算法面试一
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
- 一、时间复杂度 (大 O)
-
- 数组(动态数组/列表)
- 字符串 (不可变)
- 链表
- 哈希表/字典
- 集合
- 栈
- 队列
- 二叉树问题 (DFS/BFS)
- 二叉搜索树
- 堆/优先队列
- 二分查找
- 其他
- 二、 输入大小与时间复杂度
-
- n <= 10
- 10 < n <= 20
- 20 < n <= 100
- 100 < n <= 1,000
- 1,000 < n < 100,000
- 100,000 < n < 1,000,000
- 1,000,000 < n
- 三、排序算法
- 四、 通用 DS/A 流程图
- 总结
算法与数据结构要点速学

提示:以下是本篇文章正文内容,下面案例可供参考
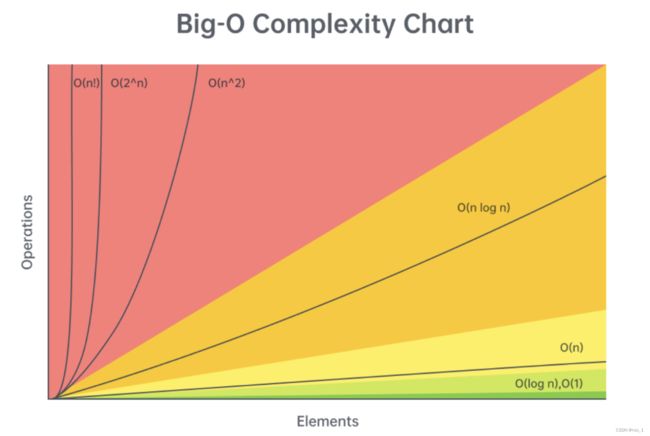
一、时间复杂度 (大 O)
我们来谈谈常用操作的时间复杂度,按数据结构/算法划分。然后,我们将讨论给定输入大小的合理复杂性。
数组(动态数组/列表)
规定 n = arr.length,
在结尾添加或删除元素: O(1) 相关讨论
从任意索引中添加或删除元素: O(n)
访问或修改任意索引处的元素: O(1)
检查元素是否存在: O(n)
双指针: O(n⋅k), kk 是每次迭代所做的工作,包括滑动窗口
构建前缀和: O(n)
求给定前缀和的子数组的和:O(1)
字符串 (不可变)
规定 n = s.length,
添加或删除字符: O(n)
任意索引处的访问元素: O(1)
两个字符串之间的连接: O(n+m), mm 是另一个字符串的长度
创建子字符串: O(m), mm 是子字符串的长度
双指针: O(n⋅k), kk 是每次迭代所做的工作,包括滑动窗口
通过连接数组、stringbuilder 等构建字符串:O(n)
链表
给定 nn 作为链表中的节点数,
给定指针位置的后面添加或删除元素: O(1)
如果是双向链表,给定指针位置添加或删除元素: O(1)
在没有指针的任意位置添加或删除元素: O(n)
无指针任意位置的访问元素: O(n)
检查元素是否存在: O(n)
在位置 i 和 j 之间反转: O(j−i)
使用快慢指针或哈希映射完成一次遍历: O(n)
哈希表/字典
给定 n = dic.length,
添加或删除键值对:O(1)
检查 key 是否存在: O(1)
检查值是否存在: O(n)
访问或修改与 key 相关的值: O(1)
遍历所有键值: O(n)
注意: O(1) 操作相对于 n 是常数.实际上,哈希算法可能代价很高。例如,如果你的键是字符串,那么它将花费O(m),其中 mm 是字符串的长度。 这些操作只需要相对于哈希映射大小的常数时间。
集合
给定 n = set.length,
添加或删除元素: O(1)
检测元素是否存在:O(1)
上面的说明也适用于这里。
栈
栈操作依赖于它们的实现。栈只需要支持弹出和推入。如果使用动态数组实现:
给定 n = stack.length,
推入元素: O(1)
弹出元素: O(1)
查看 (查看栈顶元素): O(1)
访问或修改任意索引处的元素: O(1)
检测元素是否存在: O(n)
队列
队列操作依赖于它们的实现。队列只需要支持出队列和入队列。如果使用双链表实现:
给定 n = queue.length,
入队的元素: O(1)
出队的元素: O(1)
查看 (查看队列前面的元素): O(1)
访问或修改任意索引处的元素: O(n)
检查元素是否存在: O(n)
注意:大多数编程语言实现队列的方式比简单的双链表更复杂。根据实现的不同,通过索引访问元素可能比O(n) 快,但有一个重要的常量除数。
二叉树问题 (DFS/BFS)
给定 nn 作为树的节点数,
大多数算法的时间复杂度为 O(n⋅k),kk 是在每个节点上做的操作数, 通常是 O(1)。这只是一个普遍规律,并非总是如此。我们在这里假设 BFS 是用高效队列实现的。
二叉搜索树
给定 nn 作为树中的节点数,
添加或删除元素:最坏的情况下 O(n),平均情况 O(logn)
检查元素是否存在:最坏的情况下 O(n),平均情况 O(logn)
平均情况是当树很平衡时 —— 每个深度都接近满。最坏的情况是树只是一条直线。
堆/优先队列
给定 n = heap.length 并讨论最小堆,
添加一个元素: O(logn)
删除最小的元素: O(logn)
找到最小的元素: O(1)
查看元素是否存在: O(n)
二分查找
在最坏的情况下,二分查找的时间复杂度为O(logn),其中 nn 是初始搜索空间的大小。
其他
排序: O(n⋅logn), 其中 nn 是要排序的数据的大小
图上的 DFS 和 BFS:O(n⋅k+e),其中 nn 是节点数,ee 是边数,前提是每个节点处理花费都是 O(1),不需要重复遍历。
DFS 和 BFS 空间复杂度:通常为 O(n),但如果它在图形中,则可能为 O(n+e) 来存储图形
动态规划时间复杂度:O(n⋅k),其中 nn 是状态数,kk 是每个状态所需要的操作数
动态规划空间复杂度:O(n),其中nn是状态数
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/arithmetic-interview-cheat-sheet/0exlg2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
二、 输入大小与时间复杂度
问题的约束可以被视为提示,因为它们指示解决方案时间复杂度的上限。能够在给定输入大小的情况下计算出解决方案的预期时间复杂度是一项宝贵的技能。在所有 LeetCode 问题和大多数在线评估 (OA) 中,你都会得到问题的约束条件。不幸的是,你通常不会在面试中被明确告知问题的限制条件,但这对于在 LeetCode 上练习和完成 OAs 仍然有好处。尽管如此,在面试中,询问预期的输入大小通常也没什么坏处。
n <= 10

10 < n <= 20

20 < n <= 100

100 < n <= 1,000

1,000 < n < 100,000

100,000 < n < 1,000,000

1,000,000 < n

三、排序算法
所有主要的编程语言都有一个内置的排序方法。假设并说排序成本为 O(n⋅logn)。通常是正确的,其中 nn 是要排序的元素数。为了完整起见,这里有一个图表,列出了许多常见的排序算法及其完整性。编程语言实现的算法各不相同;例如,Python 使用 Timsort,但在 C++ 中,特定算法不是强制性的并且会有所不同。

四、 通用 DS/A 流程图
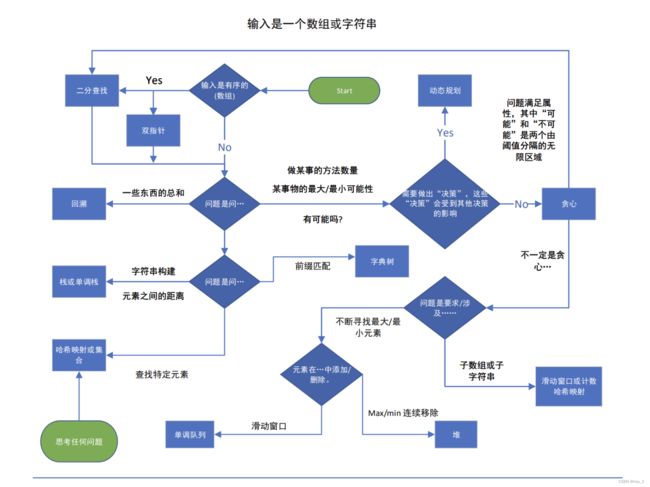
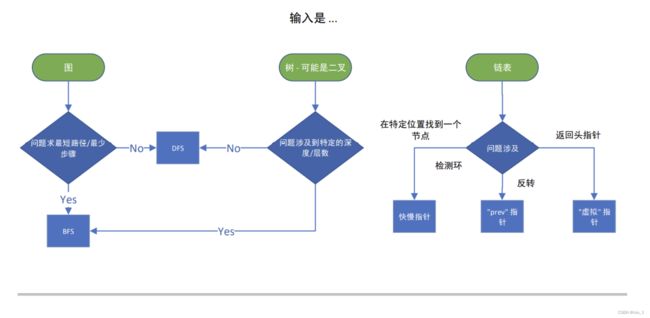
总结
作者:力扣 (LeetCode)
链接:https://leetcode.cn/leetbook/read/arithmetic-interview-cheat-sheet/0e5d6c/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。