Spark-3.2.4 高可用集群安装部署详细图文教程
目录
一、Spark 环境搭建-Local
1.1 服务器环境
1.2 基本原理
1.2.1 Local 下的角色分布
1.3 搭建
1.3.1 安装 Anaconda
1.3.1.1 添加国内阿里源
1.3.2 创建 pyspark 环境
1.3.3 安装 spark
1.3.4 添加环境变量
1.3.5 启动 spark
1.3.5.1 bin/pyspark
1.3.5.2 WEB UI (4040)
1.3.5.3 spark-shell
1.3.5.4 bin/spark-submit
1.3.6 pyspark/spark-shell/spark-submit 对比
二、Spark 环境搭建-Standalone
2.1 Standalone 架构
2.2 搭建
2.2.1 各个节点安装 Anaconda
2.2.2 修改配置文件(在 hadoop01 上执行)
2.2.2.1 workers
2.2.2.2 spark-env.sh
2.2.2.3 spark-defaults.conf
2.2.2.4 log4j.properties(可选配置)
2.2.3 分发 Spark 安装目录
2.2.4 启动服务
2.2.5 查看 Master 的 WEB UI
2.2.6 连接到 StandAlone 集群
2.2.6.1 bin/pyspark
2.2.6.2 bin/spark-shell
2.2.6.3 bin/spark-submit (PI)
2.2.7 查看历史服务器 WEB UI
三、Spark 环境搭建-Standalone HA
3.1 背景
3.2 高可用 HA
3.3 基于 Zookeeper 实现 HA
3.3.1 spark-env.sh
3.3.2 启动 HA 集群
3.3.3 master 主备切换
一、Spark 环境搭建-Local
1.1 服务器环境
- 已部署好 Hadoop 集群(HDFS\YARN),要求版本 Hadoop3 以上
- JDK 1.8
- 操作系统 CentOS 7 (建议 7.6)
本次基于这篇文章的 Hadoop 集群环境搭建 Spark:Hadoop YARN HA 集群安装部署详细图文教程_Stars.Sky的博客-CSDN博客
| IP |
主机名 |
运行角色 |
| 192.168.170.136 |
hadoop01 |
namenode datanode resourcemanager nodemanager JournalNode DFSZKFailoverController QuorumPeerMain Spark |
| 192.168.170.137 |
hadoop02 |
namenode datanode resourcemanager nodemanager JournalNode DFSZKFailoverController QuorumPeerMain Spark |
| 192.168.170.138 |
hadoop03 |
datanode nodemanage JournalNode QuorumPeerMain Spark |
1.2 基本原理
本质:启动一个 JVM Process 进程(一个进程里面有多个线程),执行任务 Task。

Local 模式可以限制模拟 Spark 集群环境的线程数量, 即 Local[N] 或 Local[*]:
- 其中 N 代表可以使用 N 个线程,每个线程拥有一个 cpu core。如果不指定 N,则默认是 1 个线程(该线程有 1 个 core)。通常 Cpu 有几个 Core,就指定几个线程,最大化利用计算能力。
- 如果是 local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine,按照 Cpu 最多的 Cores 设置线程数。
1.2.1 Local 下的角色分布
资源管理:
- Master:Local 进程本身。
- Worker:Local 进程本身。
任务执行:
- Driver:Local 进程本身。
- Executor:不存在,没有独立的 Executor 角色,由 Local 进程(也就是 Driver)内的线程提供计算能力。
注意:
- Driver 也算一种特殊的 Executor,只不过多数时候,我们将 Executor 当做纯 Worker 对待, 这样和 Driver 好区分(一类是管理一类是工人) 。
- Local 模式只能运行一个 Spark 程序,如果执行多个 Spark 程序,那就是由多个相互独立的Local 进程在执行。
1.3 搭建
Spark 下载地址:Apache Downloads
Anaconda 下载地址:Index of /
1.3.1 安装 Anaconda
# 上传安装包后赋予权限
[root@hadoop01 ~]# chmod +x Anaconda3-2023.03-1-Linux-x86_64.sh
# 执行安装脚本
[root@hadoop01 ~]# ./Anaconda3-2023.03-1-Linux-x86_64.sh
先按回车键:
 再按空格键,直到出现让你输入 yes:
再按空格键,直到出现让你输入 yes: 最后输入安装路径,并耐心等待安装完成:
最后输入安装路径,并耐心等待安装完成:
最后进行初始化,输入 yes:

[root@hadoop01 ~]# source ~/.bashrc
# 测试安装是否成功
(base) [root@hadoop01 ~]# conda list
1.3.1.1 添加国内阿里源
(base) [root@hadoop01 ~]# vim ~/.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- http://mirrors.aliyun.com/anaconda/pkgs/main
- http://mirrors.aliyun.com/anaconda/pkgs/r
- http://mirrors.aliyun.com/anaconda/pkgs/msys2
custom_channels:
conda-forge: http://mirrors.aliyun.com/anaconda/cloud
msys2: http://mirrors.aliyun.com/anaconda/cloud
bioconda: http://mirrors.aliyun.com/anaconda/cloud
menpo: http://mirrors.aliyun.com/anaconda/cloud
pytorch: http://mirrors.aliyun.com/anaconda/cloud
simpleitk: http://mirrors.aliyun.com/anaconda/cloud
# 清除索引缓存
(base) [root@hadoop01 ~]# conda clean -i
1.3.2 创建 pyspark 环境
# 查看 python 版本
[root@hadoop01 ~]# python
Python 3.10.9 (main, Mar 1 2023, 18:23:06) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
# 创建一个新的独立的 Python 环境
[root@hadoop01 ~]# conda create -n pyspark python=3.10.9
# 切换环境
[root@hadoop01 ~]# conda activate pyspark
(pyspark) [root@hadoop01 ~]#1.3.3 安装 spark
(pyspark) [root@hadoop01 ~]# tar -zxvf spark-3.2.4-bin-hadoop3.2.tgz -C /bigdata/
(pyspark) [root@hadoop01 ~]# mv /bigdata/spark-3.2.4-bin-hadoop3.2/ /bigdata/spark-3.2.4
1.3.4 添加环境变量
(pyspark) [root@hadoop01 ~]# vim /etc/profile
# spark
export SPARK_HOME=/bigdata/spark-3.2.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PYSPARK_PYTHON=/usr/local/anaconda3/envs/pyspark/bin/python3.10
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native
(pyspark) [root@hadoop01 ~]# vim /root/.bashrc
export JAVA_HOME=/usr/java/jdk1.8.0_381
export PYSPARK_PYTHON=/usr/local/anaconda3/envs/pyspark/bin/python3.10
(pyspark) [root@hadoop01 ~]# source /etc/profile
- SPARK_HOME:表示 Spark 安装路径在那里;
- HADOOP_CONF_DIR:告知 Spark Hadoop 的配置文件在那里;
- PYSPARK_PYTHON:告知 Spark 运行 python 程序的执行器在哪里。
- LD_LIBRARY_PATH:加载 Hadoop 的本地库(通常是 C 语言编写的)
1.3.5 启动 spark
1.3.5.1 bin/pyspark
bin/pyspark 程序,可以提供一个交互式的 Python 解释器环境,在这里面可以写普通 python 代码,以及 spark 代码。
(pyspark) [root@hadoop01 ~]# cd /bigdata/spark-3.2.4/
[root@hadoop01 /bigdata/spark-3.2.4]# bin/pyspark
示例代码, 将数组内容都 +1进行计算:
sc.parallelize([1,2,3,4,5]).map(lambda x: x + 1).collect()
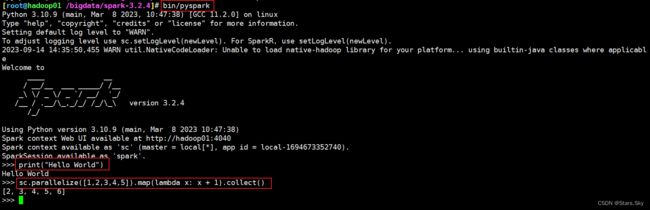
在这个环境内,可以运行 spark 代码。图中的 parallelize 和 map 都是 spark 提供的 API。
1.3.5.2 WEB UI (4040)
每一个 Spark 程序在运行的时候,会绑定到 Driver 所在机器的 4040 端口上。如果 4040 端口被占用,会顺延到 4041 ... 4042...
4040 端口是一个 WEBUI 临时端口,可以在浏览器内打开。输入:服务器 ip:4040 即可打开
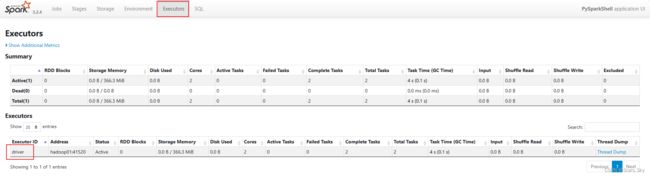
打开监控页面后,可以发现在程序内仅有一个 Driver,因为我们是 Local 模式,Driver 即管理 又干活。同时打开另一个终端,输入 jps,可以看到 local 模式下的唯一进程存在。这个进程即是 master 也是 worker。

注意:如果把当前的 pyspark 程序终止或退出(Ctrl + D)的话,SparkSubmit 进程 和 Web UI 页面也将终止和失效。
1.3.5.3 spark-shell
同样是一个解释器环境,和 bin/pyspark 不同的是,这个解释器环境 运行的不是python代码,而是 scala 程序代码。

这个仅作为了解即可,因为这个是用于 scala 语言的解释器环境。
1.3.5.4 bin/spark-submit
bin/spark-submit 程序,作用: 提交指定的 Spark 代码到 Spark 环境中运行。
# 语法
bin/spark-submit [可选的一些选项] jar 包或者 python 代码的路径 [代码的参数]
# 示例
[root@hadoop01 /bigdata/spark-3.2.4]# bin/spark-submit --master local[*] /bigdata/spark-3.2.4/examples/src/main/python/pi.py 10
# 此案例运行 Spark 官方所提供的示例代码来计算圆周率值。后面的 10 是主函数接受的参数,数字越高,计算圆周率越准确。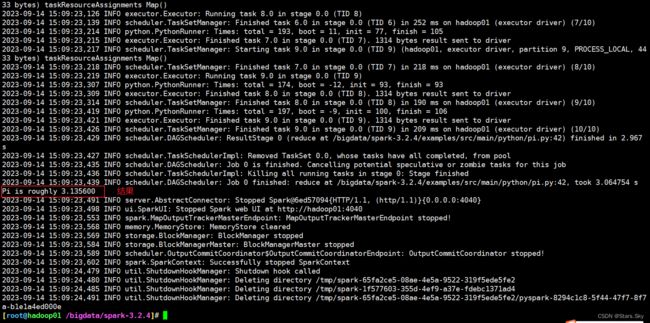
1.3.6 pyspark/spark-shell/spark-submit 对比
| bin/spark-submit | bin/pyspark | bin/spark-shell | |
|---|---|---|---|
| 功能 | 提交 java\scala\python 代码到spark中运行 | 提供一个 python 解释器环境用来以 python 代码执行 spark 程序 | 提供一个 scala 解释器环境用来以 scala 代码执行 spark 程序 |
| 特点 | 提交代码用 | 解释器环境 写一行执行一行 | 解释器环境 写一行执行一行 |
| 使用场景 | 正式场合,正式提交 spark程序运行 | 测试\学习\写一行执行一行\用来验证代码等 | 测试\学习\写一行执行一行\用来验证代码等 |
二、Spark 环境搭建-Standalone
2.1 Standalone 架构
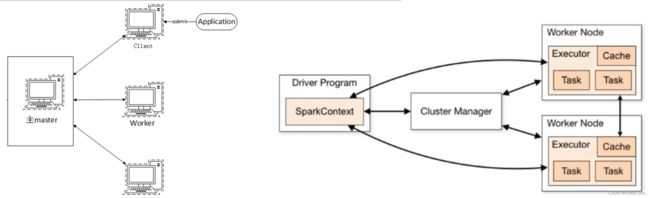
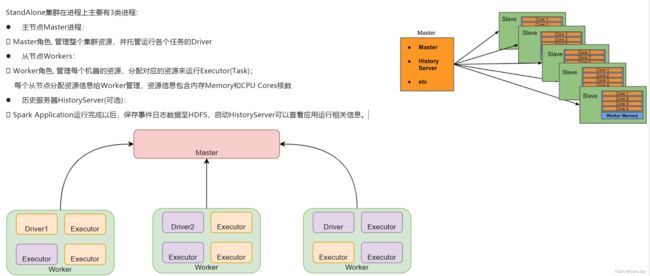
Standalone 模式是 Spark 自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone 模式是真实地在多个机器之间搭建 Spark 集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
StandAlone 是完整的 Spark 运行环境,其中:
- Master 角色以 Master 进程存在,Worker 角色以 Worker 进程存在;
- Driver 和 Executor 运行于 Worker 进程内,由 Worker 提供资源供给它们运行。
2.2 搭建
| IP |
主机名 |
运行角色 |
| 192.168.170.136 |
hadoop01 |
master worker |
| 192.168.170.137 |
hadoop02 |
worker |
| 192.168.170.138 |
hadoop03 |
worker |
2.2.1 各个节点安装 Anaconda
具体安装步骤同上面 1.3.1-1.3.4 是一样的。
2.2.2 修改配置文件(在 hadoop01 上执行)
2.2.2.1 workers
这个文件就是指示了当前 Spark StandAlone 环境下有哪些 worker:
[root@hadoop01 ~]# cd /bigdata/spark-3.2.4/conf/
[root@hadoop01 /bigdata/spark-3.2.4/conf]# mv workers.template workers
[root@hadoop01 /bigdata/spark-3.2.4/conf]# vim workers
hadoop01
hadoop02
hadoop032.2.2.2 spark-env.sh
[root@hadoop01 /bigdata/spark-3.2.4/conf]# mv spark-env.sh.template spark-env.sh
[root@hadoop01 /bigdata/spark-3.2.4/conf]# vim spark-env.sh
## 设置 JAVA 安装目录
JAVA_HOME=/usr/java/jdk1.8.0_381
## HADOOP 软件配置文件目录,读取 HDFS 上文件和运行 YARN 集群
HADOOP_CONF_DIR=/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
YARN_CONF_DIR=/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
## 指定 spark 老大 Master 的 IP 和提交任务的通信端口
# 告知 Spark 的 master 运行在哪个机器上
export SPARK_MASTER_HOST=hadoop01
# 告知 spark master 的通讯端口
export SPARK_MASTER_PORT=7077
# 告知 spark master 的 webui 端口
SPARK_MASTER_WEBUI_PORT=8081
# worker cpu 可用核数
SPARK_WORKER_CORES=1
# worker 可用内存
SPARK_WORKER_MEMORY=1g
# worker 的工作通讯地址
SPARK_WORKER_PORT=7078
# worker 的 webui 地址
SPARK_WORKER_WEBUI_PORT=8082
## 设置历史服务器
# 配置的意思是将 spark 程序运行的历史日志,存到 hdfs 的 /sparklog 文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop01:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
# 如果 hadoop 集群是 HA,则需要用下面的设置。要使用则把注释去掉
#SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://mycluster/sparklog/ -Dspark.history.fs.cleaner.enabled=true" 由于我的集群是高可用(HA)的,建议使用逻辑名称(Logical URI)而非具体的 Namenode 主机名和端口。这样可以确保即使当前的活动(Active)NameNode 发生变化,Spark 也能正确地找到日志目录。逻辑名称在 HA 配置中用于标识一个 Namenode 集群,而不是单个 Namenode。例如,如果逻辑名称是 mycluster,则您应该使用 hdfs://mycluster/sparklog/。
注意:这里的 mycluster 应该与您在 HDFS 配置文件(通常是 hdfs-site.xml)中定义的逻辑名称(NameService ID)相匹配。这样,HA 客户端库就能自动确定哪个 NameNode 当前是 Active,并且进行相应的操作。(后续的同理)
注意:上面的配置的路径要根据你自己机器实际的路径来写。
在 HDFS 上创建程序运行历史记录存放的文件夹:
[root@hadoop01 /bigdata/spark-3.2.4/conf]# hadoop fs -mkdir /sparklog
[root@hadoop01 /bigdata/spark-3.2.4/conf]# hadoop fs -chmod 777 /sparklog2.2.2.3 spark-defaults.conf
[root@hadoop01 /bigdata/spark-3.2.4/conf]# mv spark-defaults.conf.template spark-defaults.conf
[root@hadoop01 /bigdata/spark-3.2.4/conf]# vim spark-defaults.conf
# 开启spark的日期记录功能
spark.eventLog.enabled true
# # 设置spark日志记录的路径
spark.eventLog.dir hdfs://hadoop01:8021/sparklog/
# # 设置spark日志是否启动压缩
spark.eventLog.compress true
# hadoop HA 的配置,要使用则把注释去掉
#spark.eventLog.dir hdfs://mycluster/sparklog/2.2.2.4 log4j.properties(可选配置)
[root@hadoop01 /bigdata/spark-3.2.4/conf]# mv log4j.properties.template log4j.properties
[root@hadoop01 /bigdata/spark-3.2.4/conf]# vim log4j.properties
log4j.rootCategory=WARN, console
这个文件的修改不是必须的, 为什么修改为 WARN,因为 Spark 是个话痨会疯狂输出日志,设置级别为 WARN 只输出警告和错误日志,不要输出一堆废话。你如果为了更详细的信息可以默认 INFO。
2.2.3 分发 Spark 安装目录
[root@hadoop01 /bigdata]# cd /bigdata/
[root@hadoop01 /bigdata]# scp -r spark-3.2.4 hadoop02:$PWD
[root@hadoop01 /bigdata]# scp -r spark-3.2.4 hadoop03:$PWD
2.2.4 启动服务
# 启动历史服务器
[root@hadoop01 ~]# cd /bigdata/spark-3.2.4/sbin/
[root@hadoop01 /bigdata/spark-3.2.4/sbin]# ./start-history-server.sh
# 启动全部 master 和 worker
[root@hadoop01 /bigdata/spark-3.2.4/sbin]# ./start-all.sh
# 或者可以一个个启动:
# 启动当前机器的 master
sbin/start-master.sh
# 启动当前机器的 worker
sbin/start-worker.sh
# 停止全部
sbin/stop-all.sh
# 停止当前机器的 master
sbin/stop-master.sh
# 停止当前机器的 worker
sbin/stop-worker.sh
# 验证
[root@hadoop01 /bigdata/spark-3.2.4/sbin]# jps
7666 QuorumPeerMain
8739 DFSZKFailoverController
9315 NodeManager
8164 DataNode
9125 ResourceManager
10583 Worker
7977 NameNode
10649 Jps
8460 JournalNode
10492 Master
2.2.5 查看 Master 的 WEB UI
默认端口 master 我们设置到了 8081。如果端口被占用,会顺延到 8082 ...;8083... 8084... 直到申请到端口为止。
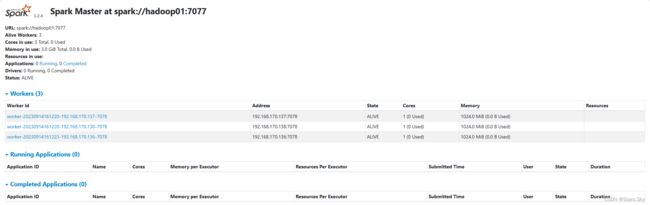
2.2.6 连接到 StandAlone 集群
2.2.6.1 bin/pyspark
[root@hadoop01 ~]# cd /bigdata/spark-3.2.4/
(pyspark) [root@hadoop01 /bigdata/spark-3.2.4]# bin/pyspark --master spark://hadoop01:7077
# 通过 --master 选项来连接到 StandAlone 集群
# 如果不写 --master 选项, 默认是 local 模式运行
2.2.6.2 bin/spark-shell
(base) [root@hadoop01 /bigdata/spark-3.2.4]# bin/spark-shell --master spark://hadoop01:7077
# 同样适用 --master 来连接到集群使用
// 测试代码
sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()2.2.6.3 bin/spark-submit (PI)
(base) [root@hadoop01 /bigdata/spark-3.2.4]# bin/spark-submit --master spark://hadoop01:7077 /bigdata/spark-3.2.4/examples/src/main/python/pi.py 10
# 同样使用 --master 来指定将任务提交到集群运行2.2.7 查看历史服务器 WEB UI
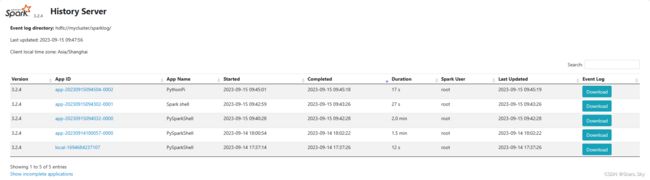
历史服务器的默认端口是: 18080,我们启动在node1上, 可以在浏览器打开:hadoop01:18080 来进入到历史服务器的 WEB UI上。
由于每个程序运行完成后,4040 端口就被注销了。在以后想回看某个程序的运行状态就可以通过历史服务器查看,历史服务器长期稳定运行,可供随时查看被记录的程序的运行过程。
三、Spark 环境搭建-Standalone HA
3.1 背景
Spark Standalone 集群是 Master-Slaves 架构的集群模式,和大部分的 Master-Slaves 结构集群一样,存在着 Master 单点故障(SPOF)的问题。

3.2 高可用 HA
如何解决这个单点故障的问题,Spark 提供了两种方案:
- 基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
- 基于 zookeeper 的 Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。
ZooKeeper 提供了一个 Leader Election 机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是 Active 的,其他的都是 Standby。当 Active 的 Master 出现故障时,另外的一个 Standby Master 会被选举出来。由于集群的信息,包括 Worker,Driver 和 Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新 Job 的提交,对于正在进行的 Job 没有任何的影响。加入 ZooKeeper 的集群整体架构如下图所示。
 3.3 基于 Zookeeper 实现 HA
3.3 基于 Zookeeper 实现 HA
前提: 确保 Zookeeper 和 HDFS 集群均已经启动!
3.3.1 spark-env.sh
先在 spark-env.sh 中删除: SPARK_MASTER_HOST=hadoop01
原因: 配置文件中固定 master 是谁,那么就无法用到 zk 的动态切换 master 功能了。
在 spark-env.sh 中增加:
(base) [root@hadoop01 /bigdata/spark-3.2.4]# vim conf/spark-env.sh
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
# spark.deploy.recoveryMode 指定 HA 模式 基于 Zookeeper 实现
# 指定 Zookeeper 的连接地址
# 指定在 Zookeeper 中注册临时节点的路径
# 分发文件
(base) [root@hadoop01 /bigdata/spark-3.2.4]# cd conf/
(base) [root@hadoop01 /bigdata/spark-3.2.4/conf]# scp -r spark-env.sh hadoop02:$PWD
(base) [root@hadoop01 /bigdata/spark-3.2.4/conf]# scp -r spark-env.sh hadoop03:$PWD3.3.2 启动 HA 集群
# 停止当前 StandAlone 集群
(base) [root@hadoop01 /bigdata/spark-3.2.4]# sbin/stop-all.sh
# 在 hadoop01 上启动一个 master 和全部 worker
(base) [root@hadoop01 /bigdata/spark-3.2.4]# sbin/start-all.sh
# 注意, 下面命令在 hadoop02 上执行,在 hadoop02 上启动一个备用的 master 进程
(base) [root@hadoop02 /bigdata/spark-3.2.4]# sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /bigdata/spark-3.2.4/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop02.out
(base) [root@hadoop02 /bigdata/spark-3.2.4]# jps
1570 QuorumPeerMain
1700 NameNode
3636 Jps
3498 Worker
3578 Master
1804 DataNode
1932 JournalNode
2204 ResourceManager
2094 DFSZKFailoverController
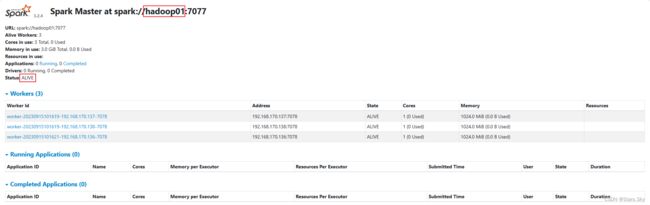
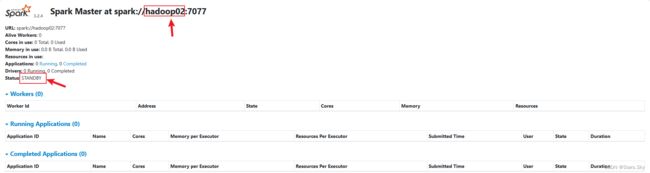
2318 NodeManager默认情况下,先启动 Master 就为 Active Master,如下截图所示:
3.3.3 master 主备切换
如果将 hadoop01 的 Master 进程 Kill 掉前,在 hadoop02 上执行pyspark 程序,也就是在执行过程中,使用 jps 查看 Active Master 进程ID,将其 kill,观察 hadoop02 的 Master 是否自动切换与应用运行完成结束,standby 是否接管集群.。(需要等待1-2min)
(base) [root@hadoop02 /bigdata/spark-3.2.4]# bin/spark-submit --master spark://hadoop01:7077 /bigdata/spark-3.2.4/examples/src/main/python/pi.py 100
(base) [root@hadoop01 /bigdata/spark-3.2.4]# jps
2352 DataNode
3537 NodeManager
2914 DFSZKFailoverController
5618 Worker
2645 JournalNode
5718 Jps
2167 NameNode
3341 ResourceManager
3773 HistoryServer
5517 Master
1854 QuorumPeerMain
(base) [root@hadoop01 /bigdata/spark-3.2.4]# kill -9 5517结论:HA 模式下主备切换不会影响到正在运行的程序。最大的影响是会让它中断大约 30 秒左右。
上一篇文章:Spark 框架概述_Stars.Sky的博客-CSDN博客
下一篇文章:Spark on YARN 部署搭建详细图文教程_Stars.Sky的博客-CSDN博客