这样理解:新的状态ht是由关于旧状态ht-1和新的输入xt的函数生成的。

神经网络的模型参数是矩阵A,新的状态ht依赖于向量ht-1和向量xt
如图,你有没有疑惑,为什么我们要用这个双区正切函数作为激活函数呢?能否把这个激活函数给去掉?去掉之后会发生什么呢?

为了方便讲述,我们做个简化:假设输入的词向量x全都是0(这等同于把输入的词向量x给去掉),即相当于把矩阵A右边这一半去掉,这么一来第100个状态向量h100就等于矩阵A×h99=A2h99= A3h98=……= A100h0
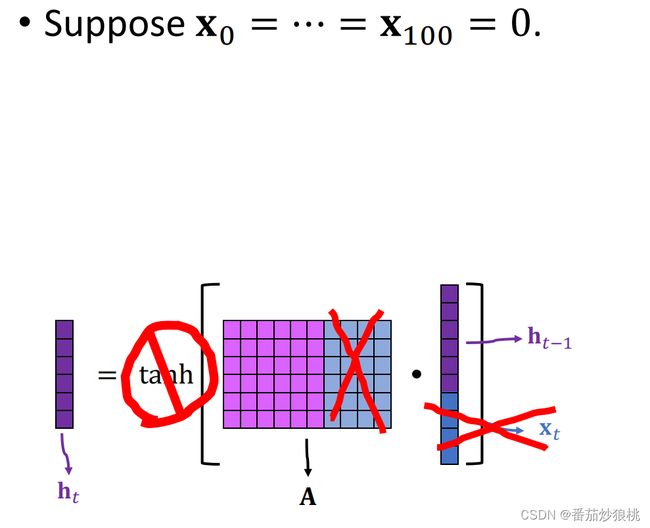
假如矩阵A最大的特征值略小于1,比如最大的特征值等于0.9那么会发生什么呢?
0.9的100次方已经非常接近零了,所以矩阵A的100次方几乎是一个全零的矩阵。那么新的状态h100几乎也是个全0的向量
假如矩阵a最大的特征值略大于1,比如最大的特征值等于1.2,那么会发生什么呢?
(1.2)100=8000多万,所以矩阵a的100次方的元素都超级大,那么新的状态h100每个元素也都巨大,假如循环的次数更多或者A的特征值再大一些,状态向量就会爆炸,假如没有这个激活函数, 数值计算的时候,很可能会出问题,要么计算出的结果全都等于零,要么爆炸了 数值全都是非常大的数

因此,使用激活函数的意义是使得每次更新状态h之后都会做一个normalization,让h恢复到[-1,1]这个合适的区间里。
那么,Simple RNN有多少个模型参数呢?
先看一下输入向量,输入向量的维度是(h+x)的维度, 所以A必须有(h的维度+x的维度)这么多列,A的行数等于向量h的维度,所以矩阵A的大小=h的维×(h的维度加上x的维度),即:
rows of A: shape(h)
cols of A: shape(h)+shape(x)
Total parameter: shape(h)× [shape(h)+shape(x)]
上一篇文章,我们用线性规划来判断电影评价是正面的还是负面的,这里我们改用RNN来解决这个问题,我们来搭一个神经网络。
如图,最底层是Ward Embedding,它可以把词映射到向量x,词向量的维度是超参数(根据需要设置)。你应该用交叉验证函数来选择最优的维度,这里设置x的维度是32

然后往上搭建一层Simple RNN Layer,输入的是词向量x,输出的是状态h,h的维度也是超参数,根据需要自己设置,应该用交叉验证来选出最好的维度。(此处h和x的维度都是32但这只是个巧合而已,h和x的维度通常不一样。)
如下图,前面说过状态向量h积累输入的信息,比如 h0包含第一个单词I的信息,h1包含前两个词I和love的信息, 最后一个状态ht积累了整句话I loved movie so much的信息

可以让keras输出所有的状态向量h,也可以让Keras只输出最后一个向量ht,ht积累了整句话的信息,所以一般使用ht这一个向量就够了。
如图,此处只使用ht,因此把前面的状态全都给丢掉,ht相当于从文本中提取的特征向量,把ht输入这个分类器,分类器就会输出一个0-1之间的数值,0代表负面电影评价,1代表正面评价,然后设置这些超参数

四、关键代码详解
如下图,首先对各个参数进行解释
设置vocabulary是10000,意思是词典里有10000个词汇,
Embedding dimension=32,意思是词向量x的维度是32。
Word number=500,意思是每个电影评论有500个单词,如果超过了500个单词就会被截掉,只保留500个,如果不到500就用zero padding补成长度等于500。
State dimension=32,意思是状态向量h的维度等于32

如下图,现在开始搭深度神经网络
首先建了一个Sequential模型model然后往model里面加层。
首先是Embedding Layer,它是把词映射成向量。
然后是Simple RNN layer,需要指定状态向量h的维度State dimension(state_dim)
最后是个全连接层, 输入RNN的最后一个状态h,输出一个0-1之间的数,这里我们设置RNN层的return_sequences=False,意思是RNN只输出最后一个状态向量,把之前的状态向量全都扔掉。

下图是模型概要

Embedding层的输出是一个500×32的矩阵,500的意思是每个电影评论有500个单词,32的意思是每个单词用32维的词向量表示。
Simple RNN的输出是一个32维的向量,它是RNN的最后一个状态向量ht,前面所有的状态向量都已经被扔掉了
我们来看一下RNN层的参数数量,它有2080个参数,这是这么算出来的呢?
h的维度乘以(h的维度+x的维度)这是矩阵A的大小,后面一个32来自于interception也叫Bias,也叫做偏移量,是为了防止模型过拟合而设置的增加噪音的参数。
设定好模型之后,进行编译模型阶段,然后用训练数据来拟合模型,编译模型的时候指定算法是RMS prop,损失函数是cross entropy,配评价标准是accuracy,然后用训练数据来拟合模型。

训练环节
可以发现,此处仅让算法运行3个epoch,是因为出现了overfitting(模型过拟合),3个epoch之后validation、accuracy会变差,提前让算法停止运行,这叫做Early stopping,让算法在validation、accuracy变差之前就停止.
接下来进入测试环节
最后用测试数据来评价模型的表现,把测试数据作为输入调用model到了evaluate,返回los和accuracy,测试的accuracy大约是84.4%,比上一篇文章使用的线性回归模型好很多(之前大概是75%),此次训练集数据准确度大概是89.2%,validation准确率是84.3%,测试准确率是84.4%。

你可能还有疑问,我们在RNN每次计算中,把之前的状态全都丢掉了,如果想用之前的状态即h0-ht的所有这些状态都运用于模型中,会使得模型的性能由明显提升吗?
如果让ENN返回所有状态 ENN的输出就是下图的矩阵,每一行是一个状态向量h,

如果用所有状态,需要加一个Flatten层, 把状态矩阵变成一个向量,然后把这个向量作为分类器的输入来判断电影是正面的还是负面的,只需要把前面的网络结构稍作改动就可以了, 之前阿安层中的return_sequences=False即只需要让RNN返回最后一个状态向量ht,现在把阿安层中的return_sequences改成True,这样RNN就会返回所有状态向量h,然后再加一个flatten层就好了。(一共就这两处改动)

下图是RNN结构的一个概要,以前只让RNN输出最后一个状态,所以RNN Layer的输出是一个32维的向量,现在我让RNN输出所有状态向量,所以RNN层的输出是500×32的矩阵,500的意思是电影评论里500个单词,所以一共有500个状态向量,每个状态向量都是32位的。
实验结果如下图

训练准确率是96.3%,validation准确率是85.4%,测试准确率是84.7%,跟之前比起来并没有提升,之前只使用最后一个状态,测试准确率是84.4%在这个应用中,用最后一个状态或是用所有状态,最终测试准确率并没有显著的区别,
五、Simple RNN的缺陷
下面来看看Simple RNN这种简单的模型有什么缺陷,举个例子,现在有这样一个问题,给定半句话,要求预测下一个单词,比如输入是clouds are in the, RNN应该是有能力做出这种预测的,在这个例子里,RNN只需要看最近的几个词,尤其是clouds are,RNN并不需要更多的上下文,并不需要看得更远,这个例子是对simple RNN是有利的。

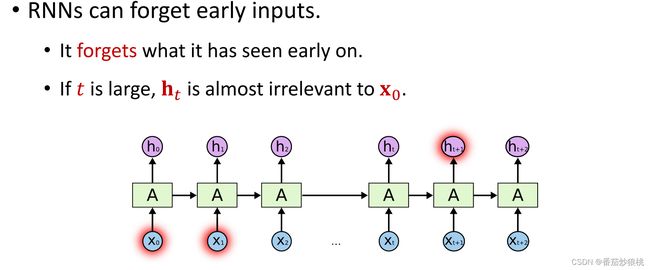
simple RNN很擅长这种short-term dependence,Simpler RNN的缺点是不擅长long-term dependence, RNN中的状态h, 跟之前所有输入的x都有函数依赖关系,照理来说,如果你改变输入的单词x,那么之后所有的状态h都会发生变化,但实际上的simple RNN并没有这种性质,所以很不合理,如果你把第100个状态向量h100关于输入x1 ,求导 你会发现导数几乎等于0
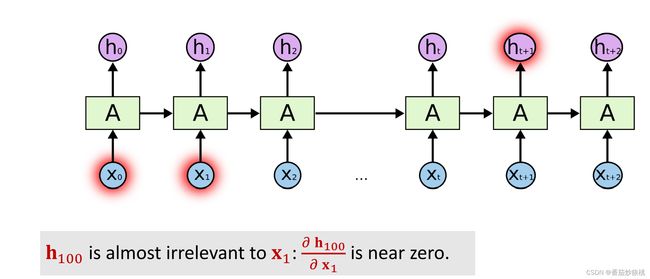
导数几乎等于0说明什么呢?
这说明你改变x1然而h 100几乎不会发生任何变化,也就是说状态是100跟100步之前的输入x1几乎没有关系, 这显然不合理,这说明状态h100已经把很多步之前的输入给忘记了。
再举个例子:下面是很长的一段话,I……(省略号代表前面有很多词)in China ……speak fluent,即我会说流利的,下一个词应该是Chinese ,我小时候在中国,所以我应该会说中文,然而 simple RNN不太可能会做出Chinese这个正确的预测,因为RNN已经把前文给忘记了,simple二RNN很擅长short-term dependence,RNN看到最近一些单词是speak fluent所以RNN知道下一个单词应该是某种语言,可能是English Chinese French she pennis等等等等,但正确答案是Chinese(根据上文可得出),而RNN就像金鱼一样,记忆力只有七秒,本记不住长句上文较为前面的单词。
六、代码实现
如图是代码运行结果
此处不多赘述,直接上代码(更多细节参考备注与上一篇文章)
'数据集读取与预处理'
# 此处使用Keras库自带函数进行简洁实现(从零开始实现请看上一节)
# 使用keras的embedding层处理文字数据(同样使用imdb数据集)
from keras.datasets import imdb
from keras import preprocessing
max_feature = 10000 # 词汇量(作为特征的单词个数)
maxlen = 500 # 在500个单词以后截断文本
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_feature)
# y_train、y_test分别表示训练集和测试集的标签
# max_words=10000:只考虑数据集中前10000个最常见的单词
print(len(input_train), 'train sequences')
print(len(input_test), 'test sequences')
print('sequence 格式:(samples*time)')
input_train = preprocessing.sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = preprocessing.sequence.pad_sequences(input_test, maxlen=maxlen)
# 此处相当于对齐序列(补0或者阶段评论)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
'定于模型:Simple RNN'
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense, Embedding
'词嵌入操作:降低输入向量维度'
embedding_dim = 32
model = Sequential()
model.add(Embedding(max_feature, embedding_dim, input_length=maxlen))
# 第一层是Embedding层,设定字典里10000个单词,Embedding层的输出是个500×32的矩阵,
# 只考虑每条电影评论中最后的500个单词,每个单词用32维的向量来表示
# 参数矩阵在此的维度是320000,矩阵的参数根据设定的每个单词表示的向量(32)*字典词个数10000得到
'Simple RNN Layer'
state_dim = 32
model.add(SimpleRNN(state_dim, return_state=False))
# return_state=False,不需要存储ht之前的状态
model.add(Dense(1, activation='sigmoid'))
# units :代表该层的输出维度或神经元个数,此处设定输出的维度为1
# activation=None:激活函数.但是默认 liner
'设定优化算法以及模型评价标准'
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
# optimizer: 优化器,loss:损失函数,metrics: 评价函数.
# 评价函数的结果不会用于训练过程中,可以传递已有的评价函数名称
'设置训练模型'
history = model.fit(
input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2
)
# input_train:输入数据,y_train:标签,
# batch_size:整数,指定进行梯度下降时每个batch包含的样本数
# epochs:整数,训练终止时的epoch值
# validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集
model.summary()
'查看模型最终性能'
loss_and_acc = model.evaluate(input_test, y_test)
print('loss=' + str(loss_and_acc[0]))
print('acc=' + str(loss_and_acc[1]))

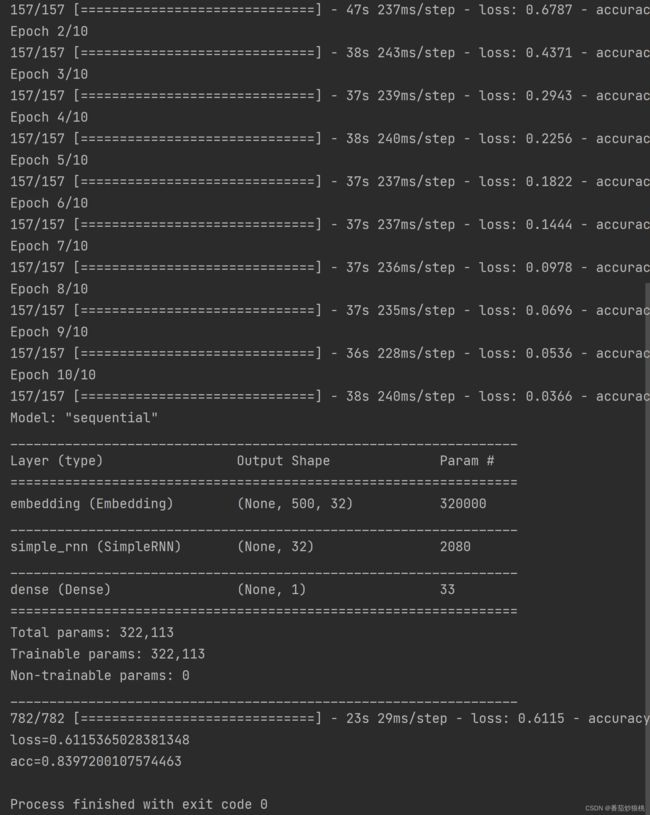
与上一篇文章使用的线性回归模型相比,Simple RNN模型的模型精度还是有较大提升的
七、总结
总结一下本文的内容:
(1)RNN是一种神经网络,它的结构不同于全连接网络和卷机网络,更适用于文本、语音、时间序列等数据。
(2)RNN按照顺序读取每一个词向量,并且在状态向量h中积累看到过的信息。h0中包含了x0的信息,h1种包含了x0和x1的信息, ht中积累了之前所有x的信息,
(有一种错误的看法是 ht中只包含了xt的信息,这是不对的。ht中包含了之前所有输入的信息,可以认为ht就是RNN从整个输入序列中抽取的特征向量,所以我们只需要ht就可以判断电影评价是正面的或是负面的)

(3)RNN的缺点是记忆比较短,它会遗忘很久之前的输入x 。如果这个时间序列很长,比如好几十步,最终的ht已经忘记了早先的输入
(4)Simple RNN只有一个参数矩阵A,它有可能还有一个interception参数向量b,本文忽略了这个参数向量b,这个参数矩阵的维度是h的维度×(h的维度+x的维度)。即:shape(h) × [shape(h)+shape(x)]
(5)参数矩阵一开始随机化,然后从训练数据中学习这个参数矩阵.注意 simple RNN只有一个参数矩阵,不管这个时序有多长,参数矩阵只有一个,所有模块里的参数都是一样的(参数共享)
下一篇将讲述LSTM,LSTM的记忆会比Simple RNN要长很多,但还是有遗忘的问题。
八、参考内容
Keras model.fit()参数详解_NoOne-csdn的博客-CSDN博客_keras.fit
Tensorflow+Keras入门练习(六):文字处理(嵌入层,RNN,LSTM) - 知乎 (zhihu.com)
GitHub - wangshusen/DeepLearning