详解MySQL事务与锁
一、MySQL事务概述
1、事务四大特性(ACID)
- A:Atomicity,原子性,要么全部执行,要么全部都不执行
- 例如:张三银行账号金额的扣减和李四账号金额的增加都生效,或者都不生效
- C:Consistency,一致性,满足现实世界业务的约束
- 例如:不管转账成功还是失败,两人的存款总金额是一致的
- I:Isolation,隔离性,并行事务之间互不影响
- 例如:事务A不能看到事务B未提交的数据
- 并行事务之间存在的问题:
- 脏写:Dirty Write,一个事务 修改 了另一个未提交事务修改过的数据
- 脏读:Dirty Read,一个事务 读取 到了另一个未提交事务修改过的数据
- 不可重复读:Non-Repeatable Read,在相同条件下,一个事务多次读取某记录,读取到结果不一致
- 幻读: Phantom,一个事务按照某个相同条件多次读取记录,后读取时读到了之前没有读到的记录
存在问题后续会进行详细讲解
- 隔离级别:
- READ UNCOMMITTED:未提交读,可能发生
脏读、不可重复读和幻读问题 - READ COMMITTED:RC,已提交读,可能发生
不可重复读和幻读问题 - REPEATABLE READ:RR,可重复读,是MySQL默认的隔离级别,可能发生
幻读问题 - SERIALIZABLE:可串行化,上述问题均不可能发生
- READ UNCOMMITTED:未提交读,可能发生
- D:Durability,持久性,事务一旦提交,就会永久保留到数据库中
- 数据库服务宕机也不会造成数据丢失
- 特别说明:
- ACID是SQL标准定义的事务的特性,不同的数据库对此的实现不同,不代表Mysql完全按照此规范运行的。
- 一致性:SQL规范定义了CHECK关键字(例如:CHECK(score <= 750) 代表分数不能大于750分)语句,但mysql没有支持。
- 隔离性:SQL规范定义“REPEATABLE READ”隔离级别允许发生幻读,但是mysql不会在“REPEATABLE READ”隔离级别时发生幻读。
2、并行事务存在问题
2.1、脏写
- 脏写:Dirty Write,一个事务 修改 了另一个未提交事务修改过的数据
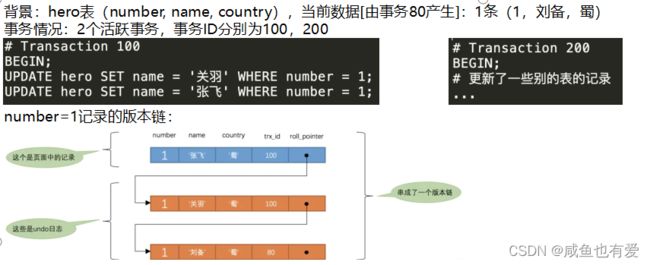
- Hero表中存在数据项:name=‘刘备’, number = 1

- Session A和Session B各开启了一个事务,Session B中的事务先将number列为1的记录的name列更新为’关羽’,然后Session A中的事务接着又把这条number列为1的记录的name列更新为张飞。如果之后Session B中的事务进行了回滚,那么Session A中的更新也将不复存在(name仍然为’刘备’),即发生了脏写
2.2、脏读
- 脏读:Dirty Read,一个事务 读取 到了另一个未提交事务修改过的数据

- Session A和Session B各开启了一个事务,Session B中的事务先将number列为1的记录的name列更新为’关羽’,然后Session A中的事务再去查询这条number为1的记录,如果读到列name的值为’关羽’,而Session B中的事务稍后进行了回滚,那么Session A中的事务相当于读到了一个不存在的数据,此即发生了脏读
2.3、不可重复读
- 不可重复读:Non-Repeatable Read,在相同条件下(相同的查询语句),一个事务多次读取某记录,读取到结果不一致

- 在Session B中提交了几个隐式事务(注意是隐式事务,意味着语句结束事务就提交了),这些事务都修改了number列为1的记录的列name的值,每次事务提交之后,Session A中的事务都可以查看到最新的值(Session A中多次相同的查询操作得到的结果不一致),此即发生了不可重复读
2.4、幻读
- 幻读: Phantom,一个事务按照某个相同条件多次读取记录时,后读取时读到了之前没有读到的记录,即同一个事务内多次查询返回的结果集总数不一样(比如增加了或者减少了行记录)

- Session A中的事务先根据条件number > 0这个条件查询表hero,得到了name列值为’刘备’的记录;之后Session B中提交了一个隐式事务,该事务向表hero中插入了一条新记录;之后Session A中的事务再根据相同的条件number > 0查询表hero,得到的结果集中包含Session B中的事务新插入的那条记录,即发生了幻读
- 不可重复读和幻读的区别
不可重复读针对的是一项数据记录的修改操作,幻读针对的是多项数据记录的修改(新增、删除、修改) - 小总结

3、其他
3.1、事务提交模式
- 自动提交:开启配置后,每条语句都是单独的一个事务。(这是个不好的编程习惯)
- 设置语法:SET autocommit = ON;
- 此时无论是读请求/写请求,都会默认开启一个事务(按照mysql默认的隔离级别执行
- 手动提交:
- 开启:BEGIN; 或者 START TRANSACTION [READ ONLY| READ WRITE];
- 提交:COMMIT;
- 回滚:ROLLBACK;
- 保存点(实现部分回滚):
- 声明一个保存点:SAVEPOINT savepoint_name;
- 删除一个保存点:RELEASE SAVEPOINT savepoint_name;
- 回滚至某个保存点:ROLLBACK TO savepoint_name;
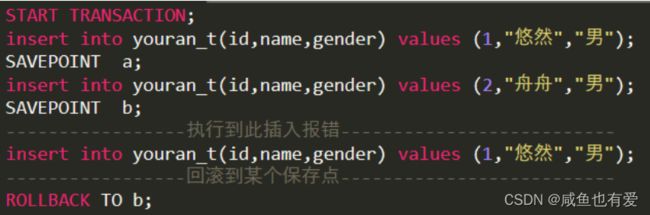
- 隐式提交:不需要手动开启事务,也不受“自动提交”设置的影响,例如DDL语句
3.2、事务隔离级别设置
- 事务隔离级别设置:SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level;
- 使用GLOBAL关键字:全局范围内影响,不影响已存在的会话
- 使用SESSION关键字:会话范围内影响,对所有后续的事务有效
- 上述两个关键字都不用:只对当前会话中下一个即将开启的事务有效
- Mysql默认隔离级别为“可重复读”,生产环境的项目使用的隔离级别为“读已提交”,必要时才会使用“可重复读”
二、MySQL事务原理
1、持久性原理
- 持久性是指事务一旦提交永久保留,即使数据库宕机,服务器宕机,也不会造成数据丢失
- 操作系统背景:数据写入文件的过程

- 有人会问,为了保证数据不丢失,每次COMMIT时,将数据都刷到硬盘上,不就可以了吗?
- 一个事务内可能会有多个SQL语句,可能会操作不同的表,且表之间的页并不相邻,会产生大量的随机IO
- INSERT/UPDATE语句,可能会更新多个辅助索引,会有大量的随机IO
- 磁盘IO本身就慢,而产生的随机IO会更慢
1.1、InnoDB内存管理
- Buffer Pool:缓冲池,在MySQL服务器启动时,会向操作系统申请一片连续的内存空间,默认大小为128MB,其主要目的是缓解CPU和硬盘速度差距过大的矛盾
- 数据的读取,先读取到Buffer Pool的缓存页,再从缓存页返回给客户端
- 数据的修改,一般先修改Buffer Pool的缓存页,再由缓存页去刷新磁盘(在适当时机)
- InnoDB数据的修改机制:事务内每个SQL的修改,都需要先修改Buffer Pool中的缓存页(修改之后没有刷盘的页就称为脏页),每次事务提交时,不会立刻刷盘,而是在合适的时机(如内存不够用)进行刷盘
- 在如上的数据修改机制下,就需要redo日志来保证MySQL宕机时数据不会出现丢失
1.2、redo日志
- redo日志:重做日志,针对 记录 修改操作的日志,在系统崩溃后重启时,按照此日志重新执行,便能恢复没有被持久化的数据页
- 在事务提交之前,将redo日志刷盘,既保证了性能,又保证系统宕机时脏页(修改操作之后没有刷盘的数据页)数据不会丢失
- redo日志的通用格式:

- 物理概念:根据space ID(表空间ID)、page number(页号),可以唯一地定位物理硬盘上的页
- 逻辑概念:data,记录对应的页是如何修改的
- redo日志是一个日志文件,总大小有限制,需要循环写入
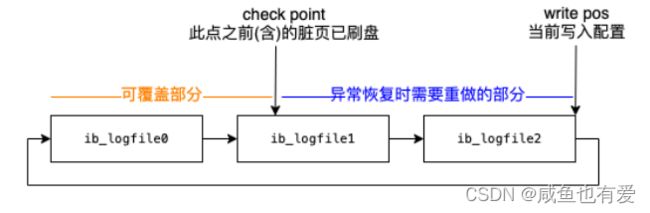
- 查看redo日志的存储位置

2、原子性原理
2.1、undo日志
- 原子性:一个或多个sql要么全部执行,要么全部都不执行
- 当执行ROLLBACK时,数据需要回滚到之前的状态,这由undo日志保证
- undo日志,也称为撤销日志,在修改操作之前,会记录数据状态的快照
- mysql行格式:隐藏列有一个回滚指针(roll_pointer),指向undo日志

undo日志链(版本链)示意图:
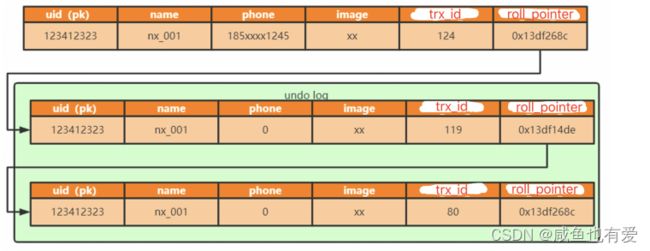
当执行ROLLBACK时,会找到上一个事务对应的undo日志记录,并执行复原 - undo日志分类:
- insert undo log:insert语句产生的undo日志,用于回滚,提交事务后则清理
- update undo log:update/delete语句产生的undo日志,用于回滚,同时实现快照读,不能随便删除,由专门的线程(purge)来执行清理
3、隔离性原理
3.1、undo + MVCC
- MVCC:Multiversion Concurrency Control,多版本并发控制,借助undo日志构造的版本链,实现对数据库的并发访问(实现了读-写,写-读的并发执行,提高性能)
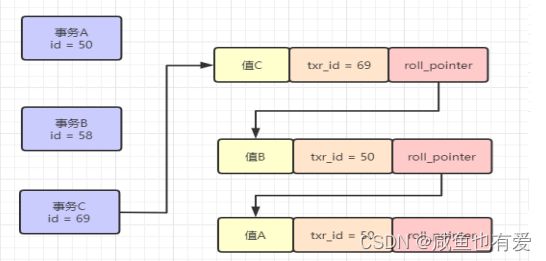
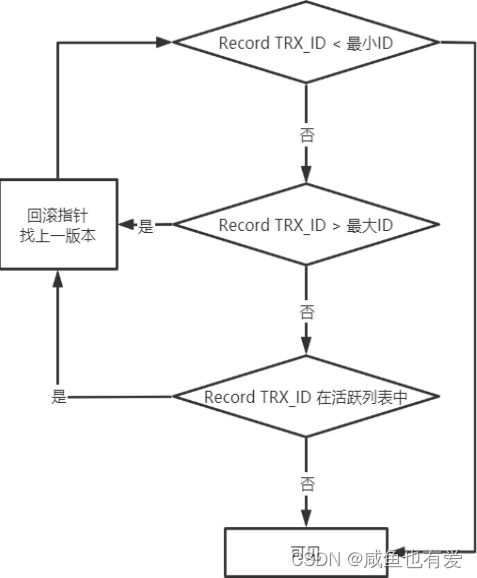
- ReadView:一种在innodb内存中的数据结构,由于判断数据项是否对当前事务可见(RR级别),其主要组成是包括m_ids、min_trx_id、max_trx_id、creator_trx_id
- m_ids:未提交的事务ID列表
- min_trx_id:未提交的事务ID列表中的最小ID,
- max_trx_id:最大ID,即下一个分配事务的id值
- creator_trx_id:当前事务ID
- 可见性判断逻辑:(trx_id表示访问记录的隐藏列的trx_id,trx_id代表了修改此记录的事务的ID)
- trx_id = creator_trx_id:意味着当前事务在访问它自己修改过的记录(可见)
- trx_id < min_trx_id:表明生成该版本的事务在当前事务生成ReadView前已经提交(可见)
- trx_id >= max_trx_id:表明生成该版本的事务在当前事务生成ReadView后才开启(不可见)
- min_trx_id <= trx_id < max_trx_id:判断一下trx_id属性值是不是在m_ids列表中
如果在,说明创建ReadView时生成该版本的事务还未提交(不可见)
如果不在,说明创建ReadView时生成该版本的事务已经被提交(可见)
- 生成ReadView的时机:
- READ COMMITTED:每次读取数据前都生成一个ReadView,但会造成脏读,可使用REPEATABLE READ解决脏读问题
- REPEATABLE READ:第一次读取数据时生成一个ReadView,之后复用。不但解决脏读,还可以解决不可重复读的问题
3.2、MVCC的ReadView
1)RC为什么无法解决不可重复读的问题
- 因为在RC(READ COMMITTED)的隔离级别下,每次读取数据前都生成一个ReadView
- 举例说明:
- 执行情况(按照时间顺序):
- 步骤1:事务2[trx_id=200]第一次读: SELECT * FROM hero WHERE number = 1;
ReadView1:活跃事务ID集合=[100,200],最小事务ID= 100,最大事务ID=201,当前事务ID=200
快照读过程(MVCC):
版本链第一/二条记录判断[trx_id=100]:由于【最小事务ID(100) <= 记录ID(100) < 最大事务ID(201)】,但是【记录ID(100) in 活跃[100,200]】,不可见。
版本链第三条记录判断[trx_id=80]:由于【记录ID < 最小事务ID(100) 】,可见
结果:得到的列name的值为’刘备’ - 步骤2:事务1[trx_id=100]提交:COMMIT;
- 步骤3:事务2[trx_id=200]第二次读:SELECT * FROM hero WHERE number = 1;
ReadView2:活跃事务ID集合=[200],最小事务ID= 200,最大事务ID=201,当前事务ID=200
快照读过程(MVCC):版本链第一条记录判断[trx_id=100]:由于【记录ID(100) < 最小记录ID(200)】,可见
结果:得到的列name的值为’张飞’ ,事务2两次读取的name值不一致,即出现不可重复读的问题
- 步骤1:事务2[trx_id=200]第一次读: SELECT * FROM hero WHERE number = 1;
2)RR为什么可以解决不可重复读的问题
- REPEATABLE READ:第一次读取数据时生成一个ReadView,之后复用
- 举例说明:

- 执行情况(按照时间顺序):
- 步骤1:事务2[trx_id=200]第一次读: SELECT * FROM hero WHERE number = 1;
ReadView:活跃事务ID集合=[100,200],最小事务ID= 100,最大事务ID=201,当前事务ID=200
快照读过程(MVCC):- 版本链第一/二条记录判断[trx_id=100]:由于【最小事务ID(100) <= 记录ID(100) < 最大事务ID(201)】,但是【记录ID(100) in 活跃[100,200]】,不可见。
- 版本链第三条记录判断[trx_id=80]:由于【记录ID < 最小事务ID(100) 】,可见
结果:得到的列name的值为’刘备’
- 步骤2:事务1[trx_id=100]提交:COMMIT;
- 步骤3:事务2[trx_id=200]第二次读:SELECT * FROM hero WHERE number = 1;
ReadView:活跃事务ID集合=[100,200],最小事务ID= 100,最大事务ID=201,当前事务ID=200【不变】
快照读过程(MVCC):与步骤1 一致(复用第一次读取数据时 生成的ReadView)
结果:得到的列name的值为’刘备’
- 步骤1:事务2[trx_id=200]第一次读: SELECT * FROM hero WHERE number = 1;
三、MySQL- 锁
1、锁-基础
-
锁:管理对共享资源的并发访问,本质上是内存中的数据结果,描述了锁定的共享资源和锁定方式
-
锁机制,解决的是多个事务同时更新数据的问题
- 读-读:无需加锁。
- 写-写:需要加锁(并非一定要程序员显式加锁,数据库会自己加锁) ,否则会产生脏写。
- 读-写/写-读:可能产生脏读、不可重复读、幻读等现象。
- 解决方案1:读采用MVCC方式,写加锁。相互不冲突,并发高(一般情况下采用此方式)
- 解决方案2:读加锁,写加锁。串行执行(某些特殊业务场景下)
-
必须加锁读的例子:
- 判断A账户钱是否 >= 100,若是,则扣减交易,若否,则交易失败(由于涉及金钱交易,redis等分布式锁的一丁点差错都不能容忍,所以使用数据库的锁

- 判断A账户钱是否 >= 100,若是,则扣减交易,若否,则交易失败(由于涉及金钱交易,redis等分布式锁的一丁点差错都不能容忍,所以使用数据库的锁
-
按照锁的作用来区分
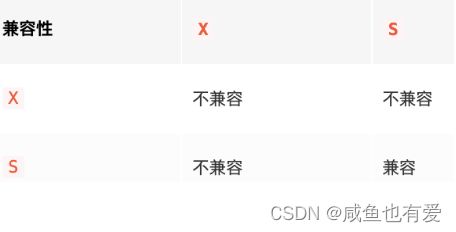
- 共享锁:读锁,S锁
- 排他锁:写锁,X锁
-
按照锁的粒度来区分:
- 行级锁:对于行级别的数据加锁
- 表级锁:对整个表加锁
-
如何加锁:
- 表级别的共享锁:lock tables user read;
- 表级别的排他锁:lock tables user write;
- 行级别的共享锁:select x in share mode;
- 行级别的排他锁:select x for update; 或 insert 或update 或delete
-
读取数据项的两种模式
- 快照读:采用MVCC的方式读取,普通的select语句均为此模式
select * from t where xxx; - 当前读:读取的是数据项的最新版本,且在读取完成后需要保证数据不被其他事务修改,因此锁涉及到的加锁模式,均为此模式
select * from t where xxx for update;---------X锁
select * from t where xxx lock in share mode;---------S锁
update / insert / delete---------X锁
- 快照读:采用MVCC的方式读取,普通的select语句均为此模式
-
加行级锁时,读取记录方式为当前读,不采用MVCC,而事务的隔离级别仍然要实现,是基于行级锁的算法实现
-
读写锁,是最简单直接的事务隔离的实现方式
- 每次读操作需要获取一个共享锁(读锁),每次写操作需要获取一个写锁
- 共享锁之间不会互斥,共享锁和写锁之间,以及写锁和写锁之间会互斥
- 当产生锁竞争时,需要等待其中一个操作释放锁之后,另外的操作才能获取到锁)
2、行级锁
- 行锁,也称为记录锁,解决的是多个事务同时更新一行数据
- 只有通过索引条件来检索数据时,InnoDB才会使用行级锁,否则,就会使用表级锁
- 如果使用的是相同的索引键,即使是访问不同行的数据记录,也会发生锁冲突
- 如果数据表在建立时有多个索引,则可以通过不同的索引 锁定不同的数据记录

2.1、行锁作用位置
- 行级锁作用位置(由加锁过程可知,先查询出数据,再执行锁定,查询数据要选择索引)
- 主键索引
- 唯一的辅助索引
- 普通的辅助索引
2.2、行锁算法
- Record Lock:单个行记录上的锁,Record锁总是会去锁住索引记录,如果InnoDB存储引擎在建表时,没有设置任何索引,InnoDB会使用隐式的主键来锁定

- Gap Lock:间隙锁,锁当前数据项(不含)到下一条数据项中间的间隙(不含)【左开右开】
- 当用范围条件而非等值条件来检索数据 并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录加锁 以及在条件范围内但并不存在的记录加锁
- 解决了事务并发的幻读问题,但是,当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成锁定的时候无法插入锁定键值范围内任何数据。在某些场景下这可能会对性能造成很大的危害。

- Next-key Lock:即Record Lock+Gap Lock,锁定当前数据项(不包含)到下一条数据项(包含)【左开右闭】,Next-key Lock是默认的行记录锁定算法
2.3、加锁分析
- 加锁目的:避免脏写、脏读、不可重复读、幻读等现象的发生,满足事务隔离级别的要求
- 采用InnoDB,对于一个SQL语句,具体加的什么锁会受到多个因素影响,因素如下:
- 事务的隔离级别(RC、RR)
- 语句执行时使用的索引(主键索引、唯一普通索引、普通辅助索引)
- 查询条件(等值查询、范围查询)
- 具体执行的语句(select … for update; insert、update、delete)
2.4、分析举例
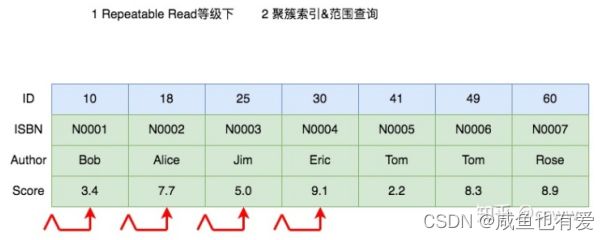
- 以下面这张 book 表作为实例,其中 id 为主键,ISBN(书号)为二级唯一索引,Author(作者)为二级非唯一索引,score(评分)无索引

- 分析 UPDATE 相关 SQL 在使用较为简单 where 从句情况下加锁情况。其中的分析原则也适用于 UPDATE,DELETE 和 SELECT … FOR UPDATE等当前读的语句
1)聚簇索引加锁
- 聚簇索引,查询命中
UPDATE book SET score = 9.2 WHERE ID = 10

- 聚簇索引,查询未命中
UPDATE book SET score = 9.2 WHERE ID = 16
在 RC 隔离等级下,不需要加锁;而在 RR 隔离级别会在 ID = 16 前后两个索引之间(ID=10,18)加上间隙锁

- 聚簇索引,范围查询
UPDATE book SET score = 9.2 WHERE ID <= 25
在RC 隔离级别下,与等值查询类似,只会在涉及的 ID = 10,ID = 18 和 ID = 25 索引上加排他记录锁

在 RR 隔离等级下,会加上间隙锁,和对应的记录锁合称为 Next-Key 锁
2)唯一索引加锁
- 二级唯一索引,查询命中
UPDATE book SET score = 9.2 WHERE ISBN = 'N0003'
在 InnoDB 存储引擎中,二级索引的叶子节点保存着主键索引的值,然后再拿主键索引去获取真正的数据行,所以在这种情况下,二级索引和主键索引都会加排他记录锁

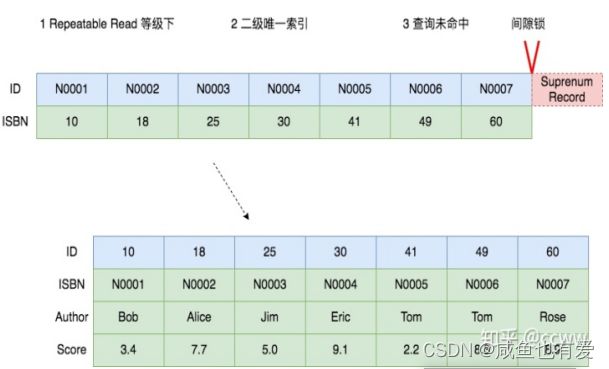
- 二级唯一索引,查询未命中
UPDATE book SET score = 9.2 WHERE ISBN = 'N0008'
在二级索引中加间隙锁,聚簇索引不加锁
2.5、如何上锁
- 隐式上锁(默认+自动)
SELECT // 不会上锁
INSERT、UPDATE、DELETE // 上写锁
- 显示上锁(手动)
select * from tableName lock in share mode;// 读锁
select * from tableName for update; // 写锁
3、意向锁
- 意向锁(Intention Locks),可分为意向共享锁和意向排他锁
- 意向共享锁,Intention Shared Lock,简称IS锁,当事务准备在某条数据记录上加S锁前,需要先在表级别添加IS锁
- 意向独占锁:Intention Exclusive Lock,简称IX锁,当事务准备在某条数据记录上加X锁前,需要先在表级别添加一个IX锁
- 意向锁存在的意义:仅仅是为了在之后加表级别的S锁和X锁时,可以快速判断表中的数据记录是否被上锁,以避免通过遍历的方式来查看表中有没有上锁的数据记录(不需要程序员手动上锁)
4、其他
4.1、表锁
- 表锁:对整张表加锁,其特点是开销小、加锁快、无死锁、锁粒度大,发生锁冲突概率大,并发性低
- 读锁(read lock),也叫共享锁(shared lock)
- 针对同一份数据,多个读操作可以同时进行而不会互相影响(select)
- 读锁会阻塞写操作,不会阻塞读操作
- 写锁(write lock),也叫排他锁(exclusive lock)
- 当前操作没完成之前,会阻塞其它读和写操作(update、insert、delete)
- 写锁会阻塞读操作和写操作
4.2、页锁
- 页锁:开销、加锁时间和锁粒度介于表锁和行锁之间,会出现死锁,并发处理能力一般,不多做介绍
4.3、悲观锁和乐观锁

5、如何排查锁
- 表锁
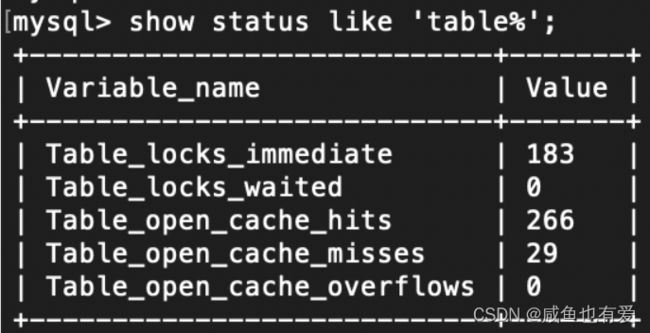
# 查看表锁情况
show open tables;
# 进行表锁分析的SQL
show status like 'table%';

- 行锁
show status like 'innodb_row_lock%';
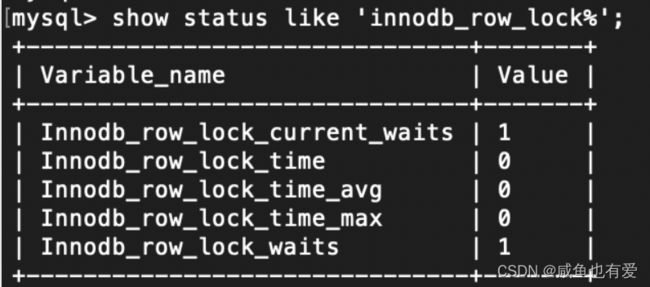
1)innodb_row_lock_current_waits //当前正在等待锁定的数量
2) innodb_row_lock_time //从系统启动到现在锁定总时间长度
3)innodb_row_lock_time_avg //每次等待所花平均时间
4)innodb_row_lock_time_max //从系统启动到现在等待最长的一次所花时间
5)innodb_row_lock_waits //系统启动后到现在总共等待的次数