C++ PrimerPlus 复习 第四章 复合类型(下)
第一章 命令编译链接文件 make文件
第二章 进入c++
第三章 处理数据
第四章 复合类型 (上)
第四章 复合类型 (下)
文章目录
- 创建和使用指针;
-
- 声明初始化指针
- 指针的危险
- 使用new和delete管理动态内存;
-
- 使用delete释放内存
- 使用new来创建动态数组;
-
- 指针小结
- 创建动态结构;
- 自动存储、静态存储和动态存储;
- vector和array类简介。
- 问答区
-
- 如何将数字地址传给指针?
- new和malloc的区别 与普通指针?
- 静态联编和动态联编的区别
- 有数组a,a和&a的区别?
- Q1: 数组、vector对象和array对象有哪些共同点和不同点?
- Q2: 如何处理数组、vector对象和array对象的超界错误?
- Q3: 如何将一个array对象赋给另一个array对象?
解决问题
如何将数字地址传给指针?
new和malloc的区别 与普通指针?
静态联编和动态联编的区别
有数组a,a和&a的区别?
Q1: 数组、vector对象和array对象有哪些共同点和不同点?
Q2: 如何处理数组、vector对象和array对象的超界错误?
Q3: 如何将一个array对象赋给另一个array对象?
前面讲了很多复合类型,现在来看看指针这种复合类型
创建和使用指针;
指针我简单总结就是一种来存储地址的符号类型
比如 int * pe; 是说pe来存储int类型的地址
何找到常规变量的地址。只需对变量应用地址运算符(&)
下面这个图就说明了
jumbo == *pe
&jumbo == pe

指针图解
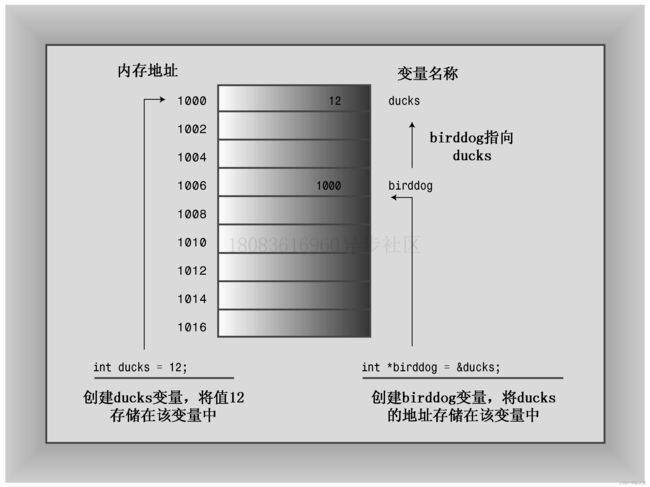
声明初始化指针
运算符两边的空格是可选的。传统上,C程序员使用这种格式,这强调ptr是一个int类型的值:
== int *ptr;==
而很多C++程序员使用这种格式,强调ptr是一个int的指针:
int* ptr;
但要知道的是,下面的声明创建一个指针(p1)和一个int变量(p2):
int* p1, p2;
对每个指针变量名,都需要使用一个*。
指针的危险
long * fellow; // create a pointer-to-long
*fellow = 223323; // place a value in never-never land
fellow确实是一个指针,但它指向哪里呢?上述代码没有将地址赋给fellow。
那么223323将被放在哪里呢?我们不知道。由于fellow没有被初始化,它可能有任何值。
不管值是什么,程序都将它解释为存储223323的地址。
如果fellow的值碰巧为1200,计算机将把数据放在地址1200上,即使这恰巧是程序代码的地址。fellow指向的地方很可能并不是所要存储223323的地方。
这种错误可能会导致一些最隐匿、最难以跟踪的bug。
一定要在对指针应用解除引用运算符(*)之前,将指针初始化为一个确定的、适当的地址。这是关于使用指针的金科玉律。
下面两个代码的区别
int * pt;
pt = 0xB8000000; // type mismatch
int * pt;
pt = (int *) 0xB8000000; // types now match
使用new和delete管理动态内存;
new指定分配内存的通用格式如下:
typeName * pointer_name = new typeName;
指针真正的用武之地在于,在运行阶段分配未命名的内存以存储值。
在这种情况下,只能通过指针来访问内存。
在C语言中,可以用库函数malloc()来分配内存;在C++中仍然可以这样做,但C++还有更好的方法——new运算符。
malloc()
int * arr = (int *)malloc(sizeof(int));
int *arr:声明了一个指向整数的指针变量arr。sizeof(int):计算出存储一个int类型所需的字节大小。malloc(sizeof(int)):调用malloc函数,尝试从堆(一种程序可用的内存区域)中分配出足够存储一个int的内存空间。如果成功,该函数将返回新分配的内存区域的地址;如果失败,例如因为堆中没有足够的空闲内存,那么它将返回NULL。(int *)malloc(sizeof(int)):将malloc函数返回的地址强制转换为int型指针。虽然在C中这一步并不是必须的,因为void指针会自动转换为其他类型的指针,但在C++中这一步是必要的,因为C++不允许这样的自动转换。int * arr = (int *)malloc(sizeof(int));:将新分配的内存地址赋值给arr。此后,我们就可以通过arr来使用这块内存了。
总的来说,这行代码的作用是申请一块可以存放一个int类型数据的内存,并且把这块内存的地址赋值给指针变量arr。
需要注意的是,使用malloc函数动态申请的内存,在用完后需要手动释放,否则会导致内存泄露。在C和C++中,我们可以使用free函数来释放这块内存,比如
free(arr);。
new
int * pn = new int;
这行代码使用C++的new操作符动态分配内存。具体来说:
int *pn:声明一个指向整数的指针pn。new int:new操作符会在堆中为一个int分配足够的内存,并返回该内存区域的地址。如果分配成功,这个地址就是一个有效的内存地址;如果分配失败(例如堆内存不足),则会抛出std::bad_alloc异常。int *pn = new int:将分配的内存地址赋给pn。
这行代码与C语言中的int *pn = (int *)malloc(sizeof(int))类似,但有一些重要的区别。
new不仅分配内存,还会调用对象的构造函数(对于基本类型如int,这没有实际效果)。new在无法分配内存时会抛出异常,而malloc则返回NULL。new分配的内存需要使用delete来释放,比如delete pn;,而不能用free()函数。
int *pn = new int;这行代码是在堆中分配一个int大小的内存,并将该内存的地址赋值给指针pn。
int higgens;
int * pt = &higgens;
这是原来的方法,有两种方法访问,指针(*pt)和变量名(higgens)来访问值
现在
int * pn = new int;
只能通过该指针进行访问
使用delete释放内存
在C++中,delete是一个运算符,用于释放在堆(heap)上分配的内存。当你使用new运算符创建对象或数组时,它会在堆区域分配必要的内存空间。
C++不会自动管理这些内存,如果你不手动释放,就会导致内存泄漏,降低程序的性能。
基本的使用方法:
-
释放单个对象的内存:首先,你需要通过
new运算符创建一个对象,例如int* ptr = new int;,然后你可以通过delete ptr;来释放指向这个对象的指针所占用的内存。 -
释放对象数组的内存:假设你已经创建了一个动态数组,例如
int* arr = new int[10];,你可以使用delete[] arr;来释放整个数组的内存。
需要注意的是,一旦使用 delete 或 delete[] 运算符释放了内存,相关的指针就变成了悬挂指针,不应再被使用。为了避免这种情况,通常将指针设置为nullptr,对空指针使用delete是安全的。
使用delete的关键在于,将它用于new分配的内存
int * ps = new int; // allocate memory
int * pq = ps; // set second pointer to same block
delete pq; // delete with second pointer
int * pq = ps;:这是创建了一个新的指针pq,并将其值设为ps的值,也就是说, pq现在指向的是与ps同样的内存地址。
delete pq;:这是释放pq指向的内存块。因为pq和ps都指向同一个内存块,所以这会影响到ps。
请注意,虽然delete pq;已经释放了那块内存,但ps还是持有着那个已经被释放的内存地址。
这就是所谓的“悬挂指针”。此时,通过ps访问那块内存可能会导致未定义行为。
此外,尝试删除非
new分配的内存,或者多次删除同一块内存,都会导致未定义的行为,需要特别小心避免这类错误发生。
一般来说,不要创建两个指向同一个内存块的指针,因为这将增加错误地删除同一个内存块两次的可能性。
总之,使用new和delete时,应遵守以下规则。
- 不要使用delete来释放不是new分配的内存。
- 不要使用delete释放同一个内存块两次。
- 如果使用new [ ]为数组分配内存,则应使用delete [ ]来释放。
- 如果使用new为一个实体分配内存,则应使用delete(没有方括号)来释放。
- 对空指针应用delete是安全的。
使用new来创建动态数组;
在C++语言中,使用new运算符可以动态分配内存,用来创建动态数组。下面是一个基本的示例:
int* arr;
arr = new int[10]; //动态创建了包含10个整数的数组
在以上代码中,首先定义了一个指向int类型的指针变量arr,然后使用new运算符为这个数组分配了足够存储10个int类型数据的空间。这里的10可以被任何非负整数常量或变量替换。
你可以像使用普通数组一样使用这个动态数组:
for(int i = 0; i < 10; i++)
arr[i] = i;
for(int i = 0; i < 10; i++)
cout << arr[i] << " ";
stacks[1]。
C++编译器将该表达式看作是*(stacks + 1),这意味着先计算数组第2个元素的地址,然后找到存储在那里的值。
最后的结果便是stacks [1]的含义
(运算符优先级要求使用括号,如果不使用括号,将给*stacks加1,而不是给stacks加1)。
也可以这样使用
// arraynew.cpp -- using the new operator for arrays
#include 下面的代码行指出了数组名和指针之间的根本差别:
p3 = p3 + 1; // okay for pointers, wrong for array names

将指针变量加1后,其增加的值等于指向的类型占用的字节数。
当不再需要使用动态分配的内存时,应该使用delete运算符释放它们,以避免内存泄漏:
delete[] arr;
此外,对于创建动态二维数组,也可以使用new运算符,其具体操作稍微复杂一些,如以下示例代码所示:
int** arr;
arr = new int*[5];
for(int i = 0; i < 5; i++)
arr[i] = new int[4]; //创建了5行4列的动态二维数组
同样的,删除动态二维数组时要对每一维进行释放:
for(int i = 0; i < 5; i++)
delete[] arr[i];
delete[] arr;
指针小结
声明指针
要声明指向特定类型的指针,请使用下面的格式:
typeName * pointerName;
给指针赋值
应将内存地址赋给指针。
可以对变量名应用&运算符,来获得被命名的内存的地址,new运算符返回未命名的内存的地址。
对指针解除引用
对指针解除引用意味着获得指针指向的值。对指针应用解除引用或间接值运算符(*)来解除引用。
区分指针和指针所指向的值
如果pt是指向int的指针,则*pt不是指向int的指针,而是完全等同于一个int类型的变量。pt才是指针。
数组名
多数情况下,C++将数组名视为数组的第1个元素的地址。
一种例外情况是,将sizeof运算符用于数组名用时,此时将返回整个数组的长度(单位为字节)
指针算术
C++允许将指针和整数相加。加1的结果等于原来的地址值加上指向的对象占用的总字节数。还可以将一个指针减去另一个指针,获得两个指针的差。后一种运算将得到一个整数,仅当两个指针指向同一个数组(也可以指向超出结尾的一个位置)时,这种运算才有意义;这将得到两个元素的间隔。
数组的动态联编和静态联编
使用数组声明来创建数组时,将采用静态联编,即数组的长度在编译时设置
使用new[ ]运算符创建数组时,将采用动态联编(动态数组),即将在运行时为数组分配空间,其长度也将在运行时设置。使用完这种数组后,应使用delete [ ]释放其占用的内存
数组表示法和指针表示法
使用方括号数组表示法等同于对指针解除引用:
tacos[0] means *tacos means the value at address tacos
tacos[3] means *(tacos + 3) means the value at address tacos + 3
指针和字符串
创建动态结构;

将new用于结构由两步组成:创建结构和访问其成员。例如,要创建一个未命名的inflatable类型,并将其地址赋给一个指针,可以这样做:
要创建结构,需要同时使用结构类型和new
inflatable * ps = new inflatable;
访问其成员
结构标识符是结构名,则使用句点运算符;
如果标识符是指向结构的指针,则使用箭头运算符。
书上的列子
// newstrct.cpp -- using new with a structure
#include
struct inflatable // structure definition
{
char name[20];
float volume;
double price;
};
int main()
{
using namespace std;
inflatable * ps = new inflatable; // allot memory for structure
cout << "Enter name of inflatable item: ";
cin.get(ps->name, 20); // method 1 for member access
cout << "Enter volume in cubic feet: ";
cin >> (*ps).volume; // method 2 for member access
cout << "Enter price: $";
cin >> ps->price;
cout << "Name: " << (*ps).name << endl; // method 2
cout << "Volume: " << ps->volume << " cubic feet\n"; // method 1
cout << "Price: $" << ps->price << endl; // method 1
delete ps; // free memory used by structure
return 0;
}
问题:
Q1:如何创建指向结构的指针并设置其值?
A1:可以通过以下代码创建指向结构的指针并设置其值:
antarctica_years_end * pa = &s02;
pa->year = 1999;
Q2:如何创建一个结构数组并设置其元素的值?
A2:可以通过以下代码创建一个结构数组并设置其元素的值:
antarctica_years_end trio[3]; // 创建结构数组
trio[0].year = 2003; // 设置元素的值
Q3:在声明了一个指向结构的指针数组后,如何访问元素的值?
A3:可以通过间接成员运算符来访问元素的值,例如:
std::cout << arp[1]->year << std::endl;
自动存储、静态存储和动态存储;
-
自动存储:在函数内部定义的常规变量使用自动存储空间,被称为自动变量(automatic variable),这意味着它们在所属的函数被调用时自动产生,在该函数结束时消亡。自动变量是一个局部变量,其作用域为包含它的代码块。
-
静态存储:静态存储是整个程序执行期间都存在的存储方式。使变量成为静态的方式有两种:一种是在函数外面定义它;另一种是在声明变量时使用关键字static。自动存储和静态存储的关键在于:这些方法严格地限制了变量的寿命。
-
动态存储:new和delete运算符提供了一种比自动变量和静态变量更灵活的方法。它们管理了一个内存池,这在C++中被称为自由存储空间(free store)或堆(heap)。
以下是几个重要的问题:
-
自动存储空间是如何工作的?
- 自动存储空间主要用于函数内部的变量存储。这些被称为自动变量,它们在所属的函数被调用时自动创建,在函数结束时自动销毁。自动变量通常存储在栈中,以后进先出(LIFO)的方式管理。
-
如何使一个变量成为静态的?
- 在C++中,可以通过两种方式使变量成为静态:一种是在函数外部定义变量;另一种是在声明变量时使用关键字static,例如:
static int a;
- 在C++中,可以通过两种方式使变量成为静态:一种是在函数外部定义变量;另一种是在声明变量时使用关键字static,例如:
-
new和delete在动态存储中起到什么作用?
new和delete用于动态内存管理。new用于在堆(也称为自由存储区)上动态分配内存,delete则负责释放那些不再需要的内存。这种方法允许在运行时根据需要分配或释放内存,提供了更大的灵活性。
-
什么情况下会发生内存泄漏,以及如何避免内存泄漏?
- 内存泄露通常发生在程序员使用
new分配了内存,但忘记使用delete释放的情况下。为了防止内存泄漏,需要保证每次使用new分配内存后,一定要在适当的地方使用delete进行释放。此外,C++提供了智能指针(如unique_ptr, shared_ptr等)来自动管理内存,这是防止内存泄露的有效方法。
- 内存泄露通常发生在程序员使用
-
为什么使用指针可能会危险,以及如何正确使用指针?
- 使用指针可能会危险,因为它们可以引用任意内存地址,这可能导致访问或修改不应被访问或修改的内存区域。例如,未初始化的指针可能指向随机内存地址,解引用此类指针将产生未定义行为。另一个危险是“悬挂指针”,即指向已被释放内存的指针。为了安全使用指针,必须确保:始终初始化指针;不要解引用空指针;不要解引用已删除的对象的指针;当内存不再需要时,确保释放分配给指针的内存。
vector和array类简介。
Vector重要信息:
-
vector是一种动态数组,可以在运行阶段设置vector对象的长度,可在末尾附加新数据,也可在中间插入新数据。它使用new和delete来管理内存,但这种工作是自动完成的。 -
要使用
vector对象,必须包含头文件vector,并且vector包含在名称空间std中。 -
vector使用不同的语法来指出它存储的数据类型。例如:vector创建一个存储整数的vi vector对象。 -
vector类使用不同的语法来指定元素数。例如:vector创建一个可以存储n个双精度浮点数的vd(n) vector对象。
重要问题及答案:
-
问题:
vector是什么?答案:
vector是一种动态数组,可以在运行阶段设置vector对象的长度,可在末尾附加新数据,也可在中间插入新数据。它使用new和delete来管理内存,但这种工作是自动完成的。 -
问题:如何创建一个
vector对象?答案:首先,需要包含头文件
vector,然后声明一个vector对象,如vector表示创建一个存储整数的vi vector对象。 -
问题:如何指定
vector对象的元素数?答案:在声明
vector对象时,可以在括号中指定元素数。例如:vector表示创建一个可以存储n个双精度浮点数的vd(n) vector对象。 -
问题:
vector对象的长度是否可以调整?答案:是的,
vector对象在插入或添加值时可以自动调整长度。
array重要概念总结:
-
C++11新增的模板类array:它位于std名称空间中。与普通数组一样,array对象的长度也是固定的,使用静态内存分配(栈),其效率与普通数组相同,但使用起来更加方便和安全。
-
创建array对象:首先需要包含头文件array。创建的语法与vector稍有不同,例如:
array -
初始化array对象:可以直接使用列表初始化,例如:
array
比较重要的问题:
-
Q: 如何在C++11中创建array对象?
A: 首先,需要包含头文件array,然后使用特定的语法创建array对象。例如,array创建了一个容量为5的整型array对象。 -
Q: 如何初始化array对象?
A: 可以直接使用列表初始化array对象。例如,array则创建并初始化了一个包含四个元素的double类型的array对象。 -
Q: array对象的内存分配方式是什么?
A: array对象使用的是静态内存分配,即在栈上进行内存分配。这使得它的效率与普通数组相同。 -
Q: array对象相比于普通数组有什么优点?
A: array对象相比于普通数组更加方便和安全。尽管它们的内存分配方式相同,都在栈上进行,但array对象提供了一些额外的功能,例如容易的列表初始化等。
分类总结:
-
数组,vector和array对象的共性:无论是数组、vector对象还是array对象,都可以使用标准数组表示法来访问各个元素。
-
存储位置不同:array对象和普通数组存储在相同的内存区域(即栈)中,而vector对象存储在另一个区域(自由存储区或堆)中。
-
赋值操作:可以将一个array/vector对象赋给另一个array/vector对象;而对于数组,必须逐元素复制数据。
-
超界错误:数组的行为不安全,C++不检查超界错误。然而,vector和array对象能够禁止这种行为,也就是说,可以使用成员函数at()在运行期间捕获非法索引。
重要问题及答案:
Q1: 数组、vector对象和array对象有哪些共同点和不同点?
A1: 共同点是它们都可以使用标准数组表示法来访问各个元素。不同点主要在于存储位置和超界错误处理上:array对象和普通数组存储在栈上,而vector对象存储在堆上。另外,数组不检查超界错误,而vector和array对象可以防止这种行为。
Q2: 如何处理数组、vector对象和array对象的超界错误?
A2: 对于数组,C++不会检查超界错误。而对于vector和array对象,可以使用成员函数at()在运行期间捕获非法索引。
Q3: 如何将一个array对象赋给另一个array对象?
A3: 对于array对象,可以直接进行赋值操作。例如:a4 = a3;。这种赋值操作只对相同大小的array对象有效。
问答区
如何将数字地址传给指针?
int * pt;
pt = (int *) 0xB8000000; // types now match
这样,赋值语句的两边都是整数的地址,因此这样赋值有效。
注意,pt是int值的地址并不意味着pt本身的类型是int。
new和malloc的区别 与普通指针?
首先,new不仅分配内存,还会调用对象的构造函数(对于基本类型如int,这没有实际效果)。
其次,new在无法分配内存时会抛出异常,而malloc则返回NULL。
最后,new分配的内存需要使用delete来释放,比如delete pn;,而不能用free()函数。
总的来说,int *pn = new int;这行代码是在堆中分配一个int大小的内存,并将该内存的地址赋值给指针pn。
与普通指针比的话,new只能通过该指针进行访问,普通的指针还有变量名
new分配的内存块通常与常规变量声明分配的内存块不同。
常规变量声明分配的内存块都存储在被称为栈(stack)的内存区域中
而new从被称为堆(heap)或自由存储区(free store)的内存区域分配内存。
静态联编和动态联编的区别
静态联编和动态联编各有其优缺点:
静态联编:
-
优点
- 效率高:在编译时就已经确定了数组的大小,系统不需要再在运行时进行分配和回收内存的操作,从而提高了程序的运行效率。
- 安全:由于数组的长度是固定的,所以在使用过程中不会出现越界的情况,这使得程序更加安全。
-
缺点
- 灵活性低:在编写程序时就已经确定了数组的大小,不能根据程序运行时的需要动态调整数组的大小。
- 资源浪费:如果声明的数组太大,而实际用到的只是其中一小部分,那么就会造成内存资源的浪费。
动态联编:
-
优点
- 灵活性高:可以根据程序运行时的需要动态地调整数组的大小,提高了内存利用率。
- 避免资源浪费:只需要为实际使用到的元素分配内存,避免了由于预先分配的数组过大而造成的内存资源浪费。
-
缺点
- 效率较低:需要在运行时进行内存分配和回收的操作,可能会降低程序的运行效率。
- 安全性较低:由于数组的长度可以动态调整,如果不正确地管理这种动态性,可能会出现访问越界等错误。
案例:
假设程序要读取1000个字符串,其中最大的字符串包含79个字符,而大多数字符串都短得多。
如果用char数组来存储这些字符串,则需要1000个数组,其中每个数组的长度为80个字符。
这总共需要80000个字节,而其中的很多内存没有被使用。
另一种方法是,创建一个数组,它包含1000个指向char的指针
然后使用new根据每个字符串的需要分配相应数量的内存。这将节省几万个字节。
是根据输入来分配内存,而不是为每个字符串使用一个大型数组。
另外,还可以使用new根据需要的指针数量来分配空间。
就目前而言,这有点不切实际,即使是使用1000个指针的数组也是这样
不过程序清单4.22还是演示了一些技巧。
另外,为演示delete是如何工作的,该程序还用它来释放内存以便能够重新使用。
// delete.cpp -- using the delete operator
#include
#include // or string.h
using namespace std;
char * getname(void); // function prototype
int main()
{
char * name; // create pointer but no storage
name = getname(); // assign address of string to name
cout << name << " at " << (int *) name << "\n";
delete [] name; // memory freed
name = getname(); // reuse freed memory
cout << name << " at " << (int *) name << "\n";
delete [] name; // memory freed again
return 0;
}
char * getname() // return pointer to new string
{
char temp[80]; // temporary storage
cout << "Enter last name: ";
cin >> temp;
char * pn = new char[strlen(temp) + 1];
strcpy(pn, temp); // copy string into smaller space
return pn; // temp lost when function ends
}
有数组a,a和&a的区别?
对数组取地址时,数组名也不会被解释为其地址。
等等,数组名难道不被解释为数组的地址吗?
不完全如此:数组名被解释为其第1个元素的地址,而对数组名应用地址运算符时,得到的是整个数组的地址:
short tell[10]; // tell an array of 20 bytes
cout << tell << endl; // displays &tell[0]
cout << &tell << endl; // displays address of whole array
从数字上说,这两个地址相同;
但从概念上说,&tell[0](即tell)是一个2字节内存块的地址,
而&tell是一个20字节内存块的地址。因此,表达式tell + 1将地址值加2,而表达式&tell + 1将地址加20。
换句话说,tell是一个short指针(short*),而&tell是一个这样的指针,即指向包含10个元素的short数组(short (*) [10])。
Q1: 数组、vector对象和array对象有哪些共同点和不同点?
A1: 共同点是它们都可以使用标准数组表示法来访问各个元素。
不同点主要在于存储位置和超界错误处理上:
array对象和普通数组存储在栈上,而vector对象存储在堆上。
另外,数组不检查超界错误,而vector和array对象可以防止这种行为。
Q2: 如何处理数组、vector对象和array对象的超界错误?
A2: 对于数组,C++不会检查超界错误。而对于vector和array对象,可以使用成员函数at()在运行期间捕获非法索引。
a2.at(1) = 2.3; // assign 2.3 to a2[1]
中括号表示法和成员函数at()的差别在于,使用at()时,将在运行期间捕获非法索引,而程序默认将中断。这种额外检查的代价是运行时间更长,这就是C++ 允许您使用任何一种表示法的原因所在。另外,这些类还让您能够降低意外超界错误的概率
Q3: 如何将一个array对象赋给另一个array对象?
A3: 对于array对象,可以直接进行赋值操作。例如:a4 = a3;。这种赋值操作只对相同大小的array对象有效。