基于YOLOv8的行人目标检测项目(超级详细)
1.下载数据集
在这里我直接用的是WiderPerson数据集,这个数据集可以从以下的官网地址获取:
http://www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson/
在这里我也准备了网盘版本以供大家获取:
链接:https://pan.baidu.com/s/18_fKMsRSs0uOGdWR6BaxtA
提取码:wv15
下载完毕之后解压,我这里选择的解压目录为F:\dataset,注意不要以中文路径作为解压路径,不然有些代码运行时会报错,整体的文件结构是这样的:
打开之后你会发现Images文件夹下有13382张图片,而对应的Annotations标注文件只有9000份,在这里先不用管,到后面我会通过程序删除多余的照片。解压目录下的其他的txt文件是数据集的划分情况,知道就好,不用做出处理。
2.将数据集转化为YOLO格式
由于这里对应的000040文件是问题文件,需要将annotations、images、train.txt中对应的文件删除掉,这是很重要的,一定不要忘了。
2.1删除多余的数据文件并划分数据集(想完整图片训练可跳过)
这里我只是简单地去跑一个检测项目,快点跑完知道如何运行就可以了,所以我这里Images中只保留了2000张图片(上面的网盘链接中是完整的数据)。如果你想利用完整数据集训练,那么可以跳过这一步骤。
具体的做法是将Annotations文件下前2000个文件保存下来,其他的删除即可。至于Images文件下的图片我们不用管它。但是现在原本数据集划分的txt文件用不上了,把test、train以及val.txt删除即可。
然后我们在F:\datase\WiderPerson目录下新建一个transform.py,将下列代码复制进去运行即可:
import os
import random
trainval_percent = 0.9
train_percent = 0.9
txtfilepath = 'F:/dataset/WiderPerson/Annotations' # txt标签文件路径
txtsavepath = 'F:/dataset/WiderPerson' # 数据划分txt文件路径
total_xml = os.listdir(txtfilepath)
num = len(total_xml)
list =[f for f in os.listdir(txtfilepath) if f.endswith(".txt")]
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('trainval.txt', 'w')
ftest = open('test.txt', 'w')
ftrain = open('train.txt', 'w')
fval = open('val.txt', 'w')
for i in list:
name = i.split(".")[0] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
如果你的路径和我的完全一样直接运行就可以了,我这里是按照9:1的比例划分数据集的,如果想要其他的比例按照注释修改即可。
运行之后返回F:\datase\WiderPerson目录下,文件结构是这样的:
2.2转换格式以及选取类别
由于WiderPerson数据集内包含五种类别,可取自己所需类别进行转换,此处只留下第一种类别,在F:\datase\WiderPerson目录下新建一个transform1.py,将下列代码复制进去并且运行:
import os
from PIL import Image
import shutil
# coding=utf-8
def check_charset(file_path):
import chardet
with open(file_path, "rb") as f:
data = f.read(4)
charset = chardet.detect(data)['encoding']
return charset
def convert(size, box0, box1, box2, box3):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box0 + box2) / 2 * dw
y = (box1 + box3) / 2 * dh
w = (box2 - box0) * dw
h = (box3 - box1) * dh
return (x, y, w, h)
if __name__ == '__main__':
outpath_txt = 'F:/dataset/WiderPerson/WiderPerson/label/val'
# 注意:这里F:/dataset/WiderPerson是你存储文件侧地方,可以替换,后面的不要动
outpath_jpg = 'F:/dataset/WiderPerson/WiderPerson/images/val'
# 注意:这里F:/dataset/WiderPerson是你存储文件侧地方,可以替换,后面的不要动
os.makedirs(outpath_txt)
os.makedirs(outpath_jpg)
path = 'F:/dataset/WiderPerson/val.txt'
with open(path, 'r') as f:
img_ids = [x for x in f.read().splitlines()]
for img_id in img_ids: # '000040'
img_path = 'F:/dataset/WiderPerson/Images/' + img_id + '.jpg'
with Image.open(img_path) as Img:
img_size = Img.size
ans = ''
label_path = img_path.replace('Images', 'Annotations') + '.txt'
outpath = outpath_txt + "/" + img_id + '.txt'
with open(label_path, encoding=check_charset(label_path)) as file:
line = file.readline()
count = int(line.split('\n')[0]) # 里面行人个数
line = file.readline()
while line:
cls = int(line.split(' ')[0])
if cls == 1:
# if cls == 1 or cls == 3:
xmin = float(line.split(' ')[1])
ymin = float(line.split(' ')[2])
xmax = float(line.split(' ')[3])
ymax = float(line.split(' ')[4].split('\n')[0])
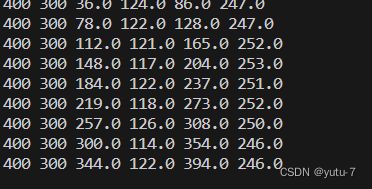
print(img_size[0], img_size[1], xmin, ymin, xmax, ymax)
bb = convert(img_size, xmin, ymin, xmax, ymax)
ans = ans + '1' + ' ' + ' '.join(str(a) for a in bb) + '\n'
line = file.readline()
with open(outpath, 'w') as outfile:
outfile.write(ans)
# 想保留原文件用copy
# shutil.copy(img_path, outpath_o + '\\' + img_id + '.jpg')
# 直接移动用这个
shutil.move(img_path, outpath_jpg + '/' + img_id + '.jpg')
然后将代码中的val换成train再运行一下,等待结束即可。
处理完毕后,返回到F:/dataset/WiderPerson/WiderPerson目录下,发现images以及label两个文件夹:
这两个文件夹打开都有train和val两个文件夹,装着各自对应的图片以及标签信息。
接下来需要进行归类处理,在F:\datase\WiderPerson目录下新建一个transform2.py,将下列代码复制进去并且运行:
import os
# 路径
otxt_path = "F:/dataset/WiderPerson/WiderPerson/label/val"
ntxt_path = "F:/dataset/WiderPerson/WiderPerson/labels/val"
os.makedirs(ntxt_path)
filer = []
for root, dirs, files in os.walk(otxt_path):
for i in files:
otxt = os.path.join(otxt_path, i)
ntxt = os.path.join(ntxt_path, i)
f = open(otxt, 'r', encoding='utf-8')
for line in f.readlines():
if line == '\n':
continue
cls = line.split(" ")
# cls = '%s'%(int(cls[0])-1) + " " + cls[1]+ " " + cls[2]+ " " + cls[3]+ " " + cls[4]
cls = '0' + " " + cls[1]+ " " + cls[2]+ " " + cls[3]+ " " + cls[4]
filer.append(cls)
with open(ntxt,"a") as f:
for i in filer:
f.write(i)
filer = []
将val换成train再运行一遍,最后返回F:/dataset/WiderPerson/WiderPerson目录下得到:

归类完成之后就可以将label文件夹删除了。
3.生成yolo格式的train、val.txt 里面存储图片路径
在F:\datase\WiderPerson目录下新建一个transform2.py,将下列代码复制进去并且运行:
import os
sets = ['train', 'val']
labels_path = "F:/dataset/WiderPerson/WiderPerson/labels"
txt_path = "F:/dataset/WiderPerson/WiderPerson/labels"
for image_set in sets:
image_i = []
for image_ids in os.listdir(labels_path + '/%s' % (image_set)):
_name = image_ids.split(".")[0]
image_i.append(_name)
list_file = open(txt_path + '/%s.txt' % (image_set), 'a')
for c_id in image_i:
print(c_id)
list_file.write('E:/yolov8Project/ultralytics/dataset/images' + '/%s/%s.jpg\n' % (image_set,c_id))
# 注意,这里我的路径E:\yolov8Project\ultralytics\dataset\images是指代的yolov8项目中图片的目录位置
list_file.close()
这里有一点需要注意,就是我们这里所做的工作都是为转化为yolo格式而准备的,最终需要将转化好的数据集放到yolo文件里面,所以这里对应的倒数第三行的代码中的路径应该是yolo文件下放置数据集的文件路径。
最终返回到F:/dataset/WiderPerson/WiderPerson/labels目录下对应的文件格式为:

并且train.txt文件记录的为yolo文件中训练图片的路径:
将F:/dataset/WiderPerson/WiderPerson文件夹命名为datasets,放置在yolov8项目中。
4.引进YOLOv8项目
4.1项目的下载以及环境配置
项目的开源地址为:https://github.com/ultralytics/ultralytics
不知道如何引进项目的可以翻看我以前的博客:
https://blog.csdn.net/m0_73414212/article/details/129724667?ydreferer=aHR0cHM6Ly9tcC5jc2RuLm5ldC9tcF9ibG9nL21hbmFnZS9hcnRpY2xlP3NwbT0xMDEwLjIxMzUuMzAwMS41NDE2
整体来说YOLOv8的环境配置方面不需要花费什么心思,根据requirements文件去配置就好了,值得注意的是这里选用的 Python>=3.7并且 PyTorch>=1.7。
官方文件中说只需要安装ultralytics文件就行,通过命令行窗口激活虚拟环境,输入以下命令即可安装:
pip install ultralytics
我这里的yolov8项目是放在E:/yolov8Project下的,和上面的图片路径是相对应的。如果不知道怎么配置环境也可以看我以前的博客:
https://blog.csdn.net/m0_73414212/article/details/129770438
4.2模型的训练
训练之前还需要配置一下yaml文件,进入ultralytics\datasets,新建person.yaml文件,注意下面的路径需要使用绝对路径:
train: E:/yolov8Project/ultralytics/dataset/labels/train.txt
val: E:/yolov8Project/ultralytics/dataset/labels/val.txt
test: E:/yolov8Project/ultralytics/dataset/labels/val.txt
# number of classes
nc: 1
# class names
names: ['people']
这样的话数据集的准备工作就完成了,接下来就可以进行模型的训练以及预测等环节了。
你可以选择预训练的方式或者是全新的模型训练方式,一般建议采用预训练模型进行训练,这样的话可以更快达到最优权重,yolov8的训练采用命令行的模型(当然也可以使用api调用的方式,后面会介绍),下面是yolov8官方给定的训练/预测/验证/导出方式:
yolo task=detect mode=train model=yolov8n.pt args...
classify predict yolov8n-cls.yaml args...
segment val yolov8n-seg.yaml args...
export yolov8n.pt format=onnx args...
下面对一些重点参数进行讲解:
- model:pt模型路径或者yaml模型配置文件路径。这次的v8稍有不同,这个model参数可以是pt也可以是yaml。
- pt:相当于使用预训练权重进行训练,比如选择为yolov8n.pt,就是训练一个yolov8n模型,并且训练前导入这个pt的权重。
- yaml:相当于直接初始化一个模型进行训练,比如选择为yolov8n.yaml,就是训练一个yolov8n模型,权重是随机初始化。
- data:数据配置文件的路径,也就是第三点中的data.yaml。
- epochs:训练次数。
- patience:在精度持续一定epochs没有提升时,过早停止训练。也就是早停机制。
- batch:batch size大小。
- imgsz:输入图像大小。
- save:是否保存模型。
- cache:是否采用ram进行数据载入,设置True会加快训练速度,但是这个参数非常吃内存,一般服务器才会设置。
- device:所选择的设备训练,如果单显卡训练的话填0就行。
那么了解完之后就可以利用命令行进行训练了,打开IDE的终端,进入虚拟环境并且定位到yolov8的文件路径下,输入以下命令:
yolo task=detect mode=train model=yolov8n.pt data=dataset/person.yaml batch=32 epochs=100 imgsz=640 workers=16 device=0
当然你也可以建立一个简单的程序去运行,比如返回到E:\yolov8Project\ultralytics目录下新建一个train.py,输入以下内容即可:
from ultralytics import YOLO
# 加载模型
# model = YOLO("yolov8n.yaml") # 从头开始构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(推荐用于训练)
if __name__ == '__main__':
# Use the model
results = model.train(data="ultralytics/datasets/people.yaml", epochs=100, batch=32,device=0) # 训练模型
如果在训练过程中出现:
OSError: [WinError 1455] 页面文件太小,无法完成操作。
或者:
RuntimeError: CUDA out of memory.
可以将上面的batch改小一点,但是记住修改后的数值最好是2的次方数。如果还不行的话可以修改虚拟内存或者结束显存任务等方式去弄,具体方法参见我之前的博客,弄好之后,静待训练即可。
4.3模型的验证以及预测
使用如下命令,即可完成对验证数据的评估:
yolo task=detect mode=val model=runs/detect/train0016/weights/best.pt data=ultralytics/datasets/people.yaml device=0

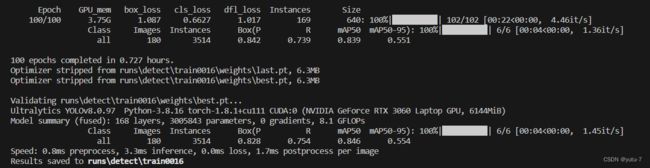
在上面可以看到精确率以及召回率等信息。
使用如下命令,即可完成对新数据的预测,source需要指定为自己的图像路径,我这里是将图片放在data/images目录下:
yolo task=detect mode=predict model=runs/detect/train0016/weights/best.pt source=data/images device=0

然后它这里显示结果保存在了runs\detect\predict文件夹下。

打开即可显示结果。
最后如果你想导出最后的模型的话,可以使用命令:
yolo task=detect mode=export model=runs/detect/train0016/weights/best.pt

显示导出成功。