二手车信息爬取教程
爬取某子网二手车信息(附源码)
文章目录
- 一、简介
- 二、思路
- 三、主要功能点
- 四、总结
- 五、源代码
一、简介
本文通过对某个二手车网站近2000条数据的爬取,本程序突破了字体加密等反爬虫技术的限制,成功获取了JSON格式的数据,并将关键字段如车名、价格、里程数等提取并保存到CSV文件中。随后,程序对里程数和价格列进行数据清洗,去除单位并转换为浮点数类型,为后续的数据分析做好准备。最终,利用Matplotlib库绘制了三种图表,分别为里程数分布散点图、价格分布散点图和里程数与价格之间的散点图,帮助读者直观地了解二手车信息的数据特征,以及里程数和价格之间的关联。
二、思路
- 通过观察网页得知,数据被存储在postList下

- 观察表头,获取正确的url地址
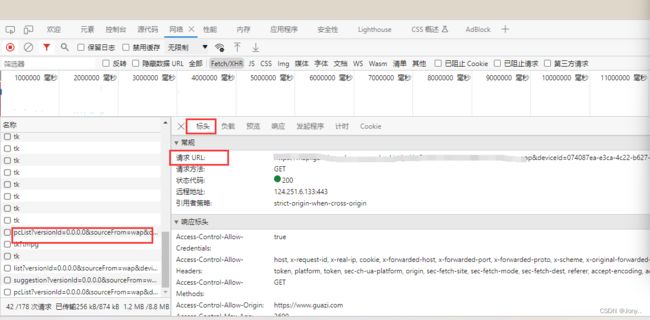
- 通过观察发现该网站采用了字体加密的反爬措施

- 解决字体加密反爬
观察每个数字对应的特殊字符
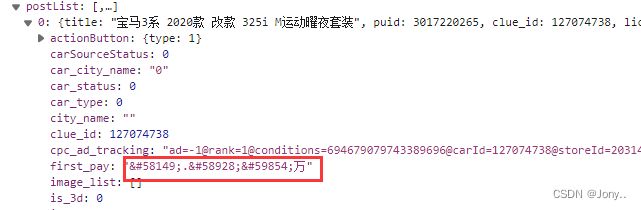
# 字体解密
font_data = {
'': '0', '': '2', '': '9', '': '3', '': '4',
'': '5', '': '1', '': '7', '': '8', '': '6',
}
# 替换源码中数字的密文
for i in font_data:
if str(i) in content:
content = content.replace(str(i), font_data[i].replace(';', ''))
三、主要功能点
- 数据采集:通过使用Python的爬虫技术,程序自动访问某个二手车网站,模拟浏览器行为,解析网页,成功获取了近2000条的二手车信息。通过破解网页中的字体加密,实现了反爬虫的目的。
import requests
import json
import jsonpath
import pandas as pd
pd.set_option('display.max_columns', None) # 显示完整的列
pd.set_option('display.max_rows', None) # 显示完整的行
pd.set_option('display.expand_frame_repr', False)
df = pd.DataFrame()
# 字体解密
font_data = {
'': '0', '': '2', '': '9', '': '3', '': '4',
'': '5', '': '1', '': '7', '': '8', '': '6',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 '
'Safari/537.36 Edg/114.0.1823.82'
}
for i in range(1, 100):
url = 'https://mapi.guazi.com/car-source/carList/pcList?versionId=0.0.0.0&sourceFrom=wap&deviceId=074087ea-e3ca-4c22' \
'-b627-d88abcd9713a&osv=Windows+10&minor=&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=&tag=-1' \
'&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=&emission=&car_color=&guobie' \
'=&bright_spot_config=&seat=&fuel_type=&order=&priceRange=0,' \
'-1&tag_types=10012&diff_city=&intention_options=&initialPriceRange=&monthlyPriceRange=&transfer_num=&car_year' \
'=&carid_qigangshu=&carid_jinqixingshi=&cheliangjibie=&page=' + str(
i) + '&pageSize=20&city_filter=12&city=12&guazi_city=12'
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
content = response.text
# 替换源码中数字的密文
for i in font_data:
if str(i) in content:
content = content.replace(str(i), font_data[i].replace(';', ''))
obj = json.loads(content)
postList = jsonpath.jsonpath(obj, '$..postList.[title,puid,clue_id,license_date,road_haul,thumb_img,price]')
try:
dataList = [postList[i:i + 7] for i in range(0, len(postList), 7)]
except TypeError:
break
# df = pd.DataFrame(dataList, columns=['车型', 'puid', 'clue_id', '年份', '公里数', '图片', '首付', '价格'])
df = df._append(
pd.DataFrame(dataList, columns=['车型', 'puid', 'clue_id', '上牌时间', '公里数(万)', '图片', '价格(万)']),
ignore_index=False)
# 重置索引
df.index = range(0, df.shape[0])
df.to_csv('二手车.csv', index=False, header=True, encoding='utf-8')
- 数据清洗:爬取到的二手车信息以JSON格式存储。程序将从JSON中提取的车名、价格和里程数等字段存储到CSV文件中,方便后续的数据处理和分析。同时,针对里程数和价格列的数据进行清洗,去除无用单位字符(如“公里”、“万”等),并将文本转换为浮点数类型,确保数据的准确性。
import pandas as pd
df = pd.read_csv('D:\BigData\pythonProject\爬虫\\requests\二手车.csv')
# 对里程数进行处理
for i in range(0, len(df['公里数(万)'])):
data = df['公里数(万)'][i]
if len(data) == 5:
df['公里数(万)'][i] = str(int(data[:-2])/10000) + '万公里'
df['公里数(万)'][i] = float(df['公里数(万)'][i][:-3])
# 对价格进行处理
for i in range(0, len(df['价格(万)'])):
df['价格(万)'][i] = float(df['价格(万)'][i][:-1])
- 数据分析:通过使用Python的数据分析库,程序对清洗后的数据进行统计和可视化。首先,绘制了里程数分布散点图,帮助读者直观了解二手车里程数的分布情况。接着,绘制了价格分布散点图,展示了二手车价格的分布情况。最后,绘制了里程数与价格之间的散点图,探究二手车里程数与价格之间的关联关系。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来显示负号
# 绘制里程数分布散点图
plt.scatter(df.index, df['公里数(万)'])
plt.xlabel('车辆编号')
plt.ylabel('公里数(万)')
plt.title('里程数分布散点图')
plt.show()
# 绘制历程数直方图
plt.hist(df['公里数(万)'], bins=20) # bins的数量可以改变直方图的分组
plt.xlabel('公里数(万)')
plt.ylabel('数量')
plt.title('里程数分布直方图')
plt.show()
# 绘制里程跟价格之间的散点图
plt.scatter(df['公里数(万)'], df['价格(万)'])
plt.xlabel('里程数(万公里)')
plt.ylabel('价格(万元)')
plt.title('里程数和价格散点图')
plt.show()
四、总结
该程序为二手车交易数据提供了全方位的数据采集、清洗和分析能力,为二手车市场的观察和研究提供了有力支持。读者可以通过该程序深入了解二手车市场的行情和特征,同时也可以借鉴和拓展该程序,实现更多数据采集与分析的功能。无论是对于二手车交易者还是研究者,这款二手车信息爬虫程序都是一个非常实用的工具。
五、源代码
import requests
import json
import jsonpath
import pandas as pd
pd.set_option('display.max_columns', None) # 显示完整的列
pd.set_option('display.max_rows', None) # 显示完整的行
pd.set_option('display.expand_frame_repr', False)
df = pd.DataFrame()
# 字体解密
font_data = {
'': '0', '': '2', '': '9', '': '3', '': '4',
'': '5', '': '1', '': '7', '': '8', '': '6',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 '
'Safari/537.36 Edg/114.0.1823.82'
}
for i in range(1, 100):
url = 'https://mapi.guazi.com/car-source/carList/pcList?versionId=0.0.0.0&sourceFrom=wap&deviceId=074087ea-e3ca-4c22' \
'-b627-d88abcd9713a&osv=Windows+10&minor=&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=&tag=-1' \
'&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=&emission=&car_color=&guobie' \
'=&bright_spot_config=&seat=&fuel_type=&order=&priceRange=0,' \
'-1&tag_types=10012&diff_city=&intention_options=&initialPriceRange=&monthlyPriceRange=&transfer_num=&car_year' \
'=&carid_qigangshu=&carid_jinqixingshi=&cheliangjibie=&page=' + str(
i) + '&pageSize=20&city_filter=12&city=12&guazi_city=12'
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
content = response.text
# 替换源码中数字的密文
for i in font_data:
if str(i) in content:
content = content.replace(str(i), font_data[i].replace(';', ''))
obj = json.loads(content)
postList = jsonpath.jsonpath(obj, '$..postList.[title,puid,clue_id,license_date,road_haul,thumb_img,price]')
try:
dataList = [postList[i:i + 7] for i in range(0, len(postList), 7)]
except TypeError:
break
# df = pd.DataFrame(dataList, columns=['车型', 'puid', 'clue_id', '年份', '公里数', '图片', '首付', '价格'])
df = df._append(
pd.DataFrame(dataList, columns=['车型', 'puid', 'clue_id', '上牌时间', '公里数(万)', '图片', '价格(万)']),
ignore_index=False)
# 重置索引
df.index = range(0, df.shape[0])
df.to_csv('二手车.csv', index=False, header=True, encoding='utf-8')
import pandas as pd
df = pd.read_csv('D:\BigData\pythonProject\爬虫\\requests\二手车.csv')
# 对里程数进行处理
for i in range(0, len(df['公里数(万)'])):
data = df['公里数(万)'][i]
if len(data) == 5:
df['公里数(万)'][i] = str(int(data[:-2])/10000) + '万公里'
df['公里数(万)'][i] = float(df['公里数(万)'][i][:-3])
# 对价格进行处理
for i in range(0, len(df['价格(万)'])):
df['价格(万)'][i] = float(df['价格(万)'][i][:-1])
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来显示负号
# 绘制里程数分布散点图
plt.scatter(df.index, df['公里数(万)'])
plt.xlabel('车辆编号')
plt.ylabel('公里数(万)')
plt.title('里程数分布散点图')
plt.show()
# 绘制历程数直方图
plt.hist(df['公里数(万)'], bins=20) # bins的数量可以改变直方图的分组
plt.xlabel('公里数(万)')
plt.ylabel('数量')
plt.title('里程数分布直方图')
plt.show()
# 绘制里程跟价格之间的散点图
plt.scatter(df['公里数(万)'], df['价格(万)'])
plt.xlabel('里程数(万公里)')
plt.ylabel('价格(万元)')
plt.title('里程数和价格散点图')
plt.show()
文末:本文仅供学习使用,不支持任何商业或投资用途!