将近 5 万字讲解 Java Web / Servlet 网络编程超级详细概念原理知识点
1. Web 基本概念
首先 Web 网页 / 网站的意思(例如:百度 www.baidu.com)
Web 分类:静态 Web / 动态 Web(技术栈 Servlet / JSP、ASP、PHP)
动态 web 在 java 中叫 javaweb
BS (Browser / Server:浏览器 / 服务器 模式)
Web 应用,可以实现跨平台,客户端零维护,但是个性化能力低,响应速度较慢
CS (Client / Server:客户端 / 服务器 模式)
桌面级应用,响应速度快,安全性强,个性化能力强,响应数据较快
Web 应用程序
Web 应用程序编写完毕,需要提供给外界访问,需要一个服务器统一管理。
静态 Web 图示

动态 Web 图示
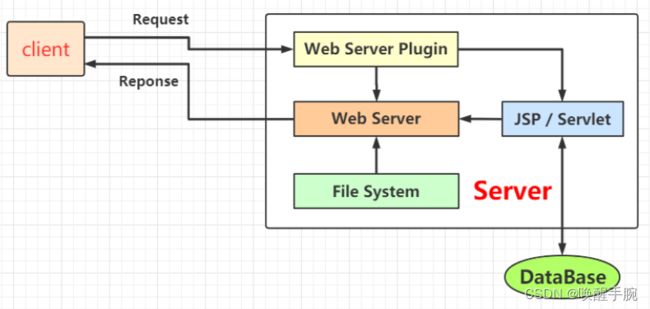
2. Web 服务器
ASP:国内最早流行起来,在HTML中嵌入VB的脚本,ASP+COM(维护成本高)
PHP:开发速度快,功能强大,代码简单,但是无法承载大的访问量
JSP / Servlet:Sun公司主推的BS架构,基于Java,承载三高带来的问题
互联网三高架构:高并发、高性能、高可用,简称三高( 3 H )
Web 服务器
服务器是被动的操作,用来处理用户的请求,响应给用户信息和数据。
本地域名解析:localhost

网站是如何进行访问?浏览器根据域名解析IP地址浏览器根据访问的域名找到其IP地址。
浏览器缓存
首先搜索浏览器自身的DNS缓存(缓存的时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否是有域名对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
系统缓存
如果浏览器自身的缓存里面没有找到对应的条目,那么浏览器会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束。
路由器缓存
如果系统缓存也没有找到,则会向路由器发送查询请求。
ISP(互联网服务提供商) DNS缓存
如果在路由缓存也没找到,最后要查的就是ISP缓存DNS的服务器。
3. Http 请求
浏览器 和 WEB 服务器建立一个 TCP 连接 TCP 的 3 次握手
浏览器给 WEB 服务器发送一个 HTTP 请求
一个HTTP请求报文由请求行(request line)、请求头部(headers)、空行(blank line)和请求数据(request body)4个部分组成
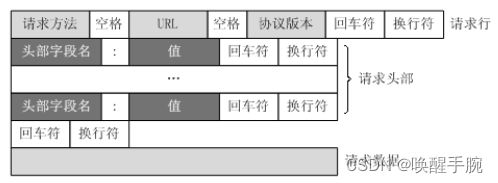
请求行分为三个部分:请求方法、请求地址 URL 和 HTTP 协议版本,它们之间用空格分割。例如,GET /index.html HTTP/1.1

4. Maven 环境搭建
官方下载页面:http://maven.apache.org/download.cgi
安装完成进行配置系统变量 MAVEN_HOME
配置 path 路径

Maven 是帮助程序员构建项目的工具,我们只需要告诉 Maven 需要哪些 Jar 包,它会帮助我们下载所有的 Jar 包,极大提升开发效率。
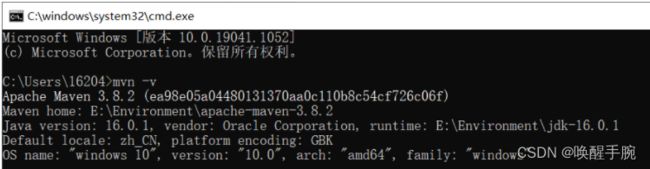
Maven 安装完成之后,在命令行输入
mvn -v(若出现 maven 信息则说明安装成功)
Maven 仓库用来存放 Maven 管理的所有 Jar 包(3 类仓库:本地仓库 / 中央仓库 / 镜像仓库)
Maven 本地仓库
本地仓库(Maven 本地的 Jar 包仓库)相当于本地的缓存,工程第一次会从远程仓库去下载 Jar 包,然后将 Jar 包存在本地仓库。第二次不需要从远程仓库去下载,寻找 Jar 包会先从本地仓库找,如果找不到才会去远程仓库查找所需 Jar 包。
Maven 中央仓库
中央仓库(Maven 官方提供的远程仓库)是 Maven 官方的远程仓库,仓库中所有 Jar 包由 Maven 团队统一进行维护。Maven 中央仓库是一个由 Sonatype 公司运营的开源软件项目仓库,提供了大量用于 Java 项目的开源依赖库。它是最常用的 Maven 仓库之一,许多开源项目都会将它们的 Jar 文件上传到这个仓库中,供其他开发者使用。
Maven 中央仓库链接地址:http://repo1.maven.org/maven2/
Maven 镜像仓库
镜像仓库(私服提供的远程仓库)是一种远程仓库的映射仓库,可以在 Maven 项目中替代原始仓库,提供更快捷的包下载速度。镜像仓库的作用是代理其他仓库,将原本需要从原始仓库获取的依赖包转而从本地或网络上的镜像仓库中获取。这种机制使得开发者可以更快地下载所需的依赖包,避免了网络不稳定或原始仓库不可访问导致的问题。
① 阿里云的 Maven 镜像仓库(推荐):http://maven.aliyun.com/nexus/content/groups/public/
② Maven官方运维的 2 号仓库:http://repo2.maven.org/
③ Maven 在 UK 架设的仓库:http://uk.maven.org/maven2/
④ JBoss 的仓库:http://repository.jboss.org/nexus/content/groups/public/
5. 配置 Maven 镜像
在 Maven 项目中,可以通过修改 setting 文件来配置镜像仓库。在 setting 文件中,可以指定镜像仓库的地址、名称等信息,以便在项目中获取依赖包时使用。例如,如果在中国使用 Maven 中央仓库,但由于网络因素导致下载速度缓慢,可以将 Maven 中央仓库的镜像配置到本地或网络上的一个镜像仓库中,从而加速包的下载过程。
打开 setting.xml 文件,找到
<mirror>
<id>nexus-aliyunid>
<mirrorOf>*mirrorOf>
<name>Nexus aliyunname>
<url>http://maven.aliyun.com/nexus/content/groups/publicurl>
mirror>
当我们的 Java 项目编译时,Maven 首先从本地仓库中寻找项目所需的 Jar 包,若本地仓库没有,再到 Maven 的中央仓库(若配置了镜像,则走镜像仓库)下载所需 Jar 包。
在 Maven 中,坐标是 Jar 包的唯一标识,Maven 通过坐标在仓库中找到项目所需的 Jar 包
<dependency>
<groupId>cn.missbe.web.searchgroupId> ## 所需Jar包的项目名
<artifactId>resource-searchartifactId> ## 所需Jar包的模块名
<packaging>jarpackaging> ## 打包方式
<version>1.0-SNAPSHOTversion> ## 所需Jar包的版本号
dependency>
6. Maven 依赖机制
传递依赖:如果我们的项目引用了一个 Jar 包,而该Jar包又引用了其他 Jar 包,那么在默认情况下项目编译时,Maven 会把直接引用和间接引用的 Jar 包都下载到本地。
排除依赖:如果我们只想下载直接引用的 Jar 包,那么需要在 pom.xml 中做如下配置:(将需要排除的 Jar 包的坐标写在中)
<exclusions>
<exclusion>
<groupId>cn.missbe.web.searchgroupId>
<artifactId>resource-searchartifactId>
<packaging>pompackaging>
<version>1.0-SNAPSHOTversion>
exclusion>
exclusions>
在项目发布过程中,帮助决定哪些构件被包括进来,欲知详情查阅 依赖机制。
- compile:默认范围,用于编译
- provided:类似于编译,但支持你期待jdk或者容器提供,类似于classpath
- runtime:在执行时需要使用
- test:用于test任务时使用
- system:需要外在提供相应的元素。通过systemPath来取得
- systemPath:仅用于范围为system。提供相应的路径
- optional:当项目自身被依赖时,标注依赖是否传递。用于连续依赖时使用
依赖冲突
Maven 依赖冲突是指项目依赖的多个 Jar 包中存在版本冲突的情况。例如,项目 A 依赖于 B 和 C 两个 Jar 包,其中 B 包依赖于 X(1.0) 版本,而 C 包依赖于 X(2.0) 版本,这就产生了依赖冲突。
短路优先
若本项目引用了 A.jar,A.jar 引用了 B.jar,B.jar 引用了 X.jar,并且 C.jar 也引用了 X.jar
在此时,Maven 只会引用引用路径最短的 Jar。
声明优先
若引用路径长度相同时,在 pom.xml 中谁先被声明,就使用谁。
7. 聚合 vs 继承
什么是聚合?
将多个项目同时运行就称为聚合。
如何实现聚合?
只需在pom中作如下配置即可实现聚合:
<modules>
<module>web-connection-poolmodule>
<module>web-java-crawlermodule>
modules>
什么是继承?
在聚合多个项目时,如果这些被聚合的项目中需要引入相同的 Jar,那么可以将这些 Jar 写入父 pom 中,各个子项目继承该 pom 即可。
关于 maven 中引入的依赖 scope 属性 的分类
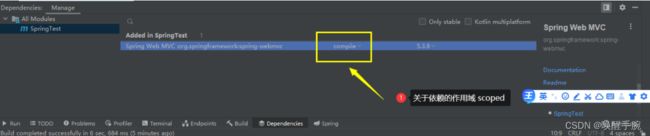
compile:默认值 他表示被依赖项目需要参与当前项目的编译,还有后续的测试,运行周期也参与其中,是一个比较强的依赖。打包的时候通常需要包含进去
test:依赖项目仅仅参与测试相关的工作,包括测试代码的编译和执行,不会被打包,例如:junit
runtime:表示被依赖项目无需参与项目的编译,不过后期的测试和运行周期需要其参与。与compile相比,跳过了编译而已。例如JDBC驱动,适用运行和测试阶段
provided:打包的时候可以不用包进去,别的设施会提供。事实上该依赖理论上可以参与编译,测试,运行等周期。相当于compile,但是打包阶段做了exclude操作
system:从参与度来说,和provided相同,不过被依赖项不会从maven仓库下载,而是从本地文件系统拿。需要添加systemPath的属性来定义路径
8. Servlet 接口
Servlet 生命周期
init 初始化
当 Servlet 容器启动或者第一次请求某个 Servlet 时,会加载并创建 Servlet 对象的实例。在此阶段,容器会调用 ServletContext 的 getServlet 方法来获取 Servlet 实例,并调用其 init 方法进行初始化。在 init 方法中,Servlet 可以进行一些初始化工作,如加载配置文件、建立数据库连接等。
service 服务
当 Servlet 初始化完成后,容器会将其放入就绪状态,表示它已经准备好处理客户端请求了。当第一个客户请求到达时,容器创建或从线程池分配一个线程,调用 service() 方法,同时以参数形式传入请求和响应对象。
通常无需覆盖 override 此方法,而是由其调用父类 HttpServlet 的 service(),然后根据请求中的 HTTP 方法(Get 或 Post等),调用覆写的 DoGet() 或 doPost() 等方法(在Servlet中必须至少覆写 doGet() 及 doPost() 方法中的一个)。service() 方法结束时,线程也结束(或者被回收到线程池)。
destory 销毁
在容器移除 Servlet 前,使得 Servlet 能有机会关闭数据库连接、停止某些后台线程、将 cookie 列表和点击计数写入磁盘、以及执行其他清理工作等。
Servlet 继承关系
Servlet 是一个接口,由 Sun 公司开发用于 Web 资源技术。任何类只要实现了 Servlet 接口,就可以成为 Servlet 程序。

GenericServlet 是 Servlet 接口的实现类,也是一个抽象类。HttpServlet 是Servlet 接口的抽象子类,也是 GenericServlet 的子类。在开发Web应用程序时,通常会继承HttpServlet类,以实现对不同提交方式的处理。
例如,如果继承了 GenericServlet,那么无论是通过 GET 还是 POST 方式提交的请求,都会调用service()方法;而如果继承了 HttpServlet,对于 GET 方式提交的请求会调用 doGet 方法,对于 POST 方式提交的请求会调用 doPost 方法。
注意点:每个请求都在一个单独的线程中运行,任何特定的 Servlet 类都只有一个实例(即单实例)!
Servlet 并发处理

当多个请求同时访问同一个 Servlet 时,Servlet容器(如Tomcat)会为每个请求创建一个新的线程,并在该线程中调用Servlet的service方法处理请求。这种方式实现了Servlet的多线程处理,可以同时处理多个请求。
在 Servlet 中,可以通过 synchronized 关键字或 Lock 对象来实现同步,以确保多个线程不会同时访问共享资源,从而避免线程安全问题。此外,Servlet 容器还提供了一些配置选项,如连接池和线程池,以优化 Servlet 的多线程处理性能。
需要注意的是,在 Servlet 中访问共享资源(如数据库连接、文件等)时,需要进行同步操作以避免多个线程同时访问导致的问题。同时,在 Servlet 中也需要避免使用过多的同步操作,以免影响性能。
9. 创建 maven 项目
首先选择包管理 maven 模式创建项目

IDEA 创建的 web.xml 这个文件版本比较低(把我的文件直接全部覆盖复制进去就可以了)
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>java-jsp-testartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>16maven.compiler.source>
<maven.compiler.target>16maven.compiler.target>
properties>
project>
需要 java.servlet Jar 包
<dependency>
<groupId>javax.servletgroupId>
<artifactId>javax.servlet-apiartifactId>
<version>4.0.1version>
<scope>providedscope>
dependency>
编写 Servlet 实现类
package com.alibaba.servlet;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
public class HelloServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
PrintWriter printWriter = resp.getWriter();
printWriter.write("hello world");
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
super.doGet(req, resp);
}
}
当只处理 get 请求时,那么 post 请求的 override 可以忽略不写
public class HelloServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
PrintWriter printWriter = resp.getWriter();
printWriter.write("hello world");
}
}
为什么需要 servlet 映射?
我们写的是 Java 程序,但是要通过浏览器访问,但是浏览器需要连接 web 服务器,所以我们需要在 web 服务器中注册我们写的 Servlet,还需要给一个浏览器可以访问的路径地址。
DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd" >
<web-app>
<display-name>Archetype Created Web Applicationdisplay-name>
<servlet>
<servlet-name>HelloServletservlet-name>
<servlet-class>com.alibaba.servlet.HelloServletservlet-class>
servlet>
<servlet-mapping>
<servlet-name>HelloServletservlet-name>
<url-pattern>/hellourl-pattern>
servlet-mapping>
web-app>
配置Tomcat服务器
下载地址:https://tomcat.apache.org/download-80.cgi
Deploy at the server startup 在服务器启动时进行部署
配置完成:运行
10. 控制台乱码问题
如何让控制台打印中文(防止 Maven 日志乱码问题)

vscode 打开编辑

console 控制台不再出现乱码
11. Tomcat 服务器
Tomcat 安装地址:https://tomcat.apache.org/download-80.cgi
Tomcat 服务器安装配置博客:Linux 操作系统云服务器安装部署 Tomcat 服务器详细教程
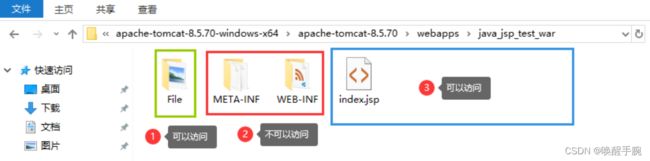
Tomcat 访问权限(File 目录 自定义的)
Tomcat Startup.bat 启动一闪而过(原因:没有配置正确的 JAVA_HOME 环境变量)
设置默认端口号:80
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
12. Tomcat 常见问题
聊个可能遇到的坑:启动 JSP 项目,运行页面报错 404
配置 conf/server.conf.xml 文件(无法热部署)
<context docBase="D:\hello" path="/newHello" />
在 conf/catalina/localhost 下创建 任意的 xml 文件(可以热部署)
<context docBase="D:\hello" path="/newHello" />

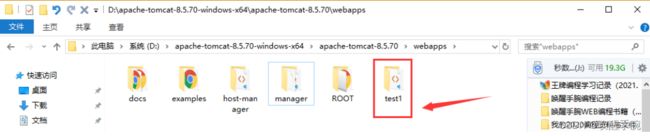
Open browser URL:http://localhost:8080/test2
在我们的 tomcat 下面的 webapp 文件没有重命名 test2(实际上是 test1 导致 404)
原因解释:
war 模式:将WEB工程以包的形式上传到服务器
war exploded 模式:将WEB工程以当前文件夹的位置关系上传到服务器
war 模式这种可以称之为是发布模式,看名字也知道,这是先打成 war 包,再发布。
war exploded 模式是直接把文件夹、jsp 页面 、classes 等等移到 Tomcat 部署文件夹里面,进行加载部署。
IDEA 帮我们在 target 文件夹下,生成类似 WAR 包解压后的文件夹,将这个文件夹的位置通过 docBase 映射到虚拟目录,这个虚拟目录其实就是
ApplicationContext, 因此这种方式支持热部署,一般在开发的时候也是用这种方式。
在平时开发的时候,使用热部署的话,应该对 Tomcat 进行相应的设置,这样的话修改的jsp界面什么的东西才可以及时的显示出来。
Application context:虚拟目录

用于获取上下文环境绝对路径的代码
String contextPath = request.getSession().getServletContext().getRealPath("/");
默认的 idea 是不需要配置虚拟目录了,它完全托管项目,但是有些时候,在开发过程中,是需要以虚拟目录的形式开发,即以:http://localhost:8080/虚拟目录名/index.html 这种形式。
根据上述的实验结果可以看到这两种方式的部署方式是不一样的,因些在获取项目的相对路径的时候得到的结果是不一样的。

注意点:其实具体的值是由于 CATALINA_BASE 决定的

C:\Users\Administrator\AppData\Local\JetBrains\IntelliJIdea2021.2\tomcat\d7d85ffc-b6ab-4368-9990-4f290b0734d5

13. ServletContext
问 2 个问题?
问题1:大家在访问某个网站的时候,往往都会看到网站的首页面显示您是第几位浏览者(网站计数器),这是怎么实现的?
问题2:我们在访问某个 bbs 网站的时候,往往会显示有多少人在线,这是怎么实现的?
可能我们会想到的常规实现思路:数据库或者文件。这种做法比较简单,但是却会对数据库或者文件访问过于频繁,开销比较大。
解决:ServletContext
ServletContext 是Java Servlet API 中的一个接口,它提供了一种方式在 Servlet容器 和 Servlet 之间进行交互。ServletContext 对象在 Web 应用程序启动时创建,并且在整个 Web 应用程序生命周期内都是可用的。
ServletContext 提供了一些方法,使得 Servlet 能够访问关于 Web 应用程序的信息,例如获取 Web 应用程序的上下文路径、获取Web应用程序的名称、获取 Web 应用程序的版本等。ServletContext 还提供了一些方法,使得 Servlet 能够访问 Web 应用程序的资源,例如获取 Web 应用程序的资源文件、获取 Web 应用程序的实时文档等。
ServletContext 在 Web 应用程序的生命周期中扮演着重要的角色。在 Web 应用程序启动时, ServletContext 对象被创建,并且可以通过 getServletContext() 方法获取。在 Web 应用程序关闭时,ServletContext 对象被销毁。在 Servlet 的生命周期中,ServletContext 对象也是可用的,可以通过 getServletConfig().getServletContext() 方法获取。
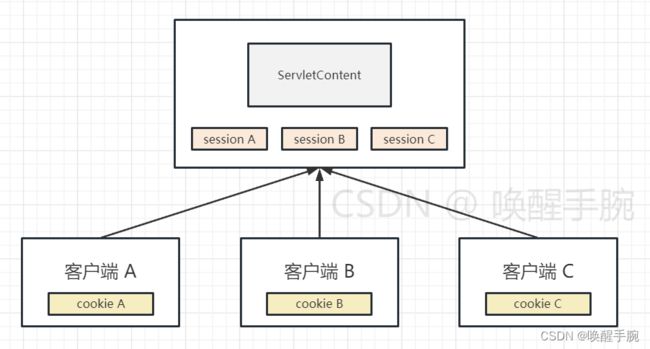
你可以把它想象成一个公用的空间,可以被所有的客户访问,也就是说 A 客户端可以访问 D,B客户端可以访问 D,C 客户端也可以访问 D。
ServletContext 常见应用:公共聊天室
如何获取 ServletContext 引用?
this.getServletContext();
this.getServletConfig().getServletContext();
把它想象成一张表,这个和 Session 非常相似:每一行就是一个属性

ServletContext 生命周期
ServletContext中的属性的生命周期从创建开始,到服务器关闭结束。
ServletContext 应用
(1)Servlet 通过 ServletContext 对象实现数据共享
(2)实现 Servlet 请求转发
(3)获取 Web 应用的初始化参数
(4)利用 ServletContext 对象读取资源文件(比如 properties 文件)
我们学过的请求转发是通过 request 对象的,这里要说明的是 ServletContext 也可以实现请求转发,这两个转发效果是一样的。
request.getRequestDispatcher("/url").forward(request, response);
this.getServletContext().getRequestDispatcher("/url").forward(request, response);
获取 Web 应用的初始化参数
我们介绍过在Servlet部署的时候,我们可以使用一个或多个
<servlet>
<servlet-name>MyServletservlet-name>
<servlet-class>com.gavin.servlet.MyServletservlet-class>
<init-param>
<param-name>encodingparam-name>
<param-value>utf-8param-value>
init-param>
servlet>
可以看到它配置了一个初始化参数 encoding=utf-8,那么我们在 MyServlet 的源代码中需要这样去得到这个参数:
String encoding = this.getServletConfig().getInitParameter("encoding");
上述的参数配置方法只针对一个特定的 Servlet 有效,现在我们可以通过 ServletContext 来获取全局的、整个 Web 应用的初始化参数,全局的初始化参数是这样配置在 web.xml 文件中的:
<context-param>
<param-name>nameparam-name>
<param-value>gavinparam-value>
context-param>
我们可以在任意一个 Servlet 中使用 ServletContext 获取这个参数
String name = this.getServletContext().getInitParameter("name");
利用 ServletContext 对象读取资源文件(比如 properties 文件)
文件在WebRoot文件夹下,即我们的Web应用的根目录下,可以使用ServletContext来读取该资源文件。
假设我们Web根目录下有一个配置数据库信息的dbinfo.properties文件,里面配置了name和password属性,这时候可以通过ServletContext去读取这个文件:
InputStream stream = this.getServletContext().getResourceAsStream("dbinfo.properties");、
注意:这种方法的默认读取路径就是 Web 应用的根目录
Properties properties = new Properties();
properties.load(stream);
String name = properties.getProperty("name");
String password = properties.getProperty("password");
out.println("name="+name+";password="+password);
但是如果这个文件放在了 src 目录下,通过 ServletContext 是读不到的,必须要使用类加载器去读取。
InputStream stream = MyServlet.class.getClassLoader().getResourceAsStream("dbinfo.properties")
注意:类加载器的默认读取路径是 src 根目录
ServletContext 可以获取文件的全路径,当然这个也是在 Web 应用根目录下的文件。比如我们在 Web Root 文件夹下有一个 images 文件夹,images 文件夹下有一个 Servlet.jpg 图片,为了得到这个图片的全路径,如下所示:
String path = this.getServletContext().getRealPath("/images/Servlet.jpg");
在网站开发中使用 ServletContext 应用,比如:网站计数器 / 网站的在线用户显示 / 简单的聊天系统
结论:如果是涉及到不同用户共享数据,而这些数据量不大,同时又不希望写入数据库中,我们就可以考虑使用 ServletContext 实现。
14. 重定向 vs 请求转发
作为一名程序员,特别是 java web开发的程序员,在使用 servlet / jsp 的时候,我们必须要知道实现页面跳转的两种方式的区别和联系:即转发和重定向的区别。
RequestDispatcher.forward 方法只能将请求转发给同一个 WEB 应用中的组件;而HttpServletResponse.sendRedirect 方法不仅可以重定向到当前应用程序中的其他资源,还可以重定向到同一个站点上的其他应用程序中的资源,甚至是使用绝对 URL 重定向到其他站点的资源。
如果传递给 HttpServletResponse.sendRedirect 方法的相对URL以“/”开头,它是相对于整个 WEB 站点的根目录。
如果创建RequestDispatcher对象时指定的相对URL以“/”开头,它是相对于当前WEB应用程序的根目录。
地址 URL 比较
调用 HttpServletResponse.sendRedirect 方法重定向的访问过程结束后,浏览器地址栏中显示的URL会发生改变,由初始的 URL 地址变成重定向的目标 URL;
而调用 RequestDispatcher.forward 方法的请求转发过程结束后,浏览器地址栏保持初始的URL地址不变。
案例介绍
HttpServletResponse.sendRedirect方法对浏览器的请求直接作出响应,响应的结果就是告诉浏览器去重新发出对另外一个URL的 访问请求。
这个过程好比有个绰号叫“浏览器”的人写信找张三借钱,张三回信说没有钱,让“浏览器”去找李四借,并将李四现在的通信地址告诉给了“浏览器”。于是,“浏览器”又按张三提供通信地址给李四写信借钱,李四收到信后就把钱汇给了“浏览器”。可见,“浏览器”一共发出了两封信和收到了两次回复, “浏览器”也知道他借到的钱出自李四之手。
RequestDispatcher.forward方法在服务器端内部将请求转发给另外一个资源,浏览器只知道发出了请求并得到了响应结果,并不知道在服务器程序内部发生了转发行为。
这个过程好比绰号叫“浏览器”的人写信找张三借钱,张三没有钱,于是张三找李四借了一些钱,甚至还可以加上自己的一些钱,然后再将这些钱汇给了“浏览器”。可见,“浏览器”只发 出了一封信和收到了一次回复,他只知道从张三那里借到了钱,并不知道有一部分钱出自李四之手。
访问请求和响应过程 比较
RequestDispatcher.forward方法的调用者与被调用者之间共享相同的request对象和response对象,它们属于同一个访问请求和响应过程;
而HttpServletResponse.sendRedirect方法调用者与被调用者使用各自的request对象和response对象,它们属于两个独立的访问请求和响应过程。
对于同一个WEB应用程序的内部资源之间的跳转,特别是跳转之前要对请求进行一些前期预处理,并要使用HttpServletRequest.setAttribute方法传递预处理结果,那就应该使用RequestDispatcher.forward方法。
不同WEB应用程序之间的重定向,特别是要重定向到另外一个WEB站点上的资源的情况,都应该使用HttpServletResponse.sendRedirect方法。
无论是RequestDispatcher.forward方法,还是HttpServletResponse.sendRedirect方法,在调用它们之前,都不能有内容已经被实际输出到了客户端
请求跳转和重定向区别?
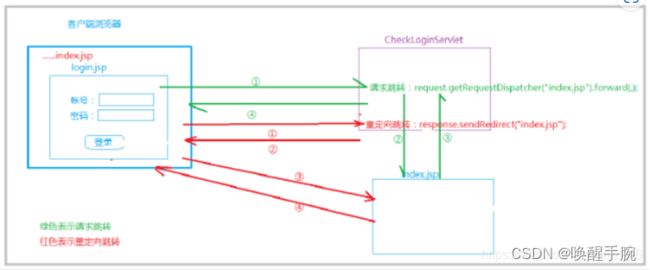
请求转发
请求转发是指服务器内部资源1的跳转到资源2的过程。它是在服务器内部进行的,对于客户端浏览器来说,它只发出了一次请求,服务器也只发送了一次响应。因此,无论是资源1还是资源2,都可以从这次请求中获取到用户提交的请求时所携带的相关数据。
重定向
重定向是指资源1需要访问资源2,但并未在服务器内直接访问,而是由服务器自动向浏览器发送一个响应,浏览器再自动提交一个新的请求,这个请求就是对资源2的请求。因此,对于资源2的访问,是先跳出了服务器,跳转到了客户端浏览器,再跳回到服务器。所以重定向又被称为服务器外跳转。
在重定向过程中,浏览器共提交了两次请求,服务器共发送了两次响应。虽然第一次响应和第二次响应对于用户来说是透明的,用户可能认为自己只提交了一次请求且只收到一次响应,但实际上发生了两次请求和两次响应。
总的来说,请求转发和重定向的主要区别在于:请求转发是在服务器内部进行的跳转,浏览器只发出了一次请求;而重定向是由服务器自动向浏览器发送响应并由浏览器再次提交新的请求的过程,所以浏览器发出了两次请求。
转发和跳转的小结
1. 转发使用的是 getRequestDispatcher()方法。重定向使用的是sendRedirect()
2. 转发:浏览器URL的地址栏不变。重定向:浏览器URL的地址栏改变
3. 转发是服务器行为。重定向是客户端行为
4. 转发是浏览器只做了一次访问请求。重定向是浏览器做了至少两次的访问请求
5. 转发 2 次跳转之间传输的信息不会丢失。重定向2次跳转之间传输的信息会丢失(request范围)
转发和重定向的选择
- 重定向的速度比转发慢,因为浏览器还得发出一个新的请求,如果在使用转发和重定向都无所谓的时候建议使用转发。
- 因为转发只能访问当前WEB的应用程序,所以不同WEB应用程序之间的访问,特别是要访问到另外一个WEB站点上的资源的情况,这个时候就只能使用重定向了。
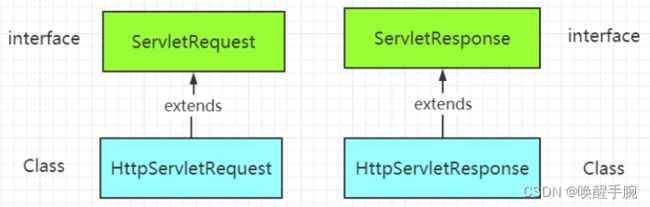
15. Servlet 内置关系
Web 服务器接收到客户端的 http 请求,针对这个请求,分别创建一个表示请求的 HttpServletRequest 对象,表示响应的一个 HttpServletResponse
如果要获取客户端请求过来的参数:HttpServletRequest
如果要给客户端响应一些信息:HttpServletRequest
HttpServletRequest 和 HttpServletResponse
| 隐式对象 | 转换后的对象 |
|---|---|
| request | HttpServletRequest / ServletRequest |
| response | HttpServletResponse / ServletResponse |
| session | HttpSession |
| application | ServletContext |
| out | JspWriter(PrintWriter) |
| page | this |
| config | ServletConfig |
| exception | Throwable |
| pageContext | PageContext |
16. response 下载文件
response 状态码
int SC_CONTINUE = 100;
int SC_SWITCHING_PROTOCOLS = 101;
int SC_OK = 200;
int SC_CREATED = 201;
int SC_ACCEPTED = 202;
int SC_NON_AUTHORITATIVE_INFORMATION = 203;
int SC_NO_CONTENT = 204;
int SC_RESET_CONTENT = 205;
int SC_PARTIAL_CONTENT = 206;
int SC_MULTIPLE_CHOICES = 300;
int SC_MOVED_PERMANENTLY = 301;
int SC_MOVED_TEMPORARILY = 302;
int SC_FOUND = 302;
int SC_SEE_OTHER = 303;
int SC_NOT_MODIFIED = 304;
int SC_USE_PROXY = 305;
int SC_TEMPORARY_REDIRECT = 307;
int SC_BAD_REQUEST = 400;
int SC_UNAUTHORIZED = 401;
int SC_PAYMENT_REQUIRED = 402;
int SC_FORBIDDEN = 403;
int SC_NOT_FOUND = 404;
int SC_METHOD_NOT_ALLOWED = 405;
int SC_NOT_ACCEPTABLE = 406;
int SC_PROXY_AUTHENTICATION_REQUIRED = 407;
int SC_REQUEST_TIMEOUT = 408;
int SC_CONFLICT = 409;
int SC_GONE = 410;
int SC_LENGTH_REQUIRED = 411;
int SC_PRECONDITION_FAILED = 412;
int SC_REQUEST_ENTITY_TOO_LARGE = 413;
int SC_REQUEST_URI_TOO_LONG = 414;
int SC_UNSUPPORTED_MEDIA_TYPE = 415;
int SC_REQUESTED_RANGE_NOT_SATISFIABLE = 416;
int SC_EXPECTATION_FAILED = 417;
int SC_INTERNAL_SERVER_ERROR = 500;
int SC_NOT_IMPLEMENTED = 501;
int SC_BAD_GATEWAY = 502;
int SC_SERVICE_UNAVAILABLE = 503;
int SC_GATEWAY_TIMEOUT = 504;
int SC_HTTP_VERSION_NOT_SUPPORTED = 505;
flush() 是清空的意思。 一般主要用在 IO 中,即清空缓冲区数据,就是说你用读写流的时候,其实数据是先被读到了内存中,然后用数据写到文件中,当你数据读完的时候不代表你的数据已经写完了,因为还有一部分有可能会留在内存这个缓冲区中。
这时候如果你调用了 close() 方法关闭了读写流,那么这部分数据就会丢失,所以应该在关闭读写流之前先 flush(),先清空数据。
fos.flush(); 可不是摆设, 这个方法的作用是把缓冲区的数据强行输出。如果你不 flush 就可能会没有真正输出,没有flush不代表它就没有输出,只是可能没有完全输出,调用 flush 是保证缓存清空输出。
private void DownFile(HttpServletResponse response) throws IOException {
## 获取下载的文件路径
## 先获取文件的相对路径(resource/image/wrist.jpg)
String relativePath = "/WEB-INF/classes/image/wrist.jpg";
## 先获取 ServletContext 再使用 ServletContext 的 getRealPath 方法获取绝对路径
String realPath = this.getServletContext().getRealPath(relativePath);
## 设置响应头控制浏览器以下载的形式打开文件
response.setHeader("content-disposition", "attachment;fileName="+"wrist.jpg");
## 获取下载文件的输入流
InputStream inputStream = new FileInputStream(realPath);
int count = 0;
byte[] data = new byte[1024];
## 通过 response 对象获取 OutputStream 流
OutputStream outputStream = response.getOutputStream();
while((count = inputStream.read(data)) != -1) {
outputStream.write(data, 0, count); // 将缓冲区的数据输出到浏览器
}
## 关闭输入流
inputStream.close();
## flush() 是清空的意思 即清空缓冲区数据
outputStream.flush();
## 关闭输出流
outputStream.close();
}
String fileName = realPath.substring(realPath.lastIndexOf("\\") + 1);
resp.setHeader("Content-Disposition", "attachment; filename = " + URLEncoder.encode(fileName))
这样主要是为了网站的安全的角度来说的,WEB-INF是安全目录Tomcat 默认的访问路径是WebRoot下的index.jsp,放在 WEB-INF 下的页面一般不配置是无法访问的。
在创建 JavaWeb 工程时有个 web.xml 的部署描述符,在下面有个这样可以定制首页的:做如下配置来看
<welcome-file-list>
<welcome-file>/WEB-INF/jsp/test.jspwelcome-file>
welcome-file-list>
web-app>
下载文件的步骤

17. response 验证码
向浏览器输出图片
## 使用response获得字节输出流
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
## 使用response获得字节输出流
ServletOutputStream out = response.getOutputStream();
## 获得服务器上的图片
String realPath = this.getServletContext().getRealPath("wrist.jpg");
InputStream in = new FileInputStream(realPath);
int len = 0;
byte[] buffer = new byte[1024];
while((len = in.read(buffer)) != 0){
out.write(buffer, 0, len);
}
in.close();
out.close();
}
绘制验证码
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
## 定义验证码宽高
int width = 100;
int height = 50;
## 创建BufferedImage对象
BufferedImage image = new BufferedImage(width,height,BufferedImage.TYPE_INT_RGB);
## 获取画笔对象
Graphics graphics = image.getGraphics();
## 设置画笔颜色为PINK
graphics.setColor(Color.PINK);
## 填充背景
graphics.fillRect(0,0,width,height);
## 设置画笔颜色为BLUE
graphics.setColor(Color.BLUE);
## 绘制边框
graphics.drawRect(0,0,width-1,height-1);
## 定义验证码字符集
String s = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
Random random = new Random();
## 循环显示字符
for (int i = 1; i <= 4; i++){
## 生成随机生成索引
int index = random.nextInt(s.length());
char ch = s.charAt(index);
graphics.drawString(ch + "",width / 5 * i,height / 2);
}
## 设置画笔颜色为绿色
graphics.setColor(Color.green);
for (int i = 0;i < 8; i++){
## 生成干扰线坐标
int x1 = random.nextInt(width-1);
int x2 = random.nextInt(width-1);
int y1 = random.nextInt(height-1);
int y2 = random.nextInt(height-1);
graphics.drawLine(x1,y1,x2,y2);
}
## 显示图片
ImageIO.write(image,"jpg",resp.getOutputStream());
}
18. request 内置方法
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,通过这个对象提供的方法,可以获得客户端请求的所有信息。
获得客户机信息和服务器信息
| 方法名称 | 具体功能 |
|---|---|
| getRequestURI | 返回请求行中的资源名部分 |
| getRequestURL | 返回客户端发出请求时的完整 URL |
| getQueryString | 返回请求行中的参数部分 |
| getRemoteAddr | 返回发出请求的客户机的IP地址 |
| getLocalAddr | 返回 WEB 服务器的 IP 地址 |
| getLocalName | 返回 WEB 服务器的 host 主机名 |
| getRemotePort | 返回客户机所使用的网络端口号 |
| getRemoteHost | 返回发出请求的客户机的完整主机名 |
获得客户机请求参数 ( 客户端提交的数据 )
| 序号 | 方法名称 | 使用率 |
|---|---|---|
| 1 | getParameter(String)方法 | 常用 |
| 2 | getParameterValues(String name)方法 | 常用 |
| 3 | getParameterNames()方法 | 不常用 |
| 4 | getParameterMap()方法 | 编写框架时常用 |
19. JSP / Servlet
在 JSP 中编写 Java 程序案例
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>简单的JSP页面</title>
</head>
<body>
<%
String welcome = "欢迎访问我的网页!";
%>
<h1><%= welcome %></h1>
</body>
</html>
JSP 全称 Java Server Pages 是一种动态网页开发技术。它使用 JSP 标签在 HTML 网页中插入 Java 代码(标签通常 <% 开头 %> 结束)
为什么使用 JSP ?
JSP(Java Server Pages)是由Sun Microsystems公司主导创建的一种动态网页技术标准。它部署于网络服务器上,可以响应客户端发送的请求,并根据请求内容动态地生成HTML、XML或其他格式文档的Web网页,然后返回给请求者。
JSP技术以Java语言作为脚本语言,为用户的HTTP请求提供服务,并能与服务器上的其它Java程序共同处理复杂的业务需求。JSP 程序和 CGI 程序有着相似的功能,但和 CGI 程序相比 JSP 程序优势如下所示:
性能更加优越,因为 JSP 可以直接在 HTML 网页中动态嵌入元素而不需要单独引用 CGI 文件
服务器调用的是已经编译好的 JSP 文件,而不像 CGI / Perl 那样必须先载入解释器和目标脚本
JSP 基于 Java Servlet API,因此,JSP 拥有各种强大的企业级 Java API,包括 JDBC,JNDI,EJB,JAXP 等等
JSP 页面可以与处理业务逻辑的 Servlet 一起使用,这种模式被 Java servlet 模板引擎所支持
JSP 是 Java EE 不可或缺的一部分,是一个完整的企业级应用平台。这意味着JSP可以用最简单的方式来实现最复杂的应用。
<dependency>
<groupId>javax.servlet.jspgroupId>
<artifactId>javax.servlet.jsp-apiartifactId>
<version>2.3.3version>
<scope>providedscope>
dependency>
<dependency>
<groupId>javax.servletgroupId>
<artifactId>javax.servlet-apiartifactId>
<version>4.0.1version>
<scope>providedscope>
dependency>
如何解决:查看 web.xml 中头文件 web-app 的版本,如果低于 2.4,修改 web-app 的版本即可正常获取相对路径,页面正常显示。

采用新版 4.0,问题解决
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0"
metadata-complete="true">
web-app>
项目案例
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<body>
<h2>Hello World!</h2>
<form action="${pageContext.request.contextPath}/login" method="get">
名字:<input type="text" placeholder="请输入名字:" name="name">
<input type="submit" value="登录">
</form>
<a href="${pageContext.request.contextPath}/hello">下载文件</a>
</body>
</html>
package com.alibaba.servlet;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
public class LoginServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String name = req.getParameter("name");
System.out.println("name = " + name);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
super.doGet(req, resp);
}
}
20. Date 时间 日期
| 序号 | 表达式 | 代表的时间 |
|---|---|---|
| 1 | yyyy | 年 |
| 2 | MM | 月 |
| 3 | dd | 日 |
| 4 | hh | 1~12 小时制 (1 - 12) |
| 5 | HH | 24 小时制 (0 - 23) |
| 6 | mm | 分 |
| 7 | ss | 秒 |
| 8 | S | 毫秒 |
| 9 | E | 星期几 |
| 10 | D | 一年中的第几天 |
| 11 | F | 一月中的第几个星期 (会把这个月总共过的天数除以 7) |
| 12 | w | 一年中的第几个星期 |
| 13 | W | 一月中的第几星期 (会根据实际情况来算) |
| 14 | a | 上下午标识 |
| 15 | k | 和 HH 差不多,表示一天24小时制 (1 - 24) |
| 16 | K | 和 hh 差不多,表示一天12小时制 (0 - 11) |
| 17 | z | 表示时区 |
代码实现举例
public class Format {
public static void main(String[] args) {
Date date = new Date();
System.out.println("一般日期输出:" + date);
System.out.println("时间戳:" + date.getTime());
SimpleDateFormat formatA = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String time = formatA.format(date.getTime());
## 这个就是把时间戳经过处理得到期望格式的时间
System.out.println("格式化结果A:" + time);
SimpleDateFormat formatB = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
time = formatB.format(date.getTime());
System.out.println("格式化结果B:" + time);
}
}
21. Cookie 会话
Cookie是储存在用户本地终端上的数据,通常由网站为了辨别用户身份和进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息。这些数据通常包含用户浏览习惯、网站登录信息、个性化设置等,以帮助用户快速登录和个性化浏览。
浏览器可以通过Cookie来跟踪用户的行为和偏好,例如记录用户访问某个网站的次数、用户的搜索历史、用户的购物车内容等等。此外,Cookie还可以帮助网站提供更个性化的服务,例如根据用户的兴趣推荐相关内容、记住用户的登录信息等等。
虽然Cookie在某些情况下可能会被用于跟踪用户的行为和偏好,但它们通常是安全的,因为它们只能被存储在用户的本地计算机上,而不能被用于收集用户的个人信息或访问用户的计算机上的其他数据。同时,用户也可以通过浏览器设置来限制或禁用Cookie的使用,以保护自己的隐私和安全。
Cookie 工作原理
(1)浏览器端第一次发送请求到服务器端
(2)服务器端创建Cookie,该Cookie中包含用户的信息,然后将该Cookie发送到浏览器端
(3)浏览器端再次访问服务器端时会携带服务器端创建的Cookie
(4)服务器端通过Cookie中携带的数据区分不同的用户
Cookie 作用
-
可以实现多个页面之间数据共享
-
cookie 保存在浏览器本地
-
cookie 和域名是关联起来的。
-
默认如果 cookie 不设置过期时间的话,浏览器关闭 cookie 就销毁了。
-
如果设置 cookie 的过期时间,cookie 没有过期的时候,关闭浏览器重新打开 cookie 还是存在的
具体解释
-
客户端第一次访问 JSP 文件,JSP 被翻译成 Servlet 时会自动创建 Session,此后客户端再次访问就会带着 JSESSIONID 过来。
-
当客户端重启浏览器时,客户端的 JSESSIONID 被销毁(此时服务端的 Session 没有受影响),客户端再次访问浏览器没有带着 JSESSIONID,服务端将再次为客户创建 Session。
-
在 JSP 文件 page 指令里设置 session=“false”,客户端访问此 JSP 将不会创建 Session。
-
客户端访问 Servlet 时不会创建 Session,只有在通过 request.getSession() 或是跳转到 JSP 文件时才创建 Session。
Cookie 创建过程

最近玩 jsp 用 tomcat 作为服务器,结果每次 tomcat 都在cookie里自动创建了 SessionId,那么怎么才能让 tomcat 不自动创建 SessionId,让 cookie 更加简洁呢?其实方法很简单,只要在第一次访问 jsp 的页面上加上一句 <%@ page session="false"%> 就行了。

Cookie 案例代码
package com.alibaba.servlet;
import javax.servlet.ServletException;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.text.SimpleDateFormat;
import java.util.Date;
public class CookieDemo extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.setCharacterEncoding("utf-8");
resp.setCharacterEncoding("utf-8");
Date date = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss");
PrintWriter writer = resp.getWriter();
Cookie[] cookies = req.getCookies();
System.out.printf("cookie:" + cookies);
if (cookies != null){
for (Cookie cookie : cookies) {
if (cookie.getName().equals("time")) {
cookie.setValue(simpleDateFormat.format(date)+"");
writer.write("your previous visit is " + cookie.getValue());
}
}
} else {
Cookie cookie = new Cookie("time", simpleDateFormat.format(date)+"");
resp.addCookie(cookie);
writer.write("this is your first visit");
}
}
}
22. Session 会话
Session在计算机中,尤其是在网络应用中,被称为“会话控制”。Session对象存储特定用户会话所需的属性和配置信息。这样,当用户在应用程序的Web页之间跳转时,存储在Session对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当用户请求来自应用程序的 Web页时,如果该用户还没有会话,则Web服务器将自动创建一个Session对象。当会话过期或被放弃后,服务器将终止该会话。
Session对象最常见的用法是存储用户的首选项。例如,如果用户指明不喜欢查看图形,就可以将该信息存储在Session对象中。有关使用Session对象的详细信息,请参阅“ASP应用程序”部分的“管理会话”。注意会话状态仅在支持cookie的浏览器中保留。
Session 工作原理
① 浏览器端第一次发送请求到服务器端,服务器端创建一个 Session,同时会创建一个特殊的Cookie(name 为 JSESSIONID 的固定值,value 为 session 对象的 ID),然后将该 Cookie 发送至浏览器端。
② 浏览器端发送第 N(N>1)次请求到服务器端,浏览器端访问服务器端时就会携带该 name 为JSESSIONID 的 Cookie 对象,
③ 服务器端根据 name 为 JSESSIONID 的 Cookie 的 value (SessionId),去查询 Session 对象,从而区分不同用户。
name 为 JSESSIONID 的 Cookie 不存在(关闭或更换浏览器),返回 1 中重新去创建 Session 与特殊的 Cookie
name 为 JSESSIONID 的 Cookie 存在,根据 value 中的 SessionId 去寻找 session 对象
value 为 SessionId 不存在(Session对象默认存活30分钟),返回 1 中重新去创建 Session 与特殊的 Cookie
value 为 SessionId 存在,返回session对象
注意点:为了安全起见,JSESSIONID 这种东西是 http only 的,javascript 是拿不到的。
如何获取全部会话的 session
Servlet2.1 之后不支持 SessionContext里面getSession(String id)方法,也不存在遍历所有会话Session的方法。
Session工作原理
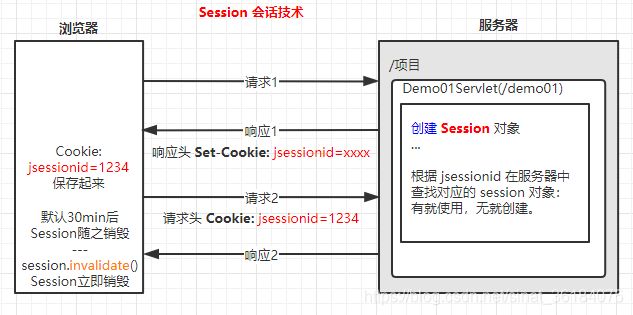
执行流程
第一次请求,请求头中没有 jsessionid 的 cookie,当访问到对应的 servlet 资源时,执行到 getSession() 会创建 HttpSession 对象;进而响应时就将 session 的 id 作为 cookie 的 value,响应到浏览器 Set-cookie:jsessionid=xxxx
再一次请求时,http 请求中就有一个 cookie:jsessionid=xxxx 信息,那么该 servlet 就可以通过getSession() 获取到 jsessionid 在服务器内查找对应的 session 对象,有就使用,无就创建。
### 获取session对象,服务器底层创建Session
HttpSession session = request.getSession();
### 获取session对象的唯一标识:sessionID (JSESSIONID=E925DE1EF00F7944537C01A3BC0E2688)
String jsessionid = session.getId();
### 销毁session对象中的jsessionid
session.invalidate();
### 往 session 中存储 msg
HttpSession session = request.getSession();
session.setAttribute("msg", "helloSession");
### 获取 msg
HttpSession session = request.getSession();
Object msg = session.getAttribute("msg");
### 删除域对象中的数据
session.removeAttribute("msg");
Session 生命周期
一般都是默认值 30 分钟,无需更改。取决于 Tomcat 中 web.xml 默认配置:
<session-config>
<session-timeout>30session-timeout>
session-config>
Session 生命周期结束时机
浏览器关闭
销毁 Cookie 中的 jsessionid=xxx,原 session 对象会保留默认 30 min后才销毁,30 分钟后为新的session
session 销毁
主动调用 session.invalidate() 方法后,立即将 session 对象销毁,再次访问时会创建新的 session
HTTP 请求中 4 大共享数据方式对比

Session 生命周期 操作方法
session.setMaxInactiveInterval(20 * 60); // 设置session过期时间
session.invalidate(); // 销毁session的方法
session.getCreationTime(); // 获得session的创建时间
session.getLastAccessedTime(); // 获得session最后一次被使用的时间
Personal understanding
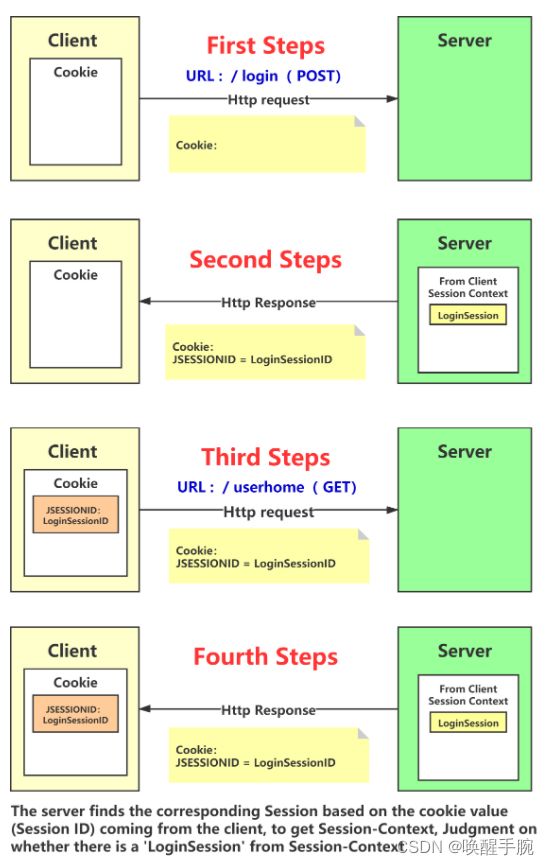
23. Filter 过滤器
过滤器是一些 web 应用程序组件,可以绑定到一个 web 应用程序中。但是与其他 web 应用程序组件不同的是,过滤器是"链"在容器的处理过程中的。
这就意味着它们会在servlet处理器之前访问一个进入的请求,并且在外发响应信息返回到客户前访问这些响应信息。这种访问使得过滤器可以检查并修改请求和响应的内容。
Filter ?什么是过滤器?
-
Filter 过滤器它是 JavaWeb 的三大组件之一
-
Filter 过滤器它是 JavaEE 的规范,也就是接口
-
Filter 过滤器它的作用是:拦截请求,过滤响应
三大组件分别是:Servlet 程序、Listener 监听器、Filter 过滤器
拦截请求常见的应用场景
常见场景:1. 权限检查 2. 日记操作 3. 事务管理 ……等等
Filter 有如下几个用处
- 在 HttpServletRequest 到达 Servlet 之前,拦截客户的 HttpServletRequest
- 根据需要检查 HttpServletRequest,也可以修改 HttpServletRequest 头和数据
- 在 HttpServletResponse 到达客户端之前,拦截 HttpServletResponse
- 根据需要检查 HttpServletResponse,可以修改 HttpServletResponse 头和数据
创建一个 Filter 只需两个步骤:(1) 创建 Filter 处理类 (2) 在 web.xml 文件中配置 Filter
创建 Filter 必须实现 javax.servlet.Filter 接口,在该接口中定义了三个方法
void init(FilterConfig config): 用于完成 Filter 的初始化。
void destroy(): 用于Filter 销毁前,完成某些资源的回收。
void doFilter(ServletRequest request, ServletResponse response, FilterChain chain): 实现过滤功能,该方法就是对每个请求及响应增加的额外处理。
package com.alibaba.filter;
import javax.servlet.*;
import java.io.IOException;
public class WordFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
this.init(filterConfig);
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
filterChain.doFilter(servletRequest,servletResponse); // 让过滤器链请求继续走
}
@Override
public void destroy() {
this.destroy();
}
}
<filter>
<filter-name>WordFilterfilter-name>
<filter-class>com.alibaba.filter.WordFilterfilter-class>
filter>
<filter-mapping>
<filter-name>WordFilterfilter-name>
<url-pattern>/*url-pattern> ## 需要拦截的地址
filter-mapping>
案例:在web.xml中配置一些过滤器来拦截请求(比如下面解决乱码的编码过滤器)
<filter>
<filter-name>encodingFilterfilter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilterfilter-class>
<init-param>
<param-name>encodingparam-name>
<param-value>UTF-8param-value>
init-param>
<init-param>
<param-name>forceEncodingparam-name>
<param-value>trueparam-value>
init-param>
filter>
<filter-mapping>
<filter-name>encodingFilterfilter-name>
<url-pattern>/*url-pattern>
filter-mapping>
过滤器链

package com.zhiying.filter;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.IOException;
@WebFilter("/*")
public class AFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("过滤器 A 被执行了");
chain.doFilter(request,response);
System.out.println("过滤器 A 回来了");
}
}
24. Listener 监听器
Servlet Listener 是一种 Java 程序,用于监听 Java web 程序中的事件,例如创建、修改、删除 Session、request、context 等,并触发响应的事件。
Listener 用于对 Session、request、context 进行监控。
在 Servlet 2.5 规范中共有 8 种 Listener
HttpSessionListener :监听 HttpSession 的创建和销毁事件。
HttpSessionAttributeListener :监听 HttpSession 中属性(Attribute)的添加、删除和修改事件。
HttpSessionBindingListener :监听对象绑定到 HttpSession 和从 HttpSession 解绑的事件。
ServletContextListener :监听 Web 应用程序的上下文(ServletContext)的创建和销毁事件。
ServletContextAttributeListener :监听 ServletContext 中属性(Attribute)的添加、删除和修改事件。
ServletRequestListener :监听 ServletRequest 的创建和销毁事件。
ServletRequestAttributeListener :监听 ServletRequest 中属性(Attribute)的添加、删除和修改事件。
HttpListener :监听对特定 HTTP 请求的接入,以及 HTTP 响应的发送。
监听器需要实现不同的 Listener 接口,一个 Listener 也可以实现多个接口,这样就可以实现多种功能的监听。对于 Servlet 的 Listener ,只需要实现特定接口即可。对于不同功能的 Listener ,实现方法也不同。
web.xml 文件中配置 Listener
com.example.MyServletContextListener
其中,
25. File IO 读写操作
File 类主要是 JAVA 为文件这块的操作(如删除、新增等)而设计的相关类。File 类的包名是 java.io,其实现了 Serializable, Comparable 两大接口以便于其对象可序列化和比较。

类的属性变量
path:封装的 String 类型变量,代表了文件的路径。
类的方法
public File(String parent, String child) {}
若子路径child为Null,会抛出NullPointerException空异常错误
当父路径为Null时,会以子路径child作为绝对路径创建实例,等同于调用第一个File(String child )效果一样
当父路径不为空时,会以父路径作为目录,子路径作为父路径下的目录或者文件名,最后得到的实例对象的路径就是父路径和子路径的组合
public String getName() ## 获取实例对象代表的文件名字(包含文件后缀)
public String getParent() ## 获取实例对象代表的文件上级目录
public String getPath() ## 获取实例对象代表的文件的实际路径
public boolean delete() ## 删除实例对象代表的文件或目录,当代表目录时,必须目录下为空才可以删除
public boolean mkdir() ## 根据实例对象的路径名创建目录(若目录已存在,则false;若路径是文件,则fasle;若路径的上级目录不存在则false)
public boolean mkdirs() ## 根据实例对象的路径创建目录,包括创建那些必须的且不存在的父级目录
public String[] list() ## 获取实例对象代表的文件下的各级文件名和目录名,返回一个字符串数组
public File[] listFiles() ## 获取指定File目录下所有的文件和目录的File数组
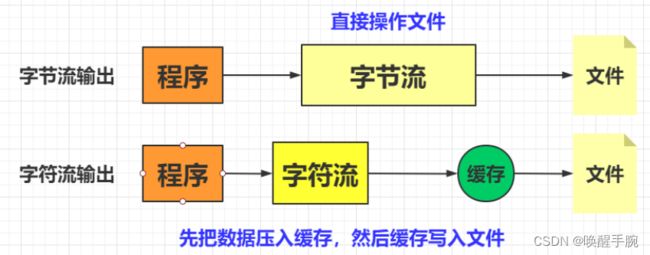
字节流 和 字符流 区别
采用字节流输出文件
package org.lxh.demo12.byteiodemo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class OutputStreamDemo05 {
public static void main(String[] args) throws Exception { // 异常抛出,不处理
## 第 1 步:使用 File 类找到一个文件
File f = new File("d:" + File.separator + "test.txt"); // 声明File 对象
## 第 2 步:通过子类实例化父类对象
OutputStream out = null;
## 准备好一个输出的对象
out = new FileOutputStream(f);
## 通过对象多态性进行实例化
## 第 3 步:进行写操作
String str = "Hello World!!!";
## 准备一个字符串
byte b[] = str.getBytes();
## 字符串转byte数组
out.write(b);
## 将内容输出
## 第 4 步:关闭输出流
out.close(); 此时没有关闭
}
}
若此时没有关闭字节流操作,但是文件中也依然存在了输出的内容,证明字节流是直接操作文件本身的。而下面继续使用字符流完成,再观察效果。结果:txt 文件中有数据
采用字符流输出文件
package org.lxh.demo12.chariodemo;
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class WriterDemo03 {
public static void main(String[] args) throws Exception { // 异常抛出, 不处理
## 第 1 步:使用 File 类找到一个文件
File f = new File("d:" + File.separator + "test.txt");// 声明File 对象
## 第 2 步:通过子类实例化父类对象
Writer out = null;
## 准备好一个输出的对象
out = new FileWriter(f);
## 通过对象多态性进行实例化
## 第 3 步:进行写操作
String str = "Hello World!!!";
## 准备一个字符串
out.write(str);
## 将内容输出
## 第 4 步:关闭输出流
out.close();
}
}
程序运行后会发现文件中没有任何内容,这是因为字符流操作时使用了缓冲区,而在关闭字符流时会强制性地将缓冲区中的内容进行输出,但是如果程序没有关闭,则缓冲区中的内容是无法输出的,所以得出结论:字符流使用了缓冲区,而字节流没有使用缓冲区。
26. File IO 缓冲区
在很多地方都碰到缓冲区这个名词,那么到底什么是缓冲区?又有什么作用呢?某些情况下,如果一个程序频繁地操作一个资源(如文件或数据库),则性能会很低,此时为了提升性能,就可以将一部分数据暂时读入到内存的一块区域之中,以后直接从此区域中读取数据即可,因为读取内存速度会比较快,这样可以提升程序的性能。
在字符流的操作中,所有的字符都是在内存中形成的,在输出前会将所有的内容暂时保存在内存之中,所以使用了缓冲区暂存数据。
如果想在不关闭时也可以将字符流的内容全部输出,则可以使用Writer类中的flush()方法完成。
提问:使用字节流好还是字符流好?
学习完字节流和字符流的基本操作后,已经大概地明白了操作流程的各个区别,那么在开发中是使用字节流好还是字符流好呢?使用字节流更好。
在回答之前,先为读者讲解这样的一个概念,所有的文件在硬盘或在传输时都是以字节的方式进行的,包括图片等都是按字节的方式存储的,而字符是只有在内存中才会形成,所以在开发中,字节流使用较为广泛。
Java 字节流
InputStream 是所有字节输入流的祖先,而 OutputStream 是所有字节输出流的祖先。
Java字符流
Reader 是所有读取字符串输入流的祖先,而 Writer 是所有输出字符串的祖先。
注意:InputStream 、OutputStream 、Reader 、Writer 都是抽象类,所以不能直接 new 生成。
注意:字节流是最基本的,所有的InputStream和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的。但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的encode来处理,也就是要进行字符集的转化。
这两个之间通过 InputStreamReader, OutputStreamWriter 来关联,实际上是通过 byte[] 和 String 来关联,在实际开发中出现的汉字问题实际上都是在字符流和字节流之间转化不统一而造成的。
什么情况下使用哪种流呢?
如果数据所在的文件通过 windows 自带的记事本打开并能读懂里面的内容,就用字符流,其他用字节流进行操作。
困惑点
既然字节流是直接把数据写入文件,不需要用到 flush() 刷新,那为何字节流的类要提供 flush() 这个方法呢?如果说是因为实现了 Flushabe 接口,那为什么要实现这个接口呢?字节流好像在任何时候都用不到这个功能。求高人解惑?
public class FileDemo {
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream("G:\\java\\document.txt");
## 底层的实现如下
FileOutputStream fos = new FileOutputStream(new File("G:\\java\\document.txt"));
fos.write(65);
## write 可以写入字节,写入“A”
byte[] buffer = {97, 98, 99};
fos.write(buffer);
## write 也可以写入字节数组,写入“abc”
fos.close();
## 关闭此文件输出流,并且释放与此流相关的资源。
}
}
FileOutputStream( ) 方法 底层的实现

write( ) 方法 底层的实现


字节流如何实现换行 window:\r\n linux:\n mac:\r
fos.write("\r\n".getBytes()); ## .getBytes() 转换类型

字节流读数据
public class FileDemo {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("G:\\Java\\document.txt");
System.out.println("read = " + (char)fis.read()); ## a
System.out.println("read = " + (char)fis.read()); ## b
System.out.println("read = " + (char)fis.read()); ## c
System.out.println("read = " + fis.read()); ## 读到末尾的时候返回 -1
fis.close();
}
}
read(byte b[]) 具体介绍
public int read(byte b[]) throws IOException {
return readBytes(b, 0, b.length);
}
###
* Reads up to {@code len} bytes of data from this input stream
* into an array of bytes. If {@code len} is not zero, the method
* blocks until some input is available; otherwise, no
* bytes are read and {@code 0} is returned.
*
* @param b the buffer into which the data is read.
* @param off the start offset in the destination array {@code b}
* @param len the maximum number of bytes read.
* @return the total number of bytes read into the buffer, or
* {@code -1} if there is no more data because the end of
* the file has been reached.
* @throws NullPointerException If {@code b} is {@code null}.
* @throws IndexOutOfBoundsException If {@code off} is negative,
* {@code len} is negative, or {@code len} is greater than
* {@code b.length - off}
* @throws IOException if an I/O error occurs.
###
案例测试
public class Test {
public static void main(String[] args) throws IOException {
final String path = "D:/hello.txt";
## 1、得到数据文件
File file = new File(path);
## 2、建立数据通道
FileInputStream fileInputStream = new FileInputStream(file);
byte[] buf = new byte[1024];
int length = 0;
## 循环读取文件内容,输入流中将最多buf.length个字节的数据读入一个buf数组中,返回类型是读取到的字节数。
## 当文件读取到结尾时返回 -1,循环结束。
while((length = fileInputStream.read(buf)) != -1){
System.out.print(new String(buf,0,length));
}
## 最后记得,关闭流
fileInputStream.close();
}
}
我的代码测试学习
public class FileDemo {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("G:\\Java\\document.txt");
byte[] each_byte = new byte[10];
while (fis.read(each_byte) != -1){
for (byte b : each_byte) {
System.out.print(b +" ");
}
}
fis.close();
}
}
document.txt 内容
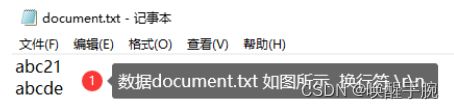
控制台输出的结果

解释:abc21 abcde
第1次读取对应 97 98 99 50 49 13 10 97 98 99
第2次读取对应 100 101 13 10 49 13 10 97 98 99
因为从第 2 次 10 后的字节结果,都是第 1 次的缓存
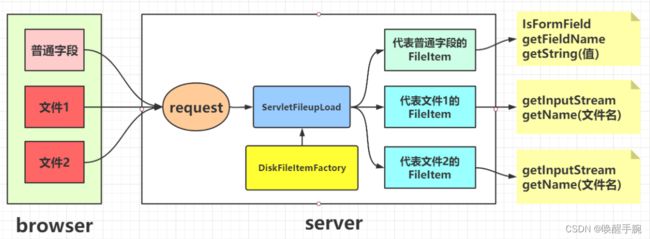
27. File IO 存储操作
文件上传和下载是 java web 中常见的操作,文件上传主要是将文件通过 IO 流传放到服务器的某一个特定的文件夹下,而文件下载则是与文件上传相反,将文件从服务器的特定的文件夹下的文件通过IO流下载到本地。
对于文件上传,浏览器在上传的过程中是将文件以流的形式提交到服务器端的,如果直接使用Servlet获取上传文件的输入流然后再解析里面的请求参数是比较麻烦,所以一般选择采用apache的开源工具common-fileupload这个文件上传组件。这个common-fileupload上传组件的jar包可以去apache官网上面下载,也可以在struts的lib文件夹下面找到,struts上传的功能就是基于这个实现的。
common-fileupload是依赖于common-io这个包的,所以还需要下载这个包。
文件上传的注意事项
1. 为了保证服务器安全,上传文件应该放在外界无法直接访问的目录下,比如放于 WEB-INF 目录下。
2. 为了防止文件覆盖的现象发生,要为上传文件产生一个唯一的文件名。常见的解决方案: 时间戳、UUID、MD5、位运算算法
3. 为防止一个目录下面出现太多文件,要使用 hash 算法打散存储。
4. 要限制文件上传的最大值
5. 可以限制上传文件的类型,在收到文件名时,判断后缀名是否合法。

注意点
因为我们上传选择的是文件类型,这是因为 request.getParameter() 获取到的只能是键值对的形式,而通过我们设置 enctype 的属性,发现传递的参数已经不是键值对的形式,因此,获取不到。
后面添了enctype属性后,查看浏览器中的请求参数,可以看出,后面的一堆乱码文件应该就是要传输文件的二进制的内容。
上传思路
接下来讲解一下上传的思路,首先我们的输入流中包含普通项和上传项,普通项就是我们的姓名和密码,上传项就是我们的图片。中间通过分割线隔开。我们通过判断可以知道哪些是上传项、哪些是普通项。当为上传项时,先在服务器上新建一个和上传文件名一样的文件,然后利用IO流,将这些二进制文件写入服务器上的这个文件中,就完成了文件的上传。
DOCTYPE html >
<html>
<head>
<meta charset="UTF-8">
<title>使用JSP+Servlet实现文件的上传下载title>
<script type="text/javascript" src="js/jquery-1.11.1.js">script>
head>
<body>
<h2>使用JSP+Servlet实现文件的上传下载h2>
<form action="uploadServlet" method="post" enctype="multipart/form-data" >
请选择文件:<input id="file" name="file" type="file" />
<input type="submit" value="上传" />${result}
form>
下载:<a href="downloadServlet?filename=FileTest.txt">fileTest.txta>${errorResult}
body>
html>
package com.alibaba.servlet;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.RandomAccessFile;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class UploadServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public UploadServlet() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request,response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");
### 更改响应字符流使用的编码,还能告知浏览器用什么编码进行显示
### 从 request 中获取文本输入流信息
InputStream fileSourceStream = request.getInputStream();
String tempFileName = "F:/tempFile";
### 设置临时文件,保存待上传的文本输入流
File tempFile = new File(tempFileName);
### outputStram文件输出流指向这个 tempFile
FileOutputStream outputStream = new FileOutputStream(tempFile);
### 读取文件流
byte temp[] = new byte[1024];
int n;
while(( n = fileSourceStream.read(temp)) != -1){
outputStream.write(temp, 0, n);
}
outputStream.close();
fileSourceStream.close();
### 获取上传文件的名称
RandomAccessFile randomFile = new RandomAccessFile(tempFile,"r");
randomFile.readLine();
String str = randomFile.readLine();
int start = str.lastIndexOf("=") + 2;
int end = str.lastIndexOf("\"");
String filename = str.substring(start, end);
### 定位文件指针到文件头
randomFile.seek(0);
long startIndex = 0;
int i = 1;
### 获取文件内容的开始位置
while(( n = randomFile.readByte()) != -1 && i <=4){
if(n == '\n'){
startIndex = randomFile.getFilePointer();
i ++;
}
}
startIndex = startIndex -1;
### 这里一定要减 1,因为前面多读了一个,这里很容易忽略
### 获取文件内容结束位置
randomFile.seek(randomFile.length());
long endIndex = randomFile.getFilePointer();
int j = 1;
while(endIndex >=0 && j<=2){
endIndex--;
randomFile.seek(endIndex);
if(randomFile.readByte() == '\n'){
j++;
}
}
### 设置保存上传文件的路径
String realPath = "F:/file";
File fileupload = new File(realPath);
if(!fileupload.exists()){
fileupload.mkdir();
}
File saveFile = new File(realPath,filename);
RandomAccessFile randomAccessFile = new RandomAccessFile(saveFile,"rw");
### 根据起止位置从临时文件中读取文件内容
randomFile.seek(startIndex);
while(startIndex < endIndex){
randomAccessFile.write(randomFile.readByte());
startIndex = randomFile.getFilePointer();
}
### 关闭输入输出流并 删除临时文件
randomAccessFile.close();
randomFile.close();
tempFile.delete();
request.setAttribute("result", "文件上传成功");
RequestDispatcher dispatcher = request.getRequestDispatcher("index.jsp");
dispatcher.forward(request, response);
}
}
28. Java 邮件发送
要在网络上实现邮件功能,必须要有专门的邮件服务器。这些邮件服务器类似于现实生活中的邮局,它主要负责接收用户投递过来的邮件,并把邮件投递到邮件接收者的电子邮箱中。
电子邮件的应用非常广泛,常见的如在某网站注册了一个账户,自动发送一封激活邮件,通过邮件找回密码,自动批量发送活动信息等。很显然这些应用不可能和我们自己平时发邮件一样,先打开浏览器,登录邮箱,创建邮件再发送。本文将简单介绍如何通过 Java 代码来创建电子邮件,并连接邮件服务器发送邮件。
SMTP 服务器地址:一般是 smtp.xxx.com,比如 163 邮箱是 smtp.163.com,qq 邮箱是 smtp.qq.com。
电子邮件协议
电子邮件在网络中传输和网页一样需要遵从特定的协议,常用的电子邮件协议包括 SMTP,POP3,IMAP。其中邮件的创建和发送只需要用到 SMTP协议,所以本文也只会涉及到SMTP协议。SMTP 是 Simple Mail Transfer Protocol 的简称,即简单邮件传输协议。
SMTP 协议 发送邮件
我们通常把处理用户 smtp 请求(邮件发送请求)的服务器称之为 SMTP 服务器(邮件发送服务器)。
POP3 协议 接收邮件
我们通常把处理用户 pop3 请求(邮件接收请求)的服务器称之为 POP3 服务器(邮件接收服务器)。
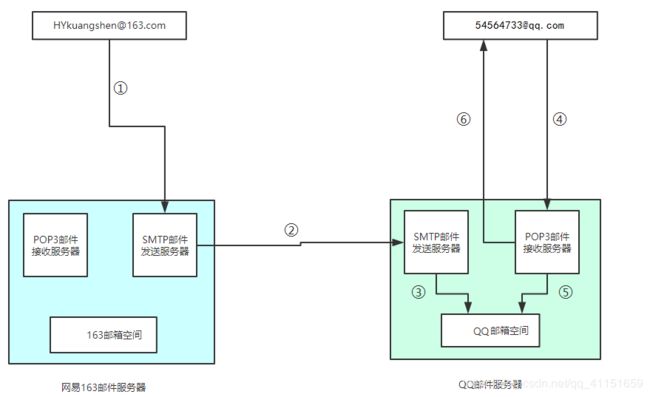
1. 首先通过smtp协议连接到Smtp服务器,然后发送一封邮件给网易的邮件服务器
2. 网易分析发现需要去QQ的邮件服务器,通过smtp协议将邮件转投给QQ的Smtp服务器
3. QQ将接收到的邮件存储在[email protected]这个邮件账号的空间中
4. 再通过Pop3协议连接到Pop3服务器收取邮件
5. 从[email protected]这个邮件账号的空间中取出邮件
6. Pop3服务器将取出来的邮件送出去
有可能填写的收件人地址,发件人地址等信息都正确了,控制台也打印了正确的信息,但是在收件箱就是收不到信息。这是因为可能收件箱服务器拒收了你发的邮件(比如认为你的邮件是广告),这时候可能在垃圾箱里能找到,可能找不到。解决办法是重复的邮件内容不要多次发送,或者更换收件箱试试。
使用 Java发送 E-mail 十分简单,但是首先你应该准备 JavaMail API 和Java Activation Framework
<dependency>
<groupId>javax.mailgroupId>
<artifactId>javax.mail-apiartifactId>
<version>1.6.2version>
dependency>
<dependency>
<groupId>javax.activationgroupId>
<artifactId>activationartifactId>
<version>1.1.1version>
dependency>

public class SendEmail {
public static void main(String[] args) throws Exception {
Properties prop = new Properties();
### 设置 QQ 邮件服务器
prop.setProperty("mail.host", "smtp.qq.com");
### 邮件发送协议
prop.setProperty("mail.transport.protocol", "smtp");
### 需要验证用户名密码
prop.setProperty("mail.smtp.auth", "true");
### 关于 QQ 邮箱,还要设置 SSL 加密,加上以下代码即可
MailSSLSocketFactory sf = new MailSSLSocketFactory();
sf.setTrustAllHosts(true);
prop.put("mail.smtp.ssl.enable", "true");
prop.put("mail.smtp.ssl.socketFactory", sf);
### 使用JavaMail发送邮件的5个步骤
### 1、创建定义整个应用程序所需的环境信息的 Session 对象
Session session = Session.getDefaultInstance(prop, new Authenticator() {
public PasswordAuthentication getPasswordAuthentication() {
### 发件人邮件用户名、授权码
return new PasswordAuthentication("[email protected]", "授权码");
}
});
### 开启 Session 的 debug 模式,这样就可以查看到程序发送 Email 的运行状态
session.setDebug(true);
### 2、通过session得到transport对象
Transport ts = session.getTransport();
### 3、使用邮箱的用户名和授权码连上邮件服务器
ts.connect("smtp.qq.com", "[email protected]", "授权码");
### 4、创建邮件
### 创建邮件对象
MimeMessage message = new MimeMessage(session);
### 指明邮件的发件人
message.setFrom(new InternetAddress("[email protected]"));
### 指明邮件的收件人,现在发件人和收件人是一样的,那就是自己给自己发
message.setRecipient(Message.RecipientType.TO, new InternetAddress("[email protected]"));
### 邮件的标题
message.setSubject("只包含文本的简单邮件");
### 邮件的文本内容
message.setContent("你好啊!", "text/html;charset=UTF-8");
### 5、发送邮件
ts.sendMessage(message, message.getAllRecipients());
ts.close();
}
}
带图片和附件的邮件 具体介绍:博客介绍
MIME
MIME(Multipurpose Internet Mail Extensions)是多用途互联网邮件扩展类型。它是一个互联网标准,扩展了电子邮件标准,使其能够支持:非ASCII字符文本;非文本格式附件(二进制、声音、图像等);由多部分(multiple parts)组成的消息体;包含非ASCII字符的头信息(Header information)。
MIME 规定了用于表示各种各样的数据类型的符号化方法。它的最初目的是为了在发送电子邮件时附加多媒体数据,让邮件客户程序能根据其类型进行处理。此外,在万维网中使用的 HTTP 协议中也使用了 MIME 的框架。
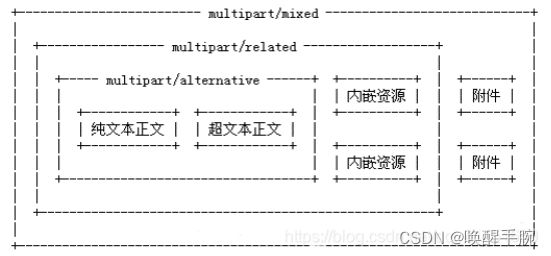
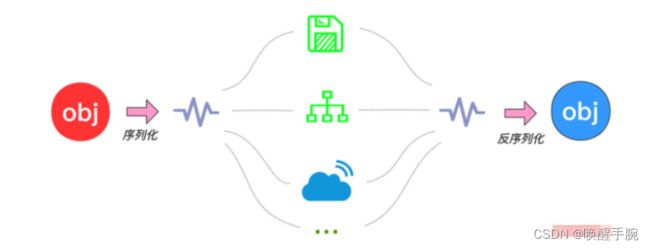
29. Serializable
为什么网络传输时对象要序列化,而字符串就不用序列化?
网络传输会将对象转换成字节流传输,序列化可以将一个对象转化成一段字符串编码,以便在网络上传输或者做存储处理,使用时再进行反序列,而字符串不用序列化的原因是如果你看过 javaSE 的源码,你就知道,字符串是已经实现了 Serializable 接口的,所以它已经是序列化了的。

遇到这个 Java Serializable 序列化这个接口,我们可能会有如下的问题
1. 什么叫序列化和反序列化?
2. 作用?为啥要实现这个 Serializable 接口,也就是为啥要序列化?
3. serialVersionUID 这个的值到底是在怎么设置的,有什么用?有的是 1 L,有的是一长串数字,迷惑 ing?
我刚刚见到这个关键字 Serializable 的时候,就有如上的这么些问题,这个Serializable接口,以及相关的东西,全部都在 Java io 里面的。
序列化:把对象转换为字节序列的过程称为对象的序列化。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
在什么情况下需要序列化?
- 当你想把的内存中的对象状态保存到一个文件中或者数据库中时候
- 当你想用套接字在网络上传送对象的时候
- 当你想通过RMI传输对象的时候
Java 如何实现 Serializable 序列化?
实现 Serializable 接口即可,上面这些理论都比较简单,下面实际代码看看这个序列化到底能干啥,以及会产生的bug问题。transient 修饰的属性,是不会被序列化的
transient private String name;
serialVersionUID
一般情况下,我们在定义实体类时会继承 Serializable 接口。并且会定义 serialversionUID(如果我们没有自己声明一个 serialVersionUID 变量,接口会默认生成一个 serialVersionUID)
经常在实现了 Serializable 接口的类中能看见 transient 关键字。这个关键字并不常见。 transient 关键字的作用是:阻止实例中那些用此关键字声明的变量持久化。当对象被反序列化时(从源文件读取字节序列进行重构),这样的实例变量值不会被持久化和恢复。
序列化的原本意图是希望对一个Java对象作一下“变换”,变成字节序列,这样一来方便持久化存储到磁盘,避免程序运行结束后对象就从内存里消失,另外变换成字节序列也更便于网络运输和传播。
序列化案例
package com.example.demo.entity.serializable;
import java.io.Serializable;
public class Persion implements Serializable {
private static final long serialVersionUID = 4359709211352400087L;
public Long id;
public String name;
public final String userName;
public Persion(Long id, String name){
this.id = id;
this.name = name;
userName = "wristwaking";
}
public String toString() {
return id.toString() + "--" + name.toString();
}
}
序列化操作
package com.example.demo.entity.serializable;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class SerialTest {
public static void main(String[] args) {
Persion person = new Persion(1L, "mahaocheng");
System.out.println("person Seria:" + person);
try {
FileOutputStream fos = new FileOutputStream("Persion.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(person);
oos.flush();
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
反序列化操作
package com.example.demo.entity.serializable;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.ObjectInputStream;
public class DeserialTest {
public static void main(String[] args) {
Persion person;
try {
FileInputStream fis = new FileInputStream("Persion.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
person = (Persion) ois.readObject();
ois.close();
fis.close();
System.out.println(person.toString());
System.out.println(person.userName);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
情况一: Persion 类序列化之后,从 A 端传到 B 端,然后在 B 端进行反序列化,在序列化Persion 和反序列化 Persion 的时候 A 和 B 端都需要一个相同的类。如果两处的 serialVersionUID 不一致,会产生什么样的效果呢。
先执行测试类 SerialTest,生成序列化文件,代表 A 端序列化后的文件,然后修改 serialVersion 值,再执行测试类 DeserialTest,代表 B 端使用不同 serialVersion 的类去反序列化,结果报错
java.io.InvalidClassException: com.example.demo.entity.serializable.Persion; local class incompatible: stream classdesc serialVersionUID = 4359709211352400087, local class serialVersionUID = 4359709211352400082
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:616)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1843)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1713)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2000)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1535)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:422)
情况二: 假设两处 serialVersionUID 一致,如果 A 端增加一个字段,然后序列化,而 B 端不变,然后反序列化,会是什么情况呢?
新增 public int age; 执行SerialTest,生成序列化文件,代表A端。删除 public int age,反序列化,代表B端,最后的结果为:执行序列化,反序列化正常,但是A端增加的字段丢失(被 B 端忽略)。
情况三: 假设两处 serialVersionUID 一致,如果 B 端减少一个字段,A 端不变,会是什么情况呢?
序列化,反序列化正常,B 端字段少于 A 端,A 端多的字段值丢失(被 B 端忽略)。
情况四: 假设两处 serialVersionUID 一致,如果 B 端增加一个字段,A 端不变,会是什么情况呢?
序列化,反序列化正常,B 端新增加的 int 字段被赋予了默认值 0。