logback日志框架
1. logback简介
目前比较常用的java日志框架包括:logback,log4j,log4j2,JUL。
log4j2和log4j是两套完全不同的框架,并且不兼容;logback是在log4j的基础上重新开发的一套日志框架,是完全实现slf4j接口API(因为开发logback和开发slf4j的是同一个人),是springboot默认推荐的日志框架。
logback分成三个模块:
logback-core, logback-classic和logback-access。
1)logback-core是其他两个模块的共同依赖模块
2)logback-classic原生实现了slf4j接口API
3)logback-access模块与Tomcat, Jetty等servlet容器集成,以提供http访问日志的功能。
我们还可以基于logback-core实现构建自己的模块
2. 代码演示
2.1 pom依赖
ch.qos.logback
logback-classic
1.2.11
2.2 代码
logback中日志级别分成5级:
TRACE < DEBUG < INFO < WARN < ERROR
默认情况下,trace级别的日志不会输出
public class LoggingTest01 {
//Logger是单例的,有则取,没有则创建
//name可以随便写,一般使用当前类的全路径名
private static final Logger logger = LoggerFactory.getLogger(LoggingTest01.class);
public static void main(String[] args) {
logger.trace("hello world! I am trace level");
logger.debug("hello world! I am debug level");
logger.info("hello world! I am info level");
logger.warn("hello world! I am warn level");
logger.error("hello world! I am error level");
}
}
16:59:39.391 [main] DEBUG com.john.logging.LoggingTest01 - hello world! I am debug level
16:59:39.402 [main] INFO com.john.logging.LoggingTest01 - hello world! I am info level
16:59:39.402 [main] WARN com.john.logging.LoggingTest01 - hello world! I am warn level
16:59:39.402 [main] ERROR com.john.logging.LoggingTest01 - hello world! I am error level2.3 记录器介绍
在logback中,所有的记录器都是缓存在一个map中的,而且有层级关系,最顶层的是root,root记录器是自动生成的,不需要创建。
层级关系由name决定,层级关系主要是方便记录器属性的管理,子记录器在没有配置相关属性时,会继承父记录器的对应属性。例如,记录器D会继承记录器A的属性,记录器A会继承根记录器的属性。
而且,日志的输出默认是有叠加性的,例如,如果使用记录器D打印一条日志,那么默认情况下,该日志还会被记录器A和跟记录器输出,也就是一共会打印3次。当然,该属性可以被关闭。在进行日志搜集到ELK时,可以在跟记录器设置一个appender,将日志传输出去。
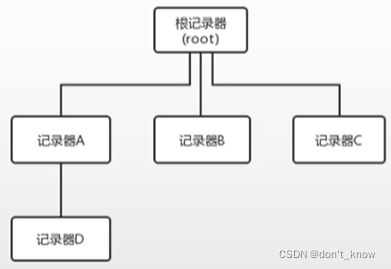
如果我们按如下方式生成一个记录器:
private static final Logger logger = LoggerFactory.getLogger("org.example.App");
private static final Logger logger2 = LoggerFactory.getLogger("org.example.App2");那么会对应生成所有如下名称的记录器:

2.4 记录器的属性
slf4j接口定义的记录器属性只有name,但是loagback的记录器有三个属性:name, level和addtivity.
1)name属性:记录器的唯一标识,也就类似于map的key
2)level属性(可选):记录器的级别,允许的级别:TRACE < DEBUG < INFO < WARN < ERROR
对应的方法:setLevel, getLevel, getEffectiveLevel
3)addtivity属性(可选):是否允许叠加打印日志
2.4.1 level测试
(1)设置level后,会影响当前记录器和当前记录器的所有未设置level属性的子记录器;
(2)设置level后,小于该level的日志将不会被打印。
package com.john.logging;
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
import org.slf4j.LoggerFactory;
public class LoggingTest01 {
private static final Logger rootLogger = (Logger)LoggerFactory.getLogger("root");
private static final Logger logger = (Logger)LoggerFactory.getLogger(LoggingTest01.class);
public static void main(String[] args) {
System.out.println("默认root日志级别:" + rootLogger.getEffectiveLevel());
System.out.println("默认test日志级别:" + logger.getEffectiveLevel());
logger.setLevel(Level.TRACE);
System.out.println("修改后root的日志级别:" + rootLogger.getEffectiveLevel());
System.out.println("修改后test的日志级别:" + logger.getEffectiveLevel());
}
}
默认root日志级别:DEBUG
默认test日志级别:DEBUG
修改后root的日志级别:DEBUG
修改后test的日志级别:TRACE2.4.2 addtivity测试
additivity的逻辑是这样的:
1)使用当前的记录器(例如com.aa)进行打印,打印完毕之后,判断当前记录器的addivity属性;
2)如果当前addivity的属性为false,那么当前记录器的父记录器不再打印;否则调用父记录器进行打印;
3)父附加器执行1)和2)...
具体表现如下:
1)在com.aa记录器上加addtivity属性为false,com.aa记录器打印一次;
2)在com记录器上加addtivity属性为false,那么com.aa记录器和com记录器各打印一次;
3)如果在root记录器上加addtivity属性为false,相当于没有加(因为root记录器没有父记录器了),那么com.aa记录器、com记录器和root记录器各打印一次;
4)在root和com记录器上都加,那么com.aa记录器和com记录器各打印一次。
2.5 使用配置文件配置记录器属性
1)使用logger标签创建记录器,level属性指定级别
2)使用root标签创建跟记录器,level属性指定级别
3)root标签等于
2.6 附加器Appender
记录器会将输出日志的任务交给附加器来完成,不同的附加器会将日志输出到不同的地方,比如控制器附加器,文件附加器,网络附加器等。
常用的附加器如下:
控制台附加器:ConsoleAppender
文件附加器:FileAppender
滚动文件附加器:RollingFileAppender
1)附加器的pattern标签
pattern由文字文本和转换说明符组成。我们可以在其中自由插入任何文字文本,每个转换说明符都以百分,后跟可选的格式修饰符、转换字和大括号之间的可选参数。转换字控制要转换的数据字段,例如记录器名称、级别、日期或者线程名称。格式修饰符控制字段宽度,填充以及对齐方式。
pattern的全量信息参考logback-classic的PatternLayout类
配置参考 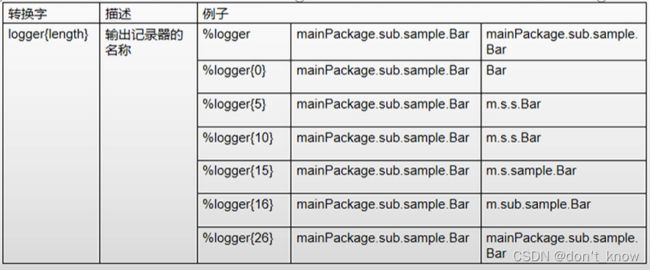
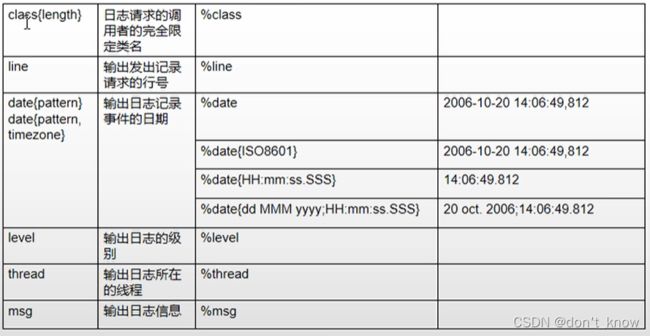
%d{HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n
d:\logs\myApp.log
true
%date %level [%thread] %logger{10} [%file:%line] %msg%n
2)滚动文件附加器
基于时间的滚动策略:TimeBasedRollingPolicy
myApp.log
%date %level [%thread] %logger{10} [%file:%line] %msg%n
%d{yyyy-MM-dd HH-mm/ss}.log
3
5GB
基于大小和时间的滚动策略:SizeAndTimeBasedRollingPolicy
myApp.log
%date %level [%thread] %logger{10} [%file:%line] %msg%n
%d{yyyy-MM-dd}.%i.log
3
5GB
1KB
2.7 自定义附加器
public class MyAppender extends UnsynchronizedAppenderBase {
private Encoder encoder;
protected void append(E e) {
ILoggingEvent event = (ILoggingEvent) e;
byte[] bytes = encoder.encode(event);
try {
String msg = new String(bytes, "utf-8");
System.out.println(msg);
} catch (UnsupportedEncodingException ex) {
ex.printStackTrace();
}
}
public Encoder getEncoder() {
return encoder;
}
public void setEncoder(Encoder encoder) {
this.encoder = encoder;
}
}
%date %msg%n
2.8 附加器过滤器
过滤器是附加器的一个组件,它用于决定附加器是否输出日志。一个附加器可以包含一个或者多个过滤器。每个过滤器都会返回一个枚举值,可选的值:DENY,NEUTRAL, ACCEPT。
附加器根据过滤器返回值判断是否输出日志,过滤器按照从上至下的顺序一次进行判断:
1)如果是DENY,那么不再继续判断该过滤器以下的其他过滤器,直接不输出日志;
如果是ACCEPT,也不再继续判断该过滤器以下的其他过滤器,直接输出日志;
2)如果是NEUTRAL,那么说明该过滤器不进行是否输出日志判断,而是交给下一个过滤器进行判断;但如果没有下一个过滤器,则输出日志。
常用的过滤器:
1)LevelFilter: 级别过滤器,级别相等才会打印日志
2)ThresholdFilter: 阈值过滤器,级别大于等于才会打印日志
3)EvaluatorFilter:评估者过滤器
4)JaninoEventEvaluator
5)TurboFilter:涡轮过滤器
6)DulicateMessageFilter:重复消息过滤器
%date %msg%n
INFO
ACCEPT
DENY
过滤器与logger标签的level属性:
日志先由logger标签的level属性进行过滤,如果有日志要输出,那么再由各个附加器的过滤器进行过滤输出。
自定义过滤器:
案例1:
public class MyFilter extends Filter {
private Level level;
public FilterReply decide(ILoggingEvent event) {
if(event.getLevel().equals(level)) {
return FilterReply.ACCEPT;
}
return FilterReply.DENY;
}
public void setLevel(Level level) {
this.level = level;
}
} 案例2:
%date %msg%n
INFO
successful
public class MyFilter extends Filter {
private String keyword;
public FilterReply decide(ILoggingEvent event) {
if (event.getMessage().contains(keyword)) {
return FilterReply.ACCEPT;
}
return FilterReply.DENY;
}
public void setKeyword(String keyword) {
this.keyword = keyword;
}
}