【计算机视觉 | 图像模型】常见的计算机视觉 image model(CNNs & Transformers) 的介绍合集(十)
文章目录
-
- 一、GreedyNAS-A
- 二、ASLFeat
- 三、GreedyNAS-B
- 四、Twins-PCPVT
- 五、MoGA-A
- 六、MoGA-C
- 七、Visformer
- 八、Multi-Heads of Mixed Attention
- 九、LocalViT
- 十、SPP-Net
- 十一、The Ikshana Hypothesis of Human Scene Understanding Mechanism
- 十二、DetNASNet
- 十三、TResNet
- 十四、MoGA-B
- 十五、Colorization Transformer
- 十六、CSPDenseNet-Elastic
- 十七、Harm-Net
- 十八、PReLU-Net
- 十九、Twins-SVT
- 二十、EsViT
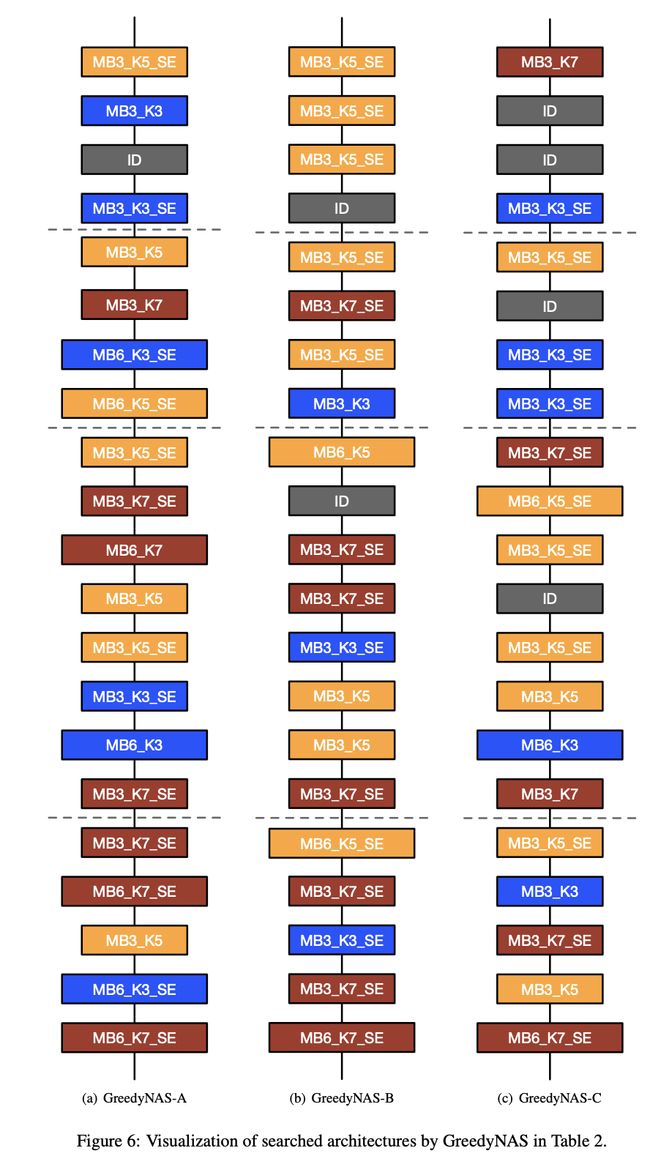
一、GreedyNAS-A
GreedyNAS-A 是使用 GreedyNAS 神经架构搜索方法发现的卷积神经网络。 使用的基本构建块是反向残差块(来自 MobileNetV2)和挤压和激励块。
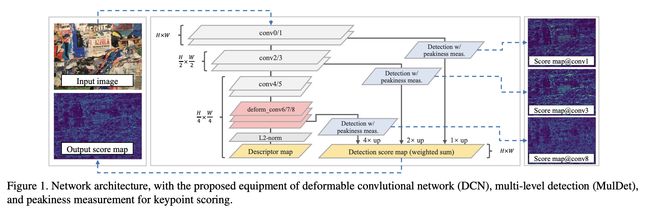
二、ASLFeat
ASLFeat 是一种用于学习局部特征的卷积神经网络,它使用可变形卷积网络来密集估计和应用局部变换。 它还利用固有的特征层次结构来恢复空间分辨率和低级细节,以实现准确的关键点定位。 最后,它使用峰值测量来关联特征响应并得出更具指示性的检测分数。
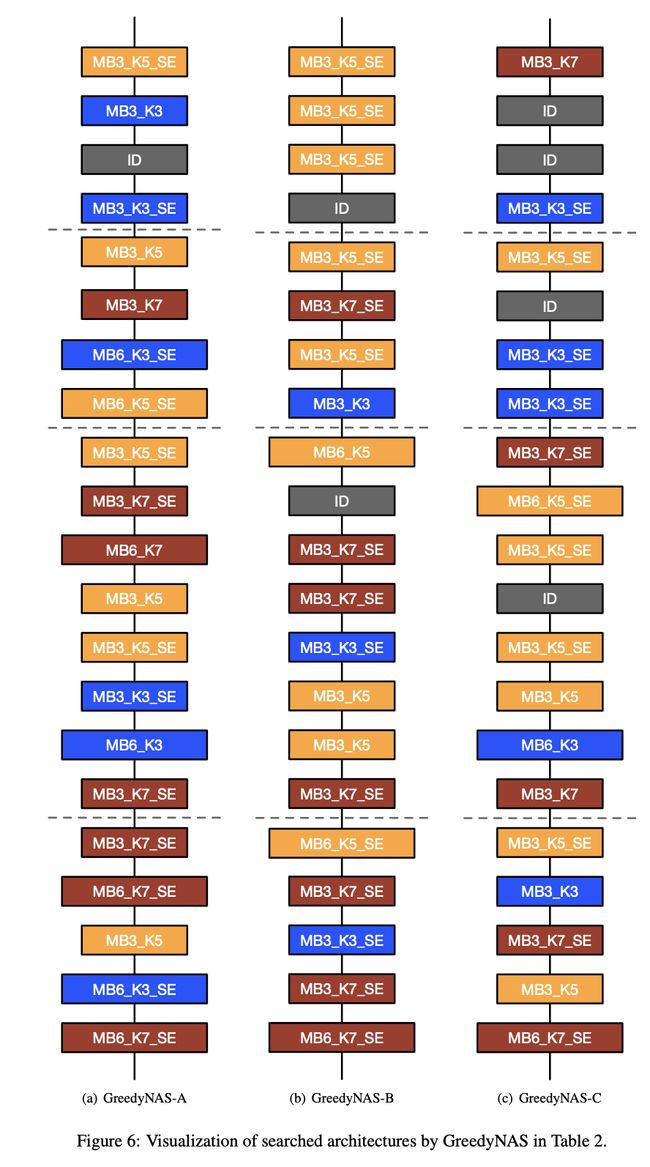
三、GreedyNAS-B
GreedyNAS-B 是使用 GreedyNAS 神经架构搜索方法发现的卷积神经网络。 使用的基本构建块是反向残差块(来自 MobileNetV2)和挤压和激励块。
四、Twins-PCPVT
Twins-PCPVT 是一种视觉变换器,它将全局注意力(特别是 Pyramid Vision Transformer 中提出的全局子采样注意力)与条件位置编码(CPE)相结合,以取代 PVT 中使用的绝对位置编码。
生成 CPE 的位置编码生成器 (PEG) 放置在每级的第一个编码器块之后。 使用最简单的 PEG 形式,即没有批量归一化的 2D 深度卷积。 对于图像级分类,在 CPVT 之后,删除类标记,并在阶段结束时使用全局平均池化。 对于其他视觉任务,遵循PVT的设计。

五、MoGA-A
MoGA-A 是一种针对移动延迟进行优化的卷积神经网络,通过移动 GPU 感知 (MoGA) 神经架构搜索发现。 基本构建块是来自 MobileNetV2 的 MBConvs(反转残差块)。 还对挤压和激励层进行了实验。

六、MoGA-C
MoGA-C 是一种针对移动延迟进行优化的卷积神经网络,并通过移动 GPU 感知 (MoGA) 神经架构搜索发现。 基本构建块是来自 MobileNetV2 的 MBConvs(反转残差块)。 还对挤压和激励层进行了实验。

七、Visformer
Visformer,或视觉友好的 Transformer,是一种将基于 Transformer 的架构特征与卷积神经网络架构的特征相结合的架构。 Visformer 采用分级设计,具有更高的基础性能。 但自注意力仅在最后两个阶段使用,考虑到即使 FLOP 平衡,高分辨率阶段的自注意力也相对低效。 Visformer 在第一阶段采用瓶颈块,并在受 ResNeXt 启发的瓶颈块中使用 3 × 3 组卷积。 它还引入了 BatchNorm 来修补嵌入模块,就像 CNN 中一样。
八、Multi-Heads of Mixed Attention
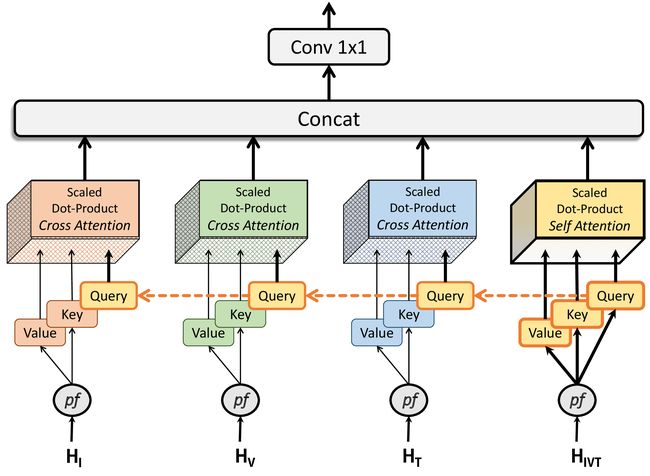
混合注意力的多头结合了自我注意力和交叉注意力,鼓励对各种注意力特征中捕获的实体之间的交互进行高级学习。 它由多个注意力头构建,每个注意力头都可以实现自我注意力或交叉注意力。 自注意力是指关键特征和查询特征相同或来自相同的领域特征。 交叉注意力是指关键特征和查询特征是由不同的特征生成的。 MHMA 建模允许模型识别不同域的特征之间的关系。 这在涉及关系建模的任务中非常有用,例如人与物体交互、工具与组织交互、人机交互、人机界面等。
九、LocalViT
LocalViT 旨在引入深度卷积来增强 ViT 的局部特征建模能力。 如图(c)所示,该网络通过深度卷积(用“DW”表示)将局域机制引入到变压器中。 为了应对卷积运算,通过“Seq2Img”和“Img2Seq”添加序列和图像特征图之间的对话。 计算如下:

输入(标记序列)首先被重塑为在 2D 晶格上重新排列的特征图。 将两个卷积和一个深度卷积应用于特征图。 特征图被重塑为一系列标记,这些标记被网络变压器层的自注意力所使用。
十、SPP-Net
SPP-Net 是一种卷积神经架构,采用空间金字塔池化来消除网络的固定大小约束。 具体来说,我们在最后一个卷积层之上添加一个 SPP 层。 SPP 层汇集特征并生成固定长度的输出,然后将其输入到全连接层(或其他分类器)。 换句话说,我们在网络层次结构的更深层(卷积层和全连接层之间)执行一些信息聚合,以避免在开始时进行裁剪或扭曲。
十一、The Ikshana Hypothesis of Human Scene Understanding Mechanism

十二、DetNASNet
DetNASNet 是一个卷积神经网络,旨在成为对象检测主干,并通过 DetNAS 架构搜索发现。 它使用 ShuffleNet V2 块作为其基本构建块。

十三、TResNet
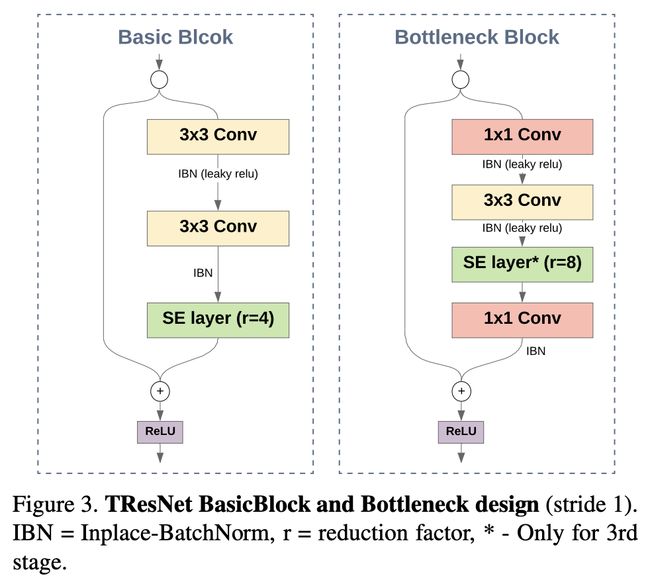
TResNet 是 ResNet 的变体,旨在提高准确性,同时保持 GPU 训练和推理效率。 它们包含多种设计技巧,包括 SpaceToDepth 茎、抗锯齿下采样、就地激活 BatchNorm、块选择以及挤压和激励层。
十四、MoGA-B
MoGA-B 是一种针对移动延迟进行优化的卷积神经网络,并通过移动 GPU 感知 (MoGA) 神经架构搜索发现。 基本构建块是来自 MobileNetV2 的 MBConvs(反转残差块)。 还对挤压和激励层进行了实验。

十五、Colorization Transformer

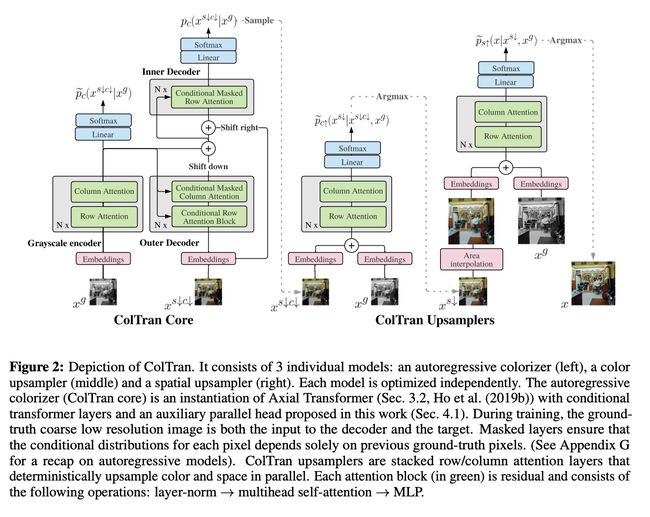
对于粗略的低分辨率着色,应用了 Axial Transformer 的条件变体。 作者利用 Axial Transformers 的半并行采样机制。 最后,采用快速并行确定性上采样模型将粗略彩色图像超分辨率为最终的高分辨率输出。
十六、CSPDenseNet-Elastic
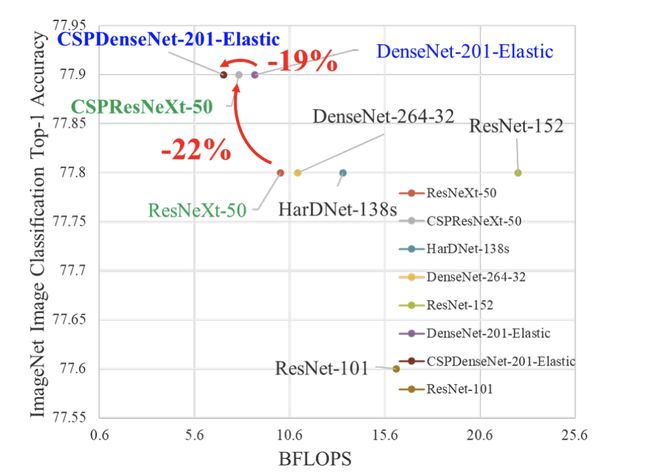
CSPDenseNet-Elastic 是一个卷积神经网络和对象检测主干,我们将跨阶段部分网络 (CSPNet) 方法应用于 DenseNet-Elastic。 CSPNet 将基础层的特征图划分为两部分,然后通过跨阶段层次结构将它们合并。 使用拆分和合并策略允许更多的梯度流通过网络。
十七、Harm-Net
谐波网络或 Harm-Net 是一种卷积神经网络,它用使用离散余弦变换 (DCT) 滤波器的“谐波块”代替卷积层。 这些块可用于截断高频信息(可能是由于谱域中的冗余)。

十八、PReLU-Net
PReLU-Net 是一种卷积神经网络,其激活函数使用参数化 ReLU。 它还使用强大的初始化方案 - 后来称为 Kaiming 初始化 - 来解释非线性激活函数。

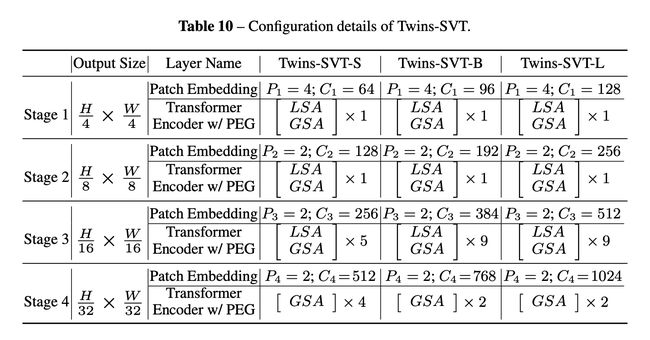
十九、Twins-SVT
Twins-SVT 是一种视觉变换器,它利用空间可分离注意力机制(SSAM),该机制由两种类型的注意力操作组成:(i)局部分组自注意力(LSA)和(ii)全局子采样 注意(GSA),其中LSA捕获细粒度和短距离信息,GSA处理长距离和全局信息。 除此之外,它还利用条件位置编码以及 Pyramid Vision Transformer 的架构设计。
二十、EsViT
EsViT 提出了两种开发高效自监督视觉转换器以进行视觉表示学习的技术:具有稀疏自注意力的多阶段架构和新的区域匹配预训练任务。 多级架构降低了建模复杂性,但代价是失去了捕获图像区域之间细粒度对应关系的能力。 新的预训练任务允许模型捕获细粒度的区域依赖性,从而显着提高学习视觉表示的质量。
