面试记录—某团java技术专家岗—一面
今年找工作,3月底到4月初面试了几家公司,接下来做一些记录,希望能帮到后续找工作的伙伴。
面试公司:某团
面试岗位:java技术专家
一、开头沟通
1、自我介绍
介绍了下自己的经历,面试官对之前工作过的中厂有良好印象
2、选择什么方向?带不带团队?
照实回答
二、算法模块
3、链表相交节点
两个长度不等链表,从某一个节点开始相交,在这个节点之后,两个链表所有的节点都是重合的,找出第一个相交的节点。
一个示例如图:
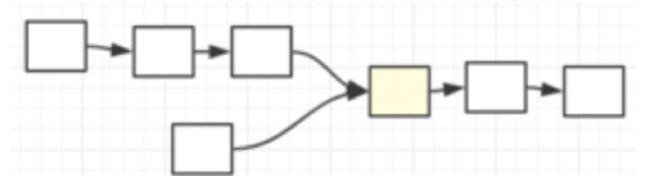
编辑切换为居中
添加图片注释,不超过 140 字(可选)
实现:Node find(Node a, Node b)
其中,Node的定义为:
class Node{
Node next;
int value;
}这道题之前遇到过,所以写出来并不难,
这道题其实要分有环的情况和无环的情况,和面试官确认,不考虑有环的情况。
我和面试官说了下解题思路:
1)首先遍历两个Node,计算出两个node的长度
2)假设node A的长度为10,node B的长度为8,那么node A先遍历两个,然后A和B同时开始遍历并判断相等,如果相等,就返回当前node,遍历完了还没有遇到相等的,就返回null。
我花了10分钟写出来了,代码如下:
public static class Node {
Node next;
int value;
}
public static Node find (Node a, Node b) {
int aLength = 0;
Node a1 = a;
while (a1 != null) {
aLength ++;
a1 = a1.next;
}
int bLength = 0;
Node b1 = b;
while (b1 != null) {
bLength ++;
b1 = b1.next;
}
if (a1 != b1) {
return null;
}
int sub = Math.abs(aLength - bLength);
a1 = a;
b1 = b;
if (aLength > bLength) {
while (sub > 0) {
a1 = a1.next;
sub --;
}
} else {
while (sub > 0) {
b1 = b1.next;
sub --;
}
}
while (a1 != null && b1 != null) {
if (a1 == b1) {
return a1;
}
a1 = a1.next;
b1 = b1.next;
}
return null;
}以上代码其实有很多优化空间,但是当时的情况就是先写出来,然后再考虑优化,这个面试官也是能理解的,只要整体思路对就行。
这里有个思考,就是我们日常的开发中也一样,代码先写出来,然后再做进一步的优化。这里有个设计原则叫YANI原则(就是避免过度设计)。
4、讲下堆的理解,场景
堆:
1)堆总是一棵完全树,即除了最底层,其他层的节点都被元素填满,且最底层尽可能地从左到右填入。
2)任一节点值均小于(或大于)它的所有后代节点值,最小值节点(或最大值节点)在堆的根上。
(这个标准是我上网搜的,当时大概意思表达出来了)
场景:PriorityQueue
三、知识点考察
5、讲下jvm结构
线程共享的区域:堆、metaspace
线程私有的区域:java虚拟栈(包含栈帧)、本地方法栈、程序计数器
执行引擎:解释器、即时编译器(JIT)、GC
本地方法接口、本地方法库

6、有没有遇到过metaspace的oom
Metaspace主要用于存储被jvm加载的类信息、常量、静态变量、即时编译器编译后的代码。
如果要让metaspace报oom错误,那么一般情况下是类加载过多,超过了metaspace的最大值所导致的,下面是加载类的例子,就是自定义类加载器加载类,然后不断的执行,就会导致metaspace的oom:
/**
* 设置最大元数据空间为10M
* 执行参数 -XX:MaxMetaspaceSize=10m
*/
public class App {
public static class MyClassLoader extends ClassLoader {
private String path;
public MyClassLoader(String path) {
this.path = path;
}
public MyClassLoader(String path, ClassLoader parentClassLoader) {
super(parentClassLoader);
this.path = path;
}
/**
* 重写父类的findClass方法,在ClassLoader在执行 loadClass 方法时,
* 如果父加载器不会加载类,就会调用当前重写的方法进行加载类
*/
@Override
protected Class findClass(String name) throws ClassNotFoundException {
BufferedInputStream bis = null;
ByteArrayOutputStream baos = null;
try {
bis = new BufferedInputStream(new FileInputStream(path + name + ".class"));
baos = new ByteArrayOutputStream();
int len;
byte[] data = new byte[1024];
while ((len = bis.read(data)) != -1) {
baos.write(data, 0, len);
}
//获取内存中的完整的字节数组的数据
byte[] classByteArray = baos.toByteArray();
//将字节数组转换为Class的实例
return defineClass(null, classByteArray, 0, classByteArray.length);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (null != baos) {
baos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (null != bis) {
bis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
}
public static void main(String[] args) throws ClassNotFoundException {
List list = new LinkedList<>();
while (true) {
MyClassLoader myClassLoader = new MyClassLoader("d:/");
list.add(myClassLoader);
Class aClass = myClassLoader.loadClass("Test");
}
}
} 7、哪些会作为gc的根起点
1)虚拟机栈(栈帧中的本地变量表)中引用的对象;
2)方法区中的类静态属性引用的对象;
3)方法区中常量引用的对象;
4)本地方法栈中JNI(即一般说的Native方法)中引用的对象
5)其他可能找到活动对象的区域(比如年轻代收集时,老年代就可以作为GC ROOT)
8、线程池的7个参数
int corePoolSize,//线程池核心线程大小
int maximumPoolSize,//线程池最大线程数量
long keepAliveTime,//空闲线程存活时间
TimeUnit unit,//空闲线程存活时间单位,一共有七种静态属性
BlockingQueue
ThreadFactory threadFactory,//自定义工厂
RejectedExecutionHandler handler//拒绝策略(默认是:ThreadPoolExecutor.AbortPolicy不执行并抛出异常)
9、设计模式:组合优于继承,为什么?
这个当时感觉没有回答好,后来看了王争老师的《设计模式之美》,正确答案如下:
继承是面向对象编程的特征之一,继承是解决类与类之间is a的关系,支持多态、代码复用的问题。
继承如果过深会造成代码复杂,影响可维护性和可读性。
这时候可以通过接口、组合、委托的方式去替代继承。
is a关系可以通过接口和组合的has a关系来替代,多态特性可以用接口来实现,代码复用可以用组合和委托来实现
10、有没有用过微服务,你是根据什么进行拆分
有的,最近的用的是spring cloud框架
业务的拆分这里其实和业务是强相关的,所以在做拆分之前建议一定要对需求做详细的分析。许世伟老师说过,架构设计三分之一的时间都要用于前期的分析。
11、DDD了解过吗?
当时只知道是面向领域编程,后续学习了解到:
DDD也称为领域驱动设计(Domain Driven Design),主要是用来指导如何解耦业务系统,划分业务模块,定义业务领域模型及其交互。做好领域驱动设计的关键是,看你对自己所做业务的熟悉程度,而并不是对领域驱动设计这个概念本身的掌握程度。即便你对领域驱动搞得再清楚,但是对业务不熟悉,也并不一定能做出合理的领域设计。所以,不要把领域驱动设计当银弹,不要花太多的时间去过度地研究它。
传统的mvc框架的开发,因为po对象只包含属性和setter、getter,不包含业务逻辑,叫做贫血模式;这种写法实际上并不符合面向对象的特性,实际是面向过程的写法。
而基于充血模型(Rich Domain Model)DDD正好相反,数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象编程风格。
12、ES了解吗?底层结构是什么?为什么快?听说过倒排索引吗?
ES底层没有详细研究,所以没答上来
13、LSM树了解过吗?
之前没注意到这个,所以也是没有回答上来
14、redis了解吗?如何实现高可用?哨兵模式如何实现高可用?使用的是什么算法?
redis通过哨兵模式实现高可用,使用的选举算法是类似paxol算法。
15、击穿、穿透、雪崩,了解过吗?如何解决这些问题?
数据库是瓶颈,尽量把压力放到缓存。
击穿:热点数据过期造成瞬间大量请求打到数据库上,解决方案:key永不过期,查询的时候上redis分布式锁
穿透:数据库没有客户要查询的数据,造成请求打到数据库上去,解决方案:布隆过滤器,查看的时候上redis分布式锁
雪崩:大量热点数据过期,解决方案:关键的key永不过期,查看的时候上redis分布式锁
16、mysql事务的隔离级别?
read uncommitted 读未提交
read committed 读已提交:简称RC
repeatable read 可重复读:简称RR
Serializable 串行执行
mysql默认一般是RC或者RR。
17、mysql如何实现可重复读
mvcc实现可重复读
18、mysql的mvcc的实现方式
意思基本回答出来了,具体可以查看这篇文章:
全网最全的一篇数据库MVCC详解,不全我负责-mysql教程-PHP中文网
19、mysql间隙锁了解过吗?
锁定范围是索引记录之间的间隙,和记录锁一起使用,统称为临建锁,针对可重复读以上隔离级别使用。
20、你有什么想问的?
我这边问了下当前部门主要的工作,然后面试官给我介绍了下目前的部门
四、最后总结
虽然后面有几道题没有回答上来,但整体回答的还算可以,算法也写的挺好,最后面试官是给过了。
参考文章链接
自定义类加载器_每天都要进步一点点的博客-CSDN博客_自定义类加载器
Java元数据区域(MetaSpace)OOM - xuan_wu - 博客园
堆算法_pirlo-san的博客-CSDN博客_堆算法
设计模式之美_设计模式_代码重构-极客时间