nginx(五十三)nginx中使用的PCRE正则
一 pcre 正则语法
说明:
1)从'在nginx中'使用符合'PCRE风格'正则的角度上'学习'
2) 部分'案例'比较冷门,不具有'实际'生产意义PCRE汇总
① 元字符
说明: 通过'\'转义,使一些'字符'具有'特殊'的含义
正则中'需要\转义'的场景:
1) * . ? + $ ^ [] () {} | \ / --> 加\将'元字符'转义为'字面意思'
2) 字面字符 -->加\将'普通字符'转义为'特殊含义'
② 字符组(集)
说明: PCRE也支持'POSIX'风格的字符组
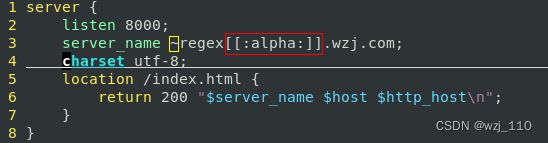
等价: \D、[^0-9]、[[:^digit:]] 三者'等价'
小细节:
1) nginx支持'POSIX'风格的正则"[[::]]"
2) '$server_name'获取的永远是'server_name'指令的'第一个'值![]()
③ 量词
难点: '贪婪'和'非贪婪'

④ 分组和补获
'分组'常见'三种'形式:
1、(pattern) -->'普通分组',捕获的字符串会'被缓存起来'以供后续使用
2、(?pattern) -->'命名分组','可读性'好,相当于创建了一个'新'变量,'推荐'
3、(?:pattern1|pattern2) -->'非补获分组',模式匹配上,但是'没分组',后面'无法引用'
+++++++++++++++++++++++++ "分割线" +++++++++++++++++++++++++
'对()中补获'和'引用的方式':
1、$1,$2,$3,$4,$9,有些地方使用\1,\2,\3,...\9
备注: sed中使用'&'表示所有匹配,perl中则使用'$&'
重点: nginx在'模式'中使用'\1'之类,在后续'其它补获'的地方用类似'${1}'
2、 \g1,\g2,\g3 或 \g{1},\g{2},\g{3}
备注: 其中$1,$2, ...用于'正则外面',而"\g1", "\g2", ... 用于'正则内部'
3、引用'号'要与对应'()'相适配 
nginx对捕获分组的支持

⑤ 锚点和零长度断言
特点: '不会'匹配实际的'内容(content)',而是'寻找'文本的'位置(position)'
⑥ 反向引用
强调: 这里反向引用在'pattern(查找)'中使用
1)'数字'引用 -->'\1' -->对应'第一个()'分组
2)'命名'引用 -->'\k'
重点: nginx中如何在'非pattern'中引用补获的内容 --> '$1' 或 以'变量${name}'的形式
补充: nginx中'无法'获取'模式匹配(类似 grep -o)'的内容,只能获取'分组'的内容
遗留: 'sed、awk'或'编程语言中'的'替换'引用怎么做的呢? 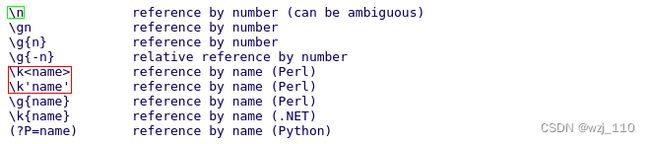
![]()
⑦ 多选结构
细节点: 一般通过'(a|b|c)<=>[a-c]'或'(str1|str2|str3)字符串分组'两种形式使用![]()
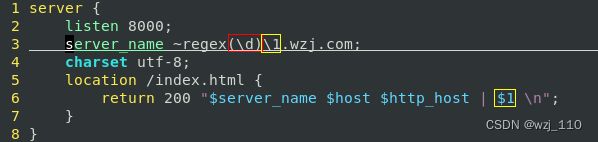
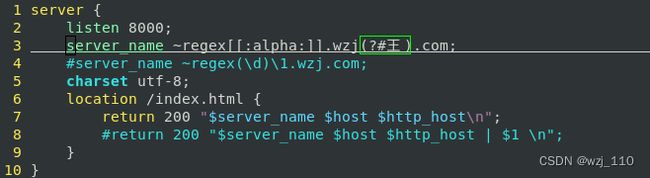
⑧ 正则注释
形式: (?#正则注释) -->'了解即可'
说明: 可以通过'nginx.conf'中的'#'注释进行解读![]()
![]()
⑨ 环视匹配
环视: 这个词从字面理解就是确定'周围环境'
环视匹配: 别名"预搜索",他只是'约束','不参与'匹配结果的'生成'
重点:要找到'参考'的'坐标原点',才能'更好'的理解'环视'匹配
本质:环视'不匹配'任何'字符',只匹配文本中的特定'位置'环视匹配的案例参考

说明: 又叫做'assert',断言只是'条件',帮你找到'真正需要'的字符串,本身并'不会'匹配
补充: 问号'?'就是在说这是一个'非捕获组',这个组'没有编号',不能用来后向引用,只能'当做断言'
![]()

++++++++++ "体会()和(?:)的区别" ++++++++++
说明: curl -w '\n' -H 'Host:ceishi.wzj.com' http://172.25.2.100:8000/6/aa
备注: \1和$1'使用'的是'(\w)',而不是'(?:\d)'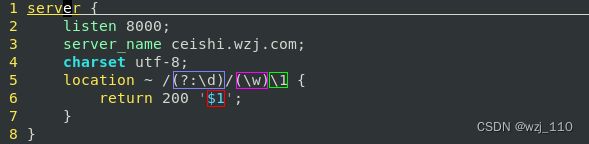
![]()
++++++++++ "体会(?:)和(?=)的区别" ++++++++++
共同点: (?:pattern) 与 (?=pattern)都'匹配分组',但'不会'把分组放到'匹配结果'中
差异点:
1)(?:pattern) 匹配得到的结果'包含pattern',(?=pattern) 则'不包含'
2) '消耗'字符
(?:pattern) 消耗字符,下一字符匹配会从'已匹配后的位置'开始
(?=pattern) 不消耗字符,下一字符匹配会从预查之前的位置开始.只预查,'不移动'匹配指针
(?:pattern) 和 (?=pattern) 的案例理解
++++++++++++++ "grep的题外话" ++++++++++++++
1) 类似用(),然后补获$1的值,细细体会'不用sed awk cut perl',只用'grep'
2) 'GUN' grep 才支持-P选项,BSD不支持,并且是'实验特性'
3) grep 搜索到的模式以'特殊颜色'标识;但是默认以行为单位显示,加上'-o'只匹配搜到的模式字符串
4) grep 匹配utf8'中文字符' --> grep -Po "[\80-\xFF]"
重点: '逆向'环视的表达式只能是'固定'长度
PCRE正则的if判断 (?(condition)true-pattern|false-pattern)
⑩ 正则选项
作用域: 为模式'随后的部分'或'未结束的模式分组'设置选项J/i/m/s/x/U'开关'
1)(?i):不区分大小写,可使用'(?-i)取消该'模式 -->'重点掌握'
场景1: "(?i)wzj(?-i)Wzj"只对'中间的wzj'进行不区分大小写的匹配
场景2: 由于(?i)'遇到闭括号'就失效,可以将需要'不区分大小写匹配的部分'写入'分组括号'中
例如: "((?i)abc)cdB"、(?:(?i)abc)cdB=(?i:abc)cdB
2)(?x):extend模式,将'忽略'pattern中多个'连续空格'和'注释符'到行尾的字符
理想:
[1]、采用了'x模式'修正符,可以在用模式中加入'空格对符式'进行'格式上的分隔
[2]、'并'分行'表示而不影响模式的解析
实际: nginx'不支持'这种'PCRE'正则
3)(?m):'multiline'多行模式,改变'^'和'$'的匹配模式 -->'了解'
[1]、默认模式下,它们分别匹配字符串'首部'和'尾部'
[2]、此模式下:
(1)^将匹配字符串'首部'和'换行';若要'仅'匹配字符串首部,使用\A
(2)$将匹配字符串'尾部'、'换行符'和换行符前的'空'字符
-->若要仅匹配字符串尾部和行尾,使用\Z,若要仅匹配字符串尾部,使用\z
4)(?s):(singleline或dotall)单行模式,改变"."的匹配模式,
[1]、默认模式下,点"."无法匹配换行符,dotall模式下可以
5)(?U):lazy匹配模式;'默认是greedy匹配'
6)The (?J) internal option setting changes the local PCRE_DUPNAMES option.
--> Allow duplicate'复制' names for subpatterns.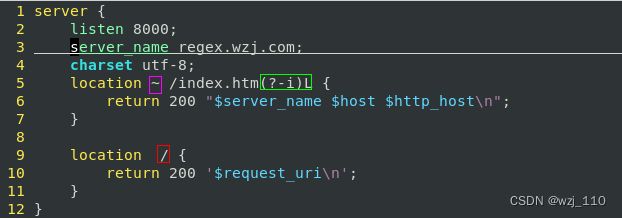
说明: 'reload'没有报错,请求的时候符合预期,说明'nginx'中的PCRE支持'选项'
场景: url中只有'部分'字符串'区分'大小写
⑪ 强转

强制'字面'解释:\Q...\E;该序列将'其中间的所有字符'强制解释为'字面'符号,强制性极强
⑫ 重置位置

作用: '\K' 用于'重置匹配的位置',\K '左边'的所有东西被"退回"且不作为'pattern'的匹配部分
细节: '\K' 的使用'不会干预到子组内'的内容,还是会'补获'
效果: 有点'删除'的意味

⑬ 条件子模式
条件子模式中的'条件'有三种:
1)一种是'前向匹配断言'结果 --> '常见' (?=assert) 、(?!assert) --> '环视匹配'
备:断言可以是'肯定'或'否定'的前身或后向断言
2)另一种是看'是否捕获'一个前面'提供的子模式' -->'命名'补获和'普通编号'补获
备: 如果在'表示条件的圆括号'里的内容'是一个数字',表示此数字代表的子模式被成功匹配时条件为真
3)条件的圆括号内是一个"R"字符 --> "难点",不常用
备:表示在这个模式或子模式'被递归调用'时条件为真;在递归调用的'顶层',这个条件为'假'

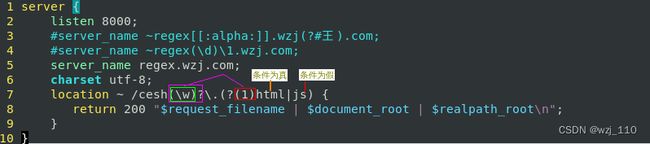
说明: 了解'nginx'可以这样做,但是一般不会这么'复杂'
++++++++ '案例2' ++++++++
后视断言必须是固定长度
理解: 就是说(?<=)和(?lookbehind assertion is not fixed length
⑭ 如何构造正则表达式
如何在nginx中'构造'正确正则表达式
1)构造正则表达式的方法和'创建数学表达式'的方法一样
2) 也就是用'多种元字符'与'操作符'将小的表达式'结合'在一起来创建更大的表达式
3) 正则表达式可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合
4) 正则表达式的'语法校验'⑮ 固化分组
1) 固化分组的'格式': '(?>...)'
需求: 能否让'([1-9])+'匹配一旦成功,'不进行回溯'呢? --> 这就用到了我们上面说的"固化分组"
特点:
[1]、当此部分表达式匹配完毕,开始匹配括号'外'面的部分时,括号'内'所有'备用'状态都会被放弃
[2]、也就是说,在固化分组'匹配结束'时,它'已经匹配的文本'已经'固化'为一个单元
[3]、只能作为'整体'而'保留'或'放弃'
[4]、括号内的'子表达式中'未尝试过的备用状态都不复存在了,所以回溯永远也不能选择其中的状态
[5]、至少是,当此‘结构匹配完成‘时,"锁定(locked in)"在其中的状态固化分组的参考
二 nginx中的正则
pcre和正则表达式的误点
nginx模块开发中使用PCRE正则表达式匹配
nginx中正则中对.、{、}等字符处理
① nginx中的pcre版本

1)nginx对'PCRE'风格正则的'支持'程度?
2)源码编译'--with-pcre'和rpm安装使用'pcre'版本
3)nginx的和pcre的'版本适配'问题
注意:nginx'不支持pcre2'版本 --> 报错 fatal error: 'pcre.h' file not found

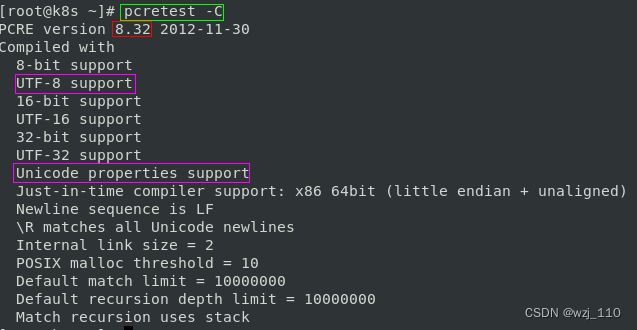
② nginx哪些指令支持pcre正则
1)map -->'~'要与'对应字符串'紧连
2)server_name '域名匹配' -->因为可能有多个域名,所以'~'要与'对应正则域名紧连',不能有空格
细节点: 最好不要使用'$server_name'做'80-->443'跳转;因为'正则'和'多域名'的原因
3)rewrite '重定向' --> '~ 有空格'
思考1: nginx在'rewrite跳转'过程中,哪些信息会'丢失'?是否可以'修改'信息?
思考2: rewrite 在跳转后加上'锚点#'
4)if '判断' --> '~ 有空格'
5)location --> 'uri匹配'③ nginx中哪些符号表示是正则匹配
1)`~` 正则'区分大小写'匹配
2)`~*` 正则'不区分大小写'匹配
3)`!~` 正则区分大小写'匹配失败'的时候 -->'反向'
4)`!~*` 正则不区分大小写'匹配失败'的时候
注意:^~ '不是'正则
思考: 正则中哪些字符需要'转义'?
[1]、'特殊'元字符转化为'普通'字符 -->例如:'\.、\\'
常见:'()、{}、|、\、.、*'
[2]、'普通'的字符转化为'特殊'含义 -->例如:'\d、\1'④ pcretest命令测试正则语法
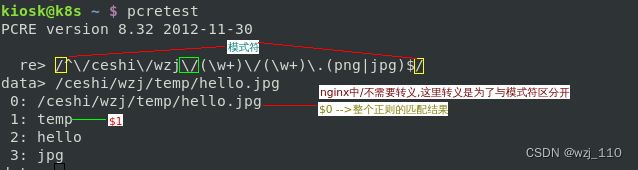
pcregrep命令
grep -Pzo '<==>' 'pcregrep'pcre正则在线测试
④ pcre_jit指令优化nginx正则

1) 启用'前提条件'
[1]、pcre库的版本'pcre8.20+'
[2]、nginx编译时'添加参数': --with-pcre --with-pcre-jit
备注: 取决于nginx'源码编译'时,使用系统的'pcre'库还是'源码编译pcre库'
2) nginx'使用'方式
http {
pcre_jit on;
}
备注: main 全局域 mginx 的'根级别指令'区域nginx调优之启用PCRE JIT以加速正则表达式的处理 PCRE性能优化