prometheus:(二)监控概述
目录
一:监控系统概论
运维监控平台设计思路
二: prometheus基础资源监控
2.1网络监控
2.2存储监控
2.3服务器监控
2.4中间件监控
2.5应用程序监控(APM)
三:常用监控系统介绍
3.1 Cacti
3.2 Nagios
3.3 Zabbix
3.4 Prometheus
3.5 Open-falcon
四:prometheus和其它监控工具的对比
4.1 Prometheus vs Zabbix
4.2 Prometheus vs Graphite
4.3 Prometheus vs InfluxDB
4.4 Prometheus vs OpenTSDB
4.5 Prometheus vs Nagios
4.6 Prometheus vs Sensu
五:Prometheus能监控什么?
六:Prometheus对kubernetes的监控
七:Prometheus告警处理
7.1 Prometheus告警简介
7.2 Alertmanager特性
7.2.1分组
7.2.2抑制
7.2.3静默
八:总结
一:监控系统概论
监控系统在这里特指对数据中心的监控,主要针对数据中心内的硬件和软件进行监控和告警。企业的 IT 架构逐步从传统的物理服务器,迁移到以虚拟机为主导的 IaaS 云。无论基础架构如何调整,都离不开监控系统的支持。
不仅如此。越来越复杂的数据中心环境对监控系统提出了更越来越高的要求:需要监控不同的对象,例如容器,分布式存储,SDN网络,分布式系统。各种应用程序等,种类繁多,还需要采集和存储大量的监控数据,例如每天数TB数据的采集汇总。以及基于这些监控数据的智能分析,告警及预警等。
在每个企业的数据中心内,或多或少都会使用一些开源或者商业的监控系统。从监控对象的角度来看,可以将监控分为网络监控,存储监控,服务器监控和应用监控等,因为需要监控数据中心的各个方面。所以监控系统需要做到面面俱到,在数据中心中充当“天眼“角色。
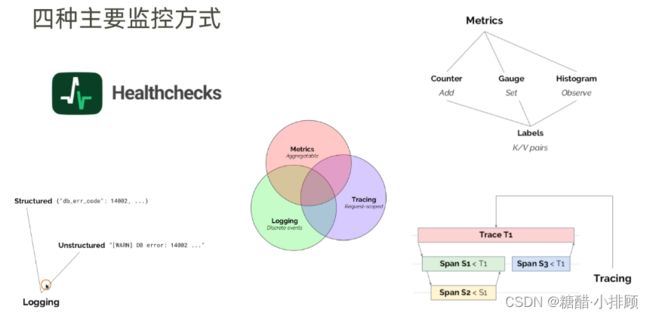
运维监控平台设计思路
- 数据收集模块
- 数据提取模块
- 监控告警模块
可以细化为6层
第六层:用户展示管理层 同一用户管理、集中监控、集中维护
第五层:告警事件生成层 实时记录告警事件、形成分析图表(趋势分析、可视化)
第四层:告警规则配置层 告警规则设置、告警伐值设置
第三层:数据提取层 定时采集数据到监控模块
第二层:数据展示层 数据生成曲线图展示(对时序数据的动态展示)
第一层:数据收集层 多渠道监控数据二: prometheus基础资源监控
2.1网络监控
网络性能监控:主要涉及网络监测,网络实时流量监控(网络延迟、访问量、成功率)和历史数据统计、汇总和历史数据分析等功能。
网络性能检测:主要针对内网或者外网的网络性能。如DDoS性能的。通过分析异常流量来确定网络性能行为。
设备监控:主要针对数据中心内的多种网络设备进行监控。包括路由器,防火墙和交换机等硬件设备,可以通过snmp等协议收集数据。
2.2存储监控
存储性能监控方面:存储通常监控块的读写速率,IOPS。读写延迟,磁盘用量等;文件存储通常监控文件系统inode。读写速度、目录权限等。
存储系统监控方面:不同的存储系统有不同的指标,例如,对于ceph存储需要监控OSD, MON的运行状态,各种状态pg的数量以及集群IOPS等信息。
存储设备监控方面:对于构建在x86服务器上的存储设备,设备监控通过每个存储节点上的采集器统一收集磁盘、SSD、网卡等设备信息;存储厂商以黑盒方式提供商业存储设备,通常自带监控功能,可监控设备的运行状态,性能和容量的。
2.3服务器监控
CPU:涉及整个 CPU 的使用量、用户态百分比、内核态百分比,每个 CPU 的使用量、等待队列长度、I/O 等待百分比、CPU 消耗最多的进程、上下文切换次数、缓存命中率等。
内存:涉及内存的使用量、剩余量、内存占用最高的进程、交换分区大小、缺页异常等。
网络 I/O:涉及每个网卡的上行流量、下行流量、网络延迟、丢包率等。
磁盘 I/O:涉及硬盘的读写速率、IOPS、磁盘用量、读写延迟等。
2.4中间件监控
消息中间件: RabbitMQ、Kafka
Web 服务中间件:Tomcat、Jetty
缓存中间件:Redis、Memcached
数据库中间件:MySQL、PostgreSQL
2.5应用程序监控(APM)
APM主要是针对应用程序的监控,包括应用程序的运行状态监控,性能监控,日志监控及调用链跟踪等。调用链跟踪是指追踪整个请求过程(从用户发送请求,通常指浏览器或者应用客户端)到后端API服务以及API服务和关联的中间件,或者其他组件之间的调用,构建出一个完整的调用拓扑结构,不仅如此,APM 还可以监控组件内部方法的调用层次(Controller-->service-->Dao)获取每个函数的执行耗时,从而为性能调优提供数据支撑。
应用程序监控工具除了有 Pinpoint,还有 Twitter 开源的 Zipkin,Apache SkyWalking,美团开源的 CAT等。
调用键监控:

三:常用监控系统介绍
3.1 Cacti
cacti(英文含义为仙人掌)是一套基于 PHP、MySQL、SNMP 和 RRDtool 开发的网络流量监测图形分析工具。它通过 snmpget 来获取数据,使用 RRDTool 绘图,但使用者无须了解 RRDTool 复杂的参数。它提供了非常强大的数据和用户管理功能,可以指定每一个用户能查看树状结构、主机设备以及任何一张图,还可以与 LDAP 结合进行用户认证,同时也能自定义模板,在历史数据的展示监控方面,其功能相当不错。
cacti 通过添加模板,使不同设备的监控添加具有可复用性,并且具备可自定义绘图的功能,具有强大的运算能力(数据的叠加功能)。
3.2 Nagios
Nagios 是一款开源的免费网络监视工具,能有效监控 windows、Linux 和 Unix 的主机状态,交换机路由器等网络设置打印机等。在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。
Nagios 主要的特征是监控告警,最强大的就是告警功能,可支持多种告警方式,但缺点是没有强大的数据收集机制,并且数据出图也很简陋,当监控的主机越来越多时,添加主机也非常麻烦,配置文件都是基于文本配置的,不支持 web 方式管理和配置,这样很容易出错,不宜维护。
3.3 Zabbix
abbix 是一个基于 web 界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。zabbix 能监视各种网络参数,保证服务器系统的安全运营;并提供强大的通知机制以让系统运维人员快速定位/解决存在的各种问题。
zabbix 由 2 部分构成,zabbix server 与可选组件 zabbix agent。zabbix server 可以通过 SNMP,zabbix agent,ping,端口监视等方法提供对远程服务器/网络状态的监视,数据收集等功能,它可以运行在 Linux,Solaris,HP-UX,ALX,Free BSD,open BSD,os x 等平台上。
zabbix 解决了 cacti 没有告警的不足,也解决了 nagios 不能通过 web 配置的缺点,同时还支持分布式部署,这使得它迅速流行起来,zabbix 也成为目前中小企业监控最流行的运维监控平台。当然,zabbix 也有不足之处,它消耗的资源比较多,如果监控的主机非常多时(服务器数量超过 500 台),可能会出现监控超时、告警超时、告警系统单点故障等现象,不过也有很多解决办法,比如提高硬件性能、改变 zabbix 监控模式、多套 zabbix 等。
监控方式:
- agent 代理:专门的代理服务方式进行监控,专属的协议,装有 zabbix-agent 的主机就可以被 zabbix-server 监控,主动或被动的方式,把数据给到 server 进行处理。
- ssh/telnet:linux 主机支持 ssh/telnet 协议
- snmp:网络设备路由器、交换机不能安装第三方程序(agent),使用简单网络协议。大多数的路由器设备支持 SNMP 协议。
- ipmi:通过 ipmi 接口进行监控,我们可以通过标准的 ipmi 硬件接口,监控被监控对象的物理特征,比如电压,温度,风扇状态电源情况,被广泛使用服务监控中,包括采集 cpu 温度,风扇转速,主板温度,及远程开关机等等,而且 ipmi 独立于硬件和操作系统,无论是 cpu,bios 还是 os 出现故障,都不会影响 ipmi 的工作,因为 ipmi 的硬件设备 BMC(bashboard management controller)是独立的板卡,独立供电。
zabbix核心组件介绍:
- zabbix server:zabbix 软件实现监控的核心程序,主要功能是与 zabbixproxies 和 agents 进行交互、触发器计算、发送告警通知;并将数据集中保存。与 prometheus 类似可以保存收集到的数据,但是 prometheus 告警需要使用 alter manager 组件。
- database storage:存储配置信息以及收集到的数据。
- web Interface:zabbix 的 GUI 接口,通常与 server 运行在同一台机器上。
- proxy:可选组件,常用于分布式监控环境中,一个帮助 zabbix server 收集数据,分担 zabbix server 的负载的程序。
- agent:部署在被监控主机上,负责收集数据发送给 server。
3.4 Prometheus
borg.kubernetes
borgmon(监控系统)对应克隆的版本:prometheus(go 语言开发)所以 prometheus 特别适合 K8S 的架构上。而作为一个数据监控解决方案,它由一个大型社区支持,有来自 700 多家公司的 6300 个贡献者,13500 个代码提交和 7200 个拉取请求。
prometheus具有以下特性:
- 多维的数据模型(基于时间序列的 Key-value 键值对)
- 灵活的查询和聚合语言 PromQL
- 提供本地存储和分布式存储
- 通过基于 HTTP 和 HTTPS 的 Pull 模型采集时间序列数据(pull 数据的推送,时间序列:每段时间点的数据值指标,持续性的产生。横轴标识时间,纵轴为数据值,一段时间内数值的动态变化,所有的点连线形成大盘式的折线图)
- 可利用 Pushgateway(Prometheus 的可选中间件)实现 Push 模式
- 可通过动态服务发现或静态配置发现目标机器(通过 consul 自动发现和收缩)
- 支持多种图表和数据大盘
3.5 Open-falcon
open-falcon 是小米开源的企业级监控工具,用 go 语言开发,包括小米、滴滴、美团等在内的互联网公司都在使用它,是一款灵活、可拓展并且高性能的监控方案。
运维监控-Open-Falcon介绍 - 尹正杰 - 博客园
PS:
Nightingale 是滴滴基础平台联合滴滴云研发和开源的企业级监控解决方案。旨在满足云原生时代企业级的监控需求。
Nightingale 在产品完成度、系统高可用、以及用户体验方面,达到了企业级的要求,可满足不同规模用户的场景,小到几台机器,大到数十万都可以完美支撑。兼顾云原生和裸金属,支持应用监控和系统监控,插件机制灵活,插件丰富完善,具有高度的灵活性和可扩展性。
Nightingale 是一款分布式高性能的运维监控系统,在 Open-Falcon 的基础上,各核心模块做了大幅优化,引入了滴滴的生产实践经验结合滴滴内部的最佳实践,在性能、可维护性、易用性方面做了大量的改进, 作为集团统一的监控解决方案,支撑了滴滴内部数十亿监控指标,覆盖了从系统、容器、到应用等各层面的监控需求,周活跃用户数千。五年磨一剑,取之开源,回馈开源。夜莺 Fork 自 Open-Falcon,可以把夜莺看做是 Open-Falcon 的下一代。
https://cloud.tencent.com/developer/article/1638839?from=15425
四:prometheus和其它监控工具的对比
4.1 Prometheus vs Zabbix
- Zabbix 使用的是 C 和 PHP, Prometheus 使用 Golang, 整体而言 Prometheus 运行速度更快一点。
- Zabbix 属于传统主机监控,主要用于物理主机,交换机,网络等监控,Prometheus 不仅适用主机监控,还适用于 Cloud, SaaS, Openstack,Container 监控。
- Zabbix 在传统主机监控方面,有更丰富的插件。
- Zabbix 可以在 WebGui 中配置很多事情,但是 Prometheus 需要手动修改文件配置。
4.2 Prometheus vs Graphite
- Graphite功能较少,它专注于两件事,存储时序数据, 可视化数据,其他功能需要安装相关插件,而 Prometheus 属于一站式,提供告警和趋势分析的常见功能,它提供更强的数据存储和查询能力。
- 在水平扩展方案以及数据存储周期上,Graphite 做的更好。
4.3 Prometheus vs InfluxDB
- InfluxDB 是一个开源的时序数据库,主要用于存储数据,如果想搭建监控告警系统, 需要依赖其他系统。
- InfluxDB 在存储水平扩展以及高可用方面做的更好, 毕竟核心是数据库。
4.4 Prometheus vs OpenTSDB
- OpenTSDB 是一个分布式时序数据库,它依赖 Hadoop 和 HBase,能存储更长久数据, 如果你系统已经运行了 Hadoop 和 HBase, 它是个不错的选择。
- 如果想搭建监控告警系统,OpenTSDB 需要依赖其他系统。
4.5 Prometheus vs Nagios
- Nagios 数据不支持自定义 Labels, 不支持查询,告警也不支持去噪,分组, 没有数据存储,如果想查询历史状态,需要安装插件。
- Nagios 是上世纪 90 年代的监控系统,比较适合小集群或静态系统的监控,显然 Nagios 太古老了,很多特性都没有,相比之下Prometheus 要优秀很多。
4.6 Prometheus vs Sensu
- Sensu广义上讲是 Nagios 的升级版本,它解决了很多 Nagios 的问题,如果你对 Nagios 很熟悉,使用 Sensu 是个不错的选择。
- Sensu 依赖 RabbitMQ 和 Redis,数据存储上扩展性更好。
五:Prometheus能监控什么?
# Databases---数据库
Aerospike exporter
ClickHouse exporter
Consul exporter (official)
Couchbase exporter
CouchDB exporter
ElasticSearch exporter
EventStore exporter
Memcached exporter (official)
MongoDB exporter
MSSQL server exporter
MySQL server exporter (official)
OpenTSDB Exporter
Oracle DB Exporter
PgBouncer exporter
PostgreSQL exporter
ProxySQL exporter
RavenDB exporter
Redis exporter
RethinkDB exporter
SQL exporter
Tarantool metric library
Twemproxy
# Hardware related---硬件相关
apcupsd exporter
Collins exporter
IBM Z HMC exporter
IoT Edison exporter
IPMI exporter
knxd exporter
Netgear Cable Modem Exporter
Node/system metrics exporter (official)
NVIDIA GPU exporter
ProSAFE exporter
Ubiquiti UniFi exporter
# Messaging systems---消息服务
Beanstalkd exporter
Gearman exporter
Kafka exporter
NATS exporter
NSQ exporter
Mirth Connect exporter
MQTT blackbox exporter
RabbitMQ exporter
RabbitMQ Management Plugin exporter
# Storage---存储
Ceph exporter
Ceph RADOSGW exporter
Gluster exporter
Hadoop HDFS FSImage exporter
Lustre exporter
ScaleIO exporter
# HTTP---网站服务
Apache exporter
HAProxy exporter (official)
Nginx metric library
Nginx VTS exporter
Passenger exporter
Squid exporter
Tinyproxy exporter
Varnish exporter
WebDriver exporter
# APIs
AWS ECS exporter
AWS Health exporter
AWS SQS exporter
Cloudflare exporter
DigitalOcean exporter
Docker Cloud exporter
Docker Hub exporter
GitHub exporter
InstaClustr exporter
Mozilla Observatory exporter
OpenWeatherMap exporter
Pagespeed exporter
Rancher exporter
Speedtest exporter
# Logging---日志
Fluentd exporter
Google's mtail log data extractor
Grok exporter
# Other monitoring systems
Akamai Cloudmonitor exporter
Alibaba Cloudmonitor exporter
AWS CloudWatch exporter (official)
Cloud Foundry Firehose exporter
Collectd exporter (official)
Google Stackdriver exporter
Graphite exporter (official)
Heka dashboard exporter
Heka exporter
InfluxDB exporter (official)
JavaMelody exporter
JMX exporter (official)
Munin exporter
Nagios / Naemon exporter
New Relic exporter
NRPE exporter
Osquery exporter
OTC CloudEye exporter
Pingdom exporter
scollector exporter
Sensu exporter
SNMP exporter (official)
StatsD exporter (official)
# Miscellaneous---其他
ACT Fibernet Exporter
Bamboo exporter
BIG-IP exporter
BIND exporter
Bitbucket exporter
Blackbox exporter (official)
BOSH exporter
cAdvisor
Cachet exporter
ccache exporter
Confluence exporter
Dovecot exporter
eBPF exporter
Ethereum Client exporter
Jenkins exporter
JIRA exporter
Kannel exporter
Kemp LoadBalancer exporter
Kibana Exporter
Meteor JS web framework exporter
Minecraft exporter module
PHP-FPM exporter
PowerDNS exporter
Presto exporter
Process exporter
rTorrent exporter
SABnzbd exporter
Script exporter
Shield exporter
SMTP/Maildir MDA blackbox prober
SoftEther exporter
Transmission exporter
Unbound exporter
Xen exporter
# Software exposing Prometheus metrics---Prometheus度量指标
App Connect Enterprise
Ballerina
Ceph
Collectd
Concourse
CRG Roller Derby Scoreboard (direct)
Docker Daemon
Doorman (direct)
Etcd (direct)
Flink
FreeBSD Kernel
Grafana
JavaMelody
Kubernetes (direct)
Linkerd
六:Prometheus对kubernetes的监控
对于Kubernetes而言,我们可以把当中所有的资源分为几类:
- 基础设施层(Node):集群节点,为整个集群和应用提供运行时资源
- 容器基础设施(Container):为应用提供运行时环境
- 用户应用(Pod):Pod中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能
- 内部服务负载均衡(Service):在集群内,通过Service在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡
- 外部访问入口(Ingress):通过Ingress提供集群外的访问入口,从而可以使外部客户端能够访问到部署在Kubernetes集群内的服务
因此,如果要构建一个完整的监控体系,我们应该考虑,以下5个方面:
- 集群节点状态监控:从集群中各节点的kubelet服务获取节点的基本运行状态;
- 集群节点资源用量监控:通过Daemonset的形式在集群中各个节点部署Node Exporter采集节点的资源使用情况;
- 节点中运行的容器监控:通过各个节点中kubelet内置的cAdvisor中获取个节点中所有容器的运行状态和资源使用情况;
- 如果在集群中部署的应用程序本身内置了对Prometheus的监控支持,那么我们还应该找到相应的Pod实例,并从该Pod实例中获取其内部运行状态的监控指标。
- 对k8s本身的组件做监控:apiserver、scheduler、controller-manager、kubelet、kube-proxy
七:Prometheus告警处理
7.1 Prometheus告警简介
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。

在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
- 在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方,Prometheus内置了对邮件,Slack等多种通知方式的支持,同时还支持与Webhook的集成,以支持更多定制化的场景。例如,目前Alertmanager还不支持钉钉,那用户完全可以通过Webhook与钉钉机器人进行集成,从而通过钉钉接收告警信息。同时AlertManager还提供了静默和告警抑制机制来对告警通知行为进行优化。
7.2 Alertmanager特性
Alertmanager除了提供基本的告警通知能力以外,还主要提供了如:分组、抑制以及静默等告警特性:

7.2.1分组
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
例如,当集群中有数百个正在运行的服务实例,并且为每一个实例设置了告警规则。假如此时发生了网络故障,可能导致大量的服务实例无法连接到数据库,结果就会有数百个告警被发送到Alertmanager。
而作为用户,可能只希望能够在一个通知中中就能查看哪些服务实例收到影响。这时可以按照服务所在集群或者告警名称对告警进行分组,而将这些告警内聚在一起成为一个通知。
告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置。
7.2.2抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。
抑制机制同样通过Alertmanager的配置文件进行设置。
7.2.3静默
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
静默设置需要在Alertmanager的Werb页面上进行设置。
八:总结
Prometheus 属于一站式监控告警平台,依赖少,功能齐全。
Prometheus 支持对云或容器的监控,其他系统主要对主机监控。
Prometheus 数据查询语句表现力更强大,内置更强大的统计函数。
Prometheus 在数据存储扩展性以及持久性上没有 InfluxDB,OpenTSDB,Sensu 好。