Flink学习——处理不同数据源的流数据,存入不同的Sink端
目录
一、单机版安装
二、IDEA操作Flink
(一)添加依赖
(二)数据源——Source
1.加载元素数据
2.加载集合数据
3.加载文件目录
4.加载端口
5.加载kafka的topic——重要&常用
6.加载自定义数据源
(三)输出端——Sink
1.读取文件中的数据,处理后输出到另一个文件
2.Source——文件&Sink——Mysql
3.读取kafka的数据,处理后传入mysql中
4.加载kafka中topic的数据,处理后传入另一个topic
5.加载kafka中topic的数据,处理后传入HBase中
6. 加载kafka中topic的数据,处理后传入redis中
一、单机版安装
Flink单机版的安装只需要把压缩包解压即可。
[root@ant168 install]# ls
flink-1.13.2-bin-scala_2.12.tgz mongodb-linux-x86_64-4.0.10.tgz
kafka_2.12-2.8.0.tgz zookeeper-3.4.5-cdh5.14.2.tar.gz
[root@ant168 install]# tar -zxf /opt/install/flink-1.13.2-bin-scala_2.12.tgz -C /opt/soft/
# 开启flink客户端
[root@ant168 flink-1.13.2]# ./bin/start-cluster.sh
[root@ant168 flink-1.13.2]# jps
9050 Jps
1628 StandaloneSessionClusterEntrypoint
1903 TaskManagerRunner
WebUI:localhost:8081
二、IDEA操作Flink
(一)添加依赖
创建maven项目,quickstart
UTF-8
1.8
1.8
1.13.2
junit
junit
4.11
test
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_2.12
${flink.version}
org.apache.flink
flink-clients_2.12
${flink.version}
org.apache.commons
commons-compress
1.21
org.apache.flink
flink-connector-kafka_2.12
${flink.version}
org.apache.flink
flink-statebackend-rocksdb_2.12
${flink.version}
org.apache.flink
flink-table-planner_2.12
${flink.version}
org.apache.flink
flink-table-planner-blink_2.12
${flink.version}
org.apache.flink
flink-csv
${flink.version}
mysql
mysql-connector-java
8.0.29
org.apache.flink
flink-scala_2.12
${flink.version}
org.apache.flink
flink-streaming-scala_2.12
${flink.version}
org.apache.hadoop
hadoop-common
3.1.3
org.apache.hadoop
hadoop-hdfs
3.1.3
org.apache.flink
flink-connector-kafka_2.12
${flink.version}
org.apache.hbase
hbase-client
2.3.5
org.apache.hbase
hbase-server
2.3.5
(二)数据源——Source
1.加载元素数据
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object SourceTest {
def main(args: Array[String]): Unit = {
// TODO 1.创建环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) // 设置并行度
// TODO 2.添加数据源
// TODO 加载元素
val stream1: DataStream[Any] = env.fromElements(1, 2, 3, 4, 5, "hello")
// TODO 3.输出
stream1.print()
env.execute("sourcetest")
}
}
运行结果:
1
2
3
4
5
hello2.加载集合数据
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
// 定义一个样例类——温度传感器
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object SourceTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val dataList = List(
SensorReading("sensor_1", 1684201947, 36.8),
SensorReading("sensor_2", 1684202000, 35.7),
SensorReading("sensor_3", 1684202064, 36.3),
SensorReading("sensor_4", 1684202064, 35.8)
)
val stream1: DataStream[SensorReading] = env.fromCollection(dataList)
stream1.print()
env.execute("sourcetest")
}
}
运行结果:
SensorReading(sensor_1,1684201947,36.8)
SensorReading(sensor_2,1684202000,35.7)
SensorReading(sensor_3,1684202064,36.3)
SensorReading(sensor_4,1684202064,35.8)3.加载文件目录
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object SourceTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val stream1: DataStream[String] = env.readTextFile(path)
stream1.print()
env.execute("sourcetest")
}
}
运行结果:
sensor_1,1684201947,36.8
sensor_7,1684202000,17.7
sensor_4,1684202064,20.3
sensor_2,1684202064,35.84.加载端口
虚拟机要下载nc命令,已经下载的可以忽略
yum -y install ncimport org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object SourceTest {
def main(args: Array[String]): Unit = {
// TODO 1.创建环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream1: DataStream[String] = env.socketTextStream("ant168", 7777)
stream1.print()
env.execute("sourcetest")
}
}5.加载kafka的topic——重要&常用
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerConfig
import java.util.Properties
object SourceTest {
def main(args: Array[String]): Unit = {
// TODO 1.创建环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ant168:9092")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "sensorgroup1")
val stream1: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
// 注意:重新启动就不会读取topic之前的数据
stream1.print()
env.execute("sourcetest")
}
}
运行结果:
hello
world# 1.开启zookeeper和kafka
zkServer.sh status
nohup kafka-server-start.sh /opt/soft/kafka212/config/server.properties &
# 2.创建topic
kafka-topics.sh --create --zookeeper ant168:2181 --topic sensor --partitions 1 --replication-factor 1
# 3.开始生产消息
kafka-console-producer.sh --topic sensor --broker-list ant168:9092
>hello
>world6.加载自定义数据源
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import scala.util.Random
// 定义一个样例类——温度传感器
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object SourceTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// TODO 读取自定义数据源
val stream1: DataStream[SensorReading] = env.addSource(new MySensorSource)
// TODO 3.输出
stream1.print()
env.execute("sourcetest")
}
}
// 自定义数据源
class MySensorSource() extends SourceFunction[SensorReading] {
override def run(sourceContext: SourceFunction.SourceContext[SensorReading]): Unit = {
val random = new Random()
while (true) {
val i: Int = random.nextInt()
sourceContext.collect(SensorReading("生成: " + i, 1, 1))
}
Thread.sleep(500)
}
override def cancel(): Unit = {
}
}
运行结果:
SensorReading(生成: -439723144,1,1.0)
SensorReading(生成: -937590179,1,1.0)
SensorReading(生成: -40987764,1,1.0)
SensorReading(生成: 525868361,1,1.0)
SensorReading(生成: -840926328,1,1.0)
SensorReading(生成: -998392768,1,1.0)
SensorReading(生成: -1308765349,1,1.0)
SensorReading(生成: -806454922,1,1.0)(三)输出端——Sink
1.读取文件中的数据,处理后输出到另一个文件
import source.SensorReading
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object SinkTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val stream1: DataStream[String] = env.readTextFile(path)
val dataStream: DataStream[SensorReading] = stream1.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// dataStream.print()
// writeAsCsv方法已过时
// dataStream.writeAsCsv("D:\\javaseprojects\\flinkstu\\resources\\out.txt")
dataStream.addSink(
StreamingFileSink.forRowFormat(
new Path("D:\\javaseprojects\\flinkstu\\resources\\out1.txt"),
new SimpleStringEncoder[SensorReading]()
).build()
)
env.execute("sinktest")
}
}
out1.txt文件内容:
SensorReading(sensor_1,1684201947,36.8)
SensorReading(sensor_7,1684202000,17.7)
SensorReading(sensor_4,1684202064,20.3)
SensorReading(sensor_2,1684202064,35.8)
2.Source——文件&Sink——Mysql
import source.SensorReading
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import java.sql.{Connection, DriverManager, PreparedStatement}
/**
* 将flink处理后的数据传入mysql中
*/
object JdbcSinkTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// TODO 从文件中读取数据存入mysql中
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val stream1: DataStream[String] = env.readTextFile(path)
// TODO 处理文件数据
val dataStream: DataStream[SensorReading] = stream1.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
dataStream.addSink(new MyJdbcSink)
env.execute("jdbc sink test")
}
}
class MyJdbcSink extends RichSinkFunction[SensorReading] {
var connection: Connection = _
var insertState: PreparedStatement = _
var updateState: PreparedStatement = _
override def open(parameters: Configuration): Unit = {
connection = DriverManager.getConnection("jdbc:mysql://192.168.180.141:3306/kb21?useSSL=false", "root", "root")
insertState = connection.prepareStatement("insert into sensor_temp(id,temp) value (?,?)")
updateState = connection.prepareStatement("update sensor_temp set temp=? where id=?")
}
override def invoke(value: SensorReading, context: SinkFunction.Context): Unit = {
updateState.setDouble(1, value.temperature)
updateState.setString(2, value.id)
val i: Int = updateState.executeUpdate()
println(i)
// 当原表中没有数据时,就不能执行update语句,所以影响的行数==0,而是执行insert语句
// 反之,当原表中有数据,就执行update语句,影响的行数为1
if (i == 0) {
insertState.setString(1, value.id)
insertState.setDouble(2, value.temperature)
insertState.execute()
}
}
override def close(): Unit = {
insertState.close()
updateState.close()
connection.close()
}
}数据源:
D:\javaseprojects\flinkstu\resources\sensor.txt
sensor_1,1684201947,36.8
sensor_2,1684202000,17.7
sensor_1,1684202064,20.3
sensor_2,1684202068,35.8DataGrip操作:
drop table sensor_temp;
create table sensor_temp(
id varchar(32),
temp double
);
select * from sensor_temp;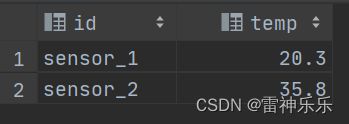
每次只获取最新的数据。
3.读取kafka的数据,处理后传入mysql中
import source.SensorReading
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerConfig
import java.sql.{Connection, DriverManager, PreparedStatement}
import java.util.Properties
/**
* 将flink处理kafka后的数据传入mysql中
*/
object KafkaToMysqlSinkTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) // 设置并行度
// TODO 从kafka中读取数据
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ant168:9092")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "sensorgroup1")
// TODO 订阅topic
val stream1: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
// TODO 处理topic数据
val dataStream: DataStream[SensorReading] = stream1.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO 处理后的topic数据存入mysql中
dataStream.addSink(new MysqlSink)
env.execute("kafka sink test")
}
}
class MysqlSink extends RichSinkFunction[SensorReading] {
var connection: Connection = _
var insertState: PreparedStatement = _
var updateState: PreparedStatement = _
override def open(parameters: Configuration): Unit = {
connection = DriverManager.getConnection("jdbc:mysql://192.168.180.141:3306/kb21?useSSL=false", "root", "root")
insertState = connection.prepareStatement("insert into sensor_temp(id,temp) value (?,?)")
updateState = connection.prepareStatement("update sensor_temp set temp=? where id=?")
}
override def invoke(value: SensorReading, context: SinkFunction.Context): Unit = {
updateState.setDouble(1, value.temperature)
updateState.setString(2, value.id)
val i: Int = updateState.executeUpdate()
println(i)
// 当原表中没有数据时,就不能执行update语句,所以影响的行数==0,而是执行insert语句
// 反之,当原表中有数据,就执行update语句,影响的行数为1
if (i == 0) {
insertState.setString(1, value.id)
insertState.setDouble(2, value.temperature)
insertState.execute()
}
}
override def close(): Unit = {
insertState.close()
updateState.close()
connection.close()
}
}kafka生产消息:
[root@ant168 opt]# kafka-console-producer.sh --topic sensor --broker-list ant168:9092
>sensor_1,1684201947,36.8
>sensor_1,1684201947,36.10
>sensor_2,1684202068,35.8
Mysql数据库:

4.加载kafka中topic的数据,处理后传入另一个topic
import source.SensorReading
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer}
import org.apache.kafka.clients.consumer.ConsumerConfig
import java.util.Properties
/**
* 将flink处理kafka后的数据传入kafka中
*/
object KafkaToKafkaSinkTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) // 设置并行度
// TODO 从kafka中读取数据
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ant168:9092")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "sensorgroup1")
// TODO 订阅topic
val stream1: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
// TODO 处理topic数据
val dataStream: DataStream[String] = stream1.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble).toString()
})
// TODO 处理后的topic数据存入另一个topic中
dataStream.addSink(
new FlinkKafkaProducer[String]("ant168:9092","sensorsinkout",new SimpleStringSchema())
)
env.execute("kafka sink test")
}
}
注意:这里默认是latest提交方式,如果程序中断,kafka生产者此时传入数据,重新开启该程序,后面传入的数据也会被消费。
5.加载kafka中topic的数据,处理后传入HBase中
HBase中创建表和列簇:
hbase(main):002:0> create_namespace 'ha'
hbase(main):004:0> create 'ha:test','sensor'
hbase(main):006:0> list_namespace_tables 'ha'Flink代码:
import source.SensorReading
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.hadoop.conf
import org.apache.hadoop.hbase.client.{BufferedMutator, BufferedMutatorParams, ConnectionFactory, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, HConstants, TableName, client}
import org.apache.kafka.clients.consumer.ConsumerConfig
import java.util.Properties
/**
* 将数据流处理后写入到HBase中
*/
object KafkaToHBaseSinkTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) // 设置并行度
// TODO 从kafka中读取数据
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ant168:9092")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "sensorgroup1")
// TODO 订阅topic
val stream1: DataStream[String] = env.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
// TODO 处理topic数据
val dataStream: DataStream[SensorReading] = stream1.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO 处理后的topic数据存入HBase中
dataStream.addSink(new MyHBaseSink)
env.execute("HBase sink test")
}
}
class MyHBaseSink extends RichSinkFunction[SensorReading] {
var connection: client.Connection = _
var mutator: BufferedMutator = _
override def open(parameters: Configuration): Unit = {
val configuration: conf.Configuration = HBaseConfiguration.create()
configuration.set(HConstants.HBASE_DIR, "hdfs://lxm147:9000/hbase")
configuration.set(HConstants.ZOOKEEPER_QUORUM, "lxm147")
configuration.set(HConstants.CLIENT_PORT_STR, "2181")
connection = ConnectionFactory.createConnection(configuration)
val params = new BufferedMutatorParams(TableName.valueOf("ha:test"))
params.writeBufferSize(10 * 1024 * 1024) // 达到缓存进行写入
params.setWriteBufferPeriodicFlushTimeoutMs(5 * 1000L) // 达不到缓存但是达到时间也进行写入
mutator = connection.getBufferedMutator(params)
}
override def invoke(value: SensorReading, context: SinkFunction.Context): Unit = {
println(connection)
println(mutator)
println(value)
val put = new Put(Bytes.toBytes(value.id + value.temperature + value.timestamp))
put.addColumn("sensor".getBytes(), "id".getBytes(), value.id.getBytes())
put.addColumn("sensor".getBytes(), "timestamp".getBytes(), value.timestamp.toString.getBytes)
put.addColumn("sensor".getBytes(), "temperature".getBytes(), value.temperature.toString.getBytes())
mutator.mutate(put)
mutator.flush()
}
override def close(): Unit = {
connection.close()
}
}kafka中传入数据:
[root@ant168 flink-1.13.2]# kafka-console-producer.sh --topic sensor --broker-list ant168:9092
>sensor_4 , 1684202064, 27.3
>sensor_2,1684202068, 35.8
HBase中查看表数据:
hbase(main):010:0> scan 'ha:test'
ROW COLUMN+CELL
sensor_235.81684202068 column=sensor:id, timestamp=2023-05-17T09:44:41.123, value=sensor_2
sensor_235.81684202068 column=sensor:temperature, timestamp=2023-05-17T09:44:41.123, value=35.8
sensor_235.81684202068 column=sensor:timestamp, timestamp=2023-05-17T09:44:41.123, value=1684202068
sensor_427.31684202064 column=sensor:id, timestamp=2023-05-17T09:21:41.475, value=sensor_4
sensor_427.31684202064 column=sensor:temperature, timestamp=2023-05-17T09:21:41.475, value=27.3
sensor_427.31684202064 column=sensor:timestamp, timestamp=2023-05-17T09:21:41.475, value=16842020646. 加载kafka中topic的数据,处理后传入redis中
org.apache.bahir
flink-connector-redis_2.12
1.1.0
package nj.zb.kb21.sink
import nj.zb.kb21.source.SensorReading
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
/**
* 将flink处理后的数据传入redis中
*/
object RedisSinkTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) // 设置并行度
val inputStream: DataStream[String] = env.socketTextStream("192.168.180.141", 7777)
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
val redisConf: FlinkJedisPoolConfig = new FlinkJedisPoolConfig.Builder()
.setHost("192.168.180.141")
.setPort(6379)
.setTimeout(30000)
.build()
dataStream.addSink(new RedisSink[SensorReading](redisConf,new MyRedisMapper))
env.execute("redis sink test")
}
}
class MyRedisMapper extends RedisMapper[SensorReading] {
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET, "sensor")
}
override def getKeyFromData(data: SensorReading): String = {
data.id
}
override def getValueFromData(data: SensorReading): String = {
data.timestamp+":"+data.temperature
}
}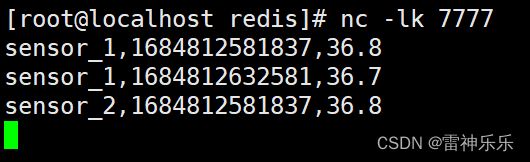
Redis Desktop
