微服务架构领域驱动设计
简章
应用程序的核心是业务逻辑,业务逻辑实现了业务规则。开发复杂的业务逻辑总是充满了挑战。组织业务逻辑有两种主要模式:
- 以「贫血模型」为基础的「事务脚本」模式也叫做「数据模型驱动」
- 以「充血模型」为基础的「领域驱动」模式也叫DDD
事务脚本模式设计
贫血模型是指对象只用于在各层之间传输数据使用,只有数据字段和Get/Set方法,没有逻辑在对象中。「事务脚本」可以理解为业务是由一条条增删改查的SQL组织而成,是面向过程的编程。
领域驱动模式设计
充血模型是面向对象设计的本质,一个对象是拥有状态和行为的。将大多数业务逻辑和持久化放在领域对象中,业务逻辑只是完成对业务逻辑的封装、事务、权限、校验等的处理。
数据模型驱动业务逻辑代码非常复杂,领域实体只包含一堆属性,只是数据表的映射,没有业务行为。非常缺乏领域概念的表达,业务逻辑散乱。比如值对象的设计在DDD里是一个类,在数据模型设计里往往是其他类的几个属性。聚合是领域驱动最小的复用单元,粒度更粗。数据模型设计里领域实体的数量跟表数量一一对应,数据表是最小的复用单元,粒度太细。
面向过程的方法简单粗暴可以快速搞定项目,无需过多仔细考虑设计组织各种类。但是业务逻辑变得越来越复杂,维护应用系统会变得像噩梦一样。除非应用程序非常简单,否则应该抵制住编写面向过程设计的诱惑,使用领域驱动模式,进行面向对象设计。
领域驱动
领域驱动DDD包含战略设计、战术设计、技术实现三个部分。战略设计侧重于高层次、宏观上去划分限界上下文,而战术设计则关注使用建模工具来细化上下文,通过领域模型来表达业务。技术实现主要通过分层架构来隔离领域模型代表的业务逻辑和技术细节。一个整体过程大致包括:宏观划分各领域 → 领域内划分限界上下文,定义上下文之间的关系 → 上下文内分析业务,识别领域概念,定义合适的领域概念 → 通过分层架构实现编码,并验证领域模型的合理性,必要时重新回到前面步骤重构领域模型。

常用名词
| 名称 |
定义 |
举例 |
| 实体 |
实体一般对应业务对象,具有业务属性和业务行为 |
线索是个实体,线索的状态会随着跟进活动的推进随时变化,需要根据唯一标识来追踪变化 |
| 值对象 |
值对象主要是属性集合,对实体的状态、特征进行业务语义的描述 |
线索上的联系方式信息是值对象,包含联系方式类型和联系方式内容,不需要唯一标识去追踪联系方式的变化过程,整体替换新联系方式 |
| 聚合 |
聚合是由业务和逻辑紧密关联的实体和值对象组成的,是数据修改和持久化的基本单元 |
线索是个聚合,线索实体是该聚合的根实体,状态信息、联系方式信息等是附属聚合的值对象 |
| 资源库 |
资源库是对资源访问的抽象。不局限于数据库、文件、网络存储。接口需要不依赖于具体的数据存储和ORM实现框架 |
线索这个聚合的访问通过线索资源库提供,资源库的实现因技术选型不同而不同,可以是数据库、文件等 |
| 领域事件 |
表示领域中所发生的重要事件,事件发生后通常会导致进一步的业务操作,或者在系统其他地方引起反应 |
线索创建后会产生线索已创建领域事件,后续的线索分配服务、打标签服务可以监听该事件启动相应操作 |
| 领域服务 |
领域服务没有任何属性或数据,只是一个领域行为或动作,不适合放在任何聚合内的逻辑行为 |
线索的查重行为属于领域服务,单个线索自身没法完成查重行为 |
| 应用服务 |
应用服务对应到一个具体业务场景,通过编排聚合、资源库、领域事件、外部适配接口、领域服务来完成 |
线索创建这个场景对应线索创建应用服务,该服务会编排线索查重、线索聚合创建、线索资源库创建、线索已创建领域事件发送等 |
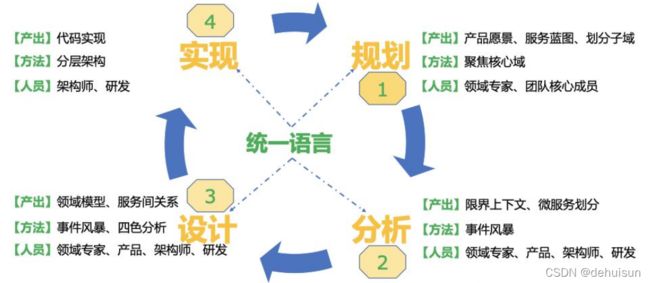 规划阶段
规划阶段
规划阶段需要考虑产品愿景和服务蓝图,需要划分出产品的核心领域,支撑领域,通用领域。如果从0到1开发产品的话规划阶段需要做很多的工作,比如开发一个产品需要考虑产品愿景和服务蓝图,需要聚焦到哪些业务领域。至于提供什么功能需要通过分析阶段来拆解。
分析阶段
分析阶段是基于业务流程和功能分析出具体的业务对象,不同的业务对象归属划分到限界上下文。因为线索功能复杂,团队对于线索功能认知不一,有必要让相关人员一起采用事件风暴方法来分析和梳理业务。事件风暴认为事件流很⼤程度上反映了现实业务逻辑,参与人员基于领域事件发生的时间线,把事件的前因后果逐步挖掘出来。整个过程包含识别领域事件、决策命令、领域名词三个步骤。通过尝试回答这几个问题:这个业务涉及的系统产生了什么变化?变化由哪个角色通过什么方式触发的?系统变化产生了哪些结果?
事件风暴
可以使用事件风暴的方法识别领域事件。事件风暴是以事件为中心的领域模型,由聚合和事件组成。
1、识别领域事件
领域专家集体讨论领域事件
2、识别事件触发器
用户操作(蓝色)、外部系统(紫色)、时间流逝、另一个领域事件。
3、识别聚合
领域专家识别哪些使用命令的聚合并发出相应的事件。由黄色表示。
4、限界上下文
划分限界上下文
基于事件风暴的结果,需要把领域名词和规则等划分到合适的限界上下文。定义好限界上下文后还需要定义不同限界上下文的协作关系。一般情况下如果业务允许的情况尽量选择通过领域事件来协作。
#1:根据相关性做归类。一般是优先考虑功能相关性而不是语义相关性,比如创建订单和支付订单都是订单语义,但功能相差比较大,应该划分为两个限界上下文。
#2:根据团队粒度做裁剪、根据技术特点做裁剪。一些通用的技术功能应该尽可能归拢到一个限界上下文,比如每个业务限界上下文都有监控,但监控能力应该归拢到监控限界上下文。
设计阶段
设计阶段就是把分析阶段产出的领域名词,领域事件,决策命令使用DDD进行领域建模,并细化每个领域概念的数据和行为。
建议的建模过程是:
-
业务需求的分析过程自上而下,由业务流程,到用户用例,到领域模型。而设计过程是自下而上的。从领域元素设计开始,最后才是应用服务的编排。
-
建议设计优先级是先值对象 → 再实体 → 再聚合 → 再领域服务→ 最后是应用服务,优先考虑领域是否应该为值对象,其次是否为实体,划分出聚合。不属于实体或值对象中的领域行为放到领域服务,需要协调聚合的领域行为设计为领域服务或者应用服务。
-
任何业务代码逻辑优先映射到原子性的领域模型,比如值对象、实体、领域事件、资源库接口、外部适配接口,其次再映射到组合性领域模型,比如领域服务、应用服务。
领域建模
建模就是设计的过程,建模的过程就是梳理、走查业务逻辑,拆解为要解决的问题和涉及的业务场景、业务流程、业务概念,在这个过程中形成对应的领域概念。
如果团队对于业务比较陌生适合采用事件风暴方法进行梳理;如果团队对业务比较熟悉,如果业务流程相对简单,则可以采用四色建模法进行业务梳理。采用这些分析业务的方法可以保证产研团队对业务逻辑的理解在一个水平上。
实现阶段
- 1 描述业务场景
用5W2H进行分析:用户(WHO)在什么环境(WHERE)下遇到什么时机(WHEN)因为什么(WHY)产生什么目标(WHAT),继而通过什么方法(HOW)去达成目标。大部分场景不需要考虑HOW MUCH。

- 2 梳理业务流程
- 3 寻找时标性对象
时标性对象对应到时刻-时段原型,是我们关心的可追溯的业务事件。通过将业务流程分解到业务过程的最小粒度来寻找,然后绘制以下格式的表格:
- 4 寻找时标对象周围的“人、地、物”
- 5 抽象“角色”
- 6 补充“描述”信息
- 7 划分限界上下文
- 8 确定聚合及聚合根
- 9 优化调整子域划分
边界
聚合将领域模型分解为块,
聚合规则
- 只引用根聚合、
- 聚合间引用必须使用跟、
- 一个事务中只能创建或更新一个聚合
聚合颗粒度
使用聚合设计业务逻辑
发布领域事件
生成发布领域事件
领域事件由聚合负责发布。
生成发布领域事件。
消费领域事件
DDD分层架构
微服务架构模型有很多种,例如洋葱架构、CQRS和六边形架构等。其核心理念都是为了设计出“高内聚,低耦合”的微服务。而DDD分层架构的出现,使微服务的架构边界变得越来越清晰。
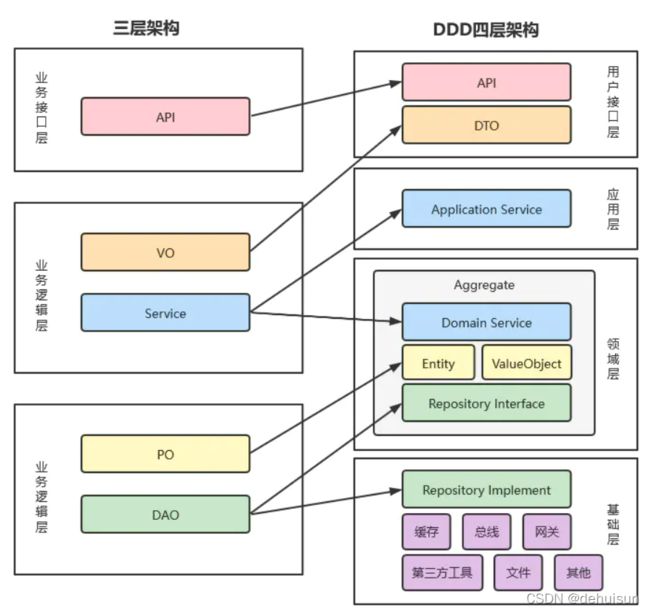


PO(数据持久化对象):与数据库字段映射的数据载体
DO(领域对象):领域模型核心业务对象的载体,包括实体和值对象
DTO(数据传输对象):用于前端和微服务交互的数据传输载体
用户接口层:主要有facade接口,Assembler转换器
- 微服务面向不同前端时,需要展示的数据可能不同,此时由于需要保持领域核心业务逻辑的稳定,不可能去定制开发各种领域服务和应用服务编排。因此,为避免暴露服务端业务逻辑,防止非必需的字段数据外泄 ,同时保证领域逻辑的干净,用户接口层的facade接口和Assembler转换器就发挥作用了。
- facade接口用于封装应用服务,适配不同前端需要的字段,提供不同要求的服务接口适配。Assembler根据不同前端的数据请求,完成DTO和领域DO对象的组装,转换,完成数据适配。
应用层:
- 应用层连接用户接口层和领域层,主要协调领域层,面向用例和业务流程,协调多个聚合完成服务的组合和编排,在这一层不实现任何业务逻辑,只是很薄的一层
- 如何判定一个东西是否属于业务逻辑?
很简单,只需设想你和产品聊这个事情时,需不需要把这部分信息输入给它?比如接口调用的处理,数据的转换,是否加了缓存等等都不属于产品关心的东西,所以不算是业务逻辑
- 应用层编排成应用服务后,被接口层facade封装,完成接口和数据适配后,以粗粒度向API网关发布服务
- 应用层还负责事件的订阅和发布,以及与其他外部服务的交互,事件的具体实现则在领域层
领域层:
- 领域层位于应用层之下,是领域模型的核心,主要实现领域模型的核心业务逻辑,体现领域模型的业务能力
- 领域层关注实现领域对象的充血模型和聚合本身的原子业务逻辑,至于用户操作和业务流程,则交给应用层去编排。这样设计可以保证领域模型不容易受外部需求变化的影响,保证领域模型的稳定
- 跨多个聚合的领域逻辑在领域层实现,由领域服务组织和协调多聚合的多实体,实现原子业务逻辑
基础层:
- 基础层贯穿了DDD所有层,包括第三方工具,API网关,消息中间件,分布式事务,消息最终一致性能力,数据库,缓存能能力的提供。
- 基础层有仓储模式的代码逻辑,通过仓储接口和仓储实现,解耦领域层和基础层,保证领域核心业务逻辑的干净,降低DB资源变化给领域层带来的影响,这部分内容,请见下回分解。
DDD一方面使用分而治之的思想,引入划分领域、限界上下文、模块分层、划分聚合在不同层次、不同粒度来降低问题的复杂度。另一方主张聚焦领域逻辑,通过不同手段来减少业务和技术的耦合。因此DDD只是大部分软件设计思想一种,软件设计的本质都是为了高内聚低耦合。但是DDD并不是万能的,不是所有业务开发场景都适合用DDD。有些简单业务场景不使用DDD反而更恰当。因为DDD有较高的学习门槛,需要整个团队形成统一认识和协同,需要相应的编码规范和架构落地。因此学习和落地DDD时要时刻记住自己的出发点是为了应对现在或者将来的复杂业务领域而来。不必太拘泥于某些点是否遵守了DDD原则,如果觉得用了DDD会比没有用好一点点,也值得迈出这一步。