R语言用逻辑回归预测BRFSS中风数据、方差分析anova、ROC曲线AUC、可视化探索
全文链接:https://tecdat.cn/?p=33659
行为风险因素监测系统(BRFSS)是一项年度电话调查。BRFSS旨在确定成年人口中的风险因素并报告新兴趋势(点击文末“阅读原文”获取完整代码数据)。
相关视频
例如,调查对象被询问他们的饮食和每周体育活动、HIV/AIDS状况、可能的吸烟情况、免疫接种、健康状况、健康日数-与健康相关的生活质量、医疗保健获取、睡眠不足、高血压认知、胆固醇认知、慢性健康问题、酒精消费、水果和蔬菜消费、关节炎负担以及安全带使用情况等。
加载数据
load("brfs.RData")第一部分:关于数据
数据收集:
对于固定电话样本采用了不成比例分层抽样(DSS),移动电话受访者则是随机选择的,每个受访者被选中的概率相等。我们正在处理的数据集共有330个变量,总共有491,775个观测值(2013年)。缺失值用“NA”表示。
泛化能力:
样本数据应该能够推广到感兴趣的总体。这是对18岁及以上的491,775名成年人进行的调查。它基于一个大规模分层随机样本。可能存在的偏差与非响应、不完整的访谈、缺失值和便利性偏差相关(一些潜在的受访者可能因为没有固定电话和手机而未被纳入在内)。
因果关系:
由于BRFSS是一项观察研究,只能建立变量之间的相关性/关联,并不能确定因果关系。
第二部分:研究问题
研究问题1:
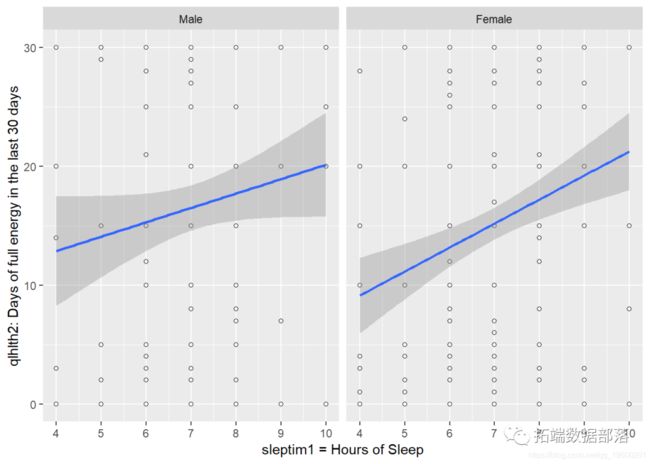
在过去30天内,男女性别在身体和心理健康不好的天数分布上是否存在差异?
研究问题2:
受访者接受采访的月份与其自我报告的健康感知之间是否存在关联?
研究问题3:
收入和医疗保险之间是否存在关联?
研究问题4:
吸烟、饮酒、胆固醇水平、血压、体重与中风的关系是什么?最终,我想看到是否可以通过上述变量对中风进行预测。
第三部分:探索性数据分析
研究问题1:
ggplt(aes(x=phhth, fill=sx), data = bfss3[!is.na(brfs13$sex), ])
ggplot+
geom_hitoam(bns=3, psition= psiion_dg
gplot(aes(x=prth, filsex), data=br203[!is.nbrfs03$ex), ]) +
gem_istrm(ns=30, postn = poiioge())
sumary(brss3$ex)
以上三个图显示了男性和女性对过去30天内身体、心理和两者都不好的天数的数据分布。我们可以看到女性受访者远多于男性受访者。
研究问题2:
R
by_mnt <- bs201 %>% fier(iyr=='2013') %>% gop_by(imnth, ghlh) %>% sumaie(n=n())
ggpt(aes(x=ionh, y=n, fill = gehh), data = b_mh[!is.na(by_mt$gehlh), ]) + go_bar(stat = 'idnty', ostin = posion_doe())
点击标题查阅往期内容

R语言数据可视化分析案例:探索BRFSS数据

左右滑动查看更多
01

02
03

04

R
by_mnh1 <- brs13 %>% ftr(iyar=='2013') %>% grup_y(imnh) %>% surse(n=n())
gglot(aes(x=imnh, y=n), daa=bymth1) + gem_ar(stat = 'dentty')
我试图找出人们在不同月份对健康状况的回答是否有所差异。例如,在春季或夏季,人们是否更有可能说自己身体健康?然而,看起来并没有明显的模式可见。
研究问题3:
R
plot(brs203$iome2, brfs13$ltpn1
总体来说,高收入的受访者比低收入的受访者更有可能享有医疗保险。
研究问题4:
为了回答这个问题,我将使用以下变量:
bphigh4: 是否曾经被告知有高血压
toldhi2: 是否曾经被告知有高血胆固醇
weight2: 报告的体重(以磅为单位)
cvdstrk3: 是否曾被诊断为中风
smoke100:至少吸过100支香烟
avedrnk2:过去30天内每天平均
首先,将上述变量转换为数值,并查看这些数值变量之间的相关性。
R
slectedfss - brfs2013[vars]
selced_rf$tolhi2 <- iflse(seeted_fss$todh2=="Yes", 1, 0)
corrmarix <- cor(selced_bfss)
corplot(corr.atri
没有任何两个数值变量之间似乎存在强相关性。
用逻辑回归预测中风
将答案"Yes, but female told only during pregnancy"和"Told borderline or pre-hypertensive"替换为"Yes"。
R
vr1 <- names(brs013) %in% c('smoke0', 'aedrk2', 'bphg4', 'tldhi2', 'wht', 'cdsrk3')
sroe <- brfs203[vars1]将'NA'值替换为'No'。
R
4 <- repce(strebh, whch(is.na(stroke$bpig4)), "No")whih(is.na(stroke$soke10)), 'No')将'NA'值替换为平均值。
R
mean(strke$avedrnk2,.rm = T)![]()
R
stoke$vdrk2 <- replce(stoe$aednk2, whch(is.nastroe$avednk2)), 2)查看将用于建模的数据。
R
hed(sroe)
sumary(sroe)
将结果转换为二元结果。
R
strke$vdrk3 <- ifelestrok$cvdsk3=="Ys", 1, 0)在整理和清理数据之后,现在可以拟合模型。
拟合逻辑回归模型
R
test <- stre[390001:491775,]
odel <- glm(cvdtrk3 ~.,famly=biomil(link = 'logit'),at=trin)
summary(mdel)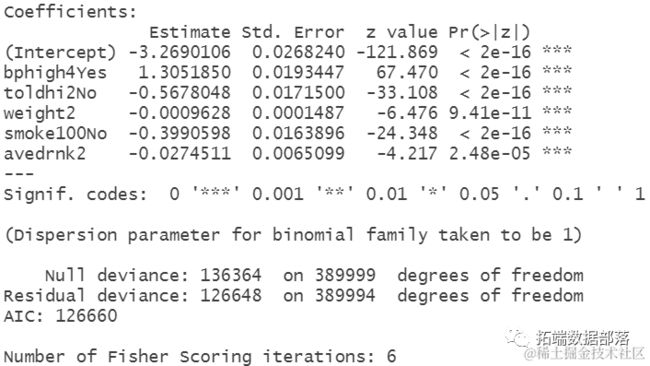
解释逻辑回归模型的结果:所有变量在统计上都是显著的。
在其他变量相等的情况下,被告知血压高的可能性更容易出现中风。
预测变量toldhi2No的负系数表明,在其他变量相等的情况下,没有被告知血胆固醇高的可能性更不容易中风。
每增加一单位的体重,中风(而不是无中风)的对数几率下降0.00096。
不吸烟至少100支香烟的可能性更小。
过去30天平均每天饮用的酒精饮料每增加一单位,中风的对数几率下降0.027。
R
anva(modl, tet="Chiq")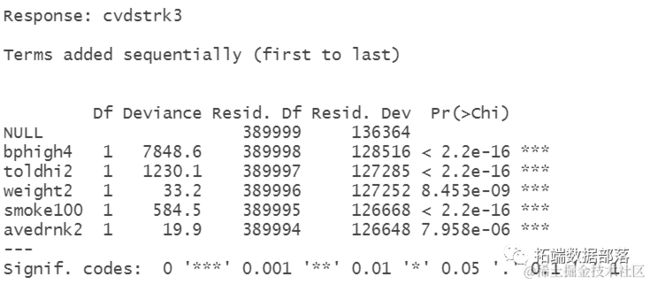
通过分析偏差表,我们可以看到在逐个添加每个变量时的偏差下降情况。添加bphigh4、toldhi2和smoke100明显降低了残差偏差。其他变量weight2和avedrnk2似乎改善了模型,尽管它们都具有较低的p值。
评估模型的预测能力
R
fite.result <- ifelse(fited.ults > 0.5,1,0)
misCasifEror <- mean(ftted.reuts != testvdtk3)
prnt(pase('Accuracy',1misClasiicEror))![]()
测试集上的准确率为0.96非常好。
绘制ROC曲线并计算AUC(曲线下面积)
R
p <- predicodel, newdat=est, te="response")
pr <- prdition(p, tet$cdstrk3)
auc <- [email protected][[1]]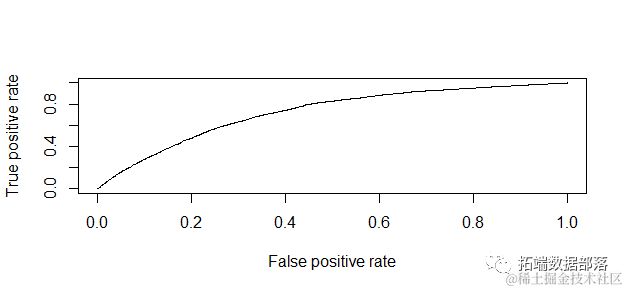
![]()
最后说明一下,当我们分析健康调查数据时,我们必须意识到自我报告的患病率可能存在偏差,因为受访者可能不了解自己的风险状况。因此,为了获得更精确的估计值,研究人员正在使用实验室测试以及自我报告的数据。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言用逻辑回归预测BRFSS中风数据、方差分析anova、ROC曲线AUC、可视化探索》。
![]()

点击标题查阅往期内容
数据分享|R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言逻辑回归logistic模型分析泰坦尼克titanic数据集预测生还情况
R语言是否对二分连续变量执行逻辑回归
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
R语言用局部加权回归(Lowess)对logistic逻辑回归诊断和残差分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言用线性模型进行臭氧预测:加权泊松回归,普通最小二乘,加权负二项式模型,多重插补缺失值
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言中回归和分类模型选择的性能指标
R语言多元时间序列滚动预测:ARIMA、回归、ARIMAX模型分析
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言计量经济学:虚拟变量(哑变量)在线性回归模型中的应用
R语言 线性混合效应模型实战案例
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言如何用潜类别混合效应模型(LCMM)分析抑郁症状
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言建立和可视化混合效应模型mixed effect model
R语言LME4混合效应模型研究教师的受欢迎程度
R语言 线性混合效应模型实战案例
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
基于R语言的lmer混合线性回归模型
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言分层线性模型案例
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据
用SPSS估计HLM多层(层次)线性模型模型
R语言空气污染数据的地理空间可视化和分析:颗粒物2.5(PM2.5)和空气质量指数(AQI)
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言计算资本资产定价模型(CAPM)中的Beta值和可视化
R语言主成分分析(PCA)葡萄酒可视化:主成分得分散点图和载荷图
R语言时变向量自回归(TV-VAR)模型分析时间序列和可视化
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言对布丰投针(蒲丰投针)实验进行模拟和动态可视化生成GIF动画
R语言信用风险回归模型中交互作用的分析及可视化
R语言生存分析可视化分析
R语言线性回归和时间序列分析北京房价影响因素可视化案例
R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
R语言动态可视化:绘制历史全球平均温度的累积动态折线图动画gif视频图
R语言动态图可视化:如何、创建具有精美动画的图
R语言中生存分析模型的时间依赖性ROC曲线可视化
![]()
![]()
