CMU15-445 数据库实验全满分通过笔记 2021 Fall bustub-cmudb lab
Contents
- PROJECT #0 - C++ PRIMER
- PROJECT #1 - BUFFER POOL
-
- TASK #1 - LRU REPLACEMENT POLICY
- TASK #2 - BUFFER POOL MANAGER INSTANCE
- TASK #3 - PARALLEL BUFFER POOL MANAGER
- PROJECT #2 - EXTENDIBLE HASH INDEX
-
- TASK #1 - PAGE LAYOUTS
-
- 零长度数组与reinterpret_cast
- 桶的大小
- 桶内删除条目
- 桶中的元素是否连续
- TASK #2 - HASH TABLE IMPLEMENTATION
-
- 总体实现
- 对页的操作
- 桶页分裂
- 桶页合并
- PROJECT #3 - QUERY EXECUTION
-
- helper classes
-
- Value
- Tuple
- TablePage
- TableHeap
- TableIterator
- RID
- Column
- Schema
- Index
- Catalog
- AbstractExpression
- AbstractPlanNode
- AbstractExecutor
- ExecutorContext
- ExecutorFactory
- ExecutionEngine
- 关于类的构造函数:右值引用和vector初始化
- executor_test
- Excecutor 实现的一些细节
-
- INSERT/DELETE
- UPDATE
- NESTED LOOP JOIN
- HASH JOIN
- DISTINCT
- PROJECT #4 - CONCURRENCY CONTROL
-
- TASK #1 - LOCK MANAGER
-
- 事务及其隔离级别
- 加锁、解锁的方案
- 请求队列与并发控制
- TASK #2 - DEADLOCK PREVENTION
- TASK #3 - CONCURRENT QUERY EXECUTION
- 总结
PROJECT #0 - C++ PRIMER

如果本地测试能通过,gradescope报错Test Failed: Test was not run. Please check the autograder!,说明build失败,可能的原因是没有进行make format格式检查,还可能是上传课程的年份搞错了(注意仓库是最新的版本,所以提交到最新的课程)。
如果内存安全测试报错Conditional jump or move depends on uninitialised value(s),可能是因为矩阵乘法中没有将矩阵初始化为全0。
- const对象只能访问const成员函数。const成员函数例子:
virtual int GetRowCount() const {
return rows_;
}
- C++智能指针
unique_ptr独享被管理对象指针所有权,要创建非空的 unique_ptr 对象,需要在创建对象时在其构造函数中传递原始指针,即:
std::unique_ptr<RowMatrix<T>> ret(new RowMatrix<T>(r1, c2));
std::unique_ptr<RowMatrix<T>> ret = new RowMatrix<T>(r1, c2); //错误,不能以赋值方式定义!
将其转换为普通指针:
RowMatrix<T> *p = ret.get();
- 抛出异常:
throw Exception(ExceptionType::OUT_OF_RANGE, "out of range!");
PROJECT #1 - BUFFER POOL

TASK #1 - LRU REPLACEMENT POLICY
原理比较简单,可见LRU缓存机制。
- 加锁和解锁:
std::mutex mtx_;
mtx_.lock();
···
mtx_.unlock();
注意mutex不是可重入锁(递归锁),所以两个函数之间有调用关系时,不能上同一把锁。
TASK #2 - BUFFER POOL MANAGER INSTANCE
这个比较难理解的是frame和page、buffer pool和replacer之间的关系。

实际上,buffer pool像一个page的容器,而page在容器的哪里由frame标记,page table就是记录page和frame的映射关系的。也就是说,frame是一个物理的概念。而frame中,哪些被page占用,哪些是空的,由free_list标记。哪些包含page的frame可以被victim,需要借助replacer来选择。replacer仅仅记录frame的编号。最后,page中的page_id说明它来自于哪个物理页面,但实际上虚拟页面和物理页面的转换已经写好了,我们不需要关心。
操作的具体步骤基本上在注释中说的很明白了,再补充一些:
- 新建页面是要pin的,而fetch页面时如果已存在则引用计数加一,否则相当于新建一个页面,引用计数设为1。
- 一个本地测试样例没测出来但在gradescope中测试出来的地方:UnpinPgImp中只有is_dirty_为真时设置页面为脏,如果is_dirty_为假,页面不能设置成不脏,因为其他进程可能写过该页面!
TASK #3 - PARALLEL BUFFER POOL MANAGER
貌似是今年新加的一项。实现起来很简单,搞清楚继承关系。
- 为存储多个BufferPoolManagerInstance,一开始想创建一个对象数组,但是数组需要用花括号的形式构造,而且需要写出实际的构造参数。因此,最后采用vector,并且循环构造压入。vector的类型为BufferPoolManagerInstance。
- BufferPoolManagerInstance和ParallelBufferPoolManager是平级的关系,它们都继承于BufferPoolManager类。在进行FlushPgImp、UnpinPgImp等时,可以直接取vector中的元素操作某一个缓冲池;也可以使用GetBufferPoolManager来取,不过它的返回值是父类指针类型的,需要进行类型转换:
return dynamic_cast<BufferPoolManagerInstance *>(GetBufferPoolManager(page_id))->FlushPgImp(page_id);
PROJECT #2 - EXTENDIBLE HASH INDEX

做的非常艰难,只能借助gradescope的输出来debug,前前后后提交了近200次······好多坑我只能说。
TASK #1 - PAGE LAYOUTS
零长度数组与reinterpret_cast
HashTableBucketPage类中,复杂保存键值对的成员数组的定义:
MappingType array_[0];
这是一个Zero-length array(零长度数组)。它位于结构体/类的最后,本身不占用空间。在声明结构体的时候分配内存,去除掉其他元素的部分就是零长度数组可以访问的部分。
而类的实例化是不能定义大小的。但是,我们的类比较特殊,它的实际意义是一个页面,而页面的大小是固定的。从测试代码可以看到该类实例化是这样的:
auto bucket_page = reinterpret_cast<HashTableBucketPage<int, int, IntComparator> *>(
bpm->NewPage(&bucket_page_id, nullptr)->GetData());
定义了一个页面,页面的data部分是全零的字节。使用reinterpret_cast,将这块空白解释为我们的对象。由于类中的成员函数是在代码段的,这块空白实际上被解释为类中的成员函数,内存分配与结构体类似。本题中已经根据页面大小为我们算好了BUCKET_ARRAY_SIZE,所以可以放心地取用这个零成员数组了。
桶的大小
源代码中,桶的大小是这样确定的:
#define BUCKET_ARRAY_SIZE (4 * PAGE_SIZE / (4 * sizeof(MappingType) + 1))
char occupied_[(BUCKET_ARRAY_SIZE - 1) / 8 + 1];
妙就妙在这里occupied数组的大小,是对BUCKET_ARRAY_SIZE/8向上取整,但是却不会发生内存泄漏。题中PAGE_SIZE已经定义为4096。取sizeof(MappingType)为1,BUCKET_ARRAY_SIZE计算得3276,occupied_差长度计算得410,实际占用空间为410*2+3276*1=4096,正好填满。测试了几个例子,都满足不会内存泄漏,直觉上来说,是因为char的size比较小,所以在较大的PAGE_SIZE下,多那么一个两个char不会抵消计算BUCKET_ARRAY_SIZE向下取整的富余空间。
桶内删除条目
为什么在HashTableBucketPage类中定义了两个工具类数组occupied和readable?在occupied的注释中找到原因:
// 0 if tombstone/brand new (never occupied), 1 otherwise.
原来删除一个条目之后,occupied仍然显示占据状态,所以应该修改readable来表示删除。不过,个人认为设计两个工具类数组是没有什么必要的,因为tombstone的设计主要是为了在开放寻址法中防止探测中断 Hash Tables · Crafting Interpreters,而我们的EXTENDIBLE HASH TABLE显然不需要,如果让我设计,删除直接把占用标志去掉就可以了。
重点来了!墓碑仅仅辅助探测,因此在插入节点时,仍然将其视为可以插入(因为插入后不会影响探测)。所以,桶空桶满只需要看readable。
桶中的元素是否连续
这个问题及occupied数组中的1是否是从数组头到数组尾连续增长的。进行普通的插入和删除条目时,我们可以保持occupied数组中1的连续状态,这让对桶的操作不必对整个数组遍历,在occupied数组找到0时停止即可。但是,实际上这里有个坑,因为有一种操作可以改变这种连续状态,那就是桶分裂。由于桶内数组被设置成了私有类型,在进行桶分裂的时候,只能通过修改occupied的每一位来代表数组是否还保留在当前桶内。因此,在插入、删除元素到桶内时,不能把元素看成连续的,还是需要遍历整个数组。
以上是我还没意识到墓碑值可以插入的时候写的,意识到了之后显然不用考虑了,当然不连续啦!
TASK #2 - HASH TABLE IMPLEMENTATION
总体实现
这张图画的很清楚了:

注意本次project建议根据后面的位来进行区分,即目录页中数组的下标,和图上相反。
对页的操作
这是一个重点,因为我在这上面栽了100多次。。因为没有及时unpin导致bufferpool满,进而无法运行,而在gradescope上根本没法看出来,直到bufferpool满时LOG_DEBUG才找到。
buffer_pool_manager->NewPage(&bucket_page_id, nullptr); //新建页
reinterpret_cast<HashTableDirectoryPage *>(buffer_pool_manager_->FetchPage(directory_page_id_, nullptr)->GetData()); //获取页内容
buffer_pool_manager_->UnpinPage(bpg_page_id, true, nullptr); //无论新建页,还是获取页,都不要忘记unpin
普通的查找、插入和删除都不难,重点是分裂和合并的逻辑。
桶页分裂
注意,接下来提到的“桶”指目录页数组的一个元素,而不是具体的存储元素的“桶页”,前者指向后者,是多对一的关系。
插入时如果桶页已满则进行分裂。步骤如下:
-
获取目录页、需要分裂的桶页。记住桶页所在页(Page)的ID,最后unpin要用。
-
判断是否需要IncrGlobalDepth。如果需要分裂的桶的深度和全局深度相等了,则增加全局深度,即将桶数扩张一倍,扩张的部分桶对应的bucket_page_id和local_depth都要和前面的桶对应。
-
新建一个桶页,并修改目录页中的bucket_page_ids,让桶中该指向新桶页的指向它。遍历指向旧桶页的桶,根据桶的局部深度对应的位之前的那一位来判断应该指向新桶页还是旧桶页。边遍历边增加local_depth:
size_t common_bits = kti % (1 << dpg->GetLocalDepth(kti)); //kti为分裂桶下标 size_t ld = dpg->GetLocalDepth(kti); for (size_t i = common_bits; i < dpg->Size(); i += (1 << ld)) { if (((i >> ld) & 1) != ((kti >> ld) & 1)) { dpg->SetBucketPageId(i, new_bucket_page_id); } dpg->IncrLocalDepth(i); } -
移动元素到新桶页。在桶页类中自定义删除和设置键值对的public函数,对桶页中每个元素重新将key映射到页来判断是否需要移动。
-
unpin目录页、旧桶页和新桶页,重新插入元素。
桶页合并
如果删除后变成空桶页则尝试合并。步骤如下:
-
获取目录页,需要合并的空桶在目录中的下标,以及镜像(image)桶的下标。image即合并的对象,如目录页容量是8的话,下标0/4,1/5,2/6,3/7互为镜像。
-
判断是否满足合并条件,即该空桶深度不为0,且桶和镜像桶深度相等。还有一个条件,就是桶和镜像对应的不是同一个桶页(否则没必要合并了)。若不满足,直接返回。
-
转移那些指向空桶的指针到镜像桶页,这一步和桶分裂的第三步实现类似。
-
删除旧桶页。注意删除之前如果有fetch过,一定要对应进行unpin,否则pin_count不为1,没法删除。
-
对目录进行Shrink,判断条件是所有桶局部深度都小于全局深度。此时,每一个桶和它的镜像桶都指向同一个桶页,所以直接DecrGlobalDepth。
之后还有一步,那就是遍历Shrink后的目录,对每个空桶尝试合并。这是因为,Shrink之后,每个桶的镜像发生了变化。例如,假设目录页容量本来是8,其中0/4/5/7(下标)是空桶,接下来,6变成空桶,2与6合并,并发生Shrink,此时2的镜像为0,0是空桶应该合并。而之前0刚变为空桶时,它的镜像是4,所以还不能与2合并。
PROJECT #3 - QUERY EXECUTION

helper classes
为了了解这些类是怎么配合实现语句的完成的,需要好好读下工具类和测试类代码,然后厘清类之间的关系。知道每个类及其成员变量、成员函数的功能,就能顺理成章完成各项操作的实现。
Value
从最小的类开始。Value可以理解为单元格,并且提供了一些比较和运算的函数。
Tuple
可以理解为一行。其中的data_字段存储了Value,使用GetValue()即可获得。虽然tuple中有rid_字段,但是在插入tuple操作中没有对其进行修改,而且也备注了该字段只在指向TableHeap时有用,所以不能把它当成tuple所在的RID。
TablePage
继承于Page类,是表的存储单元。提供了对页中Tuple的操作。
TableHeap
可以理解为一个表的物理表示,对应TablePage的双向链表。提供了对表中Tuple增删改查的操作。
TableIterator
TableHeap的迭代器,由于其运算符已经重载,所以可以当成Tuple的指针来使用。
RID
RID对应物理表页ID及在页中槽的位置,一般记录一个tuple的物理位置。
Column
表格一列的列头信息,包含类型、名称等。
Schema
表格的所有列头,主要包含一个Column的数组。
Index
表格的索引信息,每个索引提供tuple到RID的对应关系,依靠之前的ExtendibleHashTable实现。
Catalog
一个数据库的全部表格信息的索引,提供了对表格的操作。成员变量主要包括:TableInfo的表,每个TableInfo包括一个表格的ID、Schema、TableHeap;IndexInfo的表,即每个表格的索引信息。
AbstractExpression

对where语句(其实不止where语句中用到)进行拆分,形成一个树,其中的每一个节点就对应一个AbstractExpression类,该抽象类包括其子节点以及返回类型,还有其他有用的方法。其中:
-
ConstantValueExpression represents constants.
Evaluate()方法返回这个常量。这个Expression主要作为后面类型节点的子树。EvaluateAggregate()方法是给ComparisonExpression的EvaluateAggregate()使用的,可以不管。
-
ColumnValueExpression is an abstraction around “Table.member” in terms of indexes.
成员变量tuple_idx_在join操作中指明该列来自于左边的表还是右边的表,col_idx_代表该列在schema中的下标。Evaluate()方法根据输入的tuple和schema返回tuple中该列对应的value。EvaluateJoin()方法与前者不同的是,它接受join操作中两个表的两个tuple,根据tuple_idx_返回真正是该列对应的tuple中对应的value。
测试代码在构造outputschema时,会对每个column中的ColumnValueExpression成员赋值,换句话说,我们知道每个column对象在其schema的下标,以及它在join操作时的位置(左还是右)。SeqScan操作构建结果tuple时,就可以利用Evaluate()方法获取outputschema中每列对应的值:
for (uint32_t i = 0; i < plan_->OutputSchema()->GetColumnCount(); ++i) { values.emplace_back(plan_->OutputSchema()->GetColumn(i).GetExpr()->Evaluate(&*iter_, &table_info_->schema_)); //注意这里的ColumnValueExpression中的schema是对应原表的,而不是OutputSchema }而进行join操作构建最终结果tuple时,每个column的ColumnValueExpression是对应中间结果的outputschema构建的。从而,当根据左元组outer_tuple_、右元组inner_tuple_构建结果tuple时,可以使用EvaluateJoin()方法获取outputschema中每列对应的值:
for(uint32_t i = 0;i<plan_->OutputSchema()->GetColumnCount();++i){ values.emplace_back(plan_->OutputSchema()->GetColumn(i).GetExpr()->EvaluateJoin(&outer_tuple_, outer_schema, &inner_tuple_, inner_schema)); } -
AggregateValueExpression represents aggregations such as MAX(a), MIN(b), COUNT©.
对应aggregate相关的列,根据类型分为group_by(分组依据)和aggregate(对该列进行取最大值等聚合操作)两种,唯一的EvaluateAggregate()方法的用途是分别传入group_by和aggregate对应的value,返回该列对应的那一个value。
-
ComparisonExpression represents two expressions being compared.
它的两个子树可能是一个ColumnValueExpression和一个ConstantValueExpression,Evaluate()对tuple的某列与常数比较判断大小(即WHERE);也可能是两个ColumnValueExpression,EvaluateJoin()对两个tuple的两列判断是否相等(即JOIN ON);还可能是一个AggregateValueExpression和一个ComparisonExpression,EvaluateAggregate()对某列aggregate的结果(或者group用到的某列)与常数比较判断大小(即HAVING)。
AbstractPlanNode

对SQL语句的操作进行拆分,形成一个树,其中的每一个节点就对应一个executor,而AbstractPlanNode类包含执行该节点功能需要的一些材料。该抽象类包括其子节点,以及向上返回的列格式(Schema)。对于不同类型的语句,有不同的节点类的实现:如IndexScanPlanNode中包括需要扫描的表的ID,以及扫描的Tuple需要满足的条件predicate_,也就是where树AbstractExpression。
AbstractExecutor
executor的实现。主要的函数是Next(),以tuple为单位执行。
ExecutorContext
一个executor执行的背景信息,包括Executor所在数据库的Catalog,也就是包含该数据库的信息。
ExecutorFactory
创建executor的类,将ExecutorContext和AbstractPlanNode以及它们的孩子根据节点类型进行结合,从而创建一个AbstractExecutor。
ExecutionEngine
创建并执行executor,输入AbstractPlanNode和ExecutorContext,不断执行AbstractExecutor的Next(),输出结果Tuple(如果需要输出)。
关于类的构造函数:右值引用和vector初始化
AbstractPlanNode和InsertPlanNode的构造函数如下:
AbstractPlanNode(const Schema *output_schema, std::vector<const AbstractPlanNode *> &&children)
: output_schema_(output_schema), children_(std::move(children)) {}
InsertPlanNode(const AbstractPlanNode *child, table_oid_t table_oid)
: AbstractPlanNode(nullptr, {child}), table_oid_(table_oid) {}
其中的&&children,不是取两次地址的意思,而是右值引用;std::move(children)将左值转化为右值引用。简单说,移动构造函数执行时,让AbstractPlanNode中使用的children_不是传入的children的拷贝,而是children的内容本身,从而减少拷贝操作的代价。 C++ 的移动 move 是怎么运作的? - 知乎 (zhihu.com)
{child}实际上是构造了一个包括一个元素的vector,从而作为参数传入。C++如何实现用大括号初始化vector - 简书 (jianshu.com)
executor_test
阅读测试类是怎么使用我们的executor对表格操作的对理清头绪很有帮助。测试类的表格在table_generator中定义、生成,GenerateTestTables()给出了每个表的内容是怎么生成的,注意Dist::Serial是指该列的数从0增加到SIZE-1,而Dist::Cyclic类型的列的数从0增加到max,然后再变为0,以此往复。
Excecutor 实现的一些细节
INSERT/DELETE
注意一点,哈希表的key tuple对应indexed columns,只包含索引列对应的value。至于那些列是索引列,记录在成员变量metadata_的key_attrs_当中。在插入、删除Entry时,注意key tuple是否是索引列相对应的。以删除行修改索引为例:
for (IndexInfo *index : indexes_) {
std::vector<Value> key_index_vals{};
for (auto const &i : index->index_->GetKeyAttrs()) {
key_index_vals.emplace_back(old_tuple.GetValue(child_executor_->GetOutputSchema(), i));
}
index->index_->DeleteEntry(Tuple(key_index_vals, index->index_->GetKeySchema()), old_rid,
GetExecutorContext()->GetTransaction());
}
UPDATE
注意Next函数只调用一次,否则会生产出结果元组,这是不合逻辑的。
NESTED LOOP JOIN
原理不难,实现难点在于一次Next在嵌套循环中的角色。每次Next都会返回一个内外tuple中join成功的tuple结果,并且在此之前跳过那些不能join的tuple。直觉上想到使用分别指向两个表的迭代器帮助,但这部分被scanExecutor的Next隐藏了,我们能获得的信息只有是否扫描到了表的最后。因此,初始化两个标志变量指示:
bool outer_not_end_{true};
bool inner_not_end_{true};
Next中,我们的逻辑是这样的:
while (outer_not_end_ || inner_not_end_) {
if (outer_not_end_ && inner_not_end_ &&
(plan_->Predicate() == nullptr ||
plan_->Predicate()->EvaluateJoin(&outer_tuple_, outer_schema, &inner_tuple_, inner_schema).GetAs<bool>())) {
// 为结果tuple赋值(略)
inner_not_end_ = right_executor_->Next(&inner_tuple_, &inner_rid_);
return true;
}
if (inner_not_end_) {
inner_not_end_ = right_executor_->Next(&inner_tuple_, &inner_rid_);
} else {
outer_not_end_ = left_executor_->Next(&outer_tuple_, &outer_rid_);
if (outer_not_end_) {
right_executor_->Init();
inner_not_end_ = right_executor_->Next(&inner_tuple_, &inner_rid_);
}
}
}
return false;
HASH JOIN
需要构建一个哈希表,哈希表的key是outer_table的join对应的value,而哈希表的value是对应的tuples(放于vector)。由于Value类作为std::unordered_map的key需要重写哈希和“==”,所以包装一个类,可以参考AggregationExecutor中的SimpleAggregationHashTable实现。
回到功能实现上面,Init()很明显是将左表中的tuple加入哈希表,问题又到了Next()上。实际上也有两层循环的含义在里面:一层是扫描右表,一层是扫描哈希表中右表对应的tuple集合(因为左表可能有tuple对应的key相等)。使用一个变量记录哈希表中某一个tuple集合的下标,并记录扫描的右表tuple:
int32_t outer_index_{-1};
Tuple inner_tuple_{};
next的逻辑是这样的:
JoinKey cur_key;
if (outer_index_ != -1) {
cur_key.col_val_ = plan_->RightJoinKeyExpression()->Evaluate(&inner_tuple_, right_executor_->GetOutputSchema());
}
if (outer_index_ == -1 //判断是否第一次执行Next()
|| hashmap_.find(cur_key) == hashmap_.end() //判断当前是否已经指向一个能join的右表tuple
|| outer_index_ == static_cast(hashmap_[cur_key].size()) //判断这个能join的右表tuple是否还能跟左表tuple相结合
) {
while (true) {
if (right_executor_->Next(&inner_tuple_, &inner_rid)) {
cur_key.col_val_ = plan_->RightJoinKeyExpression()->Evaluate(&inner_tuple_, right_executor_->GetOutputSchema());
if (hashmap_.find(cur_key) != hashmap_.end()) {
outer_index_ = 0;
break;
}
} else {
return false;
}
}
}
// 为结果tuple赋值(略)
++outer_index_;
return true;
DISTINCT
同样构建一个哈希表,和HASH JOIN中的唯一区别就是key可能不止一个Value类,其实和AggregationExecutor中的SimpleAggregationHashTable的AggregationKey的实现几乎一摸一样了,不再赘述。
PROJECT #4 - CONCURRENCY CONTROL

TASK #1 - LOCK MANAGER
事务及其隔离级别
事务可以简单理解为执行几条语句。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable) | 不可能 | 不可能 | 不可能 |
最高的隔离级别Serializable是指两个事务的执行效果和前后分别执行的效果相同。尽管这样的结果最准确,但并行效率低,因此在执行事务时可以为其选择一个较低隔离级别。下面对分别举例说明不同隔离级别允许的bug:
-
脏读的产生:事务1修改数据,被事务2读到,之后事务1abort,事务2读到的是脏数据。
-
不可重复读的产生:事务1读数据,事务2修改数据,事务1再读数据,事务1两次读到的数据不一致。
-
幻读的产生:事务1统计行数,事务2插入数据,事务1再统计行数,事务1两次统计的行数不一致。
加锁、解锁的方案
为实现并发控制,有悲观和乐观两种方案。先说后者,即认为事务间相互影响的可能性小,所以不考虑而直接执行,发现问题就利用时间戳解决。悲观的方案就是在事务读写的时候对表上锁了,也就是这次的方案。本project的锁都是加在RID对应的Tuple上的,在table_page.h中的增删改查Tuple的方法中,通过调用lock_manager.h的方法实现上锁、解锁,后者也就是我们要补充完成的。
之后的内容中写锁代表exclusive lock,读锁代表shared lock,升级锁/更新锁代表updated lock。
在这次的project中,我们被要求实现前三种事务隔离级别(对tuple上锁并不能解决幻读,因此无法实现SERIALIZABLE)。
-
READ_UNCOMMITED只有在需要时上写锁。
-
READ_COMMITTED要解决脏读的问题,解决方案就是读时上读锁,读完解读锁;写时上写锁,但等到commit时才解写锁;读时上读锁,读完解读锁。这样,永远不会读到未commit的数据,因为上面有写锁。
-
REPEATABLE_READ进一步打造可重复读。同一事务读两次数据的中途不想被其他事务的写干扰,这就需要用到巧妙的二段封锁协议(2PL)了:事务分为两个阶段(不考虑commit/abort),上锁阶段(GROWING)只上锁,解锁阶段(SHINKING)只解锁。这样,第二次读取时,前一次读取的读锁一定还在,避免了中途被修改。
请求队列与并发控制
每一个tuple对应的RID都可以有一个LockRequestQueue用来维护对其加锁的请求。LockRequestQueue中有类型为std::condition_variable的变量对请求阻塞(wait())或唤醒(notify_one()/notify_all())。阻塞是在加锁函数中执行,而唤醒是在解锁函数中执行。注意,notify_one()是随机选择一个阻塞的进程恢复;如果判断条件正确,使用notify_all()效率更高。
- 加读锁:将请求加入队列,循环判断是否满足加读锁条件(当前没有写锁),满足则继续执行,否则阻塞;
- 加写锁:将请求加入队列,循环判断是否满足加写锁条件(当前没有读锁和写锁),满足则继续执行,否则阻塞;
- 加升级锁:将读锁升级为写锁。由于加写锁需要保证当前没有读锁,那么如果队列中有两个更新锁的请求,就会互相等待对方解读锁。因此,为了判断是否出现这种情况,在队列中维护标志变量
upgrading_,不允许队列中出现两个更新锁的请求。将队列中的读锁请求改为写锁,循环判断是否满足加更新写锁条件(当前没有写锁,且只有唯一一个该读锁)。
std::unordered_map用来维护这些队列。但每次加入一个初始化的LockRequestQueue时,会发现报错,这是因为**mutex和condition_variable不能被复制或移动**condition_variable::condition_variable - C++ Reference (cplusplus.com)。我们只能采取在map中原地构造的方式将其加入,即使用emplace(),并且需要配合pair’s piecewise constructorpiecewise_construct存在的意义 - PKICA - 博客园 (cnblogs.com):
lock_table_.emplace(std::piecewise_construct, std::forward_as_tuple(rid), std::forward_as_tuple());
疑问:为什么map中不直接放队列的指针呢?
还需要注意的是,无论是对请求队列还是lock_table_进行写操作的时候,都要使用互斥锁进行保护,否则会发生不可预知的情况。
TASK #2 - DEADLOCK PREVENTION
首先,注意21年的project将20年的死锁检测修改为死锁预防,而这部分的源码是在21年11月更新的,不要像我傻不拉几用之前的代码写好了死锁检测发现过时了。
关于我们用的Wound-Wait策略,PPT上仅有的内容如下:
Assign priorities based on timestamps: Older Timestamp = Higher Priority
Wound-Wait (“Young Waits for Old”): If requesting txn has higher priority than holding txn, then
holding txn aborts and releases lock.Otherwise requesting txn waits.
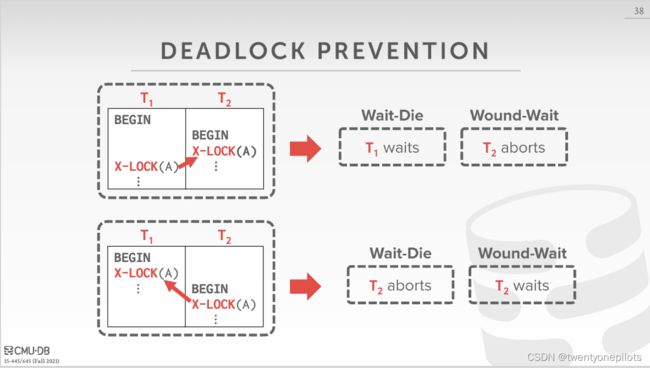
大意是如果发现当前持有锁的事务比自己更老,就等待;否则abort掉当前持有锁的事务,自己上锁。(这只是两个事务分别想上一个X锁的情况)
比较坑的是,实现的很多细节并没有提到。所以只能根据测试的结果,自己修改细节了,目前得到的能通过测试的策略如下(以下新/老事务分别指事务ID较大的一方和较小的一方):
-
关于未上锁请求。非常关键的一点,如果老事务想上锁,队列中如果有只是在等待并没有获得锁的新事务请求,也要abort它。如果老事务请求继续等待,测试就会超时。这也是很confusing的一点,因为这意味着
LockRequest的granted_字段没有用了,根本不需要管它有没有获得锁,该abort就abort。 -
关于共享锁/读锁。如果老事务要加读锁,那么要把队列中新事务的写锁请求abort掉。而对于读锁请求,可以共存。
-
关于异常抛出。不幸的是,虽然实验文档让我们抛出异常,但lock_manager的测试中没有对死锁的异常处理(实际通过transaction_manager在数据库中运行的时候,可以自己在excution_engine中catch异常),而只是检查事务状态是否设为abort,并且直接显式调用Abort()将事务中止。所以为了通过测试,我们只能不抛出异常。
那么再做一些思考,在能正确catch异常的情况下,应该在什么时候抛出异常呢?每当老事务因上锁冲突将新事务的状态设为abort,应当对新事务抛出TransactionAbortException。
如果在老事务的上锁函数中抛出异常,老事务的该上锁函数就会停止运行,不能继续上锁。可以选择在抛出之前递归执行老事务的上锁函数,不过一定要控制好递归条件,避免栈溢出。
如果想在新事务的函数中抛出异常的话,新事务要是在等待那好说,唤醒它,它发现自己abort就在自己的上锁函数中抛出异常。但如果新事务已经获得这个锁了,那只能在它unlock的时候抛出,这就需要用一些变量记录是否应该抛出,unlock的时候再判断了。
TASK #3 - CONCURRENT QUERY EXECUTION
首先,在executor中该加锁的地方加锁,该解锁的地方解锁。具体一点,就是scan时加读锁,delete和update时加升级锁/写锁。insert操作加的是新行,超纲了,不需要我们操作。
维护并发操作还需Abort后正确回滚。回滚,即插入的给它删掉、删掉的再插入回去,这是在transaction_manager的Abort函数中做的,而插入或删掉的被放在每个transaction的数据结构table_write_set_和index_write_set_中。其中前者记录元组操作,后者记录索引操作。table_heap的增删改方法中已经包含了对table_write_set_的维护,所以我们只需要在修改索引时维护index_write_set_即可。
最后在这里有一个坑,我还没有找到解决的方法。在update_executor中,每次更新一个tuple对应的索引时应当向IndexWriteSet中添加一个IndexWriteRecord。IndexWriteRecord需要包括更新前的tuple(old_tuple_)和更新后的tuple,但是该类的构造函数中没有old_tuple_,因此只能构造后手动为其赋值。memory safe test的时候给出警告,大意是认为构造时没有对该字段赋值,之后在TransactionManager的Abort函数中读了该字段,有非法读的风险。
由于测试没有检查更新后的索引,所以只要删除添加record的这段代码就能通过安全测试,但这是不符合逻辑的。
总结
不会写感想什么的,总之学到了蛮多的,尤其是自己的弱点像并发的部分,以及C++的使用得到了提升。最后还是感慨写项目框架和那么多测试的老师tql,辛苦了。