UIE Notes | Underwater Image Enhancement With Lightweight Cascaded Network
Recently, many low-level tasks (e.g., LapSRN for single image super-resolution, LPNet (From Lightweight Pyramid Networks for Image Deraining)for single image rain removal) use Laplacian pyramid to build their lightweight architecture and achieve promising results. Motivated by them, we inherit the advantages of Laplacian Pyramid and propose a Lightweight Cascaded Network (LCNet) to enhance underwater images effectively and efficiently.
Due to various light conditions and water current, the color details of underwater images might be blended with object edges and backgrounds, which makes the pixel-domain mapping into a difficult task.(By observing the result image after PCA processing and CNN, it is found that the edge of the object is very clear and the brightness is very high. However, the image without PCA does not show this feature after enhancement. Is PCA helpful to distinguish the boundary?)
In this work, we achieve the multi-scale processing with three steps: pyramid decomposition, multi-scale enhancement and image reconstruction.
Pyramid Decomposition
The multi-scale decomposition also facilitates the network to take advantage of sparsity at each level, thereby removing color artifacts.(why?)
In this work, we employ Laplacian pyramid decomposition to decompose an image into multi-scale sub-bands. we adopt Laplacian pyramid decomposition to generate a set of images ![]() with N levels:
with N levels:
![]()
where ![]() and
and ![]() are the n-th Gaussian pyramid image and an upsampling operator, respectively.
are the n-th Gaussian pyramid image and an upsampling operator, respectively. ![]() is the n-th Lapcian pyramid image, which is constructed by taking the difference between
is the n-th Lapcian pyramid image, which is constructed by taking the difference between ![]() and
and ![]() (n = 1, 2,..., N-1).
(n = 1, 2,..., N-1). ![]() and
and ![]() .
.
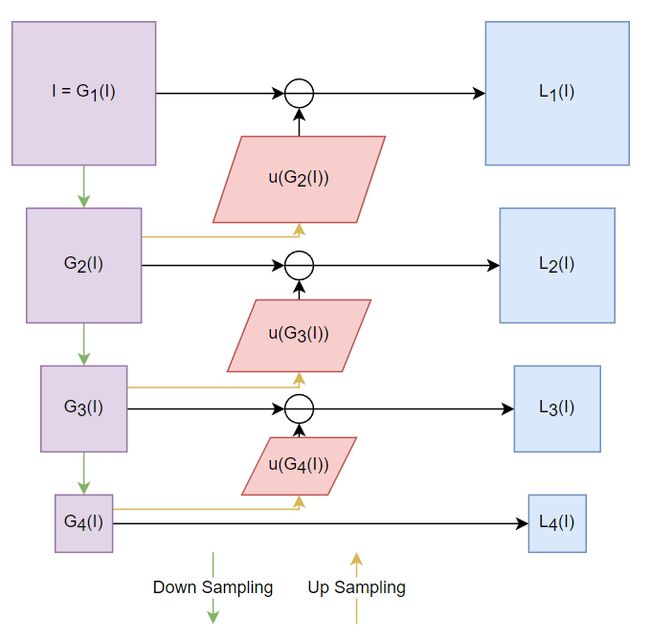 Fig.1. Laplacian Pyramid
Fig.1. Laplacian Pyramid
Multi-Scale Enhancement
With Laplacian pyramid decomposition, we are able to design simple sub-networks to handle each pyramid level in a divide-and-conquer way, resulting in compact sub-networks and fast computation. In addition, we also design each sub-network in a recursive processing manner, which allows parameter reuse to further benefit the lightweighting of our model.
 Fig.2. LCNet Network Structure
Fig.2. LCNet Network Structure
After decomposing I into different pyramid levels, we build a set of sub-networks for enhancement. Each sub-network consists of two 3 × 3 convolutional layers and four blocks(The blue block in Figure 2). At the front and end of sub-network, convolutional layers with Leaky Rectified Linear Units (LReLUs) are added to adapt to the feature dimensions. All sub-networks share the same architecture but their parameters are separately trained.
To develop a lightweight model, we adopt the recursive scheme in each block, in which two recursive units are deployed with shared weights that can be trained simultaneously. Through weight sharing, the model parameters are significantly reduced.
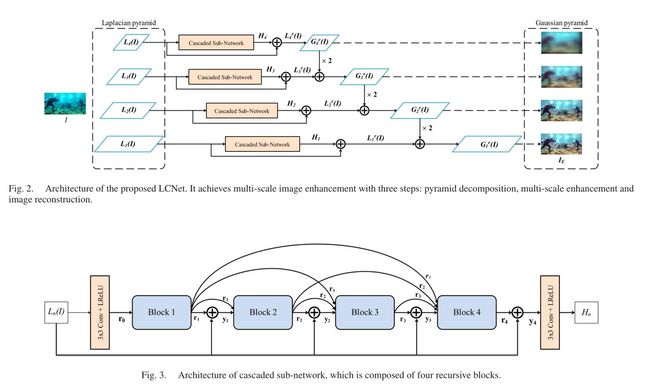 Fig.3. Network structure diagram in the paper-1
Fig.3. Network structure diagram in the paper-1
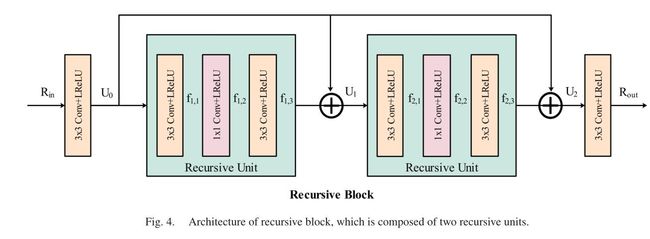 Fig.4. Network structure diagram in the paper-2
Fig.4. Network structure diagram in the paper-2
Enhanced Image Reconstruction
In the last stage, we use element-wise summation to combine Laplacian pyramid images ![]() with enhanced residual
with enhanced residual ![]() :
:
![]()
where n = 1, 2,..., N, ![]() is the output of the Laplacian image at the n-th level.
is the output of the Laplacian image at the n-th level.
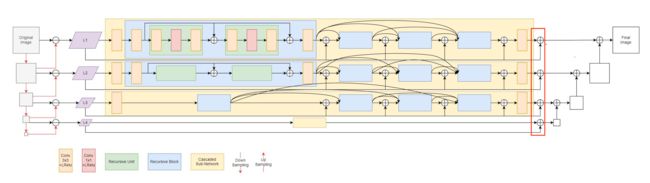 Fig.5. The above text describes the element fusion process
Fig.5. The above text describes the element fusion process
Consequently, the corresponding Gaussian pyramid of the enhanced image can be reconstructed as
![]()
where n = 1, 2,..., N − 1, ![]() . The final enhanced image
. The final enhanced image ![]() is obtained at the bottom level of the Gaussian pyramid
is obtained at the bottom level of the Gaussian pyramid ![]() .
.
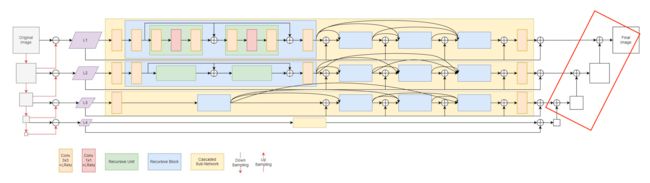 Fig.6. The image reconstruction process described in the above text
Fig.6. The image reconstruction process described in the above text
Loss Function
To achieve both good subjective visual quality and high fidelity, we combine Mean Square Error (MSE) loss and Perceptual (PER) loss to guide the training of our network.
We initialize training image pairs ![]() , where
, where ![]() is the ground-truth, and
is the ground-truth, and ![]() denotes the number of the training images.
denotes the number of the training images.
![]()
However, training with the MSE loss only might lead to over-smoothed results. To avoid this problem, we combine it with a perceptual loss, which measures the feature difference between our predicted output and ground-truth. we input the two images into a pre-trained VGG16 network and calculate their feature difference:

where ![]() represents the dimension of the feature map at j-th convolution layer within the VGG16 network, and
represents the dimension of the feature map at j-th convolution layer within the VGG16 network, and ![]() represents the feature of the j-th convolutional layer.
represents the feature of the j-th convolutional layer.
Finally, the above two functions are summed up to obtain the overall loss:
![]()
where λ = 0.02 is set empirically.