扩散模型在文本生成的应用
作者 | 郑童、鲍慧雯
单位 | 东北大学自然语言处理实验室
来自 | 机器翻译学堂
进NLP群—>加入NLP交流群
引言
扩散模型(Diffusion Models, DM)在文本到图像生成领域备受瞩目,目前已完全超过了上一代主流生成范式生成对抗网络 (Generative Adversarial Network, GAN)。相比于GAN,扩散模型可以具有以下如下几个特点:1)完备的理论基础;2)灵活的架构设计;3)稳定的训练;4)便捷的引入额外信息,例如图像风格的控制。基于上述几个特点,扩散模型迅速扩展到包括图像、语音、文本等各个领域。本文主要关注扩散模型在文本序列生成上的应用。
预备知识:什么是扩散模型?
基本思想:
扩散模型是一种新型的生成式模型,受热力学中扩散过程的启发而来,旨在从高斯噪声中不断去噪进而直接恢复原始数据。
如何学习到去噪函数?
为了很好地学习到标准高斯噪声到原始数据分布的转换,扩散模型设计了一个双向过程,分别记为前向过程和反向过程。简单来说,前向过程通过对原始数据不断加噪使其成为一个标准高斯噪声,而反向过程则不断对标准高斯噪声进行去噪,最终获取真实的数据分布。
作者认为,前向过程类似于提供了反向过程中不断去噪所需地学习标签。例如,我们并不知道如何从一个标准高斯分布变换到一个真实的数据分布,因此无法找到合适的优化目标。但是,如果我们自己设定一个已知的从真实数据分布到标准高斯噪声的转变过程,那么,我们就相当于有了一个标签。
接下来,作者将详细讲解原的扩散模型(DDPM论文中的扩散模型)的学习过程。

图1 扩散模型的示意图(来自DDPM论文)。
1、 前向过程
前向过程是一个加噪过程,旨在通过对原始数据不断增加高斯噪声,最终达到一个标准的高斯噪声。假设加噪过程中后一时刻的状态只与前一时刻的状态有关,因此上述前向过程为一个马尔科夫链,具有以下性质:
其中 是原始数据,其满足 , 代表原始数据经过 次加噪后的状态, 为 到 的转换函数, 为参数。
在实际过程中,由于上述公式(1)的计算是不可导的,为此原文中采用了一种重参数技巧,如下所示:
其中 分别均值和方差, 为随机标准高斯分布。基于公式(2), 重写为:
通常情况下,前向过程加噪的次数高达上千次,因此重复的迭代计算代价很大。为了更加高效的计算 ,我们进一步推导 如下:
其中
推导:
替换 :
由于 且根据正态分布力法准则可得:
以此类推:
根据公式(4),我们可以清楚的看出,当T很大时, , ,此时 近似为一个标准的高斯分布。
2、 反向过程
反向过程是一个去噪过程,我们想要通过对一个标准高斯噪声反复去噪来生成真实的图像。我们定义该过程的输入为 ,转换函数为 ,该反向过程同样是一个马尔可夫链:
这里面 都是可以通过网络学习的。通常情况下,我们设置 为固定值,只需要学习 即可。
如上文所述,如果知道扩散模型前向过程逆过程 ,那么我们就可以顺利的从噪声中恢复真实图像。然而,实际上我们无法知道 。但我们可以知道 ,因为根据贝叶斯定理有:
其中 均为已知。这里我们记
更进一步,由高斯分布运算性质可知:
展开配项得: 。又由于
则 有 。因此
。
因此我们通过神经网络来估计 ,其估计值为 ,其中 是由神经网络计算的。3、 扩散模型的训练
对于扩散模型的训练,作者的通俗理解就是使每一个时间步上满足 。基于此,我们可以得到扩散模型的优化目标为:

这里我们通过上文分析注意到, 与 分布之间的差距主要来自 与 之间,因此上述优化目标可进一步简化为:
上述仅为通俗的理解过程,接下来作者将介绍如何推导出上述两个公式。首先,我们旨在直接优化的目标为最小化 。然而,由于我们无法直接计算 ,因此这里我们采用VLB方法进行转换:
因此我们可以得到新的优化目标,即最小化 。随后我们进一步对上述目标进行优化:
故我们可得公式(7)。更进一步,由高斯分布的性质,我们可进一步化简得到公式(8)。
扩散模型在文本上的应用
Diffusion-LM Improves Controllable Text Generation
1、动机和主要贡献
大的自回归语言模型可以产生优质的文本。然而在实际过程中,我们需要的文本往往需要注入特定的风格。通常的做法是用所需风格的文本对语言模型进行微调,然而这种方式需要耗费大量的资源。此外,现有的其他即插即用方法无法很好地注入更复杂的元素。
主要贡献如下:
1)成功的将diffusion models适配到文本领域 (连续空间->离散空间),并提出一种新型的基于diffusion的语言模型——Diffusion-LM。
2)基于Diffusion-LM,提出了一种即插即用的可控生成方法,通过充分利用Diffusion-LM中大量的隐变量进行文本可控生成。
3)大量实验表明,基于Diffusion的可控文本生成相比于其他即插即用方法有着显著优势,尤其是在较为复杂的控制下,如语法结构。
2、 如何构建面向文本的Diffusion:Diffusion-LM

图2 Diffusion-LM的图模型结构(图片来自Diffusion-LM原论文)。
由于原始的diffusion model 是构建在连续空间上的,而文本是离散的,因此直接将diffusion models应用到文本上显然是不可行的。为此首先需要定义了一个嵌入函数 ,用于将原始的离散文本输入映射到连续空间中。形式上,给定具有 个词的文本,其对应的嵌入表示如下: 。
在此基础上,为了同时优化diffusion models 与定义的嵌入函数,原论文作者进一步修改了diffusion models的优化目标。首先原论文作者在前向过程中增加了一个马尔科夫转换过程,该过程由原始文本输入w到原始diffusion models的初始输入 ,记作 。在反向过程中,原论文作者添加了一个可训练舍入步骤,其参数化为: 。其中 是一个Softmax分布。因此新的训练目标变为如下形式:
更进一步,原论文作者设计了rounding操作以从 恢复到离散化文本。具体来说,通过选择每个位置上可能性最大的词。形式上通过优化 。理想情况下,我们希望 可以准确地对应某个词的嵌入,然而实际中并不能做到如此。这主要由于先前的 损失对 的约束不够,因此提出了另外一种参数化方法,即 参数化,来确保目标函数中的每一项都对 进行约束。
3.如何利用Diffusion-LM进行可控文本生成

图3 Diffusion-LM进行可控生成示意图。(图来自于论文Diffusion-LM)
如图所示,原论文作者对中间隐变量 实施控制并采用rounding操作将这些隐变量转换成文本。具体来说,作者认为控制 相当于从后验 解码。通过化简,对于第 步,我们在 上运行梯度更新:
其中,该优化前一项用于文本生成,而后一项则是用于控制。更进一步,作者为了生成流畅的文本,对上述梯度更新过程引入正则化系数,来平衡流畅度与控制程度。
4、实验
具体实验过程中,原论文作者首先通过两个语言建模任务E2E 和 ROCStories来训练Diffusion-LM。Diffusion-LM的模型架构选用Transformer。具体的设计请查阅原文。
原论文作者选择了6种可控任务进行模型评估,分别为Semantic Content、Parts-of-speech、Syntax Tree、Syntax Spans、Length、Infilling。其中前四种任务需要分类器,而后两个任务则不需要分类器。
为了评估方法,作者定义了如下指标:
lm-score:用于评估生成文本的流畅度。做法:将生成的文本提供给教师语言模型(例如, GPT-2模型),并报告生成的困惑度。该指标越低,表明具有更加优异的采样质量。
Semantic Content任务的成功标准:给定一个字段(例如,评级)和值(例如,5星),生成一个包含field=value的句子,并通过“value”的精确匹配来报告成功率。
Parts-of-speech任务的成功标准:给定一个词性(POS)标记序列(例如,代词、动词、限定词、名词),生成一个长度相同的单词序列,其POS标记(在oracle POS标记器下)与目标匹配(例如,我吃了一个苹果)。我们通过单词级别的精确匹配来量化成功。
Syntax Tree任务的成功标准:给定一个目标语法解析树,生成其语法解析与给定解析匹配的文本。为了评估成功与否,我们使用现成的解析器解析生成的文本,并报告F1分数。
Syntax Spans任务的成功标准:给定一个目标(span,句法类别)对,生成在span [i, j]上的解析树与目标句法类别(例如介词短语)匹配的文本。我们通过精确匹配的跨度比例来量化成功
Length任务的成功标准:给定目标长度,生成长度在目标长度±2范围以内的序列。
Infilling任务的成功标准:给定来自aNLG数据集的左上下文(O1)和右上下文(O2),目标是生成一个逻辑上连接O1和O2的句子。对于评估,我们报告了来自Genie排行榜的自动和人工评估。
基于上述指标,作者在6个控制任务上进行了相关实验。实验结果如图4-6所示。其中对于单个控制任务来说,Diffusion-LM展现出其优越性,在成功率方面全面优于之前的即插即用工作。此外,值得注意的是,在一些较难的控制任务上,Diffusion-LM能取得更加明显的优势。这也说明了基于隐变量的可控文本生成的优势。
除此之外,作者还探讨了一些组合控制任务上的效果,发现Diffusion-LM可以在组合任务上同时达到很高的成功率。这里不过多赘述,具体请参考与原论文的实验部分。

图4 Diffusion-LM在所有5个控制任务中实现了高成功率(ctrl↑)和良好的流畅性(lm↓),优于PPLM和FUDGE基线。

图5 Diffusion-LM以一定的流畅性为代价获得更高的成功率( ctrl↑) ( lm↓)。我们的方法优于FUDGE和FT-PoE(两个微调模型专家的产物)对控制成功率的影响,特别是对结构化语法控件(即语法解析树和POS)。
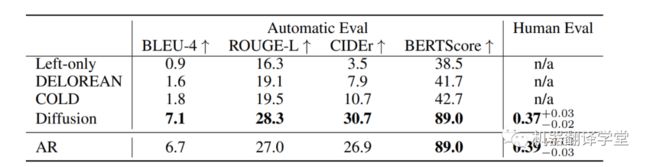
图6 对于句子填充,Diffusion-LM显著优于之前的COLD和Delorean,并与从头训练的自回归LM (AR)进行填充的性能匹配。
进一步工作与总结
1、 DIFFUSEQ: SEQUENCE TO SEQUENCE TEXT GENERATION WITH DIFFUSION MODELS
该论文进一步将Diffusion models 从可控文本生成领域扩展到seq2seq生成领域。由于seq2seq的条件是一整个源语句子,因此之前的基于分类器的Diffusion-LM不再适用。为了解决这个问题,该论文将源语和目标语拼成一个句子,并设计了一种部分加噪的前向过程,每次只对目标语部分进行加噪,而维持源语部分不动。通过这种操作,DiffusionSeq成功的将条件的注入摆脱分类器的限制。另一个值得注意的点是该论文还将Diffusion与自回归和非自回归进行了理论上的联系。具体内容请参考原论文DIFFUSEQ: SEQUENCE TO SEQUENCE TEXT GENERATION WITH DIFFUSION MODELS。
2、 SeqDiffuSeq: Text Diffusion with Encoder-Decoder Transformers
该论文进一步将seq2seq任务中的Diffusion models从encoder-only的架构扩展到更加灵活的encoder-decoder架构。此外该论文还探索了self-conditioning technique 和噪声管理器的选择
3、 相关总结
总体来说,diffusion models 在生成任务上具有一些显著的优势,比如充分的隐蔽变量提供了更加充足的空间进行可控信息的插入。然而,这种计算机制也带来了弊端:训练解码慢,例如IWSLT14 De-En任务上,使用单卡需要训练很多天,训练代价远远高于传统的Transformer架构。因此如何加速采样,是一个值得研究的点。
进NLP群—>加入NLP交流群
知识星球:NLP学术交流与求职群
持续发布自然语言处理NLP每日优质论文解读、相关一手资料、AI算法岗位等最新信息。
加入星球,你将获得:
1. 最新入门和进阶学习资料。包含机器学习、深度学习、NLP等领域。
2. 最新最优质的的论文速读。用几秒钟就可掌握论文大致内容,包含论文一句话总结、大致内容、研究方向以及pdf下载。
3. 具体细分NLP方向包括不限于:情感分析、关系抽取、知识图谱、句法分析、语义分析、机器翻译、人机对话、文本生成、命名实体识别、指代消解、大语言模型、零样本学习、小样本学习、代码生成、多模态、知识蒸馏、模型压缩、AIGC、PyTorch、TensorFlow等细方向。
4. NLP、搜广推、CV等AI岗位招聘信息。可安排模拟面试。
