Spark
Apache Spark是一种快速、通用、可扩展的大数据处理引擎,旨在处理大规模数据集并进行高效的数据分析。与Hadoop MapReduce相比,Spark具有更高的性能和更丰富的功能,可以处理更复杂的数据处理任务。以下是Apache Spark的一些基本概念:
-
Spark Core:这是Spark的基本引擎,提供了分布式任务调度、内存数据存储和数据处理等核心功能。
-
RDD(弹性分布式数据集):Spark的RDD是一个不可变的、分布式的数据集合,它可以被缓存在内存中,以加快处理速度。
-
Spark SQL:一种用于结构化数据处理的Spark组件,可以使用SQL查询和DataFrame API处理数据。
-
Spark Streaming:一个用于处理流数据的Spark组件,可以对实时数据进行处理和分析。
-
MLlib:Spark自带的机器学习库,提供了各种常用的机器学习算法。
-
GraphX:一个用于图处理的Spark组件,提供了图形算法和数据结构的支持。
在大数据分析中,Spark被广泛应用于各种数据处理场景,例如数据清洗、预处理、特征提取、建模等。由于Spark的高速处理能力和强大的功能,它已成为大数据处理和分析的重要工具之一。
Spark架构图如下:
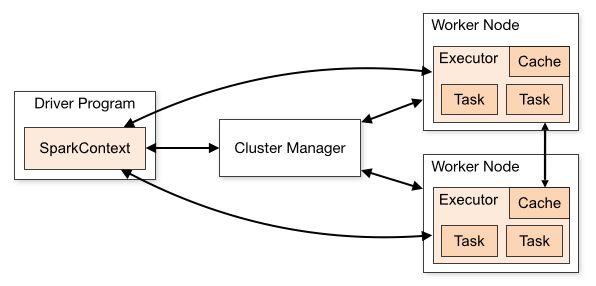
Spark架构主要由四个组件组成:Driver、Cluster Manager、Executor和Worker。
- Driver:驱动器是Spark应用程序中的主要组件。它负责整个应用程序的生命周期,包括创建SparkContext、创建RDD、调度任务、在Executor上运行任务等。
- Cluster Manager:集群管理器是Spark应用程序与底层集群系统的接口。它负责管理集群资源、分配任务、监控任务等。常用的集群管理器有Standalone、YARN和Mesos。
- Executor:执行器是集群中的工作节点,负责执行任务并返回结果给驱动器。一个Executor可以同时运行多个任务,每个任务运行在独立的线程上。
- Worker:工作节点是群集中的物理服务器。在Spark Standalone模式下,每个工作节点运行一个Worker,负责管理Executor并提供计算资源。
此外,Spark还具有一些其他的组件,如SparkContext、RDD和DataFrame等。SparkContext是Spark应用程序的入口点,用于与集群建立连接。RDD是Spark的核心数据抽象,代表不可变的分布式数据集。DataFrame是基于RDD的结构化数据抽象,提供了更高级别的API,支持SQL查询和数据分析。
- 安装Docker
首先需要先在服务器上安装Docker,可以参考官方文档来进行安装,具体步骤如下:
- 安装依赖:
sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
- 添加Docker官方GPG key:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
- 添加Docker官方仓库:
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
- 安装Docker:
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
- 构建Docker镜像
在部署Spark之前,需要先构建一个Spark的Docker镜像,我们可以使用Dockerfile来构建镜像。
首先,在本地下载Spark二进制文件,并将其复制到Dockerfile所在的目录中:
FROM ubuntu:18.04
RUN apt-get update && apt-get install -y software-properties-common
RUN add-apt-repository ppa:webupd8team/java -y
RUN apt-get update && apt-get install -y openjdk-8-jdk wget && apt-get clean
RUN wget http://mirror.bit.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
RUN tar -xzf spark-2.4.3-bin-hadoop2.7.tgz -C /usr/local/
RUN ln -s /usr/local/spark-2.4.3-bin-hadoop2.7 /usr/local/spark
然后在Dockerfile所在的目录中执行以下命令来构建镜像:
docker build -t spark_image .
- 启动容器
在构建完成Spark Docker镜像之后,接下来需要启动容器来运行Spark。我们可以使用docker run命令来启动容器,具体命令如下:
docker run -d -p 8080:8080 -p 7077Spark是一款基于Java的轻量级Web框架,它提供了一个简单、快速的方式来构建Web应用程序。以下是一些Spark Java实战:
- Hello World
在Spark Java中,编写第一个程序是Hello World,以下是一个简单的例子:
import static spark.Spark.*;
public class HelloWorld {
public static void main(String[] args) {
get("/", (req, res) -> "Hello World");
}
}
在这个示例中,我们监听了根路径的GET请求,并返回了Hello World。
- 静态文件服务
Spark Java允许我们轻松地为我们的Web应用程序提供静态文件服务,以下是一个简单的例子:
import static spark.Spark.*;
public class StaticFiles {
public static void main(String[] args) {
staticFiles.location("/public");
get("/", (req, res) -> "Hello World");
}
}
在这个示例中,我们告诉Spark Java将静态文件服务于/public路径,通过get("/")路由返回Hello World。
- 使用模板引擎
Spark Java允许我们使用模板引擎来渲染HTML页面。以下是一个使用Handlebars模板引擎的简单例子:
import static spark.Spark.*;
import java.util.HashMap;
import java.util.Map;
import spark.ModelAndView;
import spark.template.handlebars.HandlebarsTemplateEngine;
public class TemplateEngine {
public static void main(String[] args) {
staticFiles.location("/public");
HandlebarsTemplateEngine engine = new HandlebarsTemplateEngine();
get("/", (req, res) -> {
Map model = new HashMap<>();
model.put("title", "Welcome");
model.put("message", "Hello World");
return new ModelAndView(model, "index.hbs");
}, engine);
}
}
在这个示例中,我们使用Handlebars模板引擎渲染一个模板文件,该文件位于resources/templates/index.hbs。
- 使用数据库
Spark Java允许我们轻松地与数据库交互,以下是一个使用JDBC连接到MySQL的简单例子:
import static spark.Spark.*;
import java.sql.*;
public class DatabaseExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydatabase";
String user = "root";
String password = "password";
get("/users", (req, res) -> {
try (Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users")) {
StringBuilder sb = new StringBuilder();
while (rs.next()) {
sb.append(rs.getString("firstname")).append(" ")
.append(rs.getString("lastname")).append("
");
}
return sb.toString();
}
});
}
}
在这个示例中,我们使用JDBC连接到MySQL数据库,并返回users表中的所有行。