QT学习 编码
编码
编码介绍
编辑器保存文件是有编码的。编辑器中写的char* 常量字符串 “xxx”,以编辑器的编码保存在文件中。QT5编辑器 默认 utf-8
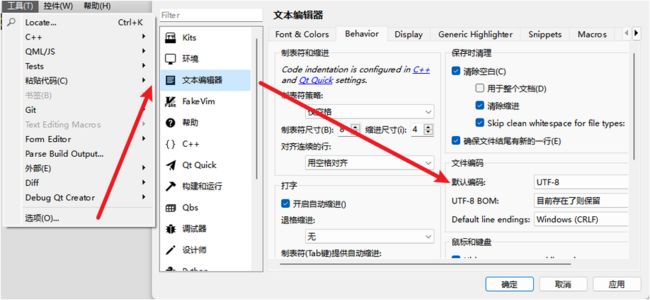
编译器在编译时也有他自己的编码方式,char*常量字符串 “xxx”大部分情况需转换成QString。QString默认是unicode。如果转换时依据的编码与编辑器的编码不一致,就会乱码。相当于乱解释。QString有多个方法用于编码
- fromAscii
- fromLatin1
- fromLocal8Bit,可以认为是ANSI码。在简体中文Windows下,local8Bit是GB国标码
- fromUtf8
QString(“”)的话,会使用上述的其中一种进行编码转换,实验可知QT5应该是fromUtf8
系统控制台是有编码的,windows默认GBK
Windows Txt是有默认编码的。ANSI,ANSI码各国不一,在简体中文Windows下,ANSI 编码代表 GB国标码
Linux文件默认编码utf-8
常量编码
避免printf等中的字符串常量的中文乱码,经常会使用QStringLiteral。
比如
QTextStream qout(stdout);
qout << QStringLiteral("中文")
qout不像cout,他会把常量字符串转换成QString。去掉QStringLiteral大概率会输出乱码。
在我的环境中
1 qout << ("中文常量:")< 2 qout << (u8"中文常量:")< 3 qout << QLatin1String("中文常量:")< 4 qout << QString::fromLatin1("中文常量:")< 5 qout << QString::fromLocal8Bit("中文常量:")< 6 qout << QString("中文常量:")< 7 qout << QString::fromUtf8("中文常量:")< 8 qout << QStringLiteral("中文常量:")< 1 2 3 4输出是一样的,乱码 QTextStream 传入常量字符串,不是调用了QString构造,而是调用了QLatin1String构造。与fromLatin1编码一致 6 7 8输出是一样的,且输出中文正确,佐证了我的编辑器的编码是utf-8. QString的默认字符串编码是fromUtf8,QStringLiteral的编码也等于fromUtf8(mingw编译器下) latin是什么鬼? Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。 ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII⼀致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是⽂字符号。 ISO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语⾔、希腊语、泰语、阿拉伯语、希伯来语对应的⽂字符号。欧元符号出现的⽐较晚,没有被收录在ISO-8859-1当中。 因为ISO-8859-1编码范围使⽤了单字节内的所有空间,在⽀持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换⾔之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,MySQL数据库默认编码是Latin1就是利⽤了这个特性。ASCII编码是⼀个7位的容器,ISO-8859-1编码是⼀个8位的容器。 换言之,latin1 的编码就是,本来是什么,就是什么。既不转换。所以说QLatin1String是char*的薄薄的封装 因windows的控制台是GBK编码的,编辑器中字符串是utf-8,3 4采用latin1编码,没有转换成正确的unicode字符串。后面到控制台也就乱码了。 输出到txt看看 打开txt(win10),不是乱码。Why? QString默认对“”常量字符串采用了fromUtf8来编码,编辑器默认是utf-8。编码一致,转换出来的unicode是正确的。 而通过QTextStream 以字节流的方式保存 QString 内容到 txt。打开Txt,没有乱码,右下角显示编码是ANSI 不是unicode啊, 原因在Qtextstream,他输出时会自动编码转换, 利用如下方法可以读出当前Qtextstream的编码器 我这读出来是system,啥意思,就是他的默认编码是系统的编码,一般中文windows那必然是GB码了。既ANSI了。 如果把Qtextstream默认编码设成utf-8,加入 执行写入之后打开txt,也不乱码?!但右下角显示是utf-8,挺智能。txt会自动识别编码。 可以使用vscode指定gb(ANSI)编码打开,就可以看到乱码了。 遇到编码问题,会尝试使用QTextCodec::setCodecForTr(...)和 QTextCodec::setCodecForCStrings(...)等 然而QT5 去掉了QTextCodec::setCodecForTr(...)和 QTextCodec::setCodecForCStrings(...),这时转换编码需要用到QTextCodec Qt 提供了 QTextCodec 类来帮助在非 Unicode 格式和 Unicode 之间进行转换。 例如 UTF-8转换到unicode Unicode 转换到 GBK 另外,通过qInfo()< ("UTF-8", "ISO-8859-1", "latin1", "CP819", "IBM819", "iso-ir-100", "csISOLatin1", "ISO-8859-15", "latin9", "UTF-32LE", "UTF-32BE", "UTF-32", "UTF-16LE", "UTF-16BE", "UTF-16", "System", "Big5-HKSCS", "Big5", "Big5-ETen", "CP950", "windows-949", "CP949", "EUC-KR", "Shift_JIS", "SJIS", "MS_Kanji", "ISO-2022-JP", "JIS7", "EUC-JP", "GB2312", "GBK", "CP936", "MS936", "windows-936", "GB18030", "hp-roman8", "roman8", "csHPRoman8", "TIS-620", "ISO 8859-11", "WINSAMI2", "WS2", "macintosh", "Apple Roman", "MacRoman", "windows-1258", "CP1258", "windows-1257", "CP1257", "windows-1256", "CP1256", "windows-1255", "CP1255", "windows-1254", "CP1254", "windows-1253", "CP1253", "windows-1252", "CP1252", "windows-1251", "CP1251", "windows-1250", "CP1250", "IBM866", "CP866", "csIBM866", "IBM874", "CP874", "IBM850", "CP850", "csPC850Multilingual", "ISO-8859-16", "iso-ir-226", "latin10", "ISO-8859-14", "iso-ir-199", "latin8", "iso-celtic", "ISO-8859-13", "ISO-8859-10", "iso-ir-157", "latin6", "ISO-8859-10:1992", "csISOLatin6", "ISO-8859-9", "iso-ir-148", "latin5", "csISOLatin5", "ISO-8859-8", "ISO 8859-8-I", "iso-ir-138", "hebrew", "csISOLatinHebrew", "ISO-8859-7", "ECMA-118", "greek", "iso-ir-126", "csISOLatinGreek", "ISO-8859-6", "ISO-8859-6-I", "ECMA-114", "ASMO-708", "arabic", "iso-ir-127", "csISOLatinArabic", "ISO-8859-5", "cyrillic", "iso-ir-144", "csISOLatinCyrillic", "ISO-8859-4", "latin4", "iso-ir-110", "csISOLatin4", "ISO-8859-3", "latin3", "iso-ir-109", "csISOLatin3", "ISO-8859-2", "latin2", "iso-ir-101", "csISOLatin2", "KOI8-U", "KOI8-RU", "KOI8-R", "csKOI8R", "iscii-mlm", "iscii-knd", "iscii-tlg", "iscii-tml", "iscii-ori", "iscii-gjr", "iscii-pnj", "iscii-bng", "iscii-dev", "TSCII") msvc编译器在遇到中文时表现出和mingw编译器完全不一样的情况。遇到中文,大概率会碰到“常量中有换行符”等错误 因MSVC默认是采用ANSI,而MingW采用UTF-8编码 由于编辑器默认是utf-8存储内容,msvc对utf-8保存的中文会误解,如果恰好把部分utf-8解释成了换行符,就会报上述错误。 解决方式是设置编辑器为utf-8 带 bom,主动告诉msvc不要将他认成ANSI文件 同时使用QString::fromLocal8Bit 或 QStringLiteral 消除乱码。注意,在MSVC编译器下,QStringLiteral 表现行为与QString::fromLocal8Bit 一致而非QString::fromUtf8,这应该与编译器编译出的二进制文件内容存储格式有关,一个是ANSI,一个是UTF-8
QString message = ("中文常量:");
QFile file("test.txt");
if(true == file.open(QIODevice::ReadWrite | QIODevice::Append))
{
QTextStream stream(&file);
stream << message << "\r\n";
file.flush();
file.close();
}
QTextCodec* codec = stream.codec();
QByteArray arr = codec->name();
stream.setCodec("utf-8");
stream.setGenerateByteOrderMark(false);// 不带bom的utf8
变量编码QTextCodec
QByteArray utf8Str = "...";
QTextCodec *codec = QTextCodec::codecForName("UTF-8");
QString str = codec->toUnicode(utf8Str);
QTextCodec *codec = QTextCodec::codecForName("GBK");
QByteArray gbkStr = codec->fromUnicode(str);
MSVC编译器