Java 一文掌握全部阻塞队列的使用
1、简介
本文主要对Java常用阻塞队列进行介绍和提供相关使用案例
2、 阻塞队列作用
阻塞队列提供了一种线程安全、高效的数据传递和同步机制 , 主要用于缓冲数据、限流、削峰填谷,生产者-消费者模型,线程间的协作等等。
3、 各阻塞队列区别对比
| 队列 | 有界性 | 锁 | 锁方式 | 数据结构 |
|---|---|---|---|---|
| ArrayBlockingQueue | 有 | 有锁 | ReentrantLock | 数组 |
| LinkedBlockingQueue | 有界 | 有锁 | 两个锁ReentrantLock + 条件变量Condition | 双向链表 |
| LinkedTransferQueue | 无界 | 无锁 | CAS+原子变量 | 链表 |
| PriorityBlockingQueue | 无界 | 有锁 | 独占锁(ReentrantLock) | 优先级队列(DelayWorkQueue) |
| DelayQueue | 无界 | 有锁 | ReentrantLock | 堆(PriorityQueue) |
| SynchronousQueue | 无容量 | 无锁 | CAS+自旋(无锁),自旋了一定次数后调用 LockSupport.park()进行阻塞 | 链表 |
4、 阻塞队列常用方法说明
注意:
- 队列添加元素是从队尾添加, 删除元素是从队头删除,有顺序性
- 虽然有些方法看起来功能很像,但是实际的逻辑可能完全不一样,一定要根据具体场景去使用
添加元素
add: 如果队列已满,抛出IllegalStateException异常offer:如果队列已满,falseput: 如果队列已满,阻塞等待直到队列有空闲位置
删除元素
take: 如果队列为空,阻塞等待直到队列有元素poll: 如果队列为空,返回 nullremove: 如果队列为空,抛出NoSuchElementException异常drainTo(Collection):批量从队列中取出全部元素到集合中drainTo(Collection, int): 批量从队列中取出n个元素到集合中remove(Obejct): 删除指定元素,删除成功返回true, 如果有多个相同元素只会删除一个removeIf(Predicate): 根据断言表达式删除所有符合条件的元素,删除失败返回falseremoveAll(Collection): 删除队列中所有在集合中存在的的元素,删除失败返回false (差集)retainAll(Collection): 保留队列中所有在集合中存在的的元素。 (交集)
查看元素
peek:查看队头元素, 如果队列为空, 返回nullelement: 查看队头元素, 如果队列为空,抛出NoSuchElementException异常
其他:
remainingCapacity:返回队列可用容量大小isEmpty: 队列是否为空
5、使用介绍
5.1、普通阻塞队列
包括ArrayBlockingQueue、LinkedBlockingQueue、ConcurrentLinkedQueue 、PriorityBlockingQueue这些队列在用法上无本质区别,只是底层数据结构和加锁方式不一样。
- 其中PriorityBlockingQueue逻辑有点不同,队列元素支持按优先级排序取出,其实就是阻塞队列里对于优先级队列的实现,支持排序。
简单的生产者-消费者模型(1P-3C)使用
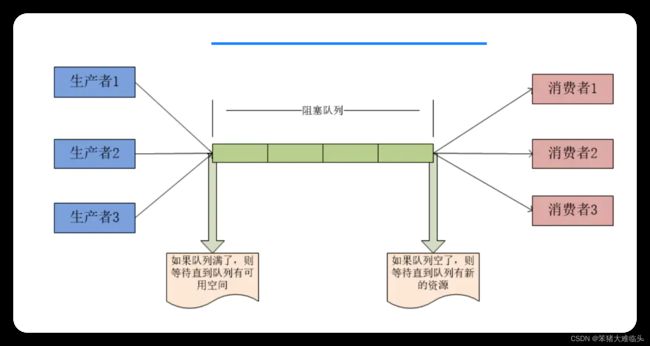
@Test
public void test4() throws InterruptedException {
// 编写1个生产者-3个消费者的模型
BlockingQueue<String> queue = new ArrayBlockingQueue<>(3);
// 1个生产者
new Thread(() -> {
for (int i = 0; i < 20; i++) {
try {
// 生产元素如果满了阻塞等待
queue.put("data_"+i);
System.out.println("生产者生产元素: " + i);
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
// 3个消费者
for (int i = 0; i < 3; i++) {
final int index = i;
new Thread(() -> {
while (true){
try {
// 消费元素,如果队列为空阻塞等待
System.out.println("消费者"+index+"消费元素: " + queue.take());
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
}
Thread.sleep(300000);
}
5.2 SynchronousQueue队列
同步阻塞队列
- 是一个无法存储元素的阻塞队列,队列的容量是0,底层并不会缓存数据。 如果你直接队列里add或者offer添加元素会失败。
- 支持指定为公平队列模式, 即的等待的线程支持按FIFO(先进先出)的顺序去生产和消费。 默认是非公平。
- 公平队列具体实现是: TransferQueue, 先进性出
- 非公平队列具体实现是 TransferStack, 先进后出
既然不会存储元素那它能干什么呢? 还是生产者-消费者模型, 与一般阻塞队列区别是每次生产者线程只能生产一份数据, 只有这份数据被消费者线程消费了,生产者才能继续生产。 同理,消费者线会阻塞等待生产者线程提供数据后才能进行处理。
ps: 它容量不是 1 而是 0,因为它不需要去持有元素,它所做的就是直接传递而已
它适合的逻辑执行链路是 生产-->消费--> 生产--> 消费-->生产--> 消费.
5.2.1 使用案例1:
假设有一个场景, 两个客户端端线程A和B, 线程A和B需要通过几次的信号同步才能建立连接成功,下面是三次信号同步的逻辑,
| 操作时间 | 操作 | 客户端A | 客户端B |
|---|---|---|---|
| 1 | A向B建立连接 | queue.put(true) | queue.take() |
| 2 | B向A建立连接 | queue.take() | queue.put(true) |
| 3 | A向B建立连接 | queue.put(true) | queue.take(true) |
@Test
public void test22() throws InterruptedException {
SynchronousQueue<Boolean> queue = new SynchronousQueue<>(true);
AtomicInteger connectionCount = new AtomicInteger(0);
Client clientA = new Client(queue,connectionCount);
Client clientB = new Client(queue,connectionCount);
clientA.connectTo(clientB);
System.out.println("第" + connectionCount.get() +"次连接成功");
clientB.connectTo(clientA);
System.out.println("第" + connectionCount.get() +"次连接成功");
clientA.connectTo(clientB);
System.out.println("第" + connectionCount.get() +"次连接成功");
System.out.println("结束");
}
static class Client {
private SynchronousQueue<Boolean> queue;
private AtomicInteger connectionCount;
public Client(SynchronousQueue<Boolean> queue, AtomicInteger connectionCount) {
this.queue = queue;
this.connectionCount = connectionCount;
}
public void ack() throws InterruptedException {
this.queue.take();
}
public boolean connectTo(Client b) throws InterruptedException {
new Thread(() -> {
try {
Thread.sleep(2000);
b.ack();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}).start();
queue.put(true);
int count = connectionCount.addAndGet(1);
if (count >= 3){
return true;
}else {
return false;
}
}
}
5.2.2 使用案例2:
假设有一个场景,有两夫妻, 第一天老公A负责卖鱼,赚到的钱给老婆B, 第二天老婆用这笔钱去投资,投资赚到的钱给老公,第三天老公用这笔钱去继续买鱼,如此日复一日, 夫妻两人属于隔天工作赚钱模式, 接下来我们用同步阻塞队列实现这个场景
@Test
public void test25() throws InterruptedException {
SynchronousQueue<AtomicInteger> queue = new SynchronousQueue<>();
Thread threadA = new Thread(() -> {
try {
new A(queue).startWork();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Thread threadB = new Thread(() -> {
try {
new B(queue).startWork();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
@Data
class A {
private SynchronousQueue<AtomicInteger> queue ;
// 老公的钱
AtomicInteger money = new AtomicInteger(1000);
public A(SynchronousQueue<AtomicInteger> queue) {
this.queue = queue;
}
public void startWork() throws InterruptedException {
while (true) {
// 卖鱼赚到的钱
Thread.sleep(2000);
int earnMoney = new Random().nextInt(100);
money.addAndGet(earnMoney);
System.out.println("老公赚到了" + earnMoney + "元, 当前余额: " + money.get());
// 把钱全部给老婆
queue.put(money);
System.out.println("老公开始休息");
// 等待老婆的钱
money = queue.take();
System.out.println("收到了老婆的" + money + "元, 继续卖鱼");
}
}
}
@Data
class B extends Thread {
private SynchronousQueue<AtomicInteger> queue ;
// 老婆的钱
AtomicInteger money = new AtomicInteger(0);
public B(SynchronousQueue<AtomicInteger> queue) {
this.queue = queue;
}
public void startWork() throws InterruptedException {
while (true) {
// 等待老公的钱
money = queue.take();
System.out.println("收到了老公的" + money + "元, 继续投资");
// 投资赚到的钱
Thread.sleep(2000);
int earnMoney = new Random().nextInt(100);
money.addAndGet(earnMoney);
System.out.println("老婆赚到了" + earnMoney + "元, 当前余额: " + money.get());
// 把钱全部给老公
queue.put(money);
System.out.println("老婆开始休息");
}
}
}
5.2.3 其他
在指定容量为1的普通阻塞队列和SynchronousQueue有什么区别?
-
容量为1的普通阻塞队列在put第一个元素并不会阻塞等待,因为还没满,只有put第二个元素后因为队列满了才会阻塞等待。 而SynchronousQueue put就会直接阻塞等待。
- 那你肯定说那指定容量为0, 但是为0没有意义根本无法使用,因为生产者无法生产数据,消费者也无法消费数据。
-
SynchronousQueue适用于需要精确控制线程之间
交换、传递元素的场景,而普通阻塞队列适用于需要缓冲多个元素的场景
适合场景:
- 线程间的数据交换、线程同步
- 实现任务执行器(Executor)框架, 作为任务提交者和任务执行者之间的交换通道,用于控制任务提交和执行的速率。当任务提交者提交一个任务时,它将被阻塞,直到任务执行者开始执行任务。这对于控制任务的执行顺序和速率非常有用
- Executors.newCachedThreadPool() 默认用的就是SynchronousQueue, 这样线程池就无法存储任务,来一个任务就直接new一个线程去处理
5.3 LinkedTransferQueue
可以看作是SynchronousQueue和LinkedBlockingQueue的结合体。 即支持SynchronousQueue的直接传递性,减少用锁来同步,也支持普通无界阻塞队列的存储更多元素.
与普通阻塞队列区别就是多了一些以下的方法去添加元素
transfer方法:
- 当此时有消费者线程在阻塞等待时,调用transfer方法的生产者线程不会将元素存入队列,而是直接将元素传递给消费者。
- 当此时没有正在等待的消费者线程,则会将元素入队,然后会阻塞等待. 当被消费一个后才会唤醒一个等待的生产线程(这个与普通阻塞队列的put方法一致)
tryTransfer方法
- 与transfer方法不同是, 如果没有正在等待的消费者线程, 不会将元素入队而是返回false。 如果有等待的消费者线程则直接传递给它并返回true
hasWaitingConsumer: 是否有消费者线程在等待
getWaitingConsumerCount: 获取等待的消费者数量的
5.4 DelayQueue 延迟队列
- 底层数据结构是优先级队列, 属于无界阻塞队列所以put操作不会阻塞等待(底层调用的是offer法) ,
- 存储的元素是
Delayed接口的子类, 会根据Delayed接口的compareTo方法进行优先级排序,时间越小元素的将被优先取出。 - take方法取出元素时,只有队头的元素延迟时间到了才会被取出否则一致阻塞等待。 这个跟普通阻塞队列的队列为空就阻塞等待不同。 它是根据Delayed接口的
getDelay方法来判断延迟时间是否到了然后取出, 这个方法返回值代表剩余的延迟时间,如果这个值小于等于0就被马上被取出消费。 - 并不适用于需要高精度的时间控制场景,因为其延迟时间的计算和排序是基于系统时间的,并受系统时间的精度和调整影响。
下面是一个使用案例:
public static void main(String[] args) {
DelayQueue<DelayedTask> delayQueue = new DelayQueue<>();
// 添加延迟任务
delayQueue.put(new DelayedTask("Task 1", 5, TimeUnit.SECONDS)); // 延迟5秒
delayQueue.put(new DelayedTask("Task 2", 10, TimeUnit.SECONDS)); // 延迟10秒
delayQueue.put(new DelayedTask("Task 3", 2, TimeUnit.SECONDS));
delayQueue.add(new DelayedTask("Task 4", 0, TimeUnit.SECONDS));
delayQueue.add(new DelayedTask("Task 5", 0, TimeUnit.SECONDS));
log.info("start");
// 处理延迟任务
while (!delayQueue.isEmpty()) {
try {
// 队头的元素延迟时间到了才会被取出否则一致阻塞等待
DelayedTask task = delayQueue.take();
log.info("处理任务: {}", task.getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
static class DelayedTask implements Delayed {
private final String name;
private final long delay;
private final long expireTime;
DelayedTask(String name, long delay, TimeUnit unit) {
this.name = name;
this.delay = unit.toMillis(delay);
this.expireTime = System.currentTimeMillis() + this.delay;
}
String getName() {
return name;
}
// 返回剩余的延迟时间, 如果小于等于0则会被取出使用
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(expireTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
// 按照具体过期时间进行优先级排序,越小的在前面优先被取出
@Override
public int compareTo(Delayed other) {
return Long.compare(this.expireTime, ((DelayedTask) other).expireTime);
}
}
下面是执行结果,从打印时间可以看到,对应的任务都是到了指定的延迟时间才会被取出。
注意由于任务4和5指定的延迟时间为0所以会被马上取出处理
17:29:29.746 [main] INFO com.disruptor.blockQueue.BQTest3_DelayQueue - start
17:29:29.747 [main] INFO com.disruptor.blockQueue.BQTest3_DelayQueue - 处理任务: Task 4
17:29:29.748 [main] INFO com.disruptor.blockQueue.BQTest3_DelayQueue - 处理任务: Task 5
17:29:31.751 [main] INFO com.disruptor.blockQueue.BQTest3_DelayQueue - 处理任务: Task 3
17:29:34.749 [main] INFO com.disruptor.blockQueue.BQTest3_DelayQueue - 处理任务: Task 1
17:29:39.749 [main] INFO com.disruptor.blockQueue.BQTest3_DelayQueue - 处理任务: Task 2
应用场景(主要适用于延迟任务):
- 订单业务: 下单之后如果三十分钟之内没有付款就自动取消订单。
- 订餐通知: 下单成功后60s之后给用户发送短信通知。
- 关闭空闲连接。服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之。
- 缓存。缓存中的对象,超过了空闲时间,需要从缓存中移出。
- 任务超时处理。在网络协议滑动窗口请求应答式交互时,处理超时未响应的请求等