【JMeter系列-2】JMeter元件详解之逻辑控制器
文章内容是参照Jmeter官网和自己实践完成的,JMeter官网地址贴上,有兴趣的朋友可以去阅读一下:JMeter官网
JMeter逻辑控制器
1 测试计划和线程组
2 逻辑控制器
2.1 Simple Controller(简单控制器)
2.2 Loop Controller(循环控制器)
2.3 Once Only Controller(仅一次控制器)
2.4 Interleave Example(交替控制器)
2.5 Random Controller(随机控制器)
2.6 Random Order Controller(随机顺序控制器)
2.7 Throughput Controller(吞吐量控制器)
2.8 Runtime Controller(运行周期控制器)
2.9 If Controller(if 控制器)
2.10 While Controller(判断循环控制器)
2.11 Switch Controller(开关控制器)
2.12 ForEach Controller(遍历循环控制器)
2.13 Module Controller(模块控制器)
2.14 Include Controller(包含控制器)
2.15 Transaction controller(事务控制器)
2.17 Critical Section Controller(临界区控制器)
2.18 bzm - Weighted Switch Controller(权重开关控制器)
1 测试计划和线程组
在介绍逻辑控制器之前,先说明一下测试计划和线程组这两个部件。
测试计划是使用 JMeter 进行测试的起点,它是其它 JMeter 测试元件的容器。一个Jmeter脚本中只能有一个测试计划。
线程组元件是一个测试计划的起点,测试计划的所有元件都要包含在线程组中。一个测试计划中可以有多个线程组。
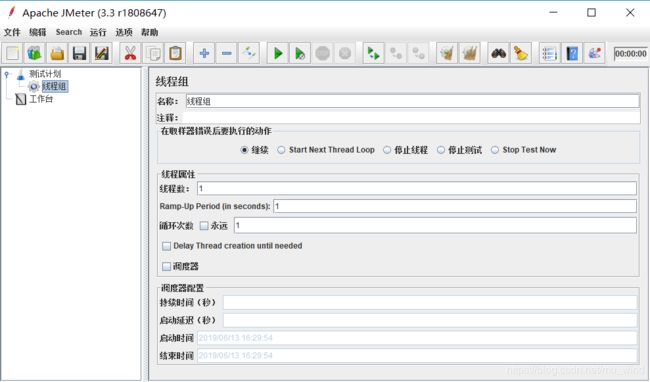
线程组:
1.名称和注释:自行填写,最好具有一定意义。
线程属性:
线程数:即用户数,需要多少用户并发,就在这里设置多少个线程数。
Ramp-Up Period(in seconds):设置的虚拟用户数需要多长时间全部启动。如果设置线程数为100,准备时长为10,那么就会在10秒钟内启动100个线程。
循环次数:每个线程发送请求的次数。如果线程数为10,循环次数为100,那么每个线程发送100次请求,总请求数为10*100=1000 。如果勾选了“永远”,那么所有线程会一直发送请求,一直到主动停止运行脚本。
Delay Thread creation until needed:延迟线程组创建,直到线程需要执行时。
调度器:有时候我们并不希望我们的脚本立即开始运行,而是在特定时段运行,这就需要用到调度器。调度器有持续时间&启动延迟和启动时间&结束时间两种组合。调度器要先勾选后才会生效,而且需要将循环次数设置为永远,否则当运行次数达到循环次数后,脚本会立即停止,持续时间和结束时间不再生效。
持续时间和延迟启动:持续时间和启动延迟内填入整数,表示脚本在被启动后,等待【启动延迟】内设置的秒数后,线程组内的元件才会被执行,执行时长为【持续时间】设置的秒数。如果【持续时间】和【延迟启动】做了设置的话,会优先于启动时间和结束时间生效。
启动时间和结束时间:当点击开始测试时,将等到【启动时间】填写的时间开始运行线程组下的元件,然后会在【结束时间】填写的时间点结束。
2 逻辑控制器
Jmeter提供了多种逻辑控制器,下面将会对它们的作用和用法做详解。对于下文中多次使用的【BeanShell Sampler】,后续会详解其用法,这里先把它简单地看做能返回特定的值的一个请求即可。2.1 Simple Controller(简单控制器)
2.1 Simple Controller(简单控制器)
简单控制器是最基本的控制器,对jmeter测试运行没有任何影响,可以将某些请求归集在一个简单控制器中,视为一个模块,使得脚本结构更清晰。
2.2 Loop Controller(循环控制器)
循环控制器,这个控制器的作用是使其子项循环运行。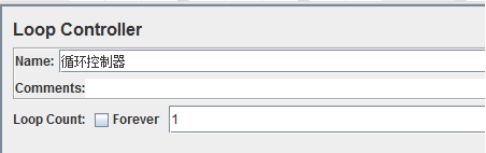
循环次数(Loop Count):在输入框中输入需要循环的次数,控制器下的子项会循环相应的次数。如果勾选了【forever】,那么控制器下的子项会一直运行。
2.3 Once Only Controller(仅一次控制器)
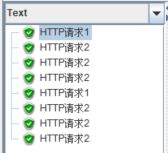
仅一次控制器,会使该控制器下的子项每个线程只运行一次,建立下面的脚本结构并运行: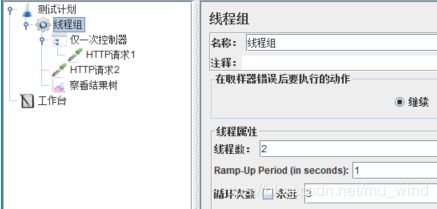
结果如下:
对上面的脚本进行修改,加入循环控制器,修改线程组【线程数】为2,【循环次数】为2: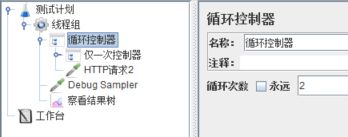
运行脚本,结果如下: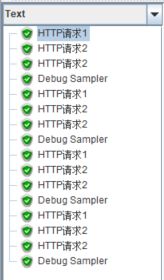
可见,【循环控制器】中的【仅一次控制器】依然生效。
2.4 Interleave Example(交替控制器)
交替控制器,使得该控制器包含的取样器步骤在每次循环中交替执行。例如下面的脚本结构,将线程组循环次数设为6并运行。
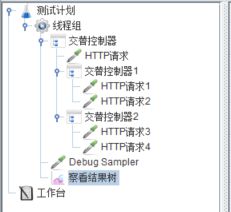
————————————————
结果如下:
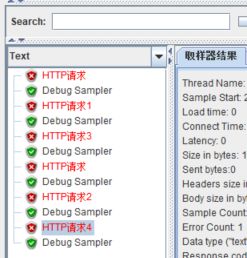
第1次运行,执行了HTTP请求,结束。
第2次运行,进入交替控制器1,并执行HTTP请求1,结束。
第3次运行,进入交替控制器2,并执行HTTP请求3,结束。
第4次运行,执行了HTTP请求,结束。
第5次运行,进入交替控制器1,并执行HTTP请求2,结束。
第6次运行,进入交替控制器2,并执行HTTP请求4,结束。
再看交替控制器下的两个参数项。
Ignore sub-contorller blocks:如果勾选此项,交替控制器将sub-controllers像单一请求元素一样,一次只允许一个请求/控制器。
Interleave across threads:勾选此项后,多线程运行脚本时,交替控制器依然生效,例如线程1执行了HTTP请求,那么线程2将直接执行简单控制器1。
首先验证【Ignore sub-contorller blocks】的作用,建立如下脚本并运行(不勾选【Ignore sub-contorller blocks】):
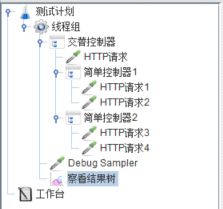
结果如下:
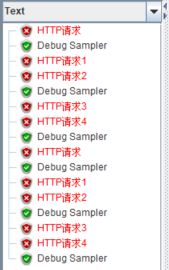
勾选【Ignore sub-contorller blocks】后再次运行:
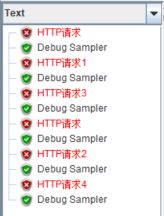
区别很明显,勾选了【Ignore sub-contorller blocks】后,交替控制器子控制器中的取样器一次运行只会被执行一个。
2.5 Random Controller(随机控制器)
随机控制器,当该控制器下有多个子项时,每次循环会随机执行其中一个。建立下图的脚本结构,线程组【循环次数】设置为4。
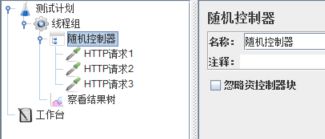
运行脚本,结果如下:
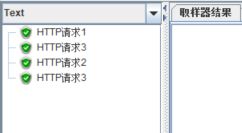
————————————————
随机控制器有一个参数项:Ignore sub-controller block(忽略子控制器模块)。如果勾选了此项,随机控制器下的子控制器中的多个子项只会被执行一个。
下面用实例验证一下。修改脚本结构:
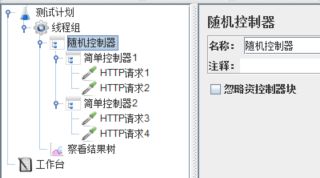
线程组【循环次数】为2,运行脚本,结果:
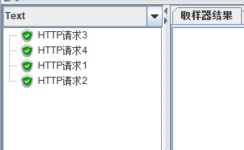
勾选【Ignore sub-controller block】后再次运行脚本,结果变为:
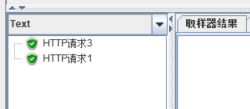
2.6 Random Order Controller(随机顺序控制器)
随机顺序控制器,与简单控制器类似,会执行它下面的每个子项,只不过执行顺序是随机的。
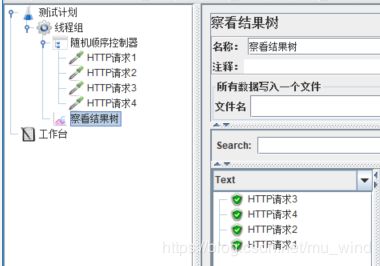
2.7 Throughput Controller(吞吐量控制器)
吞吐量控制器,允许用户自行调整该控制器下的子项的执行频率。
吞吐量控制器有两种模式:
1、Total Executions:当该控制下的子项被执行固定数量后,停止吞吐量控制器。例如下面这个脚本,线程组【循环次数】设为6,运行脚本。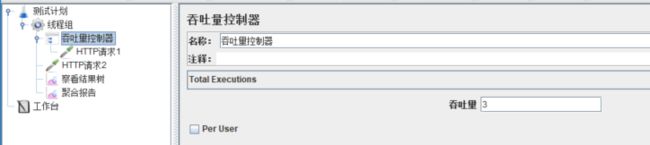
结果如下:
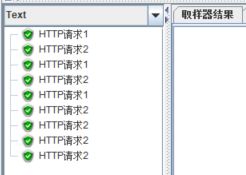
2、Percent Executions:百分比模式,该模式使吞吐量控制器下的子项执行总循环次数的一定比例(在吞吐量中设置该比例),例如下面的脚本。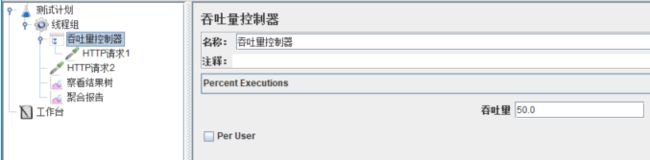
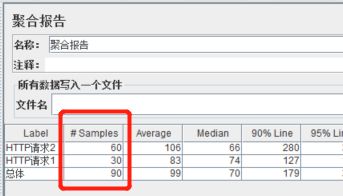
设置线程组【循环次数】为60,运行后,查看聚合报告,吞吐量控制器下的HTTP请求1执行了30次,也就是(60*50%)次。
2.8 Runtime Controller(运行周期控制器)
运行周期控制器,顾名思义,这是一种设置运行时间的控制器,它的效果就是使该控制器下的子项运行时间为【Runtime】中的数值(单位:s)。
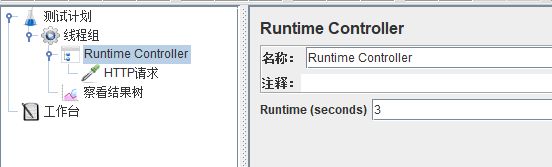
不过,经过实测,如果线程组的循环次数勾选“永远”,则HTTP请求会一直运行,如果循环次数填入1,则HTTP请求会运行3s,循环次数填入2的话,HTTP请求运行6s,因此可知,在线程组不勾选“永远”的前提下,【Runtime Controller】的运行时间为【Runtime】的值乘以线程组循环次数。
2.9 If Controller(if 控制器)
If控制器,允许用户去设置该控制器下的子项是否运行。默认情况下,条件只在初始判断一次,但我们可以选择让它对控制器中包含的每个可运行项进行判断。
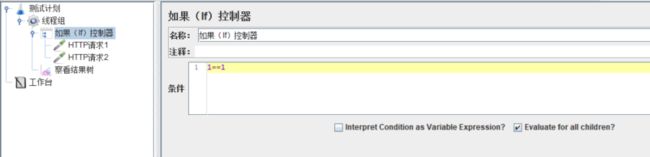
我们先看下【条件】这个输入项。它支持哪些方式:
条件表达式,例如1!=1、2>1,或者${var}>0,"${var}"==“abcd”(对于String,"=="前面的双引号不能省略)这样的写法,但这种写法在内部使用javascript来判断【条件】的计算结果是true还是false,可能会造成性能损失。在勾选了【Interpret Condition as Variable Expression】后,这些表达式的结果会被一律判定为false。
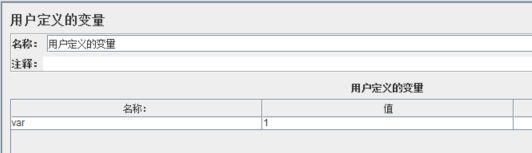
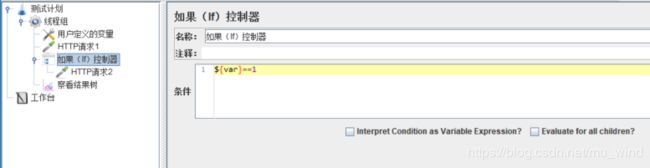
运行脚本,查看结果树,HTTP请求1和HTTP请求2都被执行。
更好的选择是,使用变量表达式,当然前提是勾选【Interpret Condition as Variable Expression】(不勾选也能使用,但影响性能)。
使用一个包含 true 或 false 的变量,例如下面的表达式中,判定条件为if控制器下的最后一个sample是否成功。
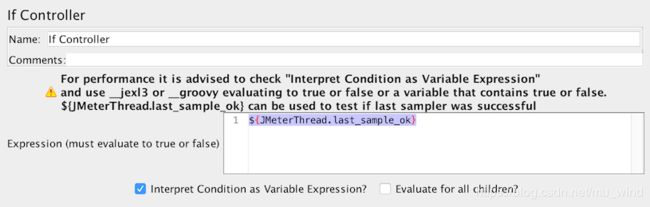
2.使用函数,这个函数表达式必须返回一个true或false的判断结果,例如下例:
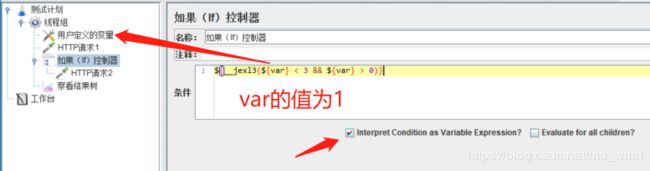
这种使用方式,因为勾选了【Interpret Condition as Variable Expression】,直接计算表达式结果,并判断是否为true,无需再使用JavaScript,理论上性能得以提升。
其他变量表达式的示例:
1、${__groovy(vars.get(“myVar”) != “Invalid” )}:判断myVar不是无效的;
2、${__groovy(vars.get(“myInt”).toInteger() <=4 )} :判断myInt这个变量小于等于4;
3、${__groovy(vars.get(“myMissing”) != null )} :判断myMissing这个变量不是null
4、${__jexl3(${COUNT} < 10)}:变量表达式判断COUNT这个变量小于10;
5、${RESULT}:RESULT这个变量本身的值应该是true或者false;
6、${JMeterThread.last_sample_ok}:判断最后一个sample成功;
2.10 While Controller(判断循环控制器)
判断循环控制器,作用是循环运行其子项,直到条件为false。这个控制器和Java中的while语法是很相似的。
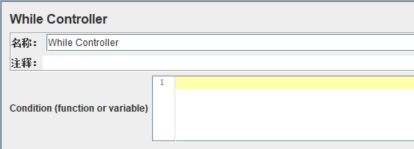
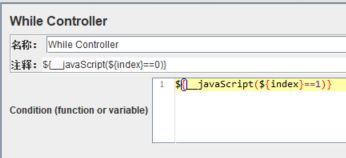
【Condition】可以填入的值有:
其它:条价值等同于false时,退出循环。有以下例子:
1、${VAR} :变量VAR在其它项中被赋值为“false”;
2、${__javaScript(${C}==10)}:针对数字型变量进行对比判断,这种表达式的计算结果为“false”时不进入或者退出循环;
3、${__javaScript("${C}"==“abc”)}:针对字符串类型变量进行对比判断,这种表达式的计算结果为“false”时不进入或者退出循环(区别在于双引号);
4、${__javaScript("${VAR2}"==“abcd”)}:VAR2在其它项中被赋值与“abcd”做比较,不相等则退出循环;
5、${_P(property)} :属性被其它项目赋予“false”
下面做一个演示:
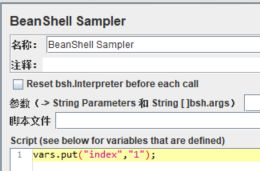
运行脚本,发现循环会一直进行下去。
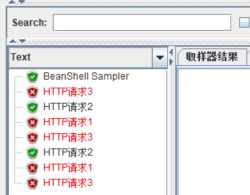
如果将【BeanShell Sampler】中的语句改为“vars.put(“index”,“0”);”,运行发现脚本不进入while循环。
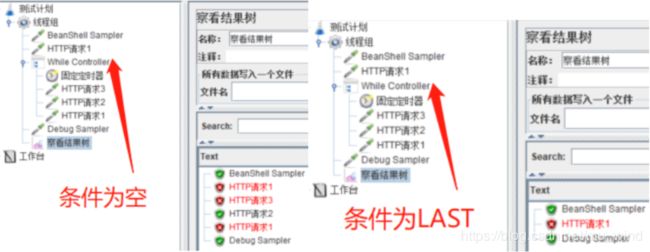
- 空白:节点下最后一个sampler失败,退出循环;
- LAST:节点下最后一个sampler失败,退出循环。如果这个失败的sampler在循环前就运行失败了,那么【While Controller】将不会执行。
2.11 Switch Controller(开关控制器)
开关控制器,通过【Switch Value】来控制哪个子项被执行,作用和Java中的switch语法是很类似的。
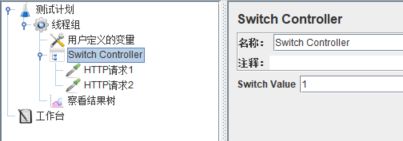
【Switch Value】有两种赋值方式:索引和子项名,经过实际测试,如果填入数字,且子项中有以数字命名的子项(当然,实际工作中要尽量避免这种命名方式),索引优先生效。
下面通过一些实例进行说明:
在上面的脚本结构中,【Switch Value】中填入的是1(Java中,索引是从0开始,1代表第二个),执行脚本,查看结果,HTTP请求2被执行。
【Switch Value】中填入“HTTP请求2”,执行脚本,查看结果,HTTP请求2被执行。
将【HTTP请求1】修改名称为【1】,【Switch Value】中填入【1】,执行脚本,查看结果,HTTP请求2被执行,说明索引优先级高于名称。
将【HTTP请求1】修改名称为【7】,【Switch Value】中填入【7】,执行脚本,查看结果,“7”被执行。
Switch Controller一般配合其他组件,才会更有意义,比如说和【Bean Shell】配合:
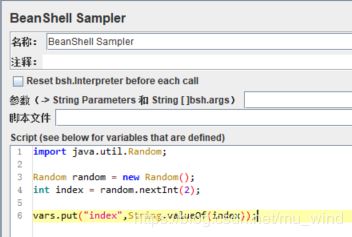
上图中的【Bean Shell】的作用是返回一个名称为“index”,值为[0,1]区间的随机int。
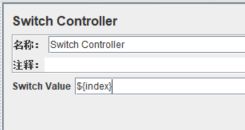
【Switch Value】填入“${index}”,运行脚本:
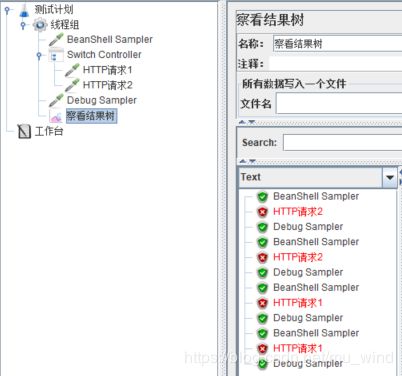
2.12 ForEach Controller(遍历循环控制器)
遍历循环控制器,首先看下它的各输入项:
输入变量前缀:输入遍历需要的变量的前缀,图中是test,为什么要写“test”呢?这是因为【用户定义的变量】中变量名称是“test”为前缀的,前缀是指数字前面的内容。当然这个变量还可以来自【正则表达式提取器】、【参数化】等。
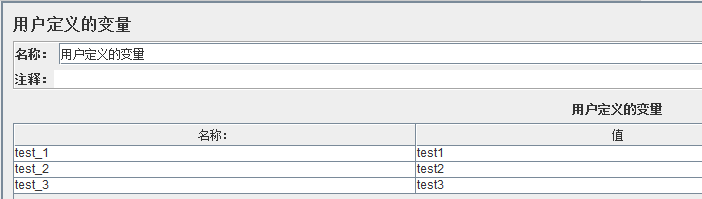
输入变量前缀:输入遍历需要的变量的前缀,图中是test,为什么要写“test”呢?这是因为【用户定义的变量】中变量名称是“test”为前缀的,前缀是指数字前面的内容。当然这个变量还可以来自【正则表达式提取器】、【参数化】等。
Start index for loop:循环开始的变量索引(行数),不填则从0开始,也就是自定义变量中的第一行。
End index for loop:循环结束的变量索引,不包括本身,也就是如果填入3,则执行完2就会结束。
输出变量名称:将读取到的变量放入内存,变量值就是输出变量名称所定义的值(本例是test)。在后面使用这个值时,使用“${输出变量名}“格式就可以了。
Add “_” before number:勾选后,【用户定义的变量】的变量名要写“test_1”格式,不勾选则写成“test1”格式。
HTTP请求按下图写入,来验证ForEach Controller的作用。
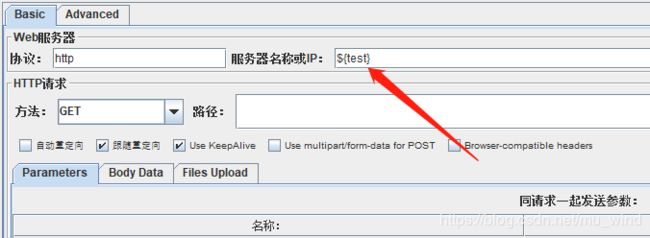
运行脚本,发现HTTP请求被执行了三次(end-start的值),${test}依次被赋值test1、test2、test3。
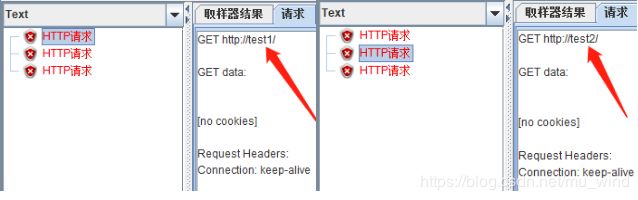
再看下面这个例子,添加BeanShell Sampler,并给它添加一个正则表达式提取器,效果就是提取到一个名为“test_1”,值为“bcde”的变量到内存中。HTTP请求的内容不变(BeanShell和正则表达式见,这里的BeanShell其实就是提供了一个模拟接口,返回值是return的内容,即“abcdef”,而正则表达式提取器的作用是按规则提取返回内容的一部分)。
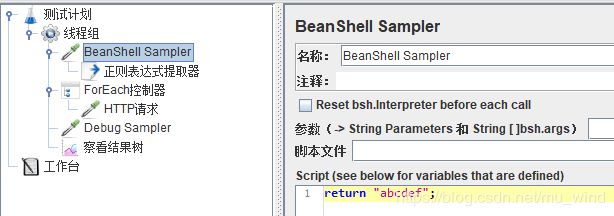
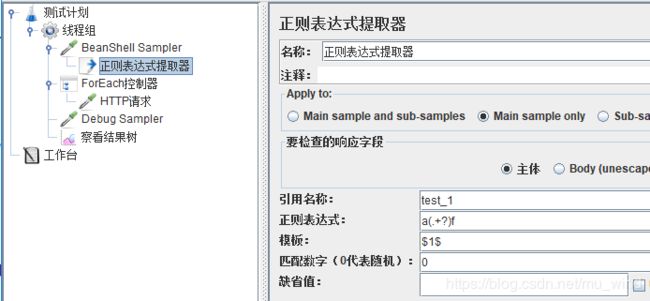
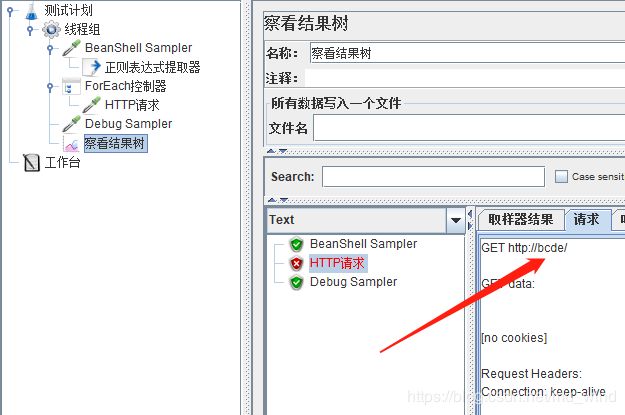
运行脚本,可以看到“bcde”的值被引用过来了。
2.13 Module Controller(模块控制器)
模块控制器,可以理解为对封装好的模块的调用。
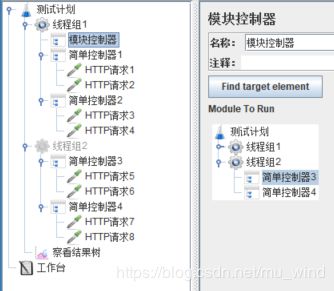
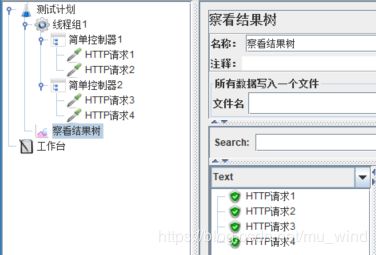
观察上图的脚本结构并运行,查看结果树,可以看到,线程组1中的模块控制器可以调用线程组2中的简单控制器3及其下面的sampler。
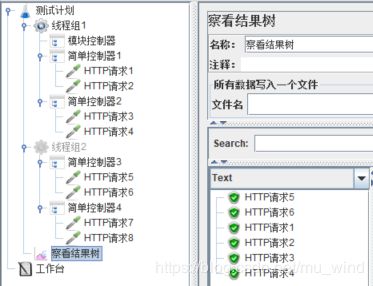
由此可知,模块控制器的作用在于,当一个测试片段(通常是一个包含sampler的控制器)在脚本中多处运行时,模块控制器可以非常便利地完成调用,避免重写这个测试片段,使脚本减少冗余,结构简洁。
另外,当测试计划中有多个线程组时,一个线程组需要运行其它线程组的一个测试片段,模块控制器的作用就更加明显了。在这种场景下,即使其它线程组被禁用,依然不影响模块控制器对其节点下测试片段的调用。而在实际测试工作中,通常是一个线程组启用,而其它线程组被禁用,防止线程组互相干扰。
使用模块控制器时,需要注意的是,要保证控制器的名字各不相同,因为模块控制器是通过控制器名去调用的。
2.14 Include Controller(包含控制器)
包含控制器,它的作用是引入外部的jmx文件。需要注意的有以下几点:
引用的jmx文件中,不能包含线程组。
当使用包含控制器中包含相同的JMX文件,要避免同名。
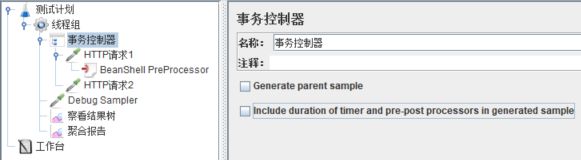
2.15 Transaction controller(事务控制器)
事务控制器,生成一个额外的采样器来测量其下测试元素的总体时间;值得注意的是,这个时间包含该控制器范围内的所有处理时间,而不仅仅是采样器的。由于时钟误差,而事务控制器的总体用时可能会稍微大于事务控制器下各个子项用时之和。
它有两个参数项:
Generate parent sample:生成父样本(不同的模式选择)
include duration of timer and pre-post processors in generated sample:是否包含时间的计时器和前后处理器耗用的时间。
建立以下结构的脚本:
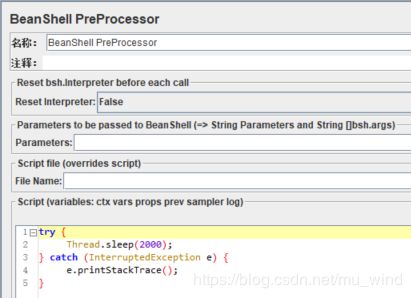
【BeanShell PreProcessor】中写入以下语句,它的作用是使HTTP请求1执行前等待2000ms(BeanShell PreProcessor会在后面Beanshell专题中详细讲解)。
运行脚本,查看结果树和聚合报告:
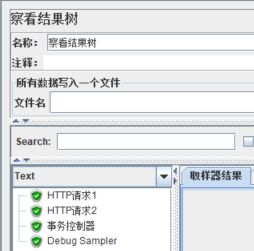
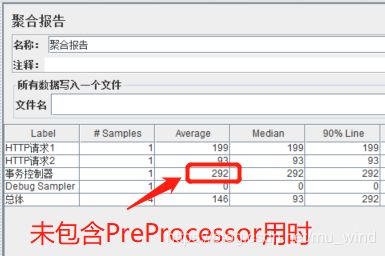
可以看到聚合报告中记录了【事务处理器】的响应用时信息。我们勾选了【Generate parent sample】后再次运行,我们发现结果树和聚合报告都有了变化,结果树中依然能看到HTTP请求,但已经归集到事务控制器下,而聚合报告中不再显示取样器。
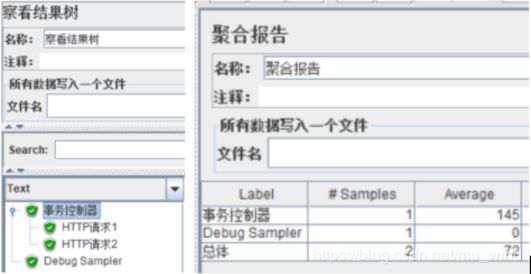
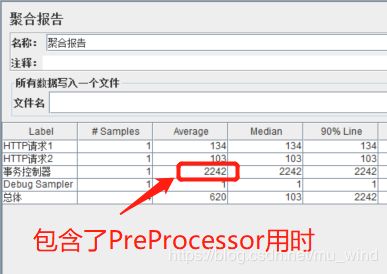
我们再勾选【include duration of timer and pre-post processors in generated sample】后运行脚本,区别就是聚合报告中事务控制器响应时间包含了PreProcessor的时间(2000ms)。
————————————————
版权声明:本文为CSDN博主「云深i不知处」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mu_wind/article/details/91879280
2.17 Critical Section Controller(临界区控制器)
临界区控制器,这个名字听起来很难理解,其实这个控制器的作用是为它的子项加一个同步锁,使得在多线程场景下,同一时刻,只有一个线程能够调用其子项。我们用实际操作来验证一下它的作用。建立如下图的脚本结构:然后设置线程组线程数为5,循环次数为2,设置固定定时器线程延迟为1000ms(固定定时器介绍见后文,这里定时器的作用是使每次HTTP请求先等待1s),而HTTP2请求是空的,目的是让HTTP请求和固定定时器的单次整体用时为1s。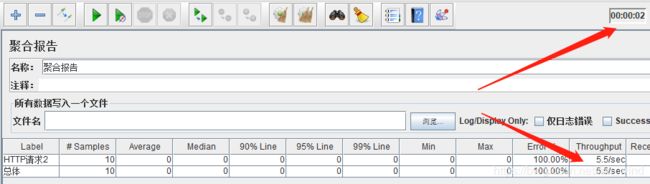 我们改变脚本结构,可以看到HTTP请求2同一时刻会被多个线程调用,tps也得以提升。
我们改变脚本结构,可以看到HTTP请求2同一时刻会被多个线程调用,tps也得以提升。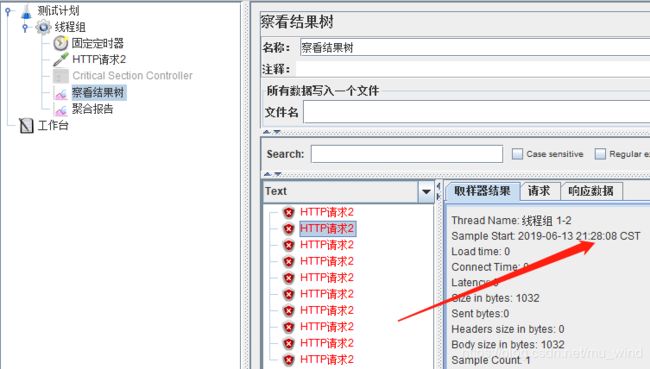
2.18 bzm - Weighted Switch Controller(权重开关控制器)
权重开关控制器(直译),它能分配其子项目(Child Item)的权重,从而控制子项的执行概率。首先建立如下的脚本结构:
在bzm - Weighted Switch Controller下有两个HTTP请求,将它们的Weight设置为7和3,线程组循环次数设为100,当脚本运行结束后,观察聚合报告,可以看到,HTTP请求1和HTTP请求2分别执行了70次和30次。经过多次测试,这个权重是精确控制,而非概率性控制。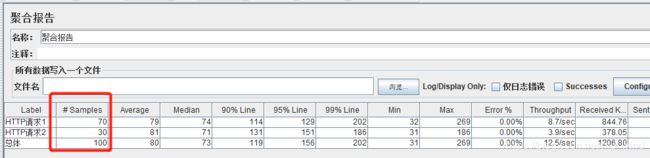
-
Weighted Switch Controller配合其他控制器,会有更丰富的用法,比如以简单控制器、循环控制器作为子项,甚至以自身作为子项,这里不再赘述,感兴趣的朋友可以动手做下测试。
————————————————
版权声明:本文为CSDN博主「云深i不知处」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mu_wind/article/details/91879280