pytorch的自动微分、计算图 | 代码解析
在深度学习和机器学习中,自动微分是一个关键的概念,用于计算函数相对于其输入变量的导数(梯度)从而利用各类优化算法如梯度下降降低损失函数。PyTorch中的张量(tensor)提供了自动微分功能,它使得梯度计算变得非常方便,是深度学习模型训练的关键组成部分。
而梯度下降算法是通过计算图来实现的,计算图非常重要
可以把复杂的求导过程表示成计算图
1. 计算图原理剖析
1.1计算图正向 正向传播
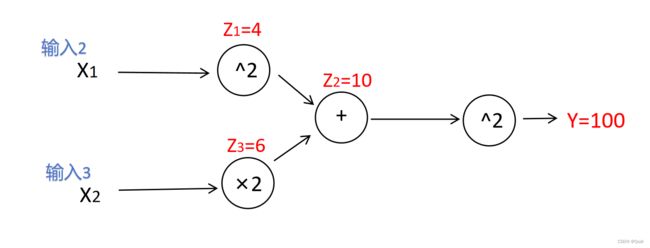
正向传播很重要,我们以 y = ( x 1 2 + 2 x 2 ) 2 y=(x_1^2+2x_2)^2 y=(x12+2x2)2 为例建立计算图
通过中间变量,复杂式子可以划分为一次加减乘除幂运算
y = z 2 2 y=z_2^2 y=z22
z 2 = z 1 + z 3 z_2=z_1+z_3 z2=z1+z3
z 1 = x 1 2 z_1=x_1^2 z1=x12
如图
输入蓝色x1,x2,圆圈代表运算 红色是中间变量z1,z2
1.2反向传播算梯度
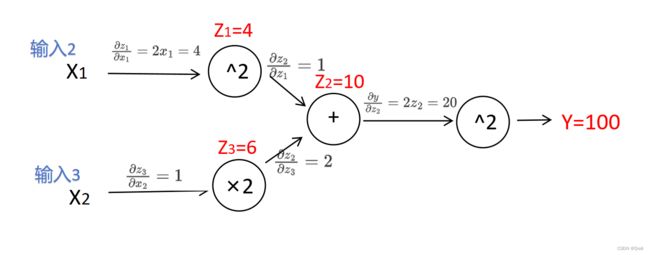
我们现在要求最终输出y对每一个参数x1,x2的梯度
根据链式法则对y求x1的偏导
由链式法则
∂ y ∂ x 1 = ∂ y ∂ z 2 ∗ ∂ z 2 ∂ z 1 ∗ ∂ z 1 ∂ x 1 \frac{\partial y}{\partial x_1}=\frac{\partial y}{\partial z_2}*\frac{\partial z_2}{\partial z_1}*\frac{\partial z_1}{\partial x_1} ∂x1∂y=∂z2∂y∗∂z1∂z2∗∂x1∂z1
拆分每一部分分别求
∂ y ∂ z 2 = 2 z 2 = 20 \frac{\partial y}{\partial z_2}=2z_2=20 ∂z2∂y=2z2=20
∂ z 2 ∂ z 1 = 1 \frac{\partial z_2}{\partial z_1}=1 ∂z1∂z2=1
∂ z 1 ∂ x 1 = 2 x 1 = 4 \frac{\partial z_1}{\partial x_1}=2x_1=4 ∂x1∂z1=2x1=4
把求得的三个累乘即可 得到结果80
∂ y ∂ x 1 = ∂ y ∂ z 2 ∗ ∂ z 2 ∂ z 1 ∗ ∂ z 1 ∂ x 1 = 80 \frac{\partial y}{\partial x_1}=\frac{\partial y}{\partial z_2}*\frac{\partial z_2}{\partial z_1}*\frac{\partial z_1}{\partial x_1}=80 ∂x1∂y=∂z2∂y∗∂z1∂z2∗∂x1∂z1=80
根据链式法则对y求x2的偏导
由链式法则
∂ y ∂ x 1 = ∂ y ∂ z 2 ∗ ∂ z 2 ∂ z 3 ∗ ∂ z 3 ∂ x 2 \frac{\partial y}{\partial x_1}=\frac{\partial y}{\partial z_2}*\frac{\partial z_2}{\partial z_3}*\frac{\partial z_3}{\partial x_2} ∂x1∂y=∂z2∂y∗∂z3∂z2∗∂x2∂z3
拆分每一部分分别求
∂ y ∂ z 2 = 2 z 2 = 20 \frac{\partial y}{\partial z_2}=2z_2=20 ∂z2∂y=2z2=20
∂ z 2 ∂ z 3 = 2 \frac{\partial z_2}{\partial z_3}=2 ∂z3∂z2=2
∂ z 3 ∂ x 2 = 1 \frac{\partial z_3}{\partial x_2}=1 ∂x2∂z3=1
把求得的三个累乘即可 得到结果40
∂ y ∂ x 1 = ∂ y ∂ z 2 ∗ ∂ z 2 ∂ z 3 ∗ ∂ z 3 ∂ x 2 = 40 \frac{\partial y}{\partial x_1}=\frac{\partial y}{\partial z_2}*\frac{\partial z_2}{\partial z_3}*\frac{\partial z_3}{\partial x_2}=40 ∂x1∂y=∂z2∂y∗∂z3∂z2∗∂x2∂z3=40
如图
1.3 其他补充
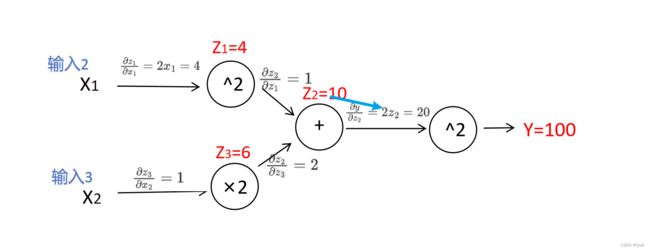
(1)通过计算图分析我们可以知道,必须先进行前向运算,每个节点的运算结果还需要保存起来,因为反向梯度回传计算可能用到,如箭头所指
(2)我们这里每一个节点代表一个很小的操作,就一个乘法或加法或幂,实际操作中我们可以把多个小节点合成一个大节点存储,这样的话就可以只存储更少的正向值,计算更少次的反向传播,我们把这样的计算图称作粗粒度计算图,相反我们上面讲到的是细粒度图
既然需要保存,就涉及内存的占用
选择粗粒度或细粒度的计算图取决于具体的应用和需求:
- 如果内存资源有限,或者计算过程非常复杂,可以考虑使用粗粒度计算图以减少内存占用和计算开销。
- 如果需要精确的梯度计算,或者希望深度学习框架能够自动进行反向传播,那么通常会选择细粒度计算图。
2.pytorch代码解析
2.1 标量
对于我们的一些深度学习框架内置的一些数据类型,如pytorch的tensor就是通过上述的方式来实现自动微分求导的
我们来看看代码实现
import torch
#申明张量
x1=torch.tensor(2.0)
x2=torch.tensor(3.0)
#设置梯度可求
x1.requires_grad_(True)
x2.requires_grad_(True)
print("反向求梯度前:",x1.grad,x2.grad)
#前向计算
y=(x1**2+2*x2)**2
#反向传播计算
y.backward()
print("反向求梯度后::",x1.grad,x2.grad)
输出
反向求梯度前: None None
反向求梯度后:: tensor(80.) tensor(40.)
总结:
(1)tensor张量必须先通过requires_grad_属性设置为True,PyTorch才会跟踪张量上的所有操作,并构建计算图计算梯度
(2)通过grad属性查看梯度,grad在默认未反向回传求梯度情况下为None
(3)前向计算后,反向计算通过backward()函数即可
注意:
(1)在PyTorch中,只有具有浮点数类型(如float32、float64等)的张量才能够进行自动微分(Autograd)。整数类型(如int32、int64)的张量默认情况下是不支持自动微分的。上述代码中如果把x1,x2改为int类型会报错RuntimeError: only Tensors of floating point dtype can require gradients
(2)由于梯度会累积,所以在求新的一轮的梯度时候,要通过grad_zero_函数清除梯度
我们还是以上面的运算为例,我们执行两次前向传播,两次反向传播计算,可以观察这种梯度累积现象
import torch
#申明张量
x1=torch.tensor(2.0)
x2=torch.tensor(3.0)
#设置梯度可求
x1.requires_grad_(True)
x2.requires_grad_(True)
print("反向求梯度前:",x1.grad,x2.grad)
#前向计算
y=(x1**2+2*x2)**2
#反向传播计算
y.backward()
#再次前向计算
y=(x1**2+2*x2)**2
#再次反向传播计算
y.backward()
print("反向求梯度后::",x1.grad,x2.grad)
输出
反向求梯度前: None None
反向求梯度后:: tensor(160.) tensor(80.)
是刚才的两倍
2.2 向量
我们上面为了更好理解,使用了标量做解释
实际使用中,参数和最终输出往往都是高纬张量,求导结果也往往是矩阵
当输入是标量,输出是标量的时候,或者输入是向量,输出是标量的时候,上面方法都没有问题。
但是当输出向量的时候,会报错RuntimeError: grad can be implicitly created only for scalar outputs 翻译过来是只能为标量输出创建梯度
因而我们需要先进行一步sum()操作,转向量为标量
import torch
# 假设模型参数是 w
w = torch.tensor([1.0,2.0,3.0], requires_grad=True)
# 定义损失函数 y(这里是一个简单的示例)
y = w*w + 2*w + 1
# 计算损失函数 y 的总和并执行自动微分
loss = y.sum().backward()
# 现在 w.grad 包含了损失函数对 w 的梯度
print(w.grad) # 输出为 tensor([4., 6., 8.])
2.3 分离计算
在 PyTorch 中,有时候需要使用 .detach() 或 .detach_() 方法来分离张量以进行反向传播,通常是为了控制梯度流或避免不必要的计算。一些常见的情况和原因:
- 避免不必要的梯度计算:在某些情况下,我们可能希望跟踪某个张量的值,但不需要计算其梯度。例如,如果我们有一个预训练的模型,并且希望固定其中的某些参数(不要更新它们的梯度),则可以将这些参数分离以避免计算它们的梯度。这可以通过在这些参数上调用
.detach()或.detach_()来实现。 - 避免计算图过大:有时候,我们可能担心计算图会变得过大,占用过多的内存。在这种情况下,您可以使用
.detach()来剥离计算图中的一部分,以减少内存占用。这在长时间的训练过程中可能会很有用。 - 阻止梯度流:有时,我们可能不希望某个张量的梯度流向更底层的张量。例如,在生成对抗网络(GAN)中,生成器和判别器的训练过程可能需要阻止生成器的梯度传播到判别器。在这种情况下,可以使用
.detach()或detach_()来分离生成器的输出。
分离计算可以把某些计算移动到计算图之外,李沐老师的动手学深度学习举了这样一个例子
假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。 想象一下,我们想计算z关于x的梯度,但由于某种原因,希望将y视为一个常数, 并且只考虑到x在y被计算后发挥的作用。
这里可以分离y来返回一个新变量u,该变量与y具有相同的值, 但丢弃计算图中如何计算y的任何信息。 换句话说,梯度不会向后流经u到x。 因此,下面的反向传播函数计算z=u*x关于x的偏导数,同时将u作为常数处理, 而不是z=x*x*x关于x的偏导数。
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
输出
tensor([True, True, True, True])