Linux内核及可加载内核模块编程
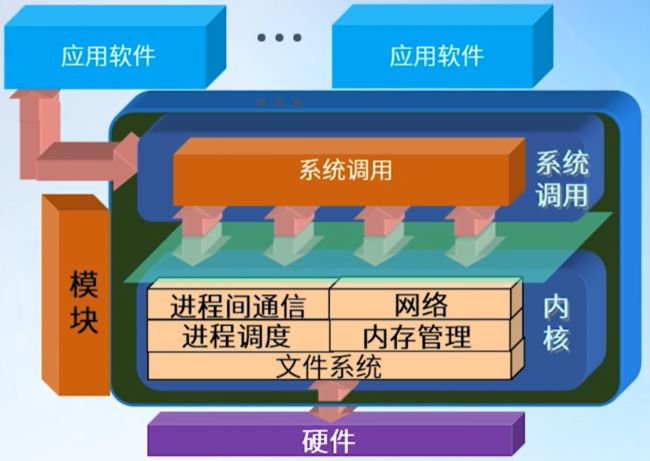
图1 Linux系统整体结构
图2 Linux的源代码结构
下面显示一段内核模块代码案例:
#include
#include
/*
模块的初始化函数lkp_ init()
_init是用于初始化的修饰符
*/
static int __init lkp_init(void)
{
printk( "<1>Hello ,world!from the kernel space...\n" );
return 0;
}
/*
模块的退出和清理函数1kp_ exit()
*/
static void __exit lkp_exit(void)
{
printk( "<1>Goodbye ,world!leaving kernel space...\n" );
}
module_init(lkp_init);
module_exit(lkp_exit);
/*
模块的许可证声明GPL
*/
MODULE_ LICENSE("GPL");
在此使用了printk0函数,该函数是由内核定义的,功能和C库中的printf()类似,它
把要打印的日志输出到终端或系统日志。字符串中的<1>是输出的级别,表示立即在终端输出。
任何模块都要包含的三个头文件:
#include
#include
#incldue
说明: module.h头文件包含了对模块的版本控制; kernel.h包含 了常用的内核函数; init.h包含 了宏__init和__exit,宏__init告诉编译程序相关的函数和变量仅用于初始化,编译程序将标有__init的所有代码存储到特殊的内存段中,初始化结束就释放这段内存。
内核模块的Makefile文件
obj-m:=module_example.o #产生module_example模块的目标文件
CURRENT_PATH :=$(shell pwd) #模块所在的当前路径
LINUX_KERNEL :=$(shell uname -r) #linux内核源代码的当前版本
LINUX_KERNEL_PATH := /usr/src/linux-headers-S(LINUX_KERNEL) #linux内核源代码的绝对路径
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules #编译模快
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean #清理模块
第一行中的obj-m :=这个赋值语句的含义是说明要使用目标文件module_example.o建立一个模块,最后生成的模块名为module_ example.ko。.0文件是经过编译和汇编,而没有经过链接的中间文件。
注: makefile文件中, 若某一 行是命令,则它必须以一个Tab键开头。
模块插入命令:
$insmod module_ example.ko
模块删除命令:
$rmmod module_ example
查看模块信息的命令:
$dmesgLinux内核模块与C应用的对比

2 操作系统接口
2.1 OS是如何对系统调用进行处理的?
系统调用发生在用户态,当调用了系统调用后就陷入到内核态。如何陷入?比如,在比如DOS的软中断int 21H;Linux下的int 0x80;处理器不同指令不同,我们统一把他叫做陷入指令。OS比较理智,它会在陷入之前先把自己当时执行的CPU现场保存起来,然后进行压栈,给自己留下退路;接下来就是让内核执行一段程序,这段程序叫系统调用服务例程,比如执行sub1在显示器上输出;内核把这种脏活累活于完以后,它会理智的撤出(就是把堆栈中东西弹出来就行)。

2.2 系统调用与一般过程调用有何不同?
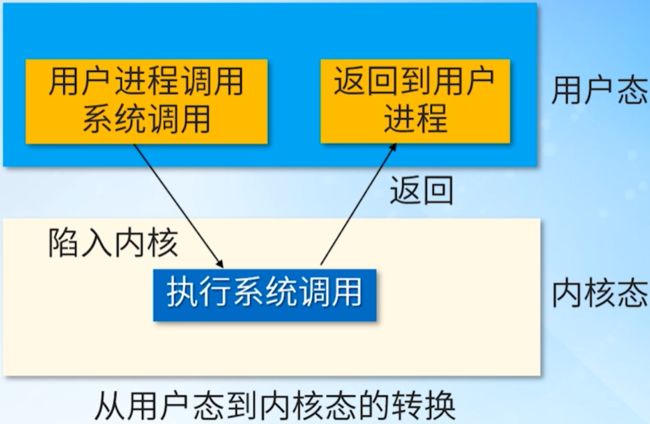
系统调用要涉及到CPU状态的转换,首先从用户态陷入到内核态,在内核执行系统调用服务例程,处理结束后,返回用户态;一般的程序它调用的时候在用户态也可能在内核态,只是一个函数调用另外一个函数而已,不存在CPU状态的转换 。
3 Linux系统调用
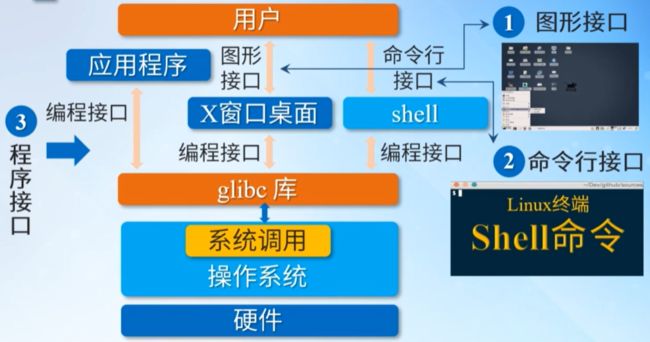
3.1 Linux各种接口

不管是图形接口还是命令行接口,都统称为用户接回,因为图形界面只是一种与用户更方便打交道的方式,其本质还是一堆实用程序的集合。而库函数,如printf,open,read等等,这些库函数实际上很多也只是穿了件衣服,尤其是与硬件或者系统打交道的话,并不是库函数干的,实际上是操作系统干的,这就是系统调用接口。
3.2 系统调用与API
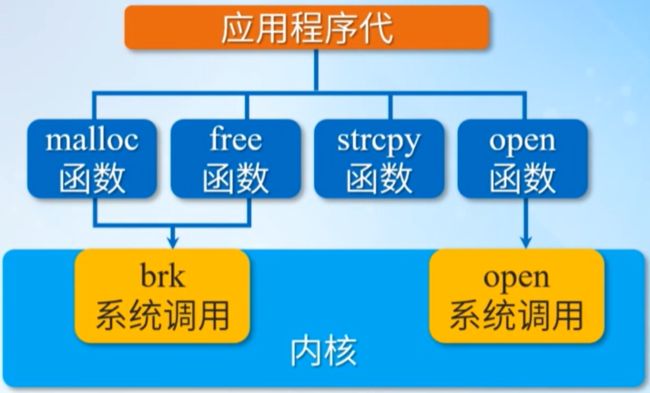
系统调用是与具体操作系统相关的,而AP1是遵循POSIX标准的,Linux的ibc库的函数malloc和free都叫做API,其实现都调用了brk系统调用;另一方面,一个API实现可能会调用好几个系统调用,而有些AP甚至不需要任何系统调用,比如说strepy函数,因为它们不需要内核提供的服务
系统调用-内核的出口
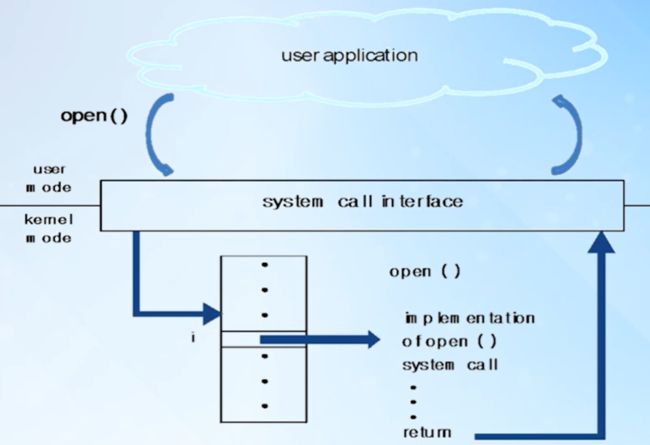
系统调用,顾名思义说的是操作系统提供给用户程序调用的一组特殊接口,从逻辑上来说,系统调用可被看成是一个内核与用户空间进行交互的接口,它好比一个中间人,把 用户进程请求传达给内核,待内核把请求处理完毕后,再将处理结果送回给用户空间。
如图为Linux系统中,各个子系统相关的工具集,在这里可以通过strace命令查看个应用程序所调用的系统调用,strace被称为神器,它是Linux环境下的一款程序调试工具,它可以统计每一个系统调用所执行的时间、被调用的次数和出错的次数,例如“strace -c 可执行文件名”,它把执行的时间以微妙为单位的每个系统调用平均耗时、调用次数、错误次数以及系统调用名称显示在表格中。

从用户态函数到系统调用
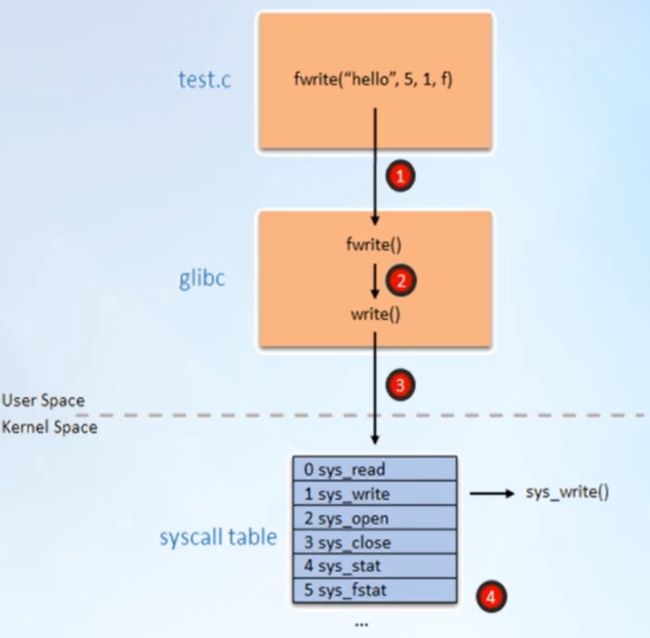
比如在程序中调用fwrite函数,图中①,而fwrite函数在glibc库中调用系统调用write()(图中②),然后从用户态陷入内核态(图中③),查找系统调用表syscall table ( 图中④),在内中中对应的系统调用服务例程为sys_write,然后在内核执行该例程。
3.3 系统调用基本概念
(1)系统调用号
①用来唯一的标识每个系统;
②作为系统调用表的下标,当用户空间的进程执行一个系统调用时,该系统调用号就被用来指明到底要执行哪个进程。
(2)系统调用表
用来把系统调用号和相应的服务例程关联起来。该表存放在sys call table数组中:
ENTRY(sys_call_table)
.long sys_restart_syscall /* 0- old "setup()"system call, used for restarting */
.long sys_exit
.long sys_fork
.long sys_read
.long sys_write
.long sys_open /*5*/
........
所有的系统调用在内核中都存放在一张表中,叫sys_call_table,在内核代码中实际上很简单是汇编语言,通过一个长整型指出每个系统调用的入口地址,如下表列出了部分系统调用:
这张表不是系统调用内核中的表示,而是为方便用户查看而建立的,第一列是系统调用号、第三列是系统调用名、第三列是系统调用在内核实现中所在文件、后面见列是传递给系统调用的参数。这张表主要是让用户理解系统调用号、系统调用表以及参数之间的相互关联。
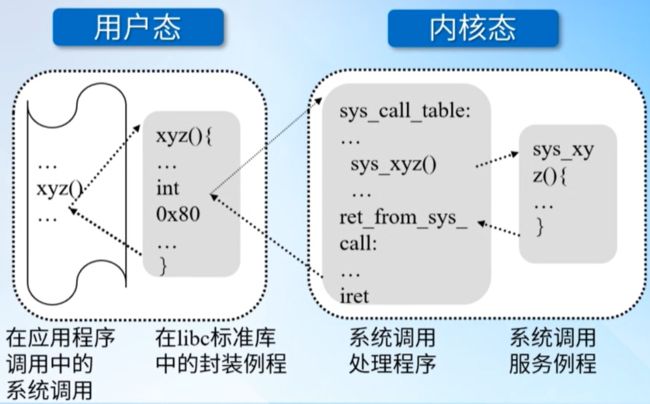
3.3.1 调用一个系统调用的过程
当用户态的进程调用一个系统调用时,首先调用ibo库中的函数,这个函数必定有一条从用户态转入到内核态的陷入指令,比如 int 0x80,这时就进入Linux内核了,在内核中找到系统调用表的入口地址sys_call_table,然后根据系统调用号在表中进行查找,找到相应的的系统调用服务例程,执行完后,通过返回指令iret,从内核态返回到用户态,这是对系统调用过程的一个简要概述。
3.3.2 系统调用处理过程
如下图所示,就是一个系统调用的处理过程。当用户态的进程调用一个系统调用时,CPU切换到内核态,首先要保护现场,然后根据存放到eax中的系统调用号,并乘以4表示每个表项占4字节,在系统表sys_call_table中找到入口地址,并跳转到相应的服务例程,执行结束后恢复现场,从内核态返回到用户态。
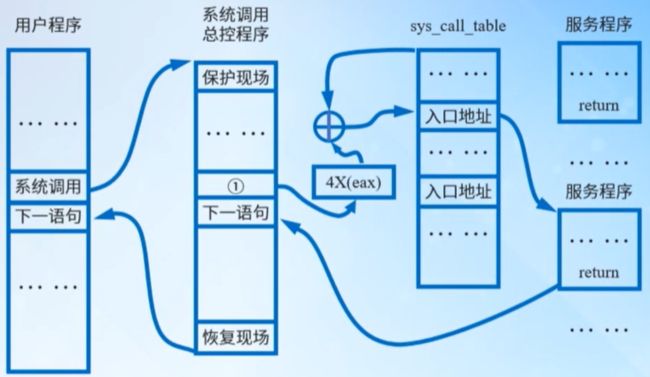
注①:此处语句为: call*SYMBOL_NAME(sys_ call_table)(
3.3.3 从用户态跟踪一个系统调用到内核
下面给出一个具体的fork系统调用的例子:
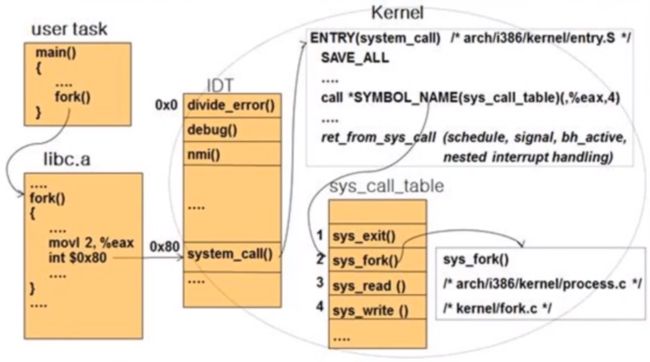
1.从用户程序中调用fork
2.在libc库中把fork对应的系统调用号2放入寄存器eax
3.通过int 0x80陷入内核
4.在中断描述表IDT中查到系统调用的入口0x80
5.进入Linux内核的entry_32(64).S 文件,从系统调用表sys_call_table 中找到sys_fork 的入口
地址
6.执行fork.c中的do_fork 代码
7通过iret返回
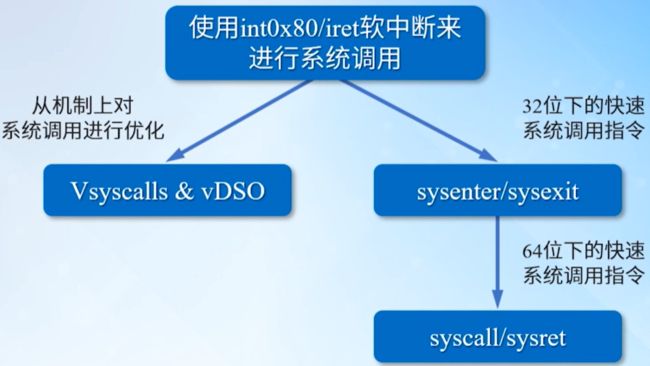
3.4 系统调用机制的优化
在26以前的早期版本中,系统调用的指令都是int 0x80和iret指令,因为系统调用的实现从用户态切换到内核态,执行完系统调用后又从内核态切换回用户态,这样做代价很大,为了加快系统调用的速度,先后引入了两种机制,分别为vSycalls和VDSO,这两种机制都是从机制上对系统调用速度进行的优化,但是使用软中断来进行系统调用,还是需要进行特权级的切换这一根本问题并未得到解决,为了解决这一问题,Intel x86 CPU从Pentfum II之后开始支持快速系统调用指sysenter/sysexit,这两条指令是Intel在32位下提出的,而AMD提syscal/sysret,64位统使用这两条指令了。
3.5 系统调用实例日志收集系统
系统调用是用户程序与系统打交道的入,系统调用的安全直接关系到系统的安全,如果一个用户恶意地不断调用fork将导致系统负载增加,所以如果能收集到是谁调用了一些有危险的系统调用以及系统调用的时间和其他信息,将有助于系统管理员进行事后追踪,从而提高系统的安全性。

上图是系统调用周志收集系统示意图,我们可以看到当用户进程进行系统调用的时候,当执行到do_syscall_64的时候,我们判断是否是我们需要记录的系统调用,如果是则拦截需要记录的系统调用,通过my_audit这一函数将相关信息写入到内核中的buffer里,同时我们编写用户测试程序,在用户测试程序中我们通过我们本次添加的335号系统调用,执行my_sysaudt这一函数,该函数把内核buffer里的信息拿到我们的用户buffer当中,其中my_audti和my_sysaudit,这两个函数是钩子函数,并且在我们的my_audit内核模块当中进行具体的实现-实例操作。
4 进程管理
4.1 Linux中进程状态及转换
操作系统一般具有就绪、运行和阻塞三种状态,这三种状态是任何一个操作系统当中都会存在的,恒到其体的操作系统的时候,就不止这三种了,比如说如图Linux当中睡眠态就有两种,一种是浅度睡眠,就是收到信号就可以唤醒它;另一种是深度睡眠,要调用唤醒函数才能唤醒它。当你调试一个程序的时候,进程就进入暂停状态;当进程退出,资源尚关回收时就进入到僵死状态,那么状态之间的转换所调用的函数是内核函数。
通过top命令我们会看到,在单CPU的机器上,只有一个进程处于R运行状态,一般情况下,进程列表当中的绝大多数进程都处于浅度睡眠TASK_INTERRUPTIBLE状态,也就是S状态;僵死状态Z,就是子进程已经结束,但父进程还没有回收它的资源。
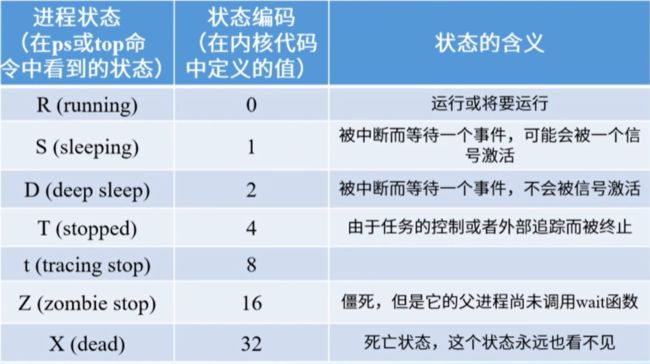
1)Linux内核源代码中进程状态的定义

上图是Linux内核5.3版本中状态的定义,每个状态的值是2的n次方,这种定义方式巧妙之处就在于,通过逻辑与运算,就可以快速的算出一个进程它所处的状态
2)扩展-从进程到云计算中的容器
容器作为目前云技术的核心技术,它与进程到底有多大关系?对于进程来说,它的静态表现就是程序,平时常都安安静静地待在磁盘上,而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现;而容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个边界”;对于Docker等大多数Linux容器来说,Cgroups技术是用来制造约束的主要手段,而Namespace技术,则是用来修改进程视图的主要方法。
4.2 进程控制块及Linux中的task_struct结构
我们说进程是由程序、数据以及进程控制块组成的,进程控制块(Process Control Block ,简称PCB),是管理进程的数据结构,用它来记录进程的外部特征,描述进程的运动行变化全过程。
OS就是靠PCB来管理进程,PCB相当于我们的身份证信息,但比身份证信息更全面,进程在执行过程中的全部信息都记录在其中,进程控制块中的信息一般分为四类:进程标识信息、处理器现场信息、进程调度信息、进程控制信息,其中进程标识信息唯一的标识进程,比如PID叫进程标识符。