A Mathematical Framework for Transformer Circuits—(二)
A Mathematical Framework for Transformer Circuits
- Zero-Layer Transformers
- One-Layer Attention-Only Transformers
-
- The Path Expansion Trick
- Splitting Attention Head terms into Query-Key and Output-Value Circuits
-
- OV和QK的独立性(冻结attention模式技巧)
- Interpretation as Skip-Trigrams
-
- 复制/原始的上下文学习
- OTHER INTERESTING SKIP-TRIGRAMS
- PRIMARILY POSITIONAL ATTENTION HEADS
- SKIP-TRIGRAM "BUGS"
- Summarizing OV/QK Matrices
-
- 检测复制行为
- Do We "Fully Understand" One-Layer Models?
Zero-Layer Transformers
接上集
在转向更复杂的模型之前,简要考虑一下“zero-layer”变压器是有用的。zero-layer模型以token为输入,对其进行嵌入、去嵌入处理,以此生成用于预测下一个token的logits:
T = W U W E T=W_UW_E T=WUWE
因为模型无法从其它tokens中移动信息,所以作者仅从当前token预测下一个token。这意味着 W U W E W_UW_E WUWE的最优行为是模拟二元对数似然。
这与2014年Levy & Goldberg的观察结果类似,即许多初始阶段产生的词嵌入可以看作是一个对数似然矩阵的矩阵分解。
上述内容与更普遍的Transformer有关。 W U W E W_UW_E WUWE形式的计算项将出现在每个transformer的扩展形式的方程中,与“直接路径”对应。在“直接路径”中,一个token embedding直接沿着residual stream向下流动至unembedding【token embedding经过计算生成token unembedding】,而不经过任何层。它唯一能影响的是二元对数似然。由于模型的其它部分将预测二元对数似然的某些部分,所以 W U W E W_UW_E WUWE不会精确地表示较大模型中的二元统计,但是它确实表示一种“残差”(“residual”)。特别是, 计算项 W U W E W_UW_E WUWE似乎通常有助于表示没有被更通用的语法规则描述的二元统计,例如,“Barack”后面经常出现“Obama”。
One-Layer Attention-Only Transformers
One-Layer attention-only transformers可以理解为一个二元模型和几个“skip-trigram”模型的一种集合(影响序列“A…BC”的概率)。直观地说,这是因为每个注意力能够选择性地从当前token(“B”)关注到前一个token(“A”),并且从前一个token(“A”)复制信息用以调整可能出现的下一个token(“C”)的概率。
本节的主要目的是严格的展示这种对应关系,并演示如何将一个transformer的原始权重转换为可解释的skip-trigram概率调整表。
The Path Expansion Trick
one-layer attention-only transformer由一个token embedding,attention layer(该层独立地使用attention heads),以及一个unembedding按序组成:

利用张量符号和之前推导出的attention heads的可替代表示,将transformer表示为一个三项式的乘积。

扩展路径的关键技巧是以一种简单的方式来扩展乘积。扩展方式是将乘积(图2公式中每个term对应图2中的一个层)转换为求和,即每个term对应一条端到端路径。如下图所示。
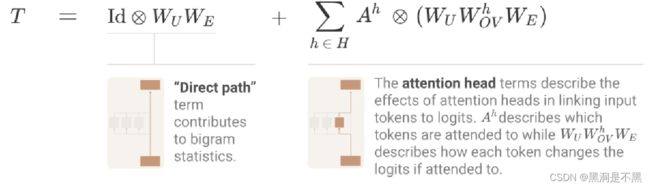
作者认为这种端到端路径中的每个term都易于理解,并且每个term都可以独立地被推理出来,此外还可以相加组合以创建模型行为。
图3中的“Direct path”term, I d ⊗ W U W E Id\otimes W_UW_E Id⊗WUWE 在研究zero-layer transforer时也出现了。由于其不会在位置之间移动信息( I d ⊗ . . . Id\otimes ... Id⊗... 说明这一特性),因此其只能实现二元统计,并且填补其他terms无法在此处处理的缺失空白。
更有意思的terms是注意力头terms。
Splitting Attention Head terms into Query-Key and Output-Value Circuits
每个attention head h都可以表示为term A h ⊗ W U W O V h W E A^h\otimes W_UW_{OV}^hW_E Ah⊗WUWOVhWE,其中 A h = s o f t m a x ( t T W E W Q K h W E t ) A^h=softmax(t^TW_EW_{QK}^hW_Et) Ah=softmax(tTWEWQKhWEt) 。下面将说明这些terms是如何与模型行为对应的,以及当按照这些terms与模型行为的对应关系去做时,为什么会在方程中得到这些特殊的矩阵乘积。
值得关注的是,这些terms由两个可分离的操作组成,这两个操作在terms的两个核心矩阵 [ n v o c a b , n v o c a b ] [n_{vocab},n_{vocab}] [nvocab,nvocab]中:
- W E W Q K h W E W_EW_{QK}^hW_E WEWQKhWE ,该矩阵为“query-key (QK)数据流程”。它为每个query token和key token计算attention分值。也就是每个attention分值描述了一个给定的query token对一个给定的key token的关注程度。
- W U W O V h W E W_UW_{OV}^hW_E WUWOVhWE,该矩阵为“Output-Value (OV)数据流程”。 它描述了关注一个给定的token是如何影响output logits的。
为了直观地理解这些乘积,可以将这些乘积视为贯穿模型的路径,tokens是起点和终点。QK数据流程是通过跟踪一个query vector和一个key vector从开始直到attention head的计算构建的,在attention head二者通过点积运算生成一个双线性形式。OV数据流程是通过跟踪计算一个值vector,直至得到logits的路径构建的。

attention 模式是源token和目标token的函数,但是一旦目标token已经决定了对源token的关注程度,那么对output的影响仅是该源token的函数。也就是说,如果多个目标tokens对同一个源token的关注程度都相同,那么该源token对预测output token的logits具有相同的影响。
从技术上讲,attention 模式是一个从开始位置到某一个给定目标token的所有可能的源tokens的函数,因为softmax通过QK数据流程计算每个可能的源token与该给定的目标token的attention分值,然后对attention分值取幂、归一化。
OV和QK的独立性(冻结attention模式技巧)
分开思考OV和QK数据流可能非常有用,因为它们都是我们可以理解的单独函数(在我们理解的矩阵上操作的线性或双线性函数)。
但独立思考它们真的是有原则的吗?为了验证独立分析二者的效果,作者设计一个实验,运行模型两次。
- 第一次,采集每个head的attention模式。这仅依赖于QK数据流程
- 第二次,将attention模式替换为第一次采集的“冻结”了的attention模式。这就得到了一个logits是tokens的线性函数的函数。
???
经过作者验证,上述方法是分析transformer的一个非常有效的方法。
Interpretation as Skip-Trigrams
对tranformer进行机械式解释的核心挑战之一是通过上下文语义化使神经网络参数有意义。作者通过将OV数据流程与QK数据流程相乘做到这一点:神经网络参数成为了tokens上的简单线性或双线性函数。QK数据流程决定了 当前目标token返回到哪个源token并从中复制信息,而OV数据流程描述了对用于预测下一个token的“输出”产生的影响。综上,所涉及的这三个tokens构成了一个形式为 [source]…[destination][out]的“skip-trigram”,并且更新了“out”。
值得注意的是,上述内容不能说明对tranformer进行机械式解释的工作很轻松。一方面,生成的结果矩阵非常庞大(作者的词汇表约50000个tokens,因此,一个单独扩展的OV矩阵具有25亿个attention分值);作者将one-layer attention-only model揭示为一个压缩的汉语空间,并且遗留下大量的卡片。在理解作用于相关变量的广义线性模型的权重和变量之间的可替代性时,也会遇见一些常见的问题。例如,一个attention head的权重可能为零,因为另一个attention head将关注同一个token并执行与其一致的功能。最后,还存在一个技术问题,即不同query向量之间的QK权重不具有可比性,并且对于如何规范化不同query向量的QK还没有明确的方法。
尽管存在上述问题,但是作者仍然构建了一个transformer,其所有参数都是上下文语义化且易于理解的。尽管存在这些细节问题,但是作者可以简便地通过关联OV矩阵和QK矩阵来读取skip-trigrams。特别地,在这些矩阵中搜索大的attention分值会发现许多有趣的行为。
在后续小节中,作者详细介绍了一些有趣的skip-trigrams,以及它们是如何嵌入到QK/OV数据流程中。
这里有两个实例,就不展示了,可以看原文中的链接。
复制/原始的上下文学习
查看这些矩阵时最引人注目的是,在one-layer模型中大多数attention heads将其很大一部分容量用于复制。OV数据流程设置完成之后,会增加tokens中被attention head关注的token的概率,同时以较小的幅度增加类似tokens的概率。然后,QK数据流程只处理可能成为下一个token的tokens。因此,tokens只会被复制到在二元统计中它们看起来更为合理的地方。如图所示。
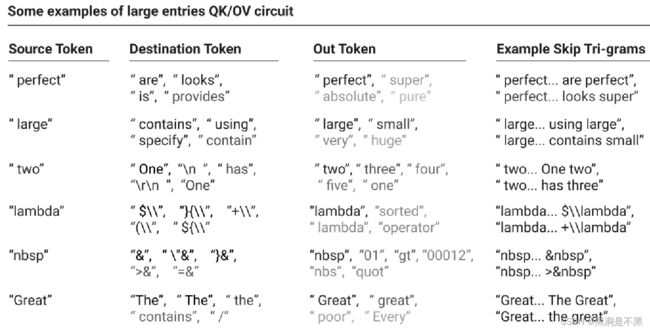
请注意,这些示例中的大多数都是复制的; 这似乎很常见。
作者还观察到一些更为微妙的复制行为。其中一个特别有趣的行为与transformer中分词功能通常是如何工作的有关。分词器通常将空格合并到单词的开头。但是,有时一个词会出现在其前面没有空格的上下文环境中,例如在新段落的开头,或一对对话的结束。由于这些情况很少见,因此并没有针对它们优化分词功能。因此,对于不太常见的单词,当它们前面有空格时,通常将它们和空格映射为一个token,当它们面前没有空格时,就对其进行拆分。例如,(" Ralph"-> [" Ralph"]),(“Ralph”-> [“R”, “alph”])。
Skip-trigram attention分值以上述这种方式处理复制的单词。实际上,有时候会观察到attention heads中的一部分会专注于处理拆分为两个没有空格的tokens的单词的复制。当这些attention heads观察到一个碎片化的token(例如,“R”)时,它们会回溯到可能带有空格的完整单词的tokens上(" Ralph"),然后预测后续的内容(“alph”)。有趣的是,上述情况可以认为是一种非常特殊的情况,一个one-layer模型能够在某种程度上模拟在two-layer模型中出现的感应heads(induction heads)。

作者将复制行为归纳为几个抽象的模式,如图 。

图 中的内容可以看作是一种非常原始的语境学习。Transformer适应其所处语境的能力是它们最有趣的特征之一,而这种简单的复制行为是它的一种非常基本的形式。但是,当作者研究two-layer transformer时,发现了可用于更深的transformers的更为有趣和更为强大的语境学习算法。
OTHER INTERESTING SKIP-TRIGRAMS
当然,复制并不是这些注意力头编码的唯一行为。
skip-trigrams似乎微不足道,但实际上可以产生比人们预期的更复杂的行为。作者接着又列举了在查看他们模型的扩展OV/QK矩阵中最大entries时发现的一些特别引人注目的skip-trigrams示例。
看原文吧
有一点需要注意的是,学到的skip-trigrams通常与token化的特质有关。例如,将空白处折叠在一起允许单个tokens显示缩进。不将反斜杠合并到文本tokens中意味着当模型预测LaTeX时,反斜杠后有一个token必须是转义序列。等等。
如果没有特定的知识,许多skip-trigrams可能很难解释(例如Israel … K → nes只有当你知道以色列( Israel’s)的立法机构被称为“议会”(“Knesset”) 时,K → nes才有意义。一个有用的策略是尝试在谷歌搜索(或类似工具)中键入潜在的skip tri-grams,并查看自动完成。
PRIMARILY POSITIONAL ATTENTION HEADS
作者对attention heads 的处理没有讨论attention heads是如何处理位置的,主要是因为现在有几种处于互相竞争关系的方法,这会增加作者所列出公式的复杂度。在标准位置嵌入的情况下,one-layer模型的数学计算结果是将 W Q K W_{QK} WQK 乘以位置嵌入。
在实际中,one-layer模型倾向于具有少量主要是位置相关的,并且特别偏好特定位置的attention heads。在图中,作者展示了一类attention head,该attention head要么关注当前token,要么关注前一个token。

SKIP-TRIGRAM “BUGS”
研究one-layer transformers中扩展的QK矩阵和OV矩阵,可以通过它们揭示从外部看来难以理解的transformer行为。
作者研究的one-layer模型以分割点在OV矩阵和QK矩阵之间的“因式分解形式”表示skip-trigram。这种表示方式类似于 f ( a , b , c ) = f 1 ( a , b ) f 2 ( a , c ) f(a,b,c)=f_1(a,b)f_2(a,c) f(a,b,c)=f1(a,b)f2(a,c) 。这种表示方式不能真正灵活地获取这三种交互。例如,如果一个单独的head增加了"keep… in mind"和"keep… at bay"的概率,那么它必须也增加"keep… in bay"和"keep… at mind"。总的来说,这对于模型是一个很好的平衡点,但在某种意义上也是一个错误。作者经常在attention heads中观察到这一点。

尽管这些特定的错误在某种意义上似乎微不足道,但我们对这一结果感到兴奋,这是使用可解释性来理解模型失败的早期演示。作者没有进一步探索这种现象,但很想更详细地这样做。例如,我们可以描述这些“错误”给模型造成了多少性能(loss或其他方面)的损失程度吗?这个特定类别是否在某种程度上在更大的模型中继续存在(大概是部分,但不完全被其他效果掩盖)?
Summarizing OV/QK Matrices
到此为止,我们已经将理解one-layer attention-only transformers的问题转换为理解其扩展OV矩阵和QK矩阵的问题。但是如前文所述,扩展的OV矩阵和QK矩阵非常庞大,通常具有数十亿个元素(attention分值)。虽然搜索最大的元素很有趣,但是有没有更好的办法来理解它们呢?至少有三个理由可以期待更好的办法:
- OV矩阵和QK矩阵是极低秩的。例如,它们是 50000×50000
的矩阵,但是其秩只有 d h e a d d_{head} dhead(64或128)。在某种意义上,尽管它们的展开式看起来很大,但是它们很小。 - 查看单独的元素通常会发现结构更为简单的暗示。例如,作者观察一个head,在这个head中人名都有像"by"这样的热门查询。例如,“Anne… by → Anne”,而位置名都有像"from"这样的热门查询,例如,“Canada… from → Canada”。这暗示了矩阵中某些类似簇结构的东西。
- 复制行为在 OV 矩阵中很普遍,可以说是最有趣的行为之一。(作者将在后续内容进行介绍,因为two-layer模型中有类似的QK矩阵结构,用于搜索与query相似的token。)似乎可以将其规范化。
虽然目前还没有一个明确的答案,但是作者乐观地认为,正确的矩阵分解或矩阵降为可能会提供大量信息。(有关如何有效使用这些大型矩阵的说明,请参阅作者原文的技术细节附录。)
检测复制行为
作者最想通过自动方式检测到复制行为。由于复制行为基本上是将相同的向量映射到自身(例如,让一个token增加自己的概率),因此复制行为似乎非常容易在某种汇总统计数据中被捕获。然而,很难确定复制行为的正确概念是什么;这是因为有许多具有细微差别的方法可以划定某事物是否是一个“复制矩阵”的界限,而作者还不明确最有用的方法是什么。例如,作者没有在该篇文章讨论的模型中观察到复制行为,但是在稍大一些的模型中,作者经常可以观察到attention heads从附近的单词中“复制”了一些性别、复数和时态的混合,以此帮助模型使用正确的代词和共轭动词。这些attention heads的矩阵并不完全复制单个tokens,而是在某种非常有意义的含义上进行复制。所以,“复制”实际上是一个比它最初看起来更加复杂的概念。
一种自然的方法可能是使用特征向量和特征值。当 M v i = λ i v i Mv_i=λ_iv_i Mvi=λivi
时, v i v_i vi是特征值为 λ i λ_i λi的矩阵M的一个特征向量。当 λ i λ_i λi是一个正实数时,可以探究这对OV数据流程 M = W U W O V h W E M=W_UW_{OV}^hW_E M=WUWOVhWE意味着什么。然后我们假设有一个tokens的线性组合,它增加了这些相同tokens的logits的线性组合。
粗略来讲,可以将其视为一组互相增加自身概率的tokens(也许这些tokens表示一个非常广泛的单词的复数,或者所有以给定第一个字母开头的tokens,或者表示某个单词的不同大写、包含空格的某些精确形式的tokens。)当然,我们希望特征向量内的值有正有负,因而它更像是两组tokens(例如,表示男女单词的tokens,或者表示单复数单词的tokens。), 这增加了同一组中其它tokens的概率,并且减少了其它组中那些tokens的概率。
特征分解将矩阵表示为一组上文所述那类的特征向量和特征值。对于一个随机矩阵,我们期望其有相同数量的正负特征值,其中的大部分是复数。
特征值得到最佳表征,并且与上文所述的期望最为相似的随机矩阵类别是Ginibre矩阵,该矩阵中的元素符合高斯分布,与作者所研究的初始化后的神经网络类似。实值Ginibre矩阵具有正负对称的特征值,在实数上具有额外的概率质量,并且在它们附近具有“排斥性”[8]。当然,在实践中,作者正在处理矩阵的乘积,但依据作者的经验,具有作者随机初始化权重的OV数据流程的特征值分布似乎反映了Ginibre分布。
但是复制操作需要正特征值,而且实际上作者观察到许多attention heads具有正特征值,显然地反映了复制操作的结构,如下图所示。

可以将图中的数据其进一步压缩折叠,获得表示有多少attention heads是执行复制操作(如果特征值作为汇总统计数据是可信的)的直方图。

图中显示12个attention heads中有10个明显是在执行复制操作(这与扩展的权重的定性检查一致。)。
但是,尽管复制矩阵时必须要有正特征值,但是并不清楚是否所有具有正特征值的矩阵都是我们必须考虑要执行复制操作的东西。矩阵的特征向量不一定是正交的,因为允许存在一些不符合常规的例子。
非正交特征向量可能具有不直观的属性。如果尝试用特征向量来表示矩阵,则需要乘以特征向量矩阵的逆矩阵,这与非正交情况下单纯地投影到特征向量上的行为完全不同。
例如,可能存在所有特征值都是正值的矩阵,这些矩阵实际上在映射某些tokens后降低了这些tokens的logits。正特征值仍然意味着矩阵在某种意义上是“平均复制”,尽管从经验上看,并且在默认情况下正特征值似乎不太可能与复制行为一致,但是正特征值仍然是复制行为的有力证据。但是,正特征值不应该合理地被认为是矩阵在所有情况下都执行复制操作的决定性证据。
人们可能会尝试用其他方式形式化“具有复制行为的矩阵”。一种可能的方式是研究矩阵的对角线,对角线上的元素(attention分值)描述了每个token如何影响其自身的概率。正如预期的那样,对角线上的元素非常趋近于正值。我们还可以研究一个随机token增加其自身概率的频率比增加其它token的概率的频率高多少(或者获取概率增加最快的k个tokens,统计这k个tokens中哪些tokens的区别只是具有不同的大小写或空格)。所有这些内容似乎都指向这些attention heads是执行复制操作的矩阵,但是并不清楚上述内容中的任何一个是否是“该矩阵的主要行为是复制”的完全稳健的形式化。值的注意的是,所有这些有关复制操作的潜在概念都与特征值之和等于矩阵的迹、等于对角线之和这一事实有关。
出于本文的目的,作者将继续使用基于特征值的汇总统计量。作者不认为它是完美的,但它似乎是复制行为的有力证据,并且在经验上与人工检查和其他定义一致。
Do We “Fully Understand” One-Layer Models?
人们经常怀疑是否有可能或值得尝试真正对神经网络进行逆向工程。在这种情况下,很容易指向one-layer attention-only transformers并说“看,如果我们采用最简化的toy版本的transformer,至少可以完全理解最小版本。”
但这种说法实际上取决于关于完全理解的定义。在我们看来,我们现在在某种程度上理解这个简化模型与我们可以查看一个巨大的线性回归的权重并理解它,或者查看一个大型数据库并理解查询它的含义相同。那是一种理解。不再有任何算法之谜。神经网络参数的语义化问题已被剥离。但是如果没有进一步的工作来总结它,有太多的东西让人们无法将模型牢牢记在脑海中。
鉴于常规的one layer神经网络只是广义线性模型并且也可以这样解释,因此单个attention层也可能是一个广义线性模型,并且也可以进行解释,那这就不足为奇了。
至此,单层注意力结束