计算机竞赛 基于生成对抗网络的照片上色动态算法设计与实现 - 深度学习 opencv python
文章目录
- 1 前言
- 1 课题背景
- 2 GAN(生成对抗网络)
-
- 2.1 简介
- 2.2 基本原理
- 3 DeOldify 框架
- 4 First Order Motion Model
- 5 最后
1 前言
优质竞赛项目系列,今天要分享的是
基于生成对抗网络的照片上色动态算法设计与实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
随着科技的发展,现在已经没有朋友会再去买胶卷拍照片了。不过对于很多70、80后来说,他们家中还保存着大量之前拍摄的胶卷和老照片。这些老照片是一个时代的记忆,记录着我们生活中的点点滴滴。不过时代发展了,这些老照片的保存和浏览也应该与时俱进。在本期文章中,我们就介绍如何将这些老照片转化为数字照片,更方便大家在电脑或者手机上浏览、保存和回忆。
本项目中我们利用生成对抗网络-GAN和图像动作驱动-First Order Motion Model来给老照片上色并使它动起来。
2 GAN(生成对抗网络)
2.1 简介
**GANs(Generative adversarial networks,对抗式生成网络)**可以把这三个单词拆分理解。
- Generative :生成式模型
- Adversarial :采取对抗的策略
- Networks :网络(不一定是深度学习)
模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative
Model)的互相博弈学习产生相当好的输出。原始 GAN 理论中,并不要求 G 和 D
都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。
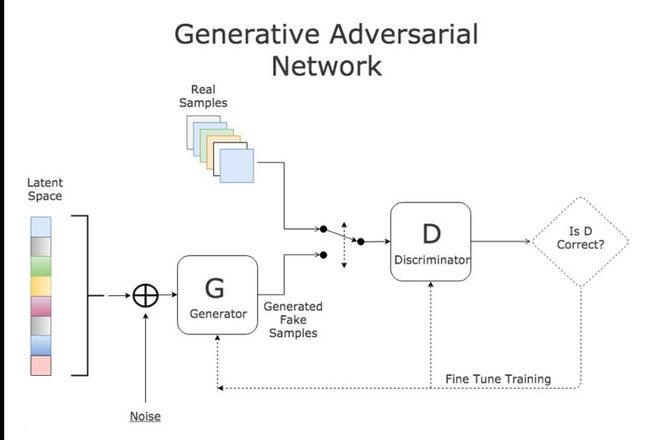
2.2 基本原理
这里介绍的是原生的GAN算法,虽然有一些不足,但提供了一种生成对抗性的新思路。放心,我这篇博文不会堆一大堆公式,只会提供一种理解思路。
理解GAN的两大护法G和D,生成对抗网络(GAN)由2个重要的部分构成:
- 生成器(Generator ):通过机器生成数据(大部分情况下是图像),负责凭空捏造数据出来,目的是“骗过”判别器
- 判别器(Discriminator ):判断这张图像是真实的还是机器生成的,负责判断数据是不是真数据,目的是找出生成器做的“假数据”

这样可以简单的看作是两个网络的博弈过程。在最原始的GAN论文里面,G和D都是两个多层感知机网络。首先,注意一点,GAN操作的数据不一定非得是图像数据,不过为了更方便解释,用图像数据为例解释以下GAN:
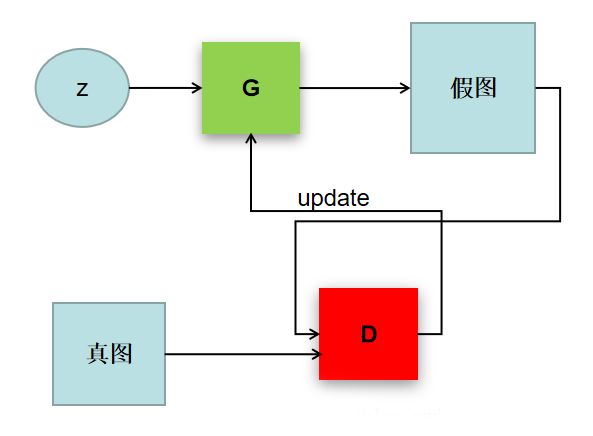
tensorflow实现
import tensorflow as tf
def load_dataset(mnist_size, mnist_batch_size, cifar_size, cifar_batch_size,):
""" load mnist and cifar10 dataset to shuffle.
Args:
mnist_size: mnist dataset size.
mnist_batch_size: every train dataset of mnist.
cifar_size: cifar10 dataset size.
cifar_batch_size: every train dataset of cifar10.
Returns:
mnist dataset, cifar10 dataset
"""
# load mnist data
(mnist_train_images, mnist_train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
# load cifar10 data
(cifar_train_images, cifar_train_labels), (_, _) = tf.keras.datasets.cifar10.load_data()
mnist_train_images = mnist_train_images.reshape(mnist_train_images.shape[0], 28, 28, 1).astype('float32')
mnist_train_images = (mnist_train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
cifar_train_images = cifar_train_images.reshape(cifar_train_images.shape[0], 32, 32, 3).astype('float32')
cifar_train_images = (cifar_train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
# Batch and shuffle the data
mnist_train_dataset = tf.data.Dataset.from_tensor_slices(mnist_train_images)
mnist_train_dataset = mnist_train_dataset.shuffle(mnist_size).batch(mnist_batch_size)
cifar_train_dataset = tf.data.Dataset.from_tensor_slices(cifar_train_images)
cifar_train_dataset = cifar_train_dataset.shuffle(cifar_size).batch(cifar_batch_size)
return mnist_train_dataset, cifar_train_dataset
3 DeOldify 框架
本项目中用到的上色就用到了DeOldify 框架,DeOldify 创建的目的是为了给黑白照片上色,但让人惊艳的是它除了能处理图片外,也可以处理视频;
DeOldify 的核心网络框架是 GAN ,对比以前上色技术有以下几个特点:
- 1,老照片中的伪影在上色过程中会被消除;
- 2,老照片的人脸部位来说,处理后皮肤会变得更光滑;
- 3,呈现更详细、真实的渲染效果;
实现过程
准备好权重文件
相关代码
#部分代码
def deoldify(self,img,render_factor=35):
"""
风格化
"""
# 转换通道
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
pil_img = Image.fromarray(img)
# 渲染彩图
color_img = self.deoldify_model.filter(
pil_img, pil_img, render_factor=render_factor,post_process=True
)
color_img = np.asarray(color_img)
color_img = cv2.cvtColor(color_img, cv2.COLOR_RGB2BGR)
# 转为numpy图
print('deoldify 转换成功')
return np.asarray(color_img)
实现效果:


4 First Order Motion Model
First Order Motion model的任务是image
animation,给定一张源图片,给定一个驱动视频,生成一段视频,其中主角是源图片,动作是驱动视频中的动作,源图像通常包含一个主体,驱动视频包含一系列动作。
通俗来说,First Order
Motion能够将给定的驱动视频中的人物A的动作迁移至给定的源图片中的人物B身上,生成全新的以人物B的脸演绎人物A的表情的视频。
以人脸表情迁移为例,给定一个源人物,给定一个驱动视频,可以生成一个视频,其中主体是源人物,视频中源人物的表情是由驱动视频中的表情所确定的。通常情况下,我们需要对源人物进行人脸关键点标注、进行表情迁移的模型训练。
基本框架
first-order 的算法框架如下图所示,主要包括三个部分的网络,keyporint detector
检测图像中的关键点,以及每个关键点对应的jaccobian矩阵;dense motion network 基于前面的结果生成最终的transform map
以及occulation map;使用transform map 和 occulation map 对编码后的source feature
做变换和mask处理,再decoder 生成出最终的结果。
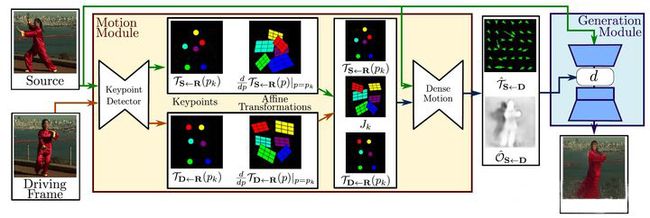
本项目相关代码
def FOM_video(self,driving_video,source_image,result_video):
# 读取图片
source_image = imageio.imread(source_image)
# 读取视频
reader = imageio.get_reader(driving_video)
fps = reader.get_meta_data()['fps']
driving_video = []
try:
for im in reader:
driving_video.append(im)
except RuntimeError:
pass
reader.close()
# 预处理
source_image = resize(source_image, (255, 255))[..., :3]
driving_video = [resize(frame, (255, 255))[..., :3] for frame in driving_video]
# 推理
predictions = self.make_animation(source_image, driving_video, self.fom_generator, self.fom_kp_detector, relative=True, adapt_movement_scale=True, cpu=True)
# 保存
imageio.mimsave(result_video, [img_as_ubyte(frame) for frame in predictions], fps=fps)
driving_video = './images/test2.mp4'
source_image = './images/out2.jpg'
result_video = './putput/result.mp4'
# 图像动起来
gan.FOM_video(driving_video, source_image,result_video)
运行如下命令,实现表情动作迁移。其中,各参数的具体使用说明如下:
- driving_video: 驱动视频,视频中人物的表情动作作为待迁移的对象。本项目中驱动视频路径为 “work/driving_video.MOV”,大家可以上传自己准备的视频,更换
driving_video参数对应的路径; - source_image: 原始图片,视频中人物的表情动作将迁移到该原始图片中的人物上。这里原始图片路径使用 “work/image.jpeg”,大家可以使用自己准备的图片,更换
source_image参数对应的路径; - relative: 指示程序中使用视频和图片中人物关键点的相对坐标还是绝对坐标,建议使用相对坐标,若使用绝对坐标,会导致迁移后人物扭曲变形;
- adapt_scale: 根据关键点凸包自适应运动尺度;
- ratio: 针对多人脸,将框出来的人脸贴回原图时的区域占宽高的比例,默认为0.4,范围为【0.4,0.5】
命令运行成功后会在ouput文件夹生成名为result.mp4的视频文件,该文件即为动作迁移后的视频。
实现效果:
,若使用绝对坐标,会导致迁移后人物扭曲变形;
- adapt_scale: 根据关键点凸包自适应运动尺度;
- ratio: 针对多人脸,将框出来的人脸贴回原图时的区域占宽高的比例,默认为0.4,范围为【0.4,0.5】
命令运行成功后会在ouput文件夹生成名为result.mp4的视频文件,该文件即为动作迁移后的视频。
实现效果:
5 最后
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate