分布式调度器xxl-job
前言
学习过程中可以把防火墙暂时关掉,防止链接不上的问题
netsh advfirewall show allprofiles //windows查看防火墙状态
netsh advfirewall set allprofiles state off //windows关闭防火墙
sudo systemctl disable firewalld //linux设置开机时关闭防火墙
systemctl status firewalld //linux 查看防火墙状态
文章目录
- xxl-job 理论
-
- 分布式调度器的必要性
- xxl-job分布式调度器
- 解决的问题
- xxl-job Demo
-
- 搭建xxl-job
- 数据库的创建
- Java执行器的编写
- 演示效果
xxl-job 理论
分布式调度器的必要性
-
处理大规模任务:如果您需要处理大规模的任务调度,单一的调度器可能无法满足需求。分布式调度器可以将任务分散到多个节点上执行,以确保高效的任务处理和资源利用。
-
高可用性:分布式调度器可以提供高可用性的任务调度服务。通过将任务分布到多个节点上,即使其中一个节点发生故障,其他节点仍然可以继续执行任务,确保任务的连续性和可靠性。
-
横向扩展性:随着业务的增长,任务调度的工作负载可能会变得更加繁重。使用分布式调度器,您可以轻松地横向扩展系统,将任务分布到多个节点上执行,以应对高负载的需求。
-
灵活性和功能丰富:分布式调度器通常提供更多的任务调度选项和灵活的配置方式。它们可以支持复杂的调度策略、任务依赖关系管理、失败重试机制等功能,以满足不同场景下的任务调度需求
-
负载均衡:分布式调度器可以根据节点的负载情况智能地分配任务,实现负载均衡。这可以确保每个节点都能够充分利用资源,并避免单点故障导致的任务堆积或延迟
总的来说,分布式调度器可以帮助您提高任务调度的性能、可靠性和可扩展性。它可以适应大规模任务、高可用性以及复杂调度需求的场景,使您的任务调度系统更加健壮和灵活。
xxl-job分布式调度器
平台负责发起 调度请求,由执行器接收调度请求并执行任务。通过这种方式即可实现 调度 与 任务 相互解耦,从而提高系统整体的稳定性和拓展性。
解决的问题
- 避免任务的重复执行
- 如果某台机器宕机了,会不会存在任务丢失。
- 如果要增加服务实例,怎么做到弹性扩容。
xxl-job官网
xxl-job Demo
搭建xxl-job
docker 拉取xxl-job
查看xxl-job版本(需要链接外网)
docker 拉取xxl-job
docker pull xuxueli/xxl-job-admin:2.4.0
配置application.properties
### web
server.port=8080
server.servlet.context-path=/xxl-job-admin
### actuator
management.server.servlet.context-path=/actuator
management.health.mail.enabled=false
### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.resources.static-locations=classpath:/static/
### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.##########
### mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://localhost/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
spring.datasource.hikari.validation-timeout=1000
### xxl-job, email
# 这是aliyun的别的百度找一下
spring.mail.host=smtp.aliyun.com
spring.mail.port=25
spring.mail.username=你的邮件
spring.mail.from=配置邮件
spring.mail.password=Lhb13525928711!
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en")
xxl.job.i18n=zh_CN
## xxl-job, triggerpool max size
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### xxl-job, log retention days
xxl.job.logretentiondays=30
需要修改的地方
- ip地址
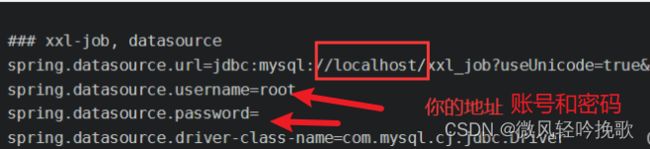
- 配置邮件

docker 中开启并将其持久化
注意这里的地址和配置文件要自己对应
docker run -p 8085:8080 --privileged=true -v /root/docker/xxl-job-admin/application.properties:/config/application.properties -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:2.4.0
运行成功之后在网址打开即可看到
[xxl-job分布式调度器 http://localhost:8080/xxl-job-admin 自己的ip和端口号
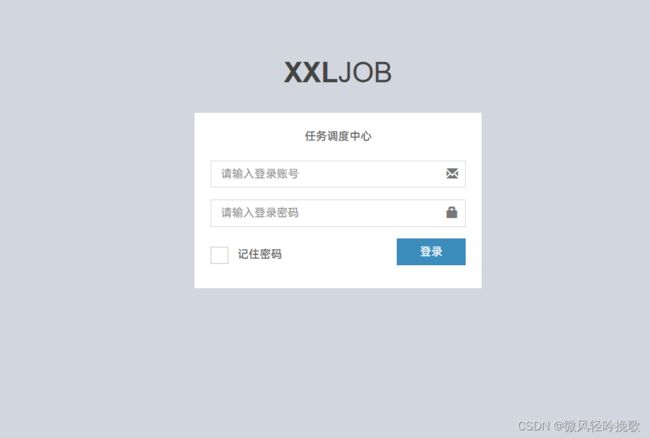
账号 admin 密码 123456
数据库的创建
数据库管理工具运行即可
# XXL-JOB v2.4.0-SNAPSHOT
# Copyright (c) 2015-present, xuxueli.
CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;
Java执行器的编写
- 引入依赖
<dependency>
<groupId>com.xuxueligroupId>
<artifactId>xxl-job-coreartifactId>
<version>2.4.0version>
dependency>
- 配置文件config
下载DEMO
从demo中复制即可
import cn.hutool.core.net.NetUtil;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
// @Value("${xxl.job.executor.port}")
// private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
int port = NetUtil.getUsableLocalPort();
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
*
* org.springframework.cloud
* spring-cloud-commons
* ${version}
*
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
- application.properties
注:上方的config中端口随机生成啦一个,而下面默认配的是9999如果按照demo的来可以直接复制gitee上的config/XxlJobConfig
# web port
server.port=8081
# no web
#spring.main.web-environment=false
# log config
logging.config=classpath:logback.xml
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job executor appname
xxl.job.executor.appname=xxl-job-executor-sample
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port=9999
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30
- demo
(1)发送一条push-order消息
(2)访问百度
import cn.hutool.http.HttpRequest;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONUtil;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* XxlJob开发示例(Bean模式)
*
* 开发步骤:
* 1、任务开发:在Spring Bean实例中,开发Job方法;
* 2、注解配置:为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。
* 3、执行日志:需要通过 "XxlJobHelper.log" 打印执行日志;
* 4、任务结果:默认任务结果为 "成功" 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 "XxlJobHelper.handleFail/handleSuccess" 自主设置任务结果;
*
* @author xuxueli 2019-12-11 21:52:51
*/
@Slf4j
@Component
public class ExpXxlJob {
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("push-order")
public void demoJobHandler() throws Exception {
XxlJobHelper.log("push-order");
log.info("-----push-order-----");
}
@XxlJob("ping-baidu")
public void httpJobHandler() throws Exception {
//读取任务管理器的参数
String param = XxlJobHelper.getJobParam();
HashMap hashMap = JSONUtil.toBean(param, HashMap.class);
if("get".equals(hashMap.get("method"))){
HttpRequest get = HttpUtil.createGet("http://www.baidu,com");
log.debug("百度 {}",get);
XxlJobHelper.log("{}",get);
}
}
}
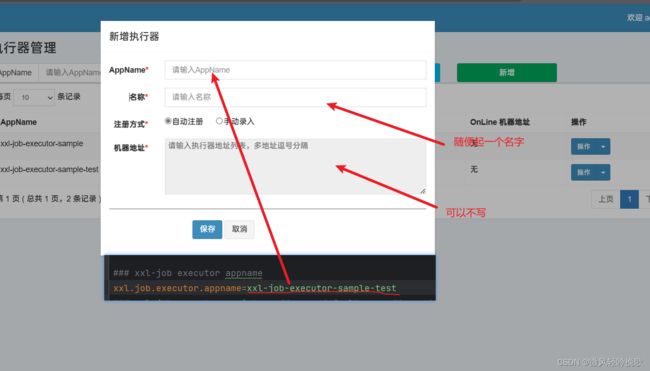
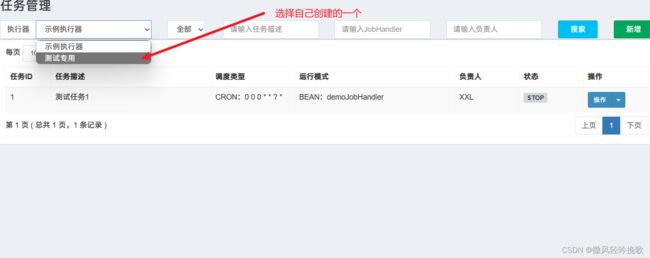
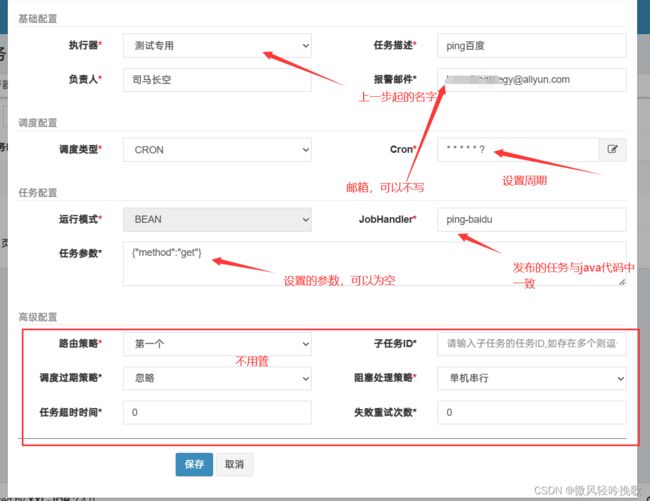
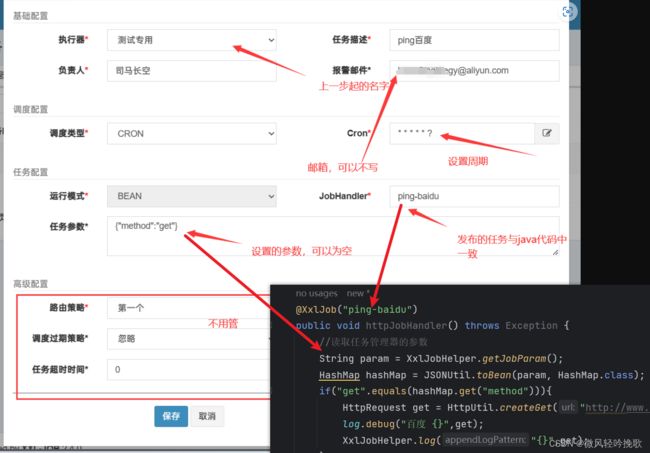
5. 启动程序 然后运行分布调度器的任务

5.1 在网页中开启调度
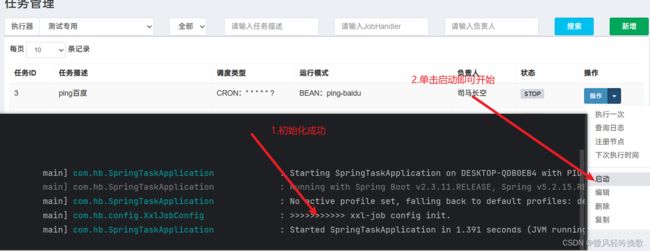
5.2 查看任务的端口和ip
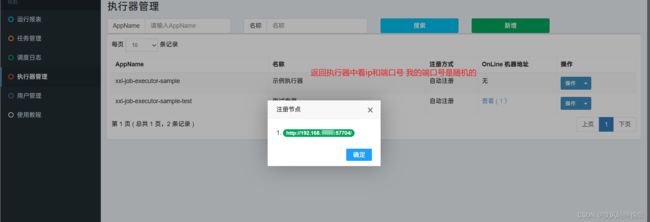
5.3 成功

演示效果
xxl-job是分布式调度器可以防止因某个线程ga导致的副作用,这里简单演示一下
- 打包后直接运行jar包 同时开启原程序
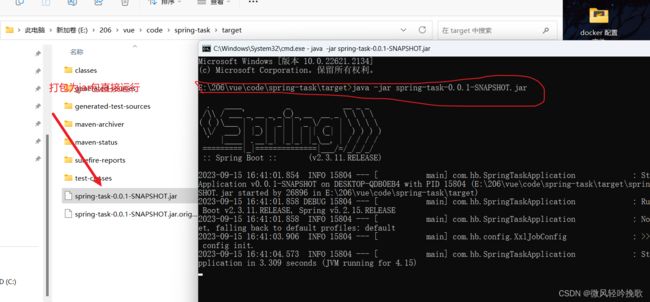
- 开启原程序记得修改端口号
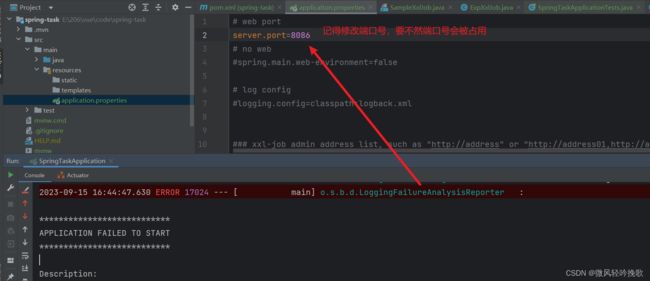

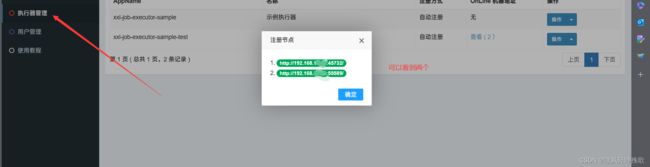
- 运行
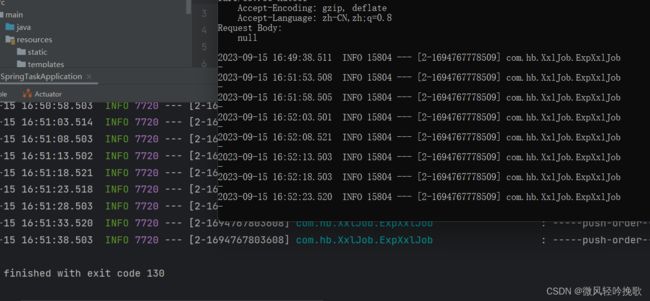
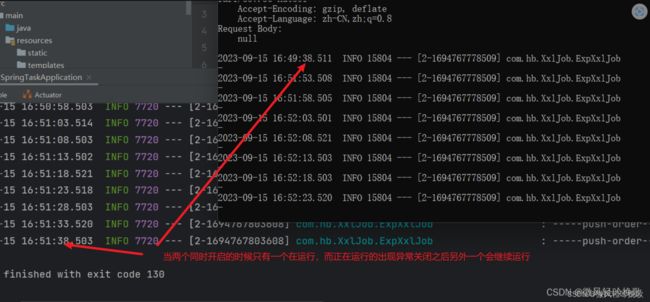
- 这是一个动图模拟线程出现问题的情况一个结束以后另一个开始运行
到这里可以明显看到当一个出现异常另一个就会紧接着进行调度